
基于Kubernetes的资源调度策略研究与改进
2023-02-27 10:34于泽川包梓群苏鸿斌
智能计算机与应用 2023年2期
于泽川, 张 娜, 包梓群, 苏鸿斌
(浙江理工大学 信息学院, 杭州 310018)
0 引 言
底层虚拟化技术的快速成熟,各大云计算厂商也开始积极建立自己的云部署平台, 与此同时以Kubernetes(以下简称K8s)为代表的容器编排技术成为云原生的标准。K8s集群中主要包括api-server、kube-scheduler、controller-manager 3大组件。其中,kube-scheduler负责执行调度指令,将需要运行的Pod(基于Docker实现的K8s的基本调度单位,提供一组服务的集合)调度到符合要求的Node(负责负载Pod的基本单位)节点上去运行;kube-scheduler的默认资源调度策略相对简单,但考虑不够全面,默认调度采用先到先服务的原则,选择负载服务的节点时采用贪心思想,保证当前最优,在多Pod调度的任务场景中无法保证全局最优[1-3]。由于容器云平台的资源调度存在很大的优化空间,由此引起了广大学者的研究改进。
张玉芳等[4]在考虑节点本身性能的情况下,为不同资源给出不同计算权重,率先提出利用负载权值计算的方法;李华东等[5]提出基于合作博弈论的多资源负载均衡(Multi-resource load Balancing algorithm based on Cooperative Game Theory,MBCGT)算法,解决面对不同资源请求时的算法下界和集群资源碎片化现象;聂清彬等[6]提出基于改进蚁群算法的自适应云资源调度模型。目前,关于智能优化算法在资源调度方面的研究成为主流。Kaewkasi等[7]将蚁群算法应用于SwarmKit集群进行容器调度,较贪心算法的性能有大幅提升;Mathiyalagan等[8]借助网格计算编程的粒子群优化算法发展系统能力;王悦悦等[9]使用自适应神经网络构建云资源预测模型,解决资源供求不均衡导致的资源利用率差等问题。随着大量研究的进行,智能优化算法被广泛应用于优化资源调度,并取得不错的成果。在智能优化算法中,粒子群算法因其简单易行、收敛速度快被广泛关注,其借助多个粒子在解空间中的迭代寻优寻找最优解[10]。本文针对智能优化算法中的粒子群算法作出改进,通过动态改变惯性因子、个体学习因子以及社会学习因子的计算权重,改善其前期的全局寻优能力和后期的局部寻优能力,加快其后期收敛速度,将之运用在K8s的资源调度方面,建立多Pod调度模型,并将改进的粒子群算法和传统粒子群算法以及K8s默认的调度策略进行比较,证明改进后的粒子群算法对集群的负载均衡度有所改善。
1 K8s默认调度策略分析与粒子群算法
1.1 K8s默认资源调度策略分析
K8s的默认资源调度过程分为预选和优选两个环节。在预选过程中,根据用户提交的yaml配置文件遍历所有Node,过滤掉不符合要求的Node,该过程保证了通过预选的节点都是足以运行当前Pod的节点。优选过程是为通过筛选的节点打分,整个选择过程通过预选阶段选择出可支持运行当前Pod的Node集合,作为下一阶段的输入,得到节点集合输入的优选过程以为各个节点打分为目标,得到分数最高的节点作为Pod落户的目标节点。打分范围是[0,10]之间的整数,通过分数表明该节点的优先级,10代表最优,0代表最差。当最高分节点不唯一,系统会从最高分节点中随机选择一个作为目标节点,存在一定随机性。
K8s的默认调度策略保持着启发式调度策略中的先到先服务准则(FCFS),会将调度Pod按照先后顺序依次执行上述预选和优选的过程,在为Pod选择负载节点时则使用贪心思想,永远将当前Pod调度到得分最高的节点上去,追求局部忽略了整个多任务调度过程的全局性;其次,K8s的调度策略只将CPU和内存作为资源调度的主要考量,忽略了网络带宽和磁盘IO的影响,Kubernetes集群的综合性能离不开这两者的的支持,因此网络带宽和磁盘IO需要加入运算,完成对节点更完整的画像;最后,在待调度队列中Pod被逐个调度时,同一副本下的调度任务可能创建多个副本,相同副本拥有相同的资源需求量,在进行相同副本的首次调度时,对符合要求的Node节点已经进行过打分,在调度下一个相同副本下的Pod时,大部分的节点打分仍然具有意义,但在K8s的调度策略中无法复用。基于上述问题,本文将对粒子群算法进行优化,并应用于K8s的资源调度,解决上述问题。
1.2 粒子群算法
粒子群算法(PSO)是一种智能优化算法,由Kennedy和Eberhart于1995年提出,作为一种基于群体智能(Swarm Intelligence)的优化方法,具有简单易行,收敛速度快和设置参数少的特点[11]。PSO通过在解空间中部署大量粒子来寻优。粒子仅具有两个重要属性,速度和位置。速度代表移动的快慢,从某种程度上反映了单次移动的步长;位置代表其作为一个解自身所对应的属性。一个粒子通过速度计算出在某维度上的速度,即会发生在该维度上的移动距离,当所有维度的数据特征聚集在一起就完成了一个粒子在解空间中的位置改变[12]。
首先,在解空间中给出大量粒子,每个粒子需要在解空间具有一个初始位置和速度,这些粒子要求均匀分布于解空间中,以防止结果陷入局部最优,无法收敛于全局最优。
粒子的速度更新公式(1)如下:
vi+1=ωvi+c1×random1()×(Pbesti-xi)+
c2×random2()×(Gbesti-xi)
(1)
其中,ω为惯性因子,取值一般为0.9,为保持上一步移动的惯性,来对下一步移动产生影响,决定了粒子继承先前移动轨迹的权重;c1是个体学习因子,表明自身历史最优值对当前移动的影响;c2是社会学习因子,表明群体最优粒子对当前粒子的吸引力,c1和c2的取值一般为2;Pbest是当前自身历史最优位置;Gbest是当前群体最优位置;xi就是当前位置;i为迭代次数;random1()和random2()为两个随机函数,随机产生范围在[0,1]的值,用于增强粒子寻优的随机性,防止粒子过早收敛,全局寻优能力降低,陷于局部最优。
单维度上的粒子的位置更新公式(2)为
xi+1=xi+vi+1
(2)
其中,x代表相对位置,i为迭代次数。
由此可见,速度直接决定了位置变化。
ω越大,当前粒子群的全局搜索能力越强,ω越小,当前粒子群的局部搜索能力越强。所以在实际应用中,为保证粒子群在迭代前期拥有较好的全局搜索能力,在后期可以有较强的局部寻优能力从而迅速收敛,ω通常是动态的,常用的动态变换公式(3)为
(3)
其中,ωmax和ωmin分别代表惯性因子的上下界,选值通常为0.9和0.4;r是迭代次数;rmax为预设的最大迭代次数,本次取值200。
随着迭代次数的不断增加,惯性因子ω完成了从最大值到最小值的线性变化,某种程度上摆脱了固定惯性因子大小带来的容易陷入局部最优的缺陷。
设置迭代次数后,对初始化粒子的位置还有个体历史最优位置和全局最优位置进行迭代更新,而确认个体历史最优位置和全局最优位置的方法就是通过适应函数计算粒子的适应值,结束条件通常为结果收敛或已经达到预设迭代次数。
2 粒子群算法改进与应用研究
2.1 改进粒子群算法Ku-PSO
PSO算法通过迭代寻优,具有易于实现,易于理解,设置参数少等特点,但其仍存在易陷入局部最优解,难以得到精确的全局最优解等缺陷。本文对传统PSO算法作出改进,改进后的算法称为Ku-PSO算法,前期迭代更为依赖个体学习,拥有更好的全局寻优能力,后期迭代更为依赖社会学习,拥有更好的局部搜索能力,利于收敛。在整个搜索过程中,当前位置适应度较低时给出更大速度,扩展更多可能性,在当前位置适应度较高时给出相对较高的惯性因子,提升收敛速度。
公式(1)中ω,c1和c2,分别充当了前一次迭代速度,前一次迭代全局最优位置和自身粒子历史最优位置参与计算当前迭代速度的权重。
首先,对ω作出改进。ω较大时,粒子会拥有更好的全局寻优能力;ω较小时,粒子会拥有更好的局部寻优能力,故提出ω的动态变化公式(3),使得ω完成了由ωmax到ωmin的线性变化。
此处将ω的线性变化公式由公式(3)替换公式(4):
(4)
借助抛物线,获得更为合理的由ωmax到ωmin的非线性变换。由于粒子群算法易陷入局部最优解,通过非线性变换使得ω在前期迭代中缓慢减小,后期迭代中快速减小,从而增强前期全局寻优能力和后期的局部收敛能力。
在此基础上,为增强粒子的全局寻优能力,设计在粒子适应度较小时,继续维持较大的速度,从而获得更大的步长,得到更广阔的解空间搜索范围。因此对c1和c2给出式(5)变化,假设公式(1)中c=c1=c2。
(5)
其中,cmin即为c的最小值,取值为1;cmax即为c的最大值,取值为3;F为当前粒子通过适应函数计算出的适应度;Fmax为前一次迭代全局最佳适应度;Favg为前一次迭代的粒子群平均适应度;θ为曲线平滑度控制因素,此处取值为3。
tanh(x)为双曲正切函数,其特征x在(0,+∞)的范围内,其值在(0,1)上非线性递增,斜率逐渐降低。设置θ为3,边界更靠近1,使得c完成了从cmin到cmax的非线性变换。随着迭代次数增加,从一定程度上降低了惯性因子的影响,使得自身收敛特征更为明显。通过分段函数使得粒子在自身适应度较低时,可以通过一个更大的速度移动,从而探索更多的解空间,而在自身适应度高于均值时,进行正常的收敛。这样做防止了粒子过早地陷入局部最优,保存了种群多样性。
为再次强化前期的全局搜索能力和后期的局部搜索能力,有必要在前期给个体学习因子c1更高的权重,在后期将权重逐渐偏向社会学习因子c2。
于是给出公式(6)和公式(7),使得在前期迭代中,个体学习因子c1占较大比重,可以增强前期的全局寻优能力,探索更大的解空间;后期迭代中,社会学习因子c2比重逐渐升高,可以在基本确定全局最优范围后迅速收敛。
(6)
(7)
Ku-PSO针对惯性因子,个体学习因子,社会学习因子均给出了优化方案,使得前期的寻优能力大幅提升的同时不影响后期粒子群的收敛速度,基本解决了粒子群算法容易陷入局部最优的问题,借此完成均衡调度。
2.2 Ku-PSO在K8s资源调度的应用
通过Ku-PSO算法针对K8s集群多Pod应用部署创建模型。
将n个Pod应用部署到m个负载应用的工作节点上,设置对应配置矩阵。部署Pod集合为Pods={p1,p2,p3,…,pn},负载节点集合Nodes={n1,n2,n3,…,nm},为Pods中每个Pi在Nodes中选择一个负载节点nj进行部署。
配置矩阵如下:
dij取值为0或1,为1代表将第i个Pod部署到了第j个Node上运行,为0则相反。一个矩阵D就是一种调度方案。在Ku-PSO算法中,一个粒子代表一个配置矩阵,即代表一种调度方案。
K8s默认调度算法只将CPU和内存性能考虑其中,忽略了网络带宽和磁盘IO对Pod部署的影响。在网络应用和涉及存储的Pod部署时,网络带宽和磁盘IO也同样重要,此次在考虑CPU和内存的基础上将网络带宽和磁盘IO也加入运算,通过时序数据库InfluxDB来获取各个Node节点的资源总量{Ccpu,Cmem,Cnet,Cdisk},和各个Pod的资源请求数值{Rcpu,Rmem,Rnet,Rdisk}。
接下来为粒子群算法设置目标函数,即为适应函数,式(8),对所有的方案进行筛选和优化比较。

(8)
其中,U代表资源的利用率;j为Node的编号;Uavg代表所有工作节点上的平均利用率。
借此式来表示一种部署方案下的集群负载均衡度,式(9):
(9)
设置好部署矩阵和评判粒子好坏的适应函数,接下来需要为配置矩阵设置约束条件,避免Pod应用部署时产生矛盾。
首先,每个Pod最多只能部署到一个Node上运行,故存在式(10):
(10)
其次,各Node节点上部署到Pod请求资源总量不得超过当前节点上拥有的资源总量。故存在式(11):
(11)
其中,i为部署到第j个Node上的Pod编号。
上述过程按照标准的粒子群算法改进,但K8s多Pod任务部署过程是一个离散型问题,需要在Ku-PSO算法的基础上,进行二进制离散粒子群的映射。标准粒子群算法使用sigmoid函数进行映射,通过映射的方式得到映射概率,可以计算出当前粒子在该维度突变为1的概率,式(12):
(12)
其中,vij为标准粒子群计算所得速度。
2.6 九种病原体的混合感染情况 本次研究仅存在两种病原体的混合感染,感染率为2.78%(194/6 984),占阳性病例的10.55%(194/1 839)。其中肺炎支原体合并乙型流感病毒居首位,占阳性病例的5.00%(92/1 839),其次为肺炎支原体合并副流感病毒,占阳性病例的3.75%(69/1 839)。
位置更新公式(13):
(13)
其中,random()为随机函数,计算得值范围为[0,1]。
然而这种计算方式已被刘建华[13]等学者证明:随着迭代次数增加,其突变的随机性会逐渐升高,在最终迭代次数时达到最大,使得后期需要收敛的结果产生了更多不确定性,不易收敛到全局最优值。
在此使用刘建华等学者改进的方法,将式(12)改为式(14):
(14)
速度在原点左右对称,为偶函数。速度为正时,概率函数递增;速度为负时,概率函数递减。
对应的位置变化公式由(13)改为式(15)~式(16):
当vij<0时,
(15)
当vij>0时,
(16)
为避免s(vij)过于接近极值1,可通过vij∈[-vmax,vmax]进行限制。通过二进制映射关系,使得粒子群算法应用到二进制离散的K8s多pod部署问题。
对粒子进行初始化,其位置初始化过程,式(17):
(17)
速度初始化公式(18)为
vij=vmin+random()×(vmax-vmin)
(18)
其中,vmin=-2,vmax=2。
3 实验设计
3.1 实验过程
实验环境采用Kubernetes1.18,通过虚拟机的形式部署在PC上,集群中包括1个Master节点和3个用于负载Pod的Node节点。
构建4台虚拟机作为Node节点,具体参数见表1。

表1 集群节点配置
部署Pod描述:本次部署选取应用场景最为丰富的网络服务web应用,该应用使用SpringBoot开发,接受无参请求,通过循环从100到1的阶乘计算,并在循环中进行当前结果的字符串拼接,并在计算完成后,存储进入文件中,其结果会返回给前端。web应用打包为Docker镜像,该Pod名称成为test-forpso。
测试流程:通过yaml文件进行文件部署,镜像在私有镜像仓库拉取,每个yaml文件中定义的Pod使用CPU、内存、磁盘的资源请求量见表2。

表2 Pod资源请求量
test-forpso部署数量为5个,依次递增至50个,每次调度在提升数量的同时,删除已部署的Pod,借此计算部署时间。
实验中使用默认调度算法,PSO和Ku-PSO分别进行实验,并对结果进行比较。
3.2 实验结果分析
通过实验,分别统计test-forpso不同部署个数的负载均衡度。结果如图1所示。
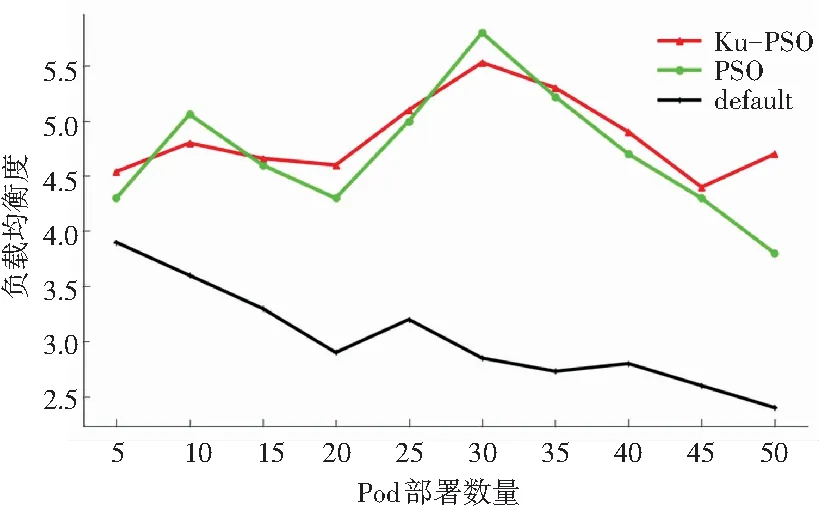
图1 负载均衡度对比
对比3种调度方法的负载均衡度,Ku-PSO明显更为稳定,且随着调度的Pod数目不断增多的过程中,其全局寻优能力更为明显,反观PSO算法更容易陷入局部最优导致负载均衡度降低,而默认的调度方法在多Pod调度时无法观察整个调度过程全局的特征,因而导致负载均衡度下降严重。
分别统计不同调度个数的时间消耗,结果如图2所示。
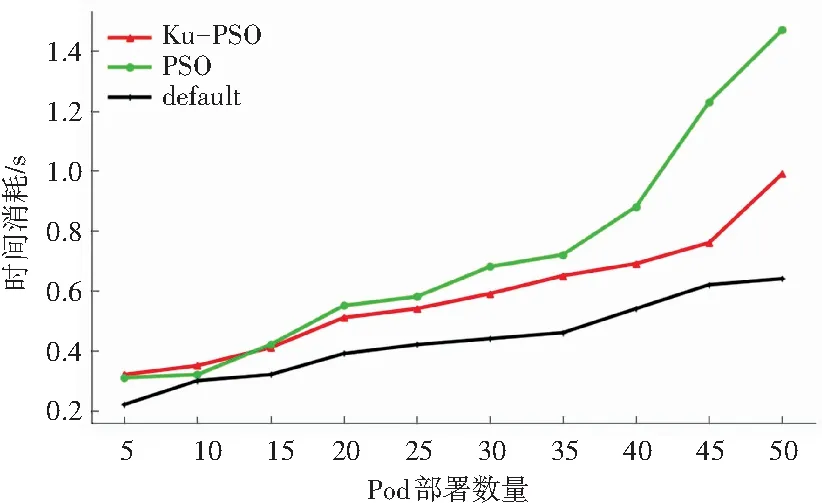
图2 调度时间消耗对比
对比3种调度方法的时间消耗,默认的调度算法由于调度过程较为简单,时间消耗最少;PSO由于过程复杂,时间消耗最长;Ku-PSO由于改进了后期的收敛速度,使得时间消耗在多Pod调度时得到迅速收敛,较传统的PSO算法消耗时间更短。
4 结束语
本文针对Kubernetes的默认调度算法中的不足进行改进,通过改进粒子群算法(PSO)得到Ku-PSO算法,使用二进制离散粒子群映射的方式将Ku-PSO应用于K8s多Pod部署过程中。Ku-PSO极大程度改善了经典粒子群算法中容易陷入局部最优的问题,通过调整惯性因子非线性变化,给予前期适应值较低的粒子更高的速度,防止陷入局部最优,使得迭代过程个体学习因子和社会学习因子权值动态调整,前期的全局寻优能力和后期的局部收敛速度均得到保证。实验结果表明,使用Ku-PSO在保证集群负载均衡度和调度时间上都有非常不错的表现。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
成都信息工程大学学报(2021年5期)2021-12-30
今日农业(2021年7期)2021-07-28
非公有制企业党建(2020年5期)2020-06-16
测控技术(2018年10期)2018-11-25
金桥(2018年4期)2018-09-26
浙江工业大学学报(2017年5期)2018-01-22
太空探索(2016年9期)2016-07-12
中国卫生(2014年5期)2014-11-10
