
基于深度学习的多目标车辆检测及追踪方法
2023-03-02 01:58王锋
汽车实用技术 2023年4期
王 锋
(长安大学 汽车学院,陕西 西安 710064)
伴随着国内外高等科学技术的急速发展,无人驾驶及智能网联汽车的发展也是日新月异。目前在发展无人驾驶过程中,尚有一些技术还在探索及发展中,导致部分技术仍不成熟[1]。如今的自动驾驶慢慢地延伸到智慧交通这个热门领域中,从而发展的方向更加全面,其中环境的感知、行为的决策以及对车辆的运动控制主键是自动驾驶的三个主要研究任务。在智慧交通的发展中,行驶道路上的车辆检测是比较重要的环节,该技术的大力发展到成熟会降低交通事故的发生率,以及提高车辆行驶的安全性和城市的车辆通行效率。但由于传统的车辆目标的检测及追踪是通过人工提取车辆特征来实现的,这样的工序就会导致检测精度较低、数据应用规模不大且泛化能力较差,很难在复杂应用场景中达到快速准确检测的效果,从而导致实时性不高[2]。
近年来,随着深度学习在自动驾驶的目标识别领域取得重大突破,其中,以深度学习为基础的车辆检测算法也逐渐成为该领域的热门话题。本文旨在克服传统检测中难以检测的场景问题,同时也处理无人驾驶领域常见的不同天气,光照变化较快,车辆目标不清晰等场景,故提出一种基于深度学习在无人驾驶和智能网联汽车领域的多目标车辆检车及追踪方法,从而实现智能车辆高级辅助驾驶中多目标车辆的实时检测及追踪。
本文共分为4章,章节内容如下:
第1章,构建车辆数据集。由于通过摄像机拍摄的照片会产生畸变,故需要对其进行畸形矫正,再建立以UA-DETRAC格式的和自制的初始车辆数据集,接着对数据集进行标注和格式的归一化处理,为后续的检验模型奠定基础。
第2章,构建神经网络模型。首先是通过K- means聚类算法获取检测图像的先验框,然后在以Darknet53的卷积YOLOv3为基础加入空间金字塔池化结构(Spatial Pyra-mid Pooling, SPP)模块,用以提高模型预测结果的精确度。最后通过预测模型的结果筛选以非极大值拟制算法为主的最终预测结果。
第3章,模型的测试与评定。根据之前构建的格式归一化后的多目标车辆数据集,通过搭建的预测模型进行训练,接着验证,最后通过相应的查准率和查全率两个指标来判断模型对车辆目标检测的准确性和健全性的好坏评价。
第4章,结论。基于深度学习为基础的多目标车辆检测神经网络模型,它是可以在一定的距离范围内基本都能准确地检测出车辆。在不同的交通环境下能够基本准确地检测出行驶的多目标车辆,说明该模型具有良好的实时性、准确性、鲁棒性和环境适应性。
1 构建车辆数据集
1.1 摄像机标定
在构建以机器视觉系统为基础的图像采集中,需要的图像质量应该能够确保机器视觉算法能够快速、准确地提取出所需要的图像信息,以便系统能够做出相关的抉择。然而想要实现这样的准确推算、测量和提取,机器视觉系统就必须使用真实世界里的坐标系和相关的测量单位。这意味着,要事先得到像素与真实世界坐标系的映射关系,才能在后续过程中使用其进行计算。在进行该模型搭建的前期,需要使用摄像机进行摄像取照,为后续模型做基础。众所周知,摄像机的成像过程本质上就是摄像机坐标系和真实世界的坐标系之间的转换。首先是将空间系中的散点通过“世界坐标系”转换到新的“摄像机坐标系”中,然后通过光学元件将形成的投影转化成平面图像,最后再将平面上的图像数据再转换成图像的像素坐标系中的坐标点。但是在转换的过程中,由于光学元件的制造精度以及组装的工艺精度的偏差会产生相应的畸变,从而导致图像会发生部分失真的现象。
由于镜头的畸变分为径向畸变和切向畸变两类,为了综合处理该镜头的畸变影响,本文采用相片变化的单应性变换方法。本文是采用棋盘格当作标定板来进行摄像机的标定和畸变矫正的处理。首先是找到图片上畸变前后的点位置的对应关系,利用多个视场计算多个单应性矩阵的方法来求解摄像机内参数,可通过OpenCV工具库的cv2.findChessBoardCorners()函数来完成,然后通过棋盘标定图纸校正摄像机的畸变,输入摄像机拍摄的完整棋盘格图像和交点在横纵向上的数量,再则选用10~20张从不同的角度拍摄的棋盘格图片,将所有的交点检测结果保存并进行畸变系数的计算,对摄像机拍摄到的实际路况进行畸变修正处理,最终再利用OpenCV工具库的cv2.drawChessboardCorners()函数绘制标定结果,如图1所示。

图1 棋盘格检测
1.2 建立多目标车辆数据集
本文所建立的多目标车辆数据集主要采用两部分来源的车辆数据,一部分是网上开源的车辆检测数据集UA-DETRAC,主要包括北京和天津不同地方的不同场景,该图像的录帧率为25帧/s,每隔10帧取一张,共得到8200张;另一部分图像数据集主要是选取自己在陕西省西安市南二环路段录制的车辆数据视频,每隔20帧抽取一张,共1100张。将这9300张图片作为深度学习模型训练和测试的多目标车辆数据集。本多目标车辆数据集会包括晴天场景、雨天场景、白天场景、黑夜场景、不同车型的场景和不同遮挡的场景等各种交通场景。
1.3 标注数据集
本方采用LabelImg的方法对多目标车辆数据集的车辆图像群进行标注,然后将图片中的多目标车辆框起来,并对车辆的类别进行标注,这里标注格式为car,接着保存标注好的内容,生成以可扩展标记语言(Extensible Markup Language, XML)格式存储的标签信息文件,如图2(a)—图2(c)所示。

图2 xml文件内容
1.4 数据集的格式转换及归一化处理
本文采用python脚本批量处理的方式将xml文件批量转换为txt文件,并对里面的xmin、ymin、xmax和ymax进行归一化处理。最终得到txt文件里的信息包括:车辆类别、x、y、框宽和框高,如图3所示。将这些制作好的标签文件按照8:1的比例通过python脚本进行处理生成train和valid两个txt文件,分别当作为训练集和测试集。最终制作好的多目标车辆数据集文件夹如图4所示。在此文件夹里,主要是分为五个部分,其中Images文件夹是用来存储该模型需要使用的全部多目标车辆数据集的图像,Labels文件夹是用来存放在Images文件夹里每张图像所对应并且被标注好的以txt格式存放的多目标车辆数据集的标签信息内容,class.name文件是用来存储汽车被标注的类别名,最后的train和valid文件夹是用来存储每张图像的存储路径信息,可以凭借该路径信息找到相应的图像。

图3 txt文件信息

图4 车辆数据集文件夹
2 建立神经网络模型
2.1 YOLOv3 SSP的介绍
YOLO(You Only Look Once)系列算法本质上属于一阶段(one stage)算法。不同于以往快速区域建议卷积神经网络(Faster-Region proposals Convolutional Neural Networks, Faster-RCNN)等两阶段(two-stage)算法,one-stage算法通常推理速度较快,但是模型精度不高,不过模型精度在YOLOv3的提出之后有了很大提升。所以YOLOv3的精度可媲美那些不足1 fps的模型,同时自身可以达到30 fps甚至更快的速度。YOLO系列算法采用Darknet网络作为特征提取网络,YOLOv2以Darknet-19为基础,Y-OLOv3是以Darknet-53为基础,其中Darknet-19长得比较像视觉几何群网络(Visual Geometry Group network, VGGnet),Darknet-53是参考了残差网络(Residual Network, RN)后再大量使用残差结构从而使网络可以在53层卷积层下能够正常学习,不会受到退化问题的影响。在YOLOv3架构中,Darknet-53舍弃了之前的池化层,并通过stride为2的卷积层实现池化层的功能。这一步的改变可为Darknet-53带来速度与精度上的提升。
本文所使用的YOLOv3-SPP是在相对于普通版本的YOLOv3基础上,在第五、六层卷积之间增加了一个超解(Ultralytics)版的SPP模块,这个模块主要是由不同的池化操作组成,如图5所示。

图5 SPP模块
2.2 SPP模块的意义
在以往的YOLO系列的网络架构中,都是采用卷积神经网络(Convolutional Neural Networks, CNN)网格架构,在最后的分类层通常是采用全连接组成,但是全连接有个明显的局限性,就是它的特征数是固定不变的,这也就导致了图像在输入网格的时候,图像的几何尺寸是保持不变的,但是在实际的运用过程中,图像的大小都是多种多样的。假如输入的图像尺寸不能满足全连接的要求,就不能完成接下来的前向运算。故为了得到固定尺寸的图像,就必须对图像进行剪裁或拉伸变形等操作,但是这样的后果就会导致图像的失真,最终影响模型的精度。为了克服之前的缺陷,希望图像在输入的时候保持之前的几何尺寸,就在YOLOv3的基础上加入了SPP模块,从而可以有效地保留图像的原尺寸,避免之前的剪裁,变形及拉伸等操作带来的图像失真影响,也同时解决了卷积神经网络对图像重复特征提取的问题。
具体就是SPP模块将特征层分别通过一个池化核大小为5 mm×5 mm、9 mm×9 mm、13 mm× 13 mm的最大池化层,然后在通道方向通过连接(concat)功能拼接再做进一步融合,这样能够在一定程度上解决目标多尺度问题。如图6所示。
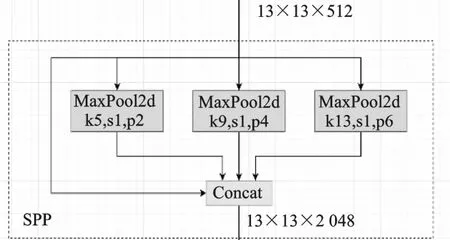
图6 SPP的功能
2.3 获取先验框
本神经网络架构是采用K-means聚类算法为基础通过自主学习获取图像的先验框。K-means算法又被称为K均值算法,K代表的是聚类中K个聚类中心点,means代表的是每一个聚类中心数据值的均值会作为该聚类中心的点的中心,即是每一个类的中心对该聚类中心进行描述。其聚类算法的思想主要是先从样本点里随机选取K个样本点作为聚类中心点,然后计算所有除了聚类中心的样本点到这些聚类中心点的几何距离。对于每一个数据样本,将其划分到距离最近的聚类中心点中,然后不断迭代,新的样本点然后又划分到新的聚类中心点里[3]。最后使用K-means聚类算法可以初步得到先验框的几何尺寸和大小。
2.4 构建神经网络框架
本模型构建了一种基于Darknet53的卷积且以SPP模块为衍生的神经网络架构,如图7所示。这种网络构架主要是由一系列的3x3和1x1的卷积层组成的,并且在每个卷积层的后面会有一个批标准化(Batch Nor-malization, BN)层和有一个负反馈修正线性单元(Leaky Rectified Linear Unit, LeakyReLU)层。在大矩形框内的模块是Residual层,它是神经网络架构的残差模块,借鉴Resnet的思想,是被用来防止梯度的损失。所以它只是用来求差,不会进行任何其他的操作,这样就可以保证输入值和输出值保持不变。在每个Residual层的后面会使用一个步长为2的3x3的卷积层来进行降解采样压缩,总共进行五次这类操作,也就是相当于进行了5次的缩放过程,也就是特征图的长宽的尺寸会变成为原来的1/32,假如输入的图像尺寸是416 mm×416 mm,那么最后输出的尺寸就是13 mm×13 mm。虚线框下面的部分就是三个不同尺寸的输出分支[4]。在经过5次的缩放过程后,会得到5种不同的图像尺寸大小的特征图,他们分别是208 mm×208 mm,104 mm×104 mm,52 mm×52 mm,26 mm×26 mm,13 mm×13 mm,如图7(a)—图7(c)所示。由于前面两个的特征图提取到的信息不是很精确,一般会舍去,然后选择后三个特征图作为预测图像的主要预测目标。它们就会分别成为小尺寸、中尺寸和大尺寸的预测框图,用来检验具有不同尺寸变化的目标的位置信息、车辆类别信息和置信度信息。
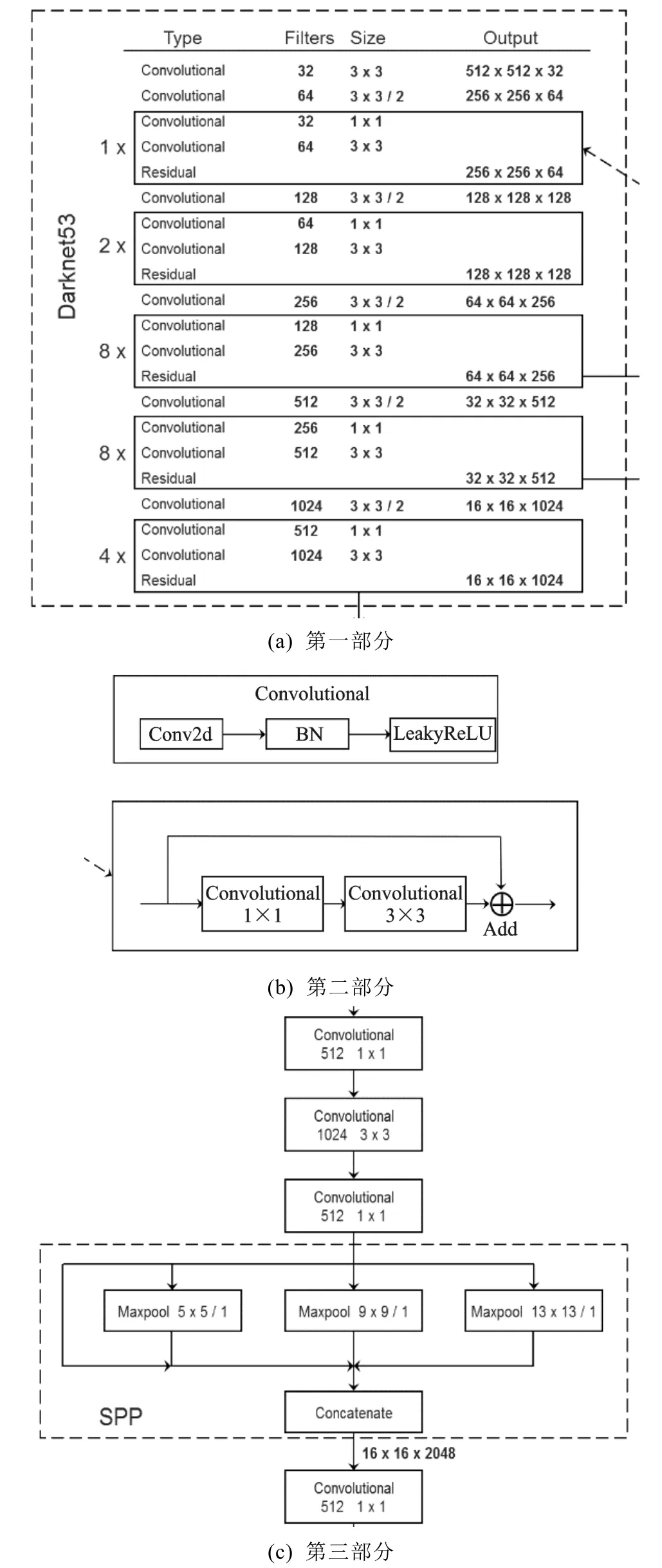
图7 YOLOv3-SPP部分网络架构
以YOLOv3-SPP搭建的神经网络模型,采用部分图像增强的功能,它会将多张图片拼接在一起输入给网络进行训练,以此就可以实现图像数据的多样性,进而增加数据目标的个数。以及BN能一次性统计多张图片的参数,实现拼接。同时BN层要求batchsize尽可能大一些,所求出来的均值方差就会尽可能的接近数据集,产生的效果就会更好。
2.5 确定预测框
由上述神经网络框架的输出可以得到三个不同的预测结果,但每一个预测s结果实际都是一个偏移量offset[5]。又因offset 由模型输出的四种类型数据组成,它们分别为tx,ty,tw,th。其与实际框的关系如图8所示。
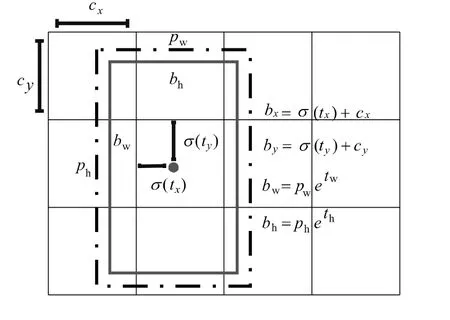
图8 边框预测示意图
在该预测示意图中,cx和cy它们分别表示中心点所在的单元格左上顶点的坐标;pw和ph分别表示先验框的宽和高;tx,ty,tw,th分别表示网络输出的预测值;σ(tx)和σ(ty)表示网络输出值tx和ty经过 sigmoid函数归一化后得到的偏移量;bx,by,bw,bh则是预测框的坐标。根据图8的表示可以得出预测框的实际坐标与网络输出预测值之间的转换关系如下所示:
经过上面公式的转化及运算,就可以得出网格训练后输出的四个预测值,然后再对由K-means聚类算法确定的先验框进行归一化处理就会得到预测框的位置信息,从而在原有的基础上提高神经网络预测目标的精度和稳定性。
2.6 获取最终的预测框
非极大值抑制算法(Non-maximum Suppres- sion, NMS)的本质就是搜索数据局部的最大值,然后抑制那些非极大值的元素数据值,从而就可以找到局部的最优解[6]。非极大值抑制算法的算法流程图如图9所示。

图9 NMS算法流程图
综上可知,非极大值抑制算法的目的就是消除冗余的数据点框,从而来确定最佳的目标物体的检测位置。在进行目标的检测过程中,只会取最接近真实值的预测框作为表示符合特征图的检测窗口。所以非极大值拟制示意图如图10所示。

图10 NMS车辆检测示意图
3 模型的测试与评定
3.1 模型的训练
基于YOLOv3-SPP的多目标车辆检测神经网络模型是在Pytorch深度学习框架下完成的,使用深度学习里的training-Opyions容器指定网络的训练参数,将预处理后的验证数据设置为一个后续方便使用的变量名:“ValidationData”,同时设置一个临时位置用来训练目标检测器的变量名:“CheckpointPath”,这样能够保证在训练过程中及时保存训练的结果。
3.2 测试与评定
本文是基于YOLOv3-SPP为网络构架的多目标车辆检测模型。本神经网络模型首先是通过查准率(Precision)、查全率(Recall)和F1值来评价模型检测车辆的性能[7]。由于本文的算法只是对车辆进行检测,因此分类目标就只有两类:车和非车,也就是正样(Right)和反样(Wrong)。因此,可以得到4种不同的检测结果,如表1所示。

表1 车辆检测结果分类表
TR(True-Right):实际为正样且被预测为正样,即正确地将正样判定为正样的样本数。
FR(False-Right):实际为反样但被预测为正样,错误地将反样判定为正样的样本数。
TW(True-Wrong):实际为正样且被预测为反样,即正确地将正样判定为反样的样本数。
FW(False-Wrong):实际为反样但被预测为反样,即错误地将反样判定为反样的样本数。
通过上面四个数值就可以得到查准率和查全率的计算公式如下:
查准率表示能够准确检测出车辆目标的数量占被检测的车辆总目标数量的比值,查全率则表示能够准确检测出车辆目标的数量占整个车辆目标数目的比值,它们分别作为该神经网络检测模型对车辆目标检测的准确性和健全性的好坏评价。它们都可以成为评价预测模型性能指标,并且查准率和查全率数值越高越好。但有时候这两个指标会相互影响,呈现负相关,不太好评价模型的性能。因此,为了兼顾查准率和查全率,我们使用 F1值进行综合评价,F1值越高,模型的检测性能就越好。通过大量的实例验证,可以得出最终模型训练过程的Precision和Recall结果如图11所示,该模型的平均查准率为86%,查全率为95.4%,则表明模型的检测性能很好。使用训练好的车辆检测模型在验证集上进行测试,经过多次迭代可以得到模型的收敛情况如图12所示,另外通过对检测时间进行统计计算,检测速度可以达到45 fps,说明实时性也较好。

图11 PR曲线
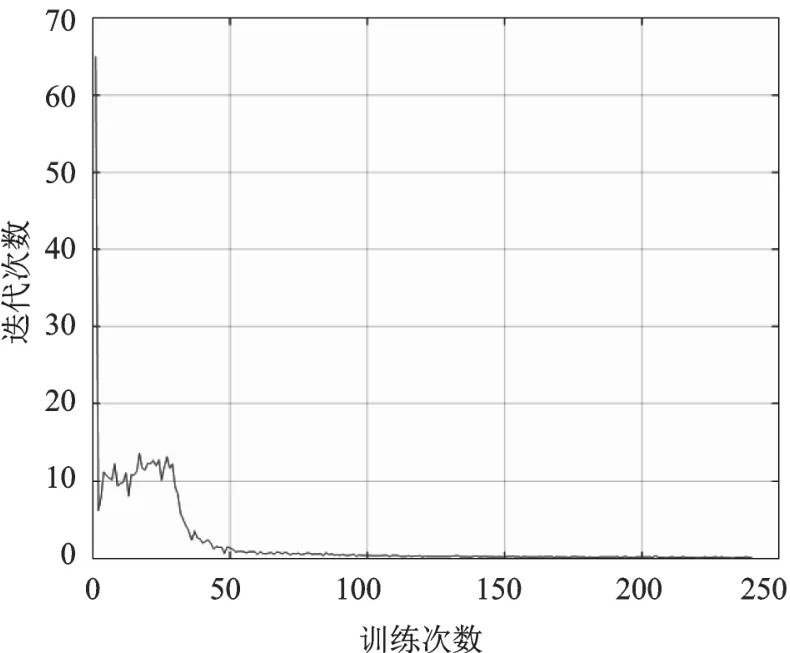
图12 多目标车辆检测模型的收敛情况
4 结论
基于深度学习为基础的多目标车辆检测神经网络模型,可以在一定的距离范围内基本都能准确地检测出车辆。从图13(a)—图13(d)和图14(a)—图14(d)可以看出,本文基于YOLOv3 SPP构建的多目标车辆检测及追踪神经网络模型能够优于传统的检测车辆目标方法或者简单的多目标车辆检测神经网络模型,在它们的基础上该模型可以在夜晚场景、白天场景、雨天场景、晴天场景、遮挡场景等不同的复杂场景下都能基本,准确地检测出行驶的多目标车辆,整体的检测精度相对于传统的说明该模型具有良好的实时性、准确性、鲁棒性和环境适应性。综上所述,本文搭建的车辆检测神经网络模型在一定的距离范围内基本都能准确的检测出车辆,并且能够适用在不同的场景下,鲁棒性较强,可以应用在智能汽车的车辆检测中。

图13 UA-DETRAC数据集的车辆检测结果


图14 自采数据集的车辆检测结果
猜你喜欢
电子制作(2019年19期)2019-11-23
铁道通信信号(2019年6期)2019-10-08
电子制作(2019年24期)2019-02-23
小太阳画报(2018年3期)2018-05-14
雷达学报(2017年6期)2017-03-26
阅读与作文(小学低年级版)(2016年12期)2016-12-22
互联网天地(2016年1期)2016-05-04
重型机械(2016年1期)2016-03-01
智能系统学报(2015年4期)2015-12-27
汽车文摘(2015年11期)2015-12-02
