
一种用于电视节目播出异态识别的人工智能模型训练方法
2023-03-07 10:02奚晓轶
电视技术 2023年1期
汤 冻,奚晓轶,闫 涛
(江苏省广播电视总台,江苏 南京 210013)
0 引 言
监听监看是广播电视安全播出的重要环节。播出机房值班人员需同时监看上百个活动画面,存在一定的视觉盲区。长时间监看大量活动画面,人员易产生视觉疲劳,导致注意力下降。部分画面异常现象出现时长可能不足0.5 s,难以被人眼或监看设备捕捉。如果多个画面异常同时出现,值班人员难以快速准确判断故障原因,可能延误播出故障的及时处理。同时,传统监听监看系统对系统硬件的要求较高。随着人工智能技术的发展,人工智能技术为智能化的异态画面检测提供了新的思路和方法。
江苏省广播电视总台研发了一套广播电视异态画面检测系统和分析系统,通过人工智能图像识别技术,实时识别异态画面,提示值班人员关注播出异常。在研发过程中,项目组发现由于广播电视节目画面异态样本少,用一般方法训练的模型的识别精度无法满足需求。本文通过分析广播电视异态画面的故障特征,提出了一种用于电视节目播出异态识别的模型训练方法,解决了样本量少以及准确度低的问题,提高了图像识别的准确度和识别速度,得到适用于广播电视播出应用场景的神经网络模型。
1 模型训练流程
为了使系统可以分辨出异态画面和正常画面,并识别出异态画面具体是哪一类异态画面,需要对异态特征进行分析。常用的图像特征有颜色特征、纹理特征、形状特征以及空间关系特征。然而,人工进行图像特征提取很难做到准确,也就导致后续识别的准确度不高。人工智能卷积神经网络(Convolutional Neural Networks,CNN)模型,可实现每一层神经网络学习不同类型的特征,自动组合并给出结果,从而实现对图片的自动特征提取与分类[1]。
电视播出过程中可能出现的异态画面一般包括视频丢失、黑场、单色场、测试卡及彩条等。在对LeNet、AlexNet、GoogleNet、ResNet[2]等 经 典 神 经网络架构进行测试和比较后,综合考虑样本量、网络结构以及网络深度对模型训练时间和精度的影响,本文最终选定Caffe深度学习框架和AlexNet神经网络结构,进行网络调试和模型训练。
模型训练的流程主要包括数据处理、模型参数调整、模型训练、数据测试以及模型输出等。训练流程如图1所示。
图1 模型训练流程
具体实施过程中,按照广播电视播出中经常出现的异常画面进行图像数据收集并分类;对图像进行尺寸归一化;再对图像进行增强操作,如图像倾斜角度、亮度、对比度调整等操作;对增强后的图像数据创建LMDB数据库;根据训练环境定义AlexNet结构,设置输出分类数量;配置训练过程参数,优化训练速度,防止过度拟合。具体训练步骤如图2所示。
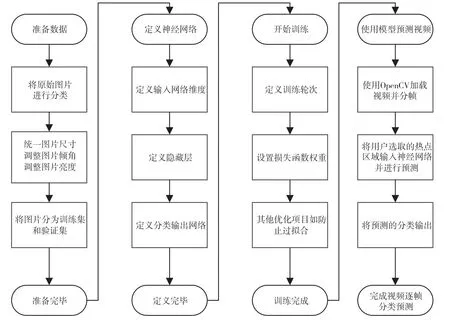
图2 具体训练步骤
2 数据处理
模型训练需要收集大量数据,输入神经网络中,通过不断调整网络参数,使最终识别结果准确度满足设计需求。现有成熟的图像识别数据库如ImageNet[3],MNIST等,大多是基于数字、动物、植物以及常见物品,而广播电视异态图像并不在通用的图像识别数据库中,数据集量也较少,需要自定义数据集,并通过数据处理,增加样本量,以达到训练要求。
2.1 数据收集
考虑到广播电视播出的节目异态画面实际情况,本文选择的图像异态主要包括彩条(75%,100%)、测试卡、单色画面(黑色、绿色、灰色、白色等)三种类型。
原始的图像数据可以从信号发生器的测试信号中选取。由于大多数测试信号不会在正常播出时出现,因此仅选取彩条、单色场等信号。另外一个图像收集途径是通过互联网爬取测试卡、彩条等图片,手工删除不符合的图片并进行分类,如图3所示。

图3 测试信号集和网络数据集
2.2 图像增强
由于本项目的数据集比较小,为避免训练过程中产生过拟合的情况,导致模型无法学习到样本的特征从而没法进行准确识别,同时考虑到本项目所训练的模型是应用于摄像头拍摄的画面识别,摄像头拍摄画面可能存在亮度不均匀、角度倾斜等问题,为让图像数据进一步贴近实际,提高识别的准确性,因此需要对收集的数据进行增强处理。
图像增强包括平移、旋转、亮度调节等方式[4]。平移是一种几何变换,它将图像中每个对象的位置映射到最终输出图像中的新位置。旋转是将原始的图像像素在位置空间上做变换。考虑到白天/黑夜不同光线条件,为了消除图像在不同背景中存在的差异,通过色彩抖动调整的是图像的亮度、饱和度和对比度。经过图像增强后,图像数据库增加到每个分类约1 000张图片。部分经过增强的图片如图4所示。

图4 图像增强效果示例
2.3 数据集制作
神经网络模型训练是经过前向传播计算损失函数(loss),描述模型的预测值与真实值之间的差距大小,指导调整优化参数,使模型在训练过程中朝着收敛的方向前进,否则可能无法达到所需的识别精度。在数据集中,通过将数据集切分为训练集(train)和验证集(val)[5],利用val数据来验证模型是否过拟合问题,并以此来调节训练参数。
本项目使用的广播电视播出异态分类数据集共有3个类别,分别建立colorbar(彩条)、tvtest(测试卡)和mono(单色画面)三个图像数据文件夹。样本的类别一般以字符串类型的类别名区分,但是对于神经网络来说,首先需要将类别进行数字编码。colorbar,tvtest和mono分别对应0,1,2的分类标签。类别名与数字的映射关系一旦创建,一般不能变动。train和val下的图片分别生成train.txt和val.txt的标签文件。将图片和标签生成Caffe框架所需要的LMDB格式数据集,就完成了模型训练所需要的数据准备。
3 模型调整
3.1 AlexNet模型结构
AlexNet模型由卷积层和全连接层[6]两大部分组成。AlexNet的优势在于网络增大(5个卷积层+3个全连接层+1个Softmax层),同时解决过拟合问题,并且利用多GPU加速计算。AlexNet模型的深度为8层,卷积层5层,全连接层3层,分类数目有1 000类。
3.2 参数调整
为了使神经网络模型更好地适用于广播电视播出异态画面数据集,需要对AlexNet模型的网络层参数进行调整。
原模型中输入的batch_size(批次数)参数是256,表示该批次输入图像为256个。根据训练的机器性能,将batch数目往下调到64,以免产生内存溢出的错误。但是由于batch_size比较小,样本覆盖面过低,产生了非常多的局部极小点,在步长和方向的共同作用下,数据产生震荡,导致不收敛。因此,需要调节其他的参数来保证数据的收敛。在这种情况下,把learning rate(学习率)调节到0.02,相当于加大了步长,这样可以在一定程度上避免震荡,图5所示为经过调整文件内容。

图5 部分模型参数调整
3.3 模型训练
参数调整后,通过Caffe框架进行模型训练。通过设置总训练轮次和断点优化训练过程。本项目每训练100轮,模型就会被保存一次。经过对模型的loss曲线查看,可以发现模型训练速度很快,损失函数逐步下降而收敛,100次左右就降到了很低的地方,因此训练200轮次就可以得到适合的模型。最终训练生成的caffe_alexnet_train_iter_200.caffemodel模型,其Loss曲线如图6所示。
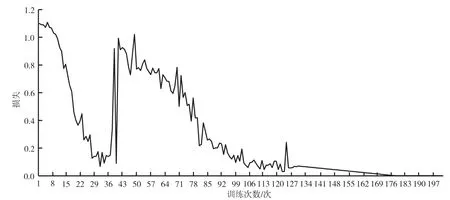
图6 损失函数曲线
4 模型测试
模型训练好后,通过OpenCV调用模型,对图片进行分类预测,以验证模型识别的准确性。图7为输入一张实际的机房监看画面,预测为tvtest(测试卡)的可能性达到99.99%,预测准确。

图7 彩条预测效果
对于摄像头拍摄的视频,通过对视频中每一帧画面进行检测,即可得到检测结果。经过测试,该模型对测试集数据中的异态画面识别精度超过97%,实际应用中,对彩条、测试卡以及单色画面等三类异态画面的识别准确度达到90%以上。
5 结 语
通过本文方法训练得到的广播电视节目异态识别模型,在广播电视异态画面检测和分析系统中得到了较好的应用。在实际使用中,通过机房摄像头/码流采集板卡等实时采集电视播出监看视频,系统可实时、准确地识别出异态画面,并标注异态信息,提示值班人员关注播出异常。在此基础上,通过对异态数据的智能分析、异态码流精准定位回看,系统能给出智能决策分析,辅助值班人员全面、高效、准确地掌握安播运行状态,以较低成本解决安全播出监看全面性、准确性和可靠性问题。
猜你喜欢
电子制作(2019年19期)2019-11-23
——西瓜
启蒙(3-7岁)(2017年6期)2017-11-21
北京广播电视报(2016年15期)2016-10-19
北京广播电视报(2016年15期)2016-10-19
北京广播电视报(2016年15期)2016-10-19
北京广播电视报(2016年15期)2016-10-19
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
小学生作文选刊·低年级版(2014年7期)2014-08-19
