
基于事件异构图表示的文本去重算法
2023-03-08 06:32艾玮许佳谢灿豪孟涛
湖南大学学报(自然科学版) 2023年2期
艾玮,许佳,谢灿豪,孟涛
(中南林业科技大学 计算机与信息工程学院,湖南 长沙 410018)
随着大数据时代网络信息激增,扩展了人们获取信息的渠道,有利于信息的传播,但是随之而来的是大量重复网络信息,如何对大量且重复的网络信息进行提炼是亟待解决的问题.其次,从当前的网络信息中可以得出,当前网络信息中需要分析、提炼的大部分是新闻文本.因此,对新闻文本展开文本去重研究是十分必要的,并且如何从冗余的数据中获取需要的信息,是信息处理的首要任务.
当前主流的去重方法,均是通过文本表示技术获取文本的向量表示,再计算向量之间的相似度,从而判断文本之间是否相似、重复.而随着词向量、神经网络、预训练模型等技术的发展,研究者们不断提出基于不同文本表示的文本去重算法,通过不同的文本表示方法可以将当前的文本去重技术分为四类:经典文本表示方法、分布式文本表示方法、上下文表示方法以及图结构表示方法.不同的文本表示方法,所获取的文本信息也是不一样的,而获取的文本信息越多,文本相似度计算结果越准确,从而文本去重准确率越高,并且新闻文本的核心是其描述的事件,因此更多地获取新闻文本描述的事件的语义信息,有利于提高文本去重的准确率.
首先,在经典的文本表示方法中主要有二值0-1、词频(Term Frequency,TF)、词频-逆文本频率指数(Term Frequency–Inverse Document Frequency)等向量文本表示,经典的文本表示方法能获取浅层的文本语义[1].王诚等作者提出了基于TF-IDF 的Simhash大规模文本去重[2],该方法通过TF-IDF 技术筛选出文本的主题词汇,再采取Simhash 算法,获取文本的向量表示,该方法消除了大量的噪声,能有效地进行大规模文本去重,同时也能保持Simhash的高效计算性能.但是经典的文本表示方法只能获取浅层的文本语义,无法获取较深层次的语义信息及文本结构信息,因此基于分布式假设理论的神经网络语言模型与分布式词向量表示应运而生.
分布式文本表示方法主要有NNLM(Neural Net⁃work Language Model)[3]、Word2vec[4]、Glove[5]等,分布式文本表示方法能获取词语的局部上下文信息,增加了文本表示的语义含量.崔洁提出了进行加权处理的Word2vec 算法进行文本相似度计算[6],该研究考虑了词语中的局部文本信息,也对词语的位置信息进行考虑,结合余弦相似度得到最终的文本是否重复的信息.但是分布式文本表示方法存在文本多义词以及未登录词(Out of Vocabulary,OOV)问题.于是研究者们针对上述问题,提出了基于上下文的文本表示方法.
基于上下文的文本表示方法主要有ELMo(Em⁃bedding from Language Models)[7]、BERT(Bidirec⁃tional Encoder Representation from Transformers)[8]等模型,这些模型能解决分布式文本表示的相关问题,还能获取文本序列的上下文信息.宁春妹提出了基于BERT 的文本相似度算法[9],利用BERT 进行文本表示,解决一词多义的问题,在文本相似度上取得较好的结果.尽管目前使用最多的文本表示是基于上下文的文本表示方法,但是它忽略了文本的全局结构信息,而图结构能够很好地表示结构信息,因此提出了基于图结构的文本表示方法.
目前主要有两种图结构,分别是词连通子图结构与事件连通子图结构.二者均是通过将文本中的词或者特征句当作节点,并将词或者特征句之间的关系构建边,得到最终的图结构,通过图结构能够将文本的结构信息进行表示,丰富了文本表示的信息含量.刘铭等人提出了基于词进行构建篇章级事件表示的文本相似度方法[10],通过图结构将句子级事件进行连接,形成篇章级事件表示,能将事件内部触发词与事件元素进行联系,之后采取结合EM思想的TextRank 算法,计算得出文本的相似度.谭伟志等人提出了面向事件的文本表示方法计算文本相似度[11],该方法将特征句作为图结构的基本节点,特征句之间的关系作为边,以此构建事件语义网络模型,之后采取PageRank算法,计算得出文本的相似度.
基于图结构的文本表示方法中,对图的表征除了采取PageRank 等算法,还有采取图核算法的.蒋强荣等提出使用图核算法对文本图表示结构表征[12],在计算表征后的向量的相似度得到文本相似度,通过图核算法能更好地表征结构信息,提高计算的准确率.左咪等提出的基于W-L 图核算法的文本图表示进行图表征[13],利用W-L 图核算法,能获取图的结构信息并且能简化图计算的复杂度,有效提升了图相似度计算的准确率及性能.虽然当前基于图结构的文本表示已经使得文本去重效果得到提升,并且采取的相关图表征算法也有一定的效率及效果上的提升.但是,目前基于图结构的文本表示仍然存在一定的缺陷,无法对事件语义或者事件元素关系进行完整表示,并且当前图表征计算方法,不能获取图结构信息或者不能对多种节点类型的图进行完整表征.
针对上述问题,本文以新闻文本为研究对象,根据新闻文本的核心内容事件进行分析,提出基于事件异构图表示的文本去重算法,该算法首先采取事件异构图进行文本图表示,事件异构图包含了事件实体、事件触发词、事件特征句三种节点类型,以及多种节点边类型,通过事件异构图可以更好地表达出文本的各种信息.其次,为了更好地表征事件异构图,我们采取能够获取图结构信息及语义信息的图核算法进行图表征,但是当前的图核算法无法对异构图进行表征,所以本文提出双标签图核算法表征异构图结构,通过标签的信息迭代逐步对全部的节点信息进行表征,并且双标签图核算法能降低图计算的复杂度,达到提高去重的效果以及效率的目的.因此,基于事件异构图表示的文本去重算法能有效地提高文本去重算法的效率及效果.
1 事件异构图
在本节中,主要介绍构建事件异构图的相关过程以及相关定义,主要包括事件抽取、关系识别、事件异构图定义及构建.
1.1 事件抽取
事件是文本表示的最小语义单位,并且一篇文本中会存在多个事件语义单位[14],我们首先对事件进行如下定义:
式中,E代表事件,W是事件的触发词,S是事件的特征句,C是事件的主要对象,O是事件的次要对象,T是事件发生的时间.
我们选取Han 等人提出的中文新闻事件抽取算法[15]来完成本文的事件抽取.根据事件的定义,事件抽取的内容主要包括事件的实体、触发词、时间、地点、事件句等元素.如给定一段文本信息,采取中文新闻事件抽取算法[15]得到图1 所示的事件信息.从图中可知,下画线标记的句子是事件的特征句S,事件的实体对象C、O分别是“永安期货”与“中信证券”,事件的触发词W为“龙头企业”,事件的时间T为“1 月4 日”.其中,事件元组中的O与T可以是空的.

图1 事件抽取示例图Fig.1 Event extraction example graph
1.2 关系识别
关系识别是当前构图的关键部分,如何让文本表示中的结构信息更加丰富,是本文需要考虑的一个重要问题.我们采取两种方法进行关系识别,第一种是马彬等作者提出的基于事件依存线索的事件语义关系识别[16],第二种是杨竣辉等作者提出的基于语义事件因果关系识别[17],采取这两种方法进行关系获取,主要是由于目前事件关系的识别结果的准确率还有一定的提升空间,为了不过多引入噪声,采取常用的因果关系识别,以及较为准确的事件语义依存线索进行其余的关系识别与关系新增.本文所包含的关系如表1所示.

表1 关系表Tab.1 Relationship table
例如,给定一个文本抽取后的三个事件,通过因果关系识别方法进行关系识别,得到如图2 所示的关系.从图中可以看出,三个事件的实体均是“永安期货、中信证券”,将这三个事件分别表示为A、B、C,彼此之间存在两种关系,分别是要素间因果关系、隐性因果关系.其中,因为A、B事件的要素“行业龙头”引导了“估值溢价”要素发生,因此A、B 之间存在要素间因果关系.这些关系在构图的时候,能够使得事件异构图的结构更加完善,包含的信息更加丰富.
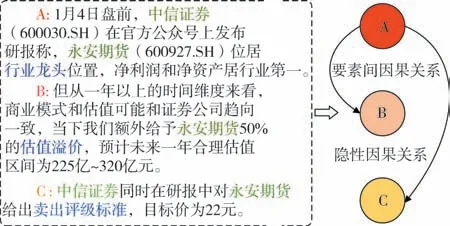
图2 关系识别示例图Fig.2 Relationship recognition example graph
1.3 事件异构图
异构图的概念是包含多种节点类型、多种节点连接类型的图,它能够表达更多的信息.因此,本文提出基于事件构建事件异构图进行文本表示,利用多种节点类型及节点连接类型表示文本的信息.定义如下所示.
定义1事件异构图:在一篇新闻文本中,存在N个事件,并且N个事件之间存在M个关系,此时可以以事件为对象构建事件异构图.如式(2)所示:
式中,G代表事件异构图;V是事件异构图的节点集,包括三种类型的节点,分别是特征句S、触发词W,以及主要对象C与次要对象O;R是事件异构图的节点边集,包含多种事件之间的关系以及事件元素之间的关系.具体表示如式(3)所示.
式中,N代表存在多少个事件E,M代表存在多少个关系.从公式(3)中可以看出,如何将这些节点与关系进行连接并构建图是本文的关键.若按照一般的相似度、事件关系等进行连接,比如,特征句之间根据相似度连接,触发词根据相似度关系进行连接等,这些无法包含事件的语义特征,且图之间的关系错乱,节点本身的作用被隐藏,无法达到丰富语义的目的.
因此,本文将特征句、触发词、事件实体构建一个图的具体模式结构—Λ 结构,该结构既能包含事件的语义特征,又能使得各种节点类型在图中的结构清晰明了,便于信息的传递.Λ结构定义如下.
定义2Λ 结构:当事件以元组形式表示时,以事件特征句S为中心节点,将事件的实体C、O与事件的触发词W作为子节点,并连接到中心节点特征句S上,形成具体模式Λ结构.
图3(a)所展示的是事件已构成的具体模式Λ 结构,图3(b)所展示的是部分关系实例,图3(c)是具体的事件异构图实例展示,其中包含5 个Λ 结构,各种节点之间存在着因果关系、时序关系等4 种关系、16条边.

图3 事件异构图示意图Fig.3 Schematic diagram of event heterogeneous graph
1.4 构建事件异构图
通过上述小节的描述,我们可知,通过采取事件抽取、关系识别等技术,获取构建图的节点集V和R.在传统的图构建方式中,是通过词的权重筛选后进行无差别连接构图,或者通过事件的相似度进行构图,这两种构建方式均不能表示事件的句法信息,导致图结构表示不够精准.
而本文是通过事件的Λ 结构构图,通过计算事件的Λ 结构的相似度,能获得事件之间的依存关系,更加精准地判别事件之间的相似关系.因此,事件的Λ结构相似度的计算如式(4)所示:
式中,Λ(Ea)、Λ(Eb)分别是事件Ea、Eb的Λ 结构的向量表示.若相似度大于阈值U,则认为两事件是相似的,反之则不相似.通过此我们可以将文本中描述相同事件的Λ 结构连接,形成部分Λ 结构连接子图,减少关系识别的复杂度,增加事件异构图的结构信息.
最后,根据节点集R进行完整构图.本文主要存在如表1 所示的关系类型.其中,显、隐性因果关系以及事件要素之间的因果关系,主要通过事件的元素进行分析,将事件间的因果关系转换为更细粒度的事件元素之间的因果关系,同时还会考虑事件的时序关系,并不会同时存在多种关系.而依存关系根据的线索广泛,两事件之间会存在多种关系,因此,若通过依存关系识别后,实体依存关系、触发词依存关系、结构依存关系均存在,此时我们并不将全部的关系进行连接,而是根据设定的关系优先选取策略进行连接,依存关系选取策略为:实体依存关系>触发词依存关系>结构依存关系.假如两事件之间同时存在触发词依存关系、结构依存关系,根据选取策略,仅选取触发词依存关系进行连接,这样有利于减少图结构中关系的重复度.
根据以上三个步骤,即可完成事件异构图的构建,具体详细流程见算法详解.
2 基于事件异构图表示的去重算法
本节主要介绍本文提出的文本去重算法,首先介绍算法如何对事件异构图进行表征,其次介绍根据表征后的信息如何进行去重计算,最后介绍文本去重算法的全部流程及其伪代码.
2.1 事件异构图的表征
当前图结构表征采取的是非异构图表征算法,无法获取图结构的语义信息,导致最终的信息有所缺失.图核算法虽然能获取图的结构信息与语义信息,但是也无法处理本文所提出的异构图结构.因此,本文提出了双标签图核算法表征事件异构图的方法,该方法将只能对同构图表征的图核算法[13],改进为对异构图表征的双标签图核算法,该算法既能获取图的结构与语义信息,又能对异构图实现表征.
本文提出的双标签图核算法表征方法,首先将Λ 结构中的子节点转变为标签信息进行传递,而双标签也增加了信息的含量,提升了图表征的信息含量.事件异构图的双标签图核算法表征方法迭代流程图如图4 所示,下面我们将具体描述双标签图核算法的迭代步骤,以及每个迭代步骤如何实现及其作用.
首先,将多节点类型的事件异构图,转变为单类型、双标签的图结构.从事件异构图的定义可知,节点的类型存在三种,分别是特征句、实体、触发词,而事件异构图由具体的Λ 结构组成.因此,将特征句当作单节点,触发词以及实体当作标签,进行图结构的信息表征的基础内容.于是,我们采取公式(5),并根据事件节点的子节点实体及触发词的内容,进行节点标签初始化,得到如图4中A步骤所示的节点的数字标签集.
式中,L是W、C的映射统一对象,F函数对相同的映射对象赋相同的标签值,∑是一个标签集,其大小是自然数集.在赋值时,通过函数F将不同的映射对象赋不同的标签值,相同的映射对象赋予相同的标签值.
当异构图的双标签赋值转变完成后,此时存在两个事件异构图G、G′,基于此我们开始展开双标签图核的迭代流程.首先我们对节点标签进行扩展,获取邻居节点信息,以当前节点标签开始,邻居节点的标签按照大小顺序进行排序,形成节点的多集,如式(6)所示.
其中,k代表节点j的邻居节点个数,如图4 中的B 步骤所示,在事件异构图G中,原本节点标签“2,2”的多集为“21,22”.

图4 双标签图核算法迭代流程Fig.4 Iterative process of double label graph kernel algorithm
当节点标签扩展完成后,对扩展的节点进行标签压缩,再次通过公式(5),接着上一次的标签值继续更新节点标签,对相同的扩展标签赋予相同的标签值,不同的扩展标签赋予不同的标签值,如图4 的步骤C所示,对G中的多集“21”赋予新标签“5”,G′中的多集“21”也赋予相同的新标签“5”,而G中的多集“1113”赋予新标签“11”,G′中的“11113”赋予新的标签“10”.
将步骤C 获得的新标签对上一个图的节点标签进行更新.如图4 的步骤D 所示,原始标签为“1,2”,迭代后的标签为“6,7”.通过公式(7)可得到每个标签迭代后的一维向量.
其中,∑*是当前节点的标签集合,φ函数是统计节点标签的个数,形成最终的一维向量.如图4 中的E 步骤所示,得到四个标签的一维向量φC(G)、φW(G)、φC(G′)、φW(G′).
由于本文的标签为两个,因此每次迭代后所得到的图一维向量为各个标签的一维向量拼接,通过公式(8)形成最终的图一维向量.
其中,当φ的下标为0 时,表示的是原始标签的向量表示;当φ的下标为i时,表示的是第i次迭代的标签向量表示.
最终,具体的双标签图核算法步骤如表2所示.

表2 双标签图核算法Tab.2 Double label graph kernel algorithm
2.2 文本相似度的计算
本文提出的基于事件异构图表示的文本去重算法,首先对文本采取事件异构图的图结构表示后,对图结构进行表征,得到文本的向量.通过2.1小节,我们可知图表征采取的是基于双标签的图核算法表征,而每次迭代循环均会得到新的图表征信息,通过循环标签压缩迭代对图进行表征,当φi与φi-1相等时,意味着图的信息扩展到最外层的信息,因此图的标签压缩迭代停止.
当图核算法每循环一次,图核能获取更多的信息,比如第一次节点标签更新,包含了该节点的直接相邻的节点的信息,而第二次迭代时新增了间隔为1的邻居节点信息,以此类推,每次迭代所获取的φ(Gi)与φ(G′i)向量是每次迭代更新的图信息表征.因此,计算图结构之间的相似度,也就是计算图表征过程中每次迭代所产生的向量的相似度.而每次迭代后所获取的信息也会越来越多,于是当计算图的相似度时,随着迭代次数增加,图向量中会持续引入噪声,导致最终的图相似度计算结果存在偏差.
因此,本文为了减少噪声对相似度计算的影响,对不同迭代次数下的向量相似度给予不同的权重,这种方法将使得最终得到的相似度值更准确,减少了由引入其他信息而导致的相似度值减少.权重给予的方法如公式(9)所示.
式中,h是图迭代的总次数,i是当前迭代的次数,i的最大值等于h.随着迭代次数的增加,对应的权重值逐渐减小.
因此,最终的事件异构图文本相似度的计算公式如式(10)所示:
最终,若通过公式(10)得出的相似度值大于或等于阈值Y,则两事件异构图为相似的,即文本是相似的;反之则不相似.
2.3 文本去重算法描述
本文提出的基于事件异构图表示的文本去重算法的主要步骤如表3所示,简称HGW-L.本算法采取伪代码的方式进行展示,具体见伪代码的算法说明.

表3 算法伪代码Tab.3 Algorithm pseudocode
算法说明:本算法的输入为新闻文本数据,以及本文所需的相似度阈值U、Y.从数据中选取需要执行文本去重的两篇数据Ta、Tb,首先我们进行第一部分操作,构建事件异构图对文本进行表示,如表3 的4~8 行所示.文本表示完成后,我们展开第二部分即异构图的图表征迭代过程,如表3 的10~19 行所示.文本表示及迭代过程完成后,最后是迭代向量的相似度计算步骤,如表3 中的21~33 行所示.最终HGW-L 算法的输出为两个事件异构图之间是否相似,当输出为1时则相似,输出为0时则不相似.
HGW-L 算法与之前的基于图表示的文本去重算法相比,首先在构图上包含更多的文本信息含量,如表3 中的第一部分构图建边所示,包含多重关系,能使得语义信息更加丰富.其次,能实现异构图的表征,并且包含图的结构与语义信息,有利于提升去重的效果.
3 实验分析
在本小节中,我们将对本文提出的文本去重算法进行分析、比较,并在真实的数据集上验证本文提出的文本去重算法的效果.
3.1 数据集及评估指标
由于文本去重领域没有公开的测试集,因此我们从新闻文本数据集(搜狗语料、今日头条语料)中分别随机取出大小不同的数据集进行效果检测,并对这些数据进行人工标注,确定数据的重复标签.数据集具体的大小划分如表4所示.

表4 数据集信息Tab.4 DataSet information
文本去重的本质是查找重复和非重复的数据的能力,因此本文主要采取精确率、召回率、以及F1值三个评估指标对文本去重方法进行评估,下面将详细介绍评估指标的计算公式.
去重的精确率反映文本去重方法计算的准确程度,是一个重要的评价标准.准确率Pre 的计算方法如公式(11)所示:
召回率反映去重的范围的覆盖面.召回率Rec的计算方法如公式(12)所示:
式中,x代表人工标注为重复且去重算法计算得出的重复标记一致的个数,y代表人工标注为重复且去重算法计算得出的重复标记不一致的个数,z代表人工标注为非重复且去重算法计算得出的重复标记一致的个数.
F1值即准确率和召回率的调和平均值,计算方法如公式(13)所示:
3.2 相似度阈值实验分析
本文的阈值选取有两个,第一个是事件的Λ 结构相似度阈值U,第二个是事件异构图相似度阈值Y.本节将通过实验选取阈值U、Y的最佳值.
3.2.1 相似度阈值U选取实验
相似度阈值U是图构建的重要步骤之一,通过判断Λ结构的相似度,识别出相似关系并进行连接构图;不同的相似度阈值U会影响事件之间的相似度准确率,越准确的相似度值越能使得事件异构图中相似的信息聚集,使得异构图中的关系更加准确,便于后续的图信息表示.在本文的数据集下进行实验,实验结果如图5所示.
在图5 中,横坐标代表不同的阈值U,阈值的取值范围为0.40~0.80,纵坐标代表不同阈值U下实验对应的F1值,此时的阈值Y设定为0.60.从图5 的(a)与(b)中我们可以看出,当阈值U的取值范围为0.60~0.70 时,实验的F1值相对稳定并且能取得较好的效果.从图中可以看出,头条数据集的实验效果相对低于搜狗数据集,这是由于头条数据集中的新闻的类型涵盖面更广阔,存在一定的效果差距.最终本文在后续实验中,选取0.65 作为相似度阈值U的实验值.

图5 相似度阈值U实验结果图Fig.5 The similarity threshold U experiment result graph
3.2.2 相似度阈值Y选取实验
相似度阈值Y是判断去重的主要依据,通过判断事件异构图之间的相似度值是否在设定阈值区间范围内,从而判断出文本是否重复.我们从不同的数据集类型以及大小中展开实验,得到如图6 所示的结果,其中,横坐标代表不同的阈值Y,阈值的取值范围为0.40~0.80,纵坐标代表不同阈值Y下实验对应的F1值.
从图6的(a)与(b)中可以得出,当阈值Y的取值范围为0.55~0.65 时,算法在搜狗数据集与头条数据集上的效果均达到较好的值.取值范围之外的Y值,算法的F1值均有所下降.故本文的相似度阈值Y设定为0.6,此时的HGW-L 文本去重算法的F1值在搜狗数据集上能达到0.9以上.

图6 相似度阈值Y实验结果图Fig.6 The similarity threshold Y experiment result graph
3.3 对比实验选取
本文是基于事件异构图表示的文本去重计算,因此我们将选取基于图结构的文本去重方法,以及其余基于分布式向量和上下文的文本表示方法的去重算法,形成多方面的对比,验证本算法的可行性以及准确性.我们选取了五种去重方法进行对比试验,如表5所示.

表5 对比实验选取表Tab.5 The comparison experiment selection table
首先,根据本文采取的文本表示方法,选取同类型的对比算法,即采取图表示的文本去重算法,主要有E-TC 算法与T-C 算法.其中,E-TC 算法是基于篇章级事件图的去重方法[10],首先采取事件实体以及事件触发词构图,然后使用基于EM 思想的TextRank算法计算图,再结合余弦相似度得到最终文本的相似度.T-C 算法是基于事件连通图的去重方法[11],该方法采取的是以词为节点进行建图,再基于PageR⁃ank算法进行计算,最终结合余弦相似度得到最终文本的相似度.
其次选取能获取文本上下文信息的文本表示方法,有B-R 算法与B-L 算法,其中B-R 算法是基于BERT 进行文本表示的[18],B-L 算法是基于Bi-LSTM进行文本表示的[19],这两种方法均直接进行文本向量转换,再对向量进行相似度计算从而得到最终的文本重复标签.
最后,我们还选取了基于分布式表示的去重方法,该算法采取的文本表示方式是当前使用较多的,有较好的去重效果,因此本文设计了该类型的对比试验.W-V 算法采取基于加权的Word2vec[6],通过Word2vec 算法对文本进行向量表示,结合余弦相似度计算并得到文本的相似性.
这五种方法从不同的去重角度、去重效率等方面进行选取,是符合多角度的实验对比分析的,通过最终的结果能更好地验证本文提出的文本去重算法的效果及效率.
3.4 实验结果及分析
本小节将选取的五种对比算法与本文所提出的方法,在不同大小、不同类型的新闻数据集上进行验证,并对本文提出的文本去重算法的效果及性能进行验证与分析.
3.4.1 效果分析
首先,我们将六种算法分别在不同的类型数据集以及不同数据大小下进行实验,并根据本文的评估指标得到图7所示的结果.
由图7 实验结果可得,本文所提出的HGW-L 算法,在两个不同来源、大小的数据集上的结果均优于其他五种去重算法,其中T-C 算法的效果最差,ETC 算法、B-R 算法、B-L 算法、W-V 算法的效果仅次于我们所提出的HGW-L算法.

图7 对比算法实验结果图Fig.7 Comparison algorithm experiment result graph
其中,E-TC 算法能获取文章的结构信息,但是忽略了事件的句法信息,如果是相同的特征词及实体,当出现不同的句法表示存在区别时,无法判断出两者不相似,因此其效果仅次于我们所提出的算法.而B-L 算法、B-R 算法与W-V 算法,通过使用Bi-LSTM、BERT以及加权的Word2vec算法,能获取短语或者事件的上下文关系,能得到较为丰富的文本语义信息,但是无法对文本的结构信息进行全局分析,获取的结构信息存在局部缺陷,因此整体结果相比而言较差.而T-C 算法通过构建词语连通子图的文本表示,基于PageRank 算法,获取的文本语义信息较差,忽略了词语的上下文关系,无法对不同语境下的事件进行区分,虽然是基于图结构的文本表示,但是在去重上的效果较差.而本文提出的HGW-L 算法,通过多种节点类型以及节点连接类型获取更多的语义信息及结构信息,再通过双标签图核算法获取精准的图表征,使得最终的相似度值的含义更加准确,达到当前最优F1值.
因此,本文所提出的方法在新闻文本数据上能实现更准确的去重,提升了去重算法的效果.
3.4.2 性能分析
由于事件抽取、关系识别以及构图等步骤对文本的性能有一定的影响.因此,本文的性能分析从不同的组别进行实验分析,分别是包含了事件抽取、关系识别等任务的运行时间分析,以及不包含前期处理、直接构图的运行时间分析.均在本文的数据集上进行实验,得到了图8中的两组实验对比结果.

图8 对比算法性能结果图Fig.8 Comparison algorithm performance results
在图8 中,子图(a)、(b)是本文提出的算法与对比算法分别在两个数据集上的消耗时间对比,由于本文的算法与E-TC、T-C 算法同属于基于图表示的算法,因此在这段时间计算中,我们仅从基于事件或者文本开始构图计算,并不包含文本的事件抽取、实体识别等任务;子图(c)、(d)与子图(a)、(b)的不同之处在于,将事件抽取、实体识别、关系识别等任务的时间均包含到总运行时间,从图中可以看出,新增的不同样式的柱状图是这些任务的运行时间.
从子图(a)、(b)中我们可以看出,处理相同数据量时,性能最差的是基于BERT 的B-R 算法与基于Bi-LSTM 的B-L 算法,性能最好的是本文提出的HGW-L 算法,并且能迅速处理完成,而另外两个基于图结构的E-TC、T-C 算法的性能与基于Word2vec算法性能保持中等并且相差不大.本文提出的HGW-L 去重算法,由于采取双标签图核算法,计算的性能为线性级,能保持较高的性能水准.而B-R、B-L 算法,需要对上下文进行处理,存在一定的计算消耗,因此处理时间较差.
从子图(c)、(d)中我们可以看出,当增加了事件抽取、关系识别等任务的处理时间后,基于图的去重算法性能优势减少.此时最佳性能算法为W-V 算法,该算法通过词向量的处理,能较快速地实现去重计算过程,而效果最差的是基于图表示的E-TC 算法,篇章及事件构造需要识别更多的内容,对文本的前期处理更加复杂,因此算法运行时间随着数据的增加而增加,导致性能最差.
因此,虽然本文在包括文本处理的时间后,性能不是最佳的,但是从整体上看,本算法的性能还是优于其余算法,并且能对处理后的文本进行快速去重.
4 总结及展望
本算法是针对新闻文本的去重算法.在对目前新闻文本去重研究现状进行分析后,我们针对当前新闻文本去重存在的语义表示不完善、效率较低等问题,提出基于事件异构图表示的文本去重方法,该方法首先采取事件异构图的文本图表示方法.可以获取更多的语义信息,提高去重计算的准确率.其次,通过提出双标签图核算法表征方法,对事件异构图进行表征,能高质量且高效地获取图的结构与语义信息.最后,我们在真实数据集上进行了对比实验分析,实验结果证明,本算法在真实数据集上的效果均优于对比算法,并在其余算法性能对比中,运行效率有所优化.
然而,当前去重计算较为冗余,尽管采取图核算法能减少图计算的复杂度,能提升去重算法的性能,但是进一步减少冗余计算,能使得本算法在大数据环境下快速计算.因此,我们后续计划对算法的去重计算次数进行优化,减少重复迭代计算次数,提高去重算法的性能.
猜你喜欢
小学教学研究(2022年5期)2022-04-28
开放教育研究(2020年2期)2020-03-31
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
中国洗涤用品工业(2017年2期)2017-04-16
电信科学(2016年11期)2016-11-23
现代语文(2016年21期)2016-05-25
公民与法治(2016年10期)2016-05-17
通信电源技术(2016年6期)2016-04-20
少儿科学周刊·少年版(2015年2期)2015-07-07
