
基于BERT与要素标注的适用法条推荐
2023-03-12 07:07李培林庞彦燕贺巧琳张世全
四川师范大学学报(自然科学版) 2023年1期
李培林, 庞彦燕, 贺巧琳*, 王 竹, 张世全
(1. 四川大学 数学学院, 四川 成都 610064; 2. 四川大学 法学院, 四川 成都 610207)
近几年,自然语言处理技术飞速发展.自语言模型中的word2vec提出之后,一大批词嵌入方法涌现,如GloVe[1]和fastText[2]等,它们从不同的方向都得到了表现优异的嵌入表征.2018年,Peters等[3]首次提出Elmo语言模型,实现了对无标注数据的使用.随后,Google团队在文献[4]中先通过无标注文本去训练生成语言模型,再根据具体的下游任务使用标注数据对模型进行fine-tuning.2018年末,Google发布了BERT[5]语言模型,融合了Transformer、OpenAI-GPT等工作的核心思想,并在NLP领域的11个方向大幅刷新了精度.BERT在各大数据集上取得的优异成绩,无疑将自然语言处理的发展推向了又一个高潮.2020至2021年,大量基于BERT的语言模型不断涌现,其中不乏对Attention机制的改进.Choromanski等[6]使用随机特征改进了Attention并推出了Performer. Kitaev等[7]发布了Reformer,通过哈希函数优化了Attention的计算速度. Cao[8]推出了Galerkin Transformer,在原有BERT的基础上改进了算法的精度与速度.
自2013年裁判文书网上线以来,人工智能在法律方面的运用也变得更为广泛.Luo等[9]使用Attention-based神经网络结构建立了罪名预测模型.Li等[10]实现了在CNN模型下的半监督学习,使大量庭审数据可以在无需人工标记的情况下使用.Long等[11]以法律事实、原告诉求以及涉及法条作为数据,将标签分类问题转化为阅读理解,推出了LRC模型以及“自动审判”系统.Chalkidis等[12]研究发现对模型引入Self-attention能提高模型在多标签分类任务中的表现.Wang等[13]在使用深度学习训练法条推断相关模型的基础上引入了分级制度,实现对训练过程中的标签数量的削减.
在法学人工智能和智慧法院建设中,法条推荐是关键任务,需要根据实时变化的法律事实等文本信息,通过人工智能技术自动推送对案件适用的法律条款,其本质上属于多标签分类问题.现有的法条推荐工作[14]直接以判决书中使用的法条作为标签,在模型训练中存在标签空间大、难分类数据样本较多等难点,推荐效果往往并不理想,对司法人员的帮助较为有限.
基于此,本文提出“要素标注+法条对应”的推荐模式.首先组织法学专业人员对研究领域涉及的法条和要素进行梳理和标注,得到案件事实的要素标注数据集,再利用机器学习训练案件事实和要素的对应关系,最后通过事先建立的要素与法条对应关系得出最终法条的推荐结果.这种方式克服了直接文本方式训练过程中标签数量过多的难题,提高了法条推送的全面性和针对性,能够推荐适用于具体案件的司法解释,减少法律适用中的遗漏风险.
基于要素标注的模式在训练模型过程中主要有2个难点:1) 实验涉及的要素标签在NLP分类任务中相对较多;2) 标注的训练数据集中部分标签正样本比例相对较少.为此,本文采用基于BERT的语言模型,根据裁判文书的数据特点从模型构建、分类器优化等方面对模型训练过程进行改进,得到了能够根据输入案件事实文本全面准确推荐适用法条的推荐模型.
本文剩余部分安排如下:第1节分别介绍了直接文本学习和基于要素标注2种不同的法条推荐模式;第2节介绍数据集的构成、分布与模型的选择;第3节基于裁判文书网获取并进行要素人工标注的数据集,使用不同的模型进行了对比,详细介绍了针对问题进行改进和优化的模型训练方法;第4节展示了不同案由下模型的推荐结果和分析;最后,在第5节总结了本文推荐模型的特点和下一步的研究方向.
1 法条推荐模式
法条推荐旨在于庭审过程中,根据变化的案件事实等数据文本通过人工智能模型实时自动完成推荐适用的法律条款等任务,能减轻司法人员的负担,提高审批的效率和质量.
1.1 直接文本学习的法条推荐模式自2013年中国裁判文书网①上线以来,海量裁判文书可以用于人工智能研究.上述裁判文书具有实时性、分类性、规范性的优势特点.
直接文本学习法条推荐则是指在法条推荐任务中,以判决书中法律事实部分作为输入,并将该判决书中裁判依据部分法官引用的法条作为对应的标签,通过语言模型进行训练.裁判文书网上的数据与文本法条推荐有着很好的契合度,不需要额外的人工标注,研究人员可以轻松地筛查数据,通过程序自动对裁判文书数据进行适用法条标注,从而获得大量的训练数据.
然而,这种传统的法条推荐模式存在以下几个缺陷:1) 法条数量庞大,一个案由下的法条数量会有好几百条甚至更多,导致模型训练标签数量过多,会严重影响模型训练效果与速度;2) 大部分法条使用频率极少,数据量少,模型学习困难;3) 法条推送不够全面,数据与输出结果往往未能包含针对性的司法解释和量刑意见等.
与此同时,司法人员对常用法条已经足够熟悉,比起传统的法条精确推荐,更倾向于机器推荐对当前具体案件具有针对性的司法解释和地方法规.
1.2 基于要素标注的法条推荐模式要素是指针对某一案由下所有涉及的法律问题、法律文本进行专业分析、归纳,形成若干个关键的核心词语或短语,用以代替某种特定的具有法律涵义的情形或者状态.这种确定要素的方式存在以下必要性:1) 法院系“依法审判”,其作出的每一个裁判结果都必须有法律依据,只有对应相关的法条,才能在审理过程中具有法律意义,产生相应的法律后果,所以针对事实文本的分析也必须以法条为依归;2) 本文的研究目的系针对事实文本进行法条推荐,所以进行要素标注的目的也仍然是围绕法条推荐,因此,每一个要素的确定都应当有对应的法条.比如刑法中的累犯、自首、退赃、认罪、未遂等,民法中的合同效力、履行期限、违约金、管辖条款等,这些都属于本文所指的“要素”.
在对数据集进行要素标注时,笔者组织了法律专业人员对基础数据进行逐一审查后,通过自身的法律专业判断,为该数据逐一贴上要素标签,使这些基础数据成为经过专业化处理的优化数据,且上述标注完成后将由其他同样具备法律专业知识的人进行复核,确保要素标注的准确度.
基于要素标注的法条推荐模式与直接文本学习不同,在训练中不再以法条作为标签,而是用要素做标签对案件事实的文本进行人工标注,再用标注数据进行训练.该模式首先通过人工整理要素集和要素与法条之间的对应关系,然后对事实文本进行要素标注,继而对这些有要素标签的标注数据集进行机器学习,训练得到事实文本与要素之间的对应关系.对新的事实文本进行分析时,模型会先推送出涉及的要素,每个要素都有人工整理的对应法条,从而完成对新的事实文本进行适用法条推荐.
2种法条推荐模式的流程如图1所示.对比直接文本法条推荐,要素标注模式需要首先进行要素的人工整理和标注.在模型训练上,由于要素在单个案由下数量比法条少得多,降低了模型的标签数量,改善了标签空间过大的问题,并且要素能更准确、简练地抽取法学特征,难分类样本的出现也远少于传统法条推荐标注.同时要素与法条之间有合理的法学解释与专业人工整理对应关系,在实际使用中,只要要素推荐的准确率高,则适用法条推荐的准确率就会高.

图 1 直接文本学习法条推荐与要素标注法条推荐流程
本文从刑事、民事中各自选取一个案由作为研究对象,选取案件类型的标准需要具有以下特点:1) 案件事实本身较为复杂;2) 涉及的法条、司法解释较多.这不仅使得研究过程更具有难度,而且对于法条推荐来说更具有实践价值.基于以上选取标准,本文在刑事中选取了诈骗罪这一案件类型,而民事中选取了离婚纠纷.
“要素标注+法条对应”模式相较于传统的法条推荐在使用上更为便利.首先,可以根据不同区域的需求就法条推荐进行区域性的专属设置.不同地区存在着不同的地方性法规、地方法院的指导意见等,而要素与法条的对应系人工整理得出的,则可以根据所处区域不同进行专属性推送,无需重新学习.其次,要素所对应的法条可以实时更新,包括对修改的法条进行修改、增加新发布的法律、司法解释等,而已有的要素无需更改.
表1为人工专业整理的部分法条与要素对应关系示例②.在“要素-法条”对应关系中,离婚案由对应36个要素,共计涉及24个法条;诈骗案由对应32个要素,共计涉及19个法条.其中,“多对一”与“一对多”的情况均出现在要素与法条的对应关系中.2021年《民法典》正式实施,只需修改“要素-法条”对应关系即可继续使用.例如,在表1中列举出的“要素-法条”对应关系中,诈骗要素对应的法条尚未存在修订等情况,离婚要素“赌博、吸毒等恶习”原对应法条为“《婚姻法》第32条”,现对应法条为“《民法典》第1079条”.

表 1 部分要素与法条对应关系
2 数据集构成与模型选择
2.1 数据集构成与分布本文从中国裁判文书网上公开的裁判文书中随机抽取了46 300份离婚案由裁判文书与57 240份诈骗案由裁判文书,这些裁判文书包含了法律事实与涉案法条等部分.通过抽取其中涉案法条与法律事实建立了对应关系,形成了数据集1,其中各个案由中每篇裁判文书标签分布统计如图2所示.之后继续在中国裁判文书网公开的判决书中随机抽取10 000份诈骗罪的刑事判决书与13 200份离婚纠纷的民事判决书,提取了判决书中事实查明部分的文字作为基础数据,并组织法学专业人员进行要素的人工标注,最终得到具有要素标注的文本数据③,作为本文的数据集2,其中各个案由中每篇裁判文书标签分布统计如图3所示.
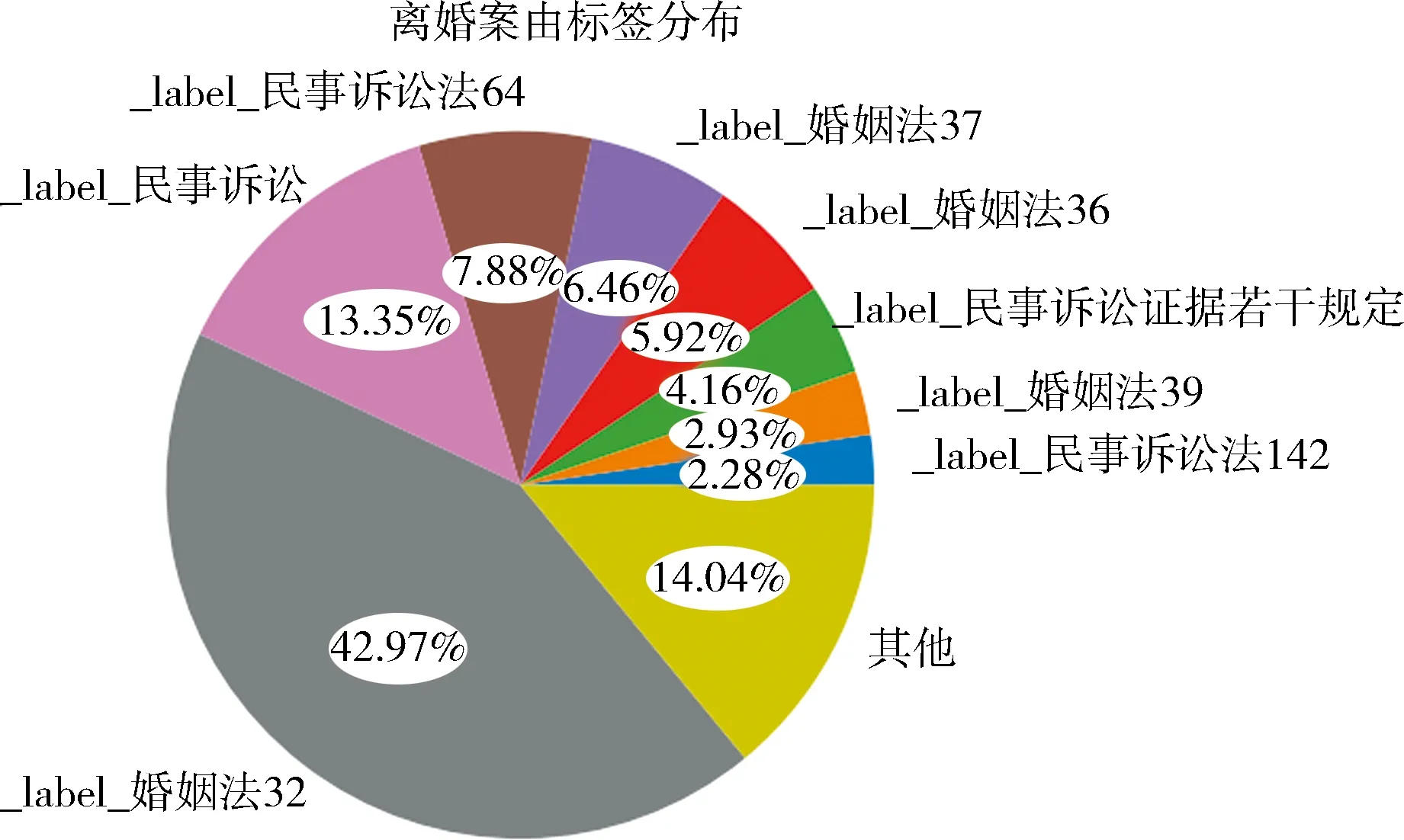
图 2 数据集1中各个案由中每篇裁判文书标签分布统计
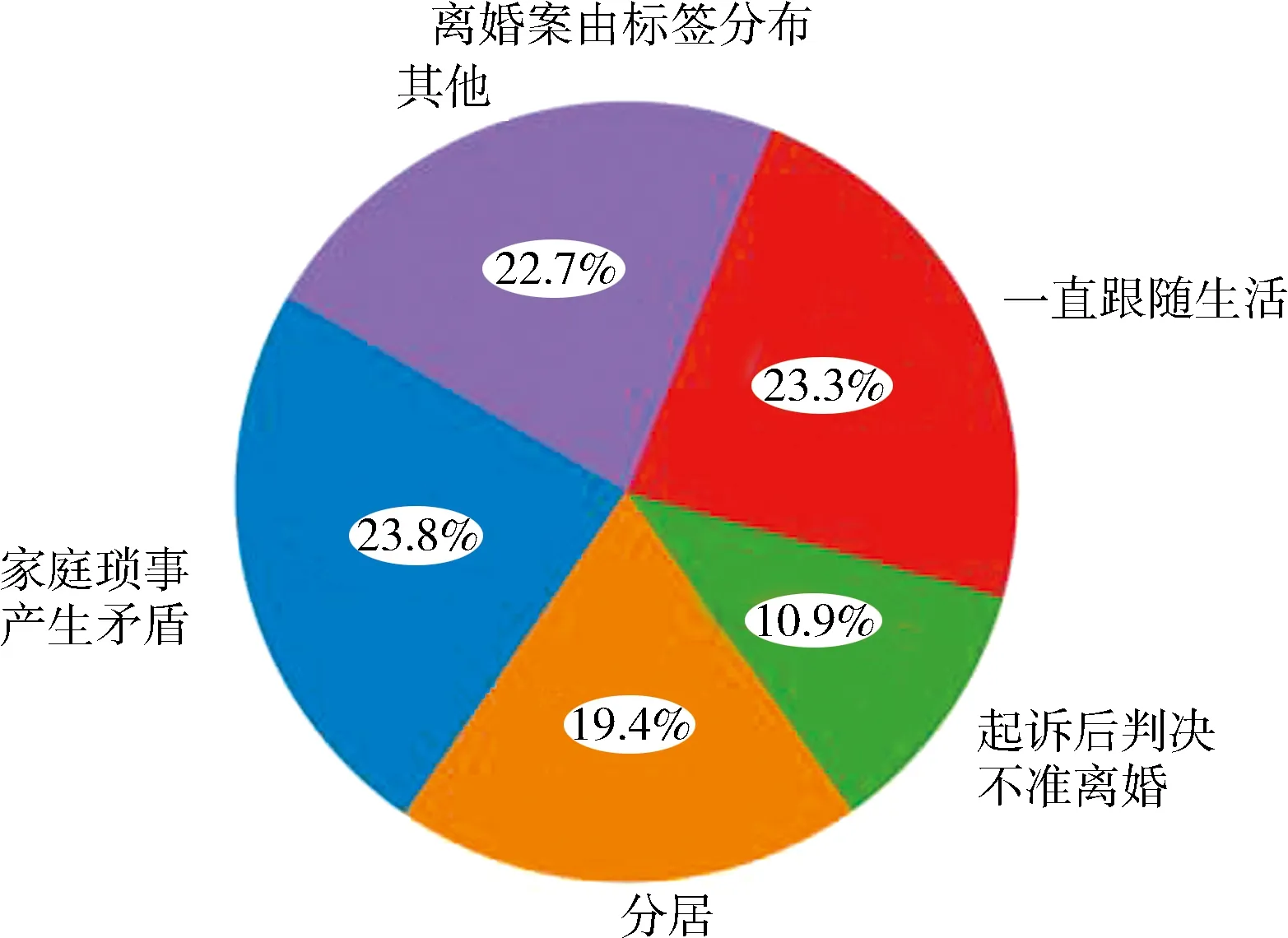
数据集2的标注过程如下:首先提取数据集中裁判文书的法律事实部分,然后按照要素对该部分进行人工标注.要素标注在遵循庭审与法律的逻辑的同时,极大地降低了传统法条推荐任务中的维度,减轻了后续模型训练的负担.这里选取法院事实认定部分,目的在于以下几点:1) 判决文书的查明事实部分存在大量其他案件事实的描述,对法条推荐任务没有直接联系;2) 摈弃了指控与辩护意见等文字部分,最大程度上还原事实本身;3) 法院事实认定部分用语相对精炼、专业,有利于对该事实做出性质判断.因此,为了保障案件还原的完整性和标注的有效性,本文进行要素标注时选取了法院事实认定的一整段文本作为标注对象.
数据集1中,离婚案由共计667个不同的涉案法条,平均每篇裁判文书包含了2.27个法条标签.诈骗案由共计638个涉案法条,平均每篇裁判文书包含了5.11个法条标签.将出现频率低于20%的标签归为“其他”,故图2中“其他”包含了超过500个标签,数据集1为不均衡数据集.这是由庭审流程与法律条款本身的特点决定的,也是适用法条推荐中时常遇到的问题,在模型训练时优化难度较高.
由图3可知,在数据集2的离婚案由中,共计36个要素,平均每篇裁判文书被标注了1.00个标签.诈骗案由中,共计32个要素,平均每篇裁判文书被标注了3.03个标签.数据集2同样存在数据不平衡的问题,但相较于数据集1已经得到明显改善.
大部分现有经典分类数据集的正负标签比例以及标签数量更为均衡.例如:ChnSentiCorp_htl_all④数据集包含7 000多条评论,正向评论约占5 000条,负向评论约占2 000条;Simplifyweibo_4_moods⑤数据集包含了36万条数据以及4类情感,“喜悦”约占20万条,“愤怒、厌恶、低落”各约5万条;今日头条新闻数据集⑥共计约38万条,15个标签,其中正样本占比低于10%的仅有1类.
从统计的角度来讲,随机抽取裁判文书是合理的,但是作为针对深度学习的数据集而言,抽取的裁判文书仍然存在样本分布不均的问题,部分要素在训练过程中仍会面临正样本过少的问题;这是在训练模型时需要解决的主要问题.
2.2 模型选择不均衡数据集是深度学习模型训练中的难点之一.2019年,Geng等[15]将带有Self-attention的Bi-lstm块对输入文本进行编码,从而将Few-shot方法与Attention进行结合,缓解了不均衡数据集带来的困难.基于此,本文将使用基于BERT的语言模型,来训练法律事实与要素之间的对应关系.
Attention是BERT中最为核心的机制.在BERT中,Attention机制负责实现特征提取,并取代了RNN与CNN.首先对于输入的句子,BERT会对其进行编码,其值为词向量信息、句子分割信息以及词位置信息的和.其中,词向量信息(token-embeddings)是根据词表生成,句子分割信息(segment-embeddings)根据中文中的逗号以及句号进行分割.BERT的词位置嵌入信息(position-embeddings)在编码中的公式如下:
(1)
(2)
词向量维度dmodel取32,即每个单词的位置信息将被编码成32维的向量;pos最大值取值为100,即在这个句子中共计100个单词.可以观察到,不同位置的词对应的向量存在差异,词语在句子中的位置信息被很好地记录下来.最终,针对段落的编码可以写为
Tensor_embedding=
Token+Segment+Position.
(3)
在一个Attention层中内置了WQ、WK、WV这3个可训练的矩阵.当一段文本以Tensor的形式进入Self-attention层中后会以矩阵相乘的方式生成对应的Q、K与V,最后通过上述公式计算得出Attention层的输出矩阵Z.
Q=Tensor*WQ,
(4)
K=Tensor*WK,
(5)
V=Tensor*WV,
(6)
(7)
(8)
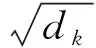
注意到在(3)式中生成Tensor_embedding时,3个embedding的模长均为1,故(7)式中QKT的大小可以表示该Attention块中输入的query与key的关联程度,其值越大代表两者关联度越高.最终Self-attention输出的矩阵Z记录了一个句子中各个单词与句内其他单词的关联度,不同于传统的NLP语言模型,BERT主要在以下方面进行了创新:1) 使用了双向Transformer连接,增加了句段中各个句子前后的联系,使得模型能够捕捉上下文信息;2) 支持模型预训练,能针对不同的下游任务更针对性地优化模型;3) 支持通过遮蔽语言模型来挖掘和搜索文本序列内部的隐藏关系;4) embedding方面选择了词向量嵌入信息(token-embeddings)、句子分割嵌入信息(segment-embeddings)以及词位置嵌入信息(position-embeddings)3部分构成.
虽然BERT在NLP领域中大部分数据集上刷新了精度,但Attention机制存在局部信息捕捉过弱的隐患.由于实际计算能力的限制,当句子超过一定数量时多出来的词将被程序忽略掉.目前,NLP领域中大部分实验也是将BERT与RNN、CNN等思想结合.
与文献[16]类似,本文实验选择了BERT中的Position-embedding,并分别在BERT后接入了Bi-LSTM、RCNN、RNN与LSTM进行了对比.通过将BERT提取的特征输入后续模型,进行进一步特征提取.
2.3 模型预训练本文针对不同案由进行了预训练.在预训练中,BERT将使用无标注数据记录不同案由下的语义特征.分别使用数据集1中的离婚裁判文书与诈骗裁判文书的法律事实部分形成无标记数据,构建了2个不同案由下的预训练模型.不同领域的法律事实主要涉及的词语差异较大,预训练后模型在不同案由下的针对性更强.
本文将数据集2中90%划为训练集、5%划为测试集、5%划为预测集,并根据案由的不同加载训练集1中得出的预训练模型,训练本文案件事实与要素的对应关系.
3 “要素-法条”模型训练与优化
3.1 评估指标与模型参数选取考虑到BERT使用的Attention机制存在局部信息捕捉弱的风险,本文在BERT后分别接入了RCNN、Bi-LSTM、RNN与LSTM,并使用数据集2中的训练集与测试集进行训练,对模型在预测集上的表现进行评估.
评估指标使用的是宏平均下的F1分数,即准确率P(precision)与召回率R(recall)的调和平均.首先,准确率与召回率的计算公式为:
(9)
(10)
其中,TP(truepositive)表示预测为正且实际也为正的样本,FP(falsepositive)表示预测为正实际为负的样本,FN(falsenegative)表示预测为负实际为正的样本.宏平均下的准确率与召回率如下:
(11)
(12)
其中,Si表示第i的标签的正样本数量总和,n表示标签总数,{Si|i=1,2,…,n}表示全体标签所组成的集合.接着对宏平均下的准确率与召回率求调和平均即得宏平均下的F1分数
(13)
本文实验的软件环境为Ubuntu 20.04.3,代码基于Tensorflow(版本1.13.1)进行开发.在训练超参数设定上,选择文本分类任务常用预设初始值,BERT向量化维度设为768,读取字符最大长度为512,训练最小批量为128,迭代epoch次数为40,学习率指数采取衰减策略,损失函数选择如下公式[17]
Focal_loss=
(14)
其中,p表示模型输出的预测概率值,y为真实数据(真则y=1,否则y=0),α的取值决定了模型对正样本的关注程度,γ的取值决定了模型对难分类样本的关注程度.
相较于传统的交叉熵损失函数,Focal_loss在不均衡数据集、难分类样本上的表现更好,适合作为本文训练案件事实与要素关系的损失函数.本文直接使用BERT模型进行训练,关于Focal_loss中α取值进行了实验,在(0,1)上以0.05为步长分别验证了模型精度,最后发现α=0.4、γ=2时,模型在数据集1与2上均有较优的表现,后续研究将以此为基础.
3.2 分类器优化从上述分析中可以发现不同要素之间分布不均,这是法条推荐任务必须解决的难题.在实验中发现由于数据集中正样本比例偏少,模型输出的预测值往往低于0.5,这干扰了模型在大部分标签上的判断.针对这一情况,本文采用阈值移动对模型训练过程进行了优化.
阈值移动是指在模型训练过程中,使分类器中预测阈值被调整为超参数录入模型.语言模型执行分类任务时将会针对每一个标签输出一个概率值,当概率值大于某一个阈值时模型输出为是,反之为否.在模型训练结束后,模型会在测试集上进行预测.加入了阈值移动的模型将针对每个标签在0至1之间以F1分数作为指标筛选阈值,并记录下模型在测试集上的表现,最终对每个标签筛选出最合适的阈值.本文以0.01为步长进行筛选,并将筛选的结果以超参数的形式录入了模型.例如在诈骗案由中,标签“累犯”的阈值为0.33(模型预测“累犯”的概率值大于0.33,则输出为是).以诈骗案由为例,部分标签的阈值见表2.观察可知由于数据集正样本比例较少,多数标签最佳阈值均为0.5以下.显然若以0.5为阈值的话,模型在大部分标签上的表现都会受到影响.
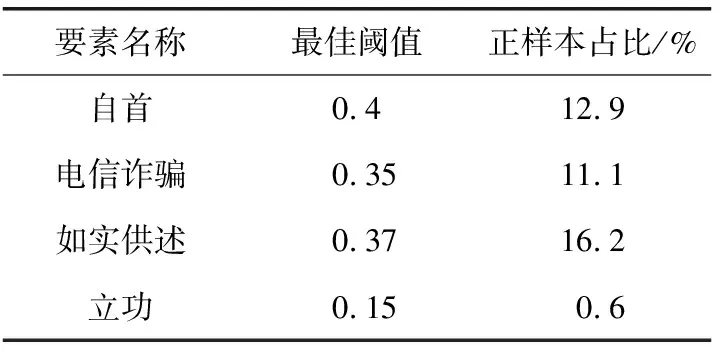
表 2 部分标签最佳阈值与正样本占比
除此之外,由于训练数据系从裁判文书网上随机取样,与法院受理案件有极高的相关性,故针对每个要素的最佳阈值录入模型后对之后模型投入实际使用具有积极的影响.
表3为不同模型在2个案由下F1分数.观察可知,离婚案由表现最好的模型为BERT+RCNN,诈骗案由表现最好的模型为BERT+Bi-LSTM.首先,本文尝试了SVM、RNN与LSTM,其中词嵌入部分与后续实验相同,均包含位置信息;同时对比了fastText(实验方法与参数设置见文献[11]);加入了BERT部分后,模型表现均优于机器学习模型.
之后尝试了BERT和BERT后接单向或双向语言模型.其中,BERT后接入LSTM与RNN后表现会降低,且与fastText不相上下.BERT后接入双向语言模型后模型表现会得到稳定的提升.
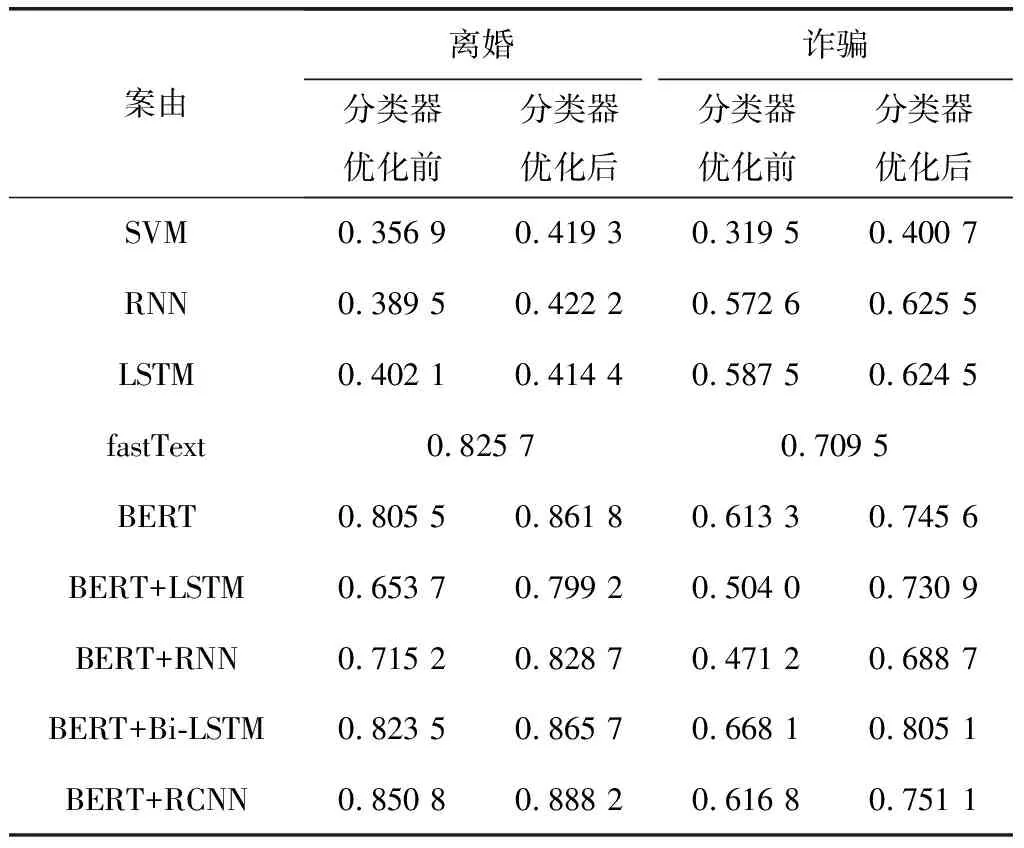
表 3 不同模型在各个案由下的F1分数
分析表3可以得到以下结论:
1) RCNN与Bi-LSTM均为双向模型,LSTM与RNN均为单向模型.BERT后接入双向模型可提升模型表现,均优于BERT本身.这可能是BERT使用了双向Transformer结构,单向的语言模型会对BERT提取的特征造成干扰,而双向的语言模型能一定程度上弥补BERT使用Attention机制带来的风险.
2) 分类器优化后模型表现均能得到大幅度提升.由于数据集正样本比例较少,对于正样本少的标签模型输出的概率值往往会偏低.对分类器进行优化后可以显著地改善这个问题.
4 要素标注模式与传统模式对比
完成以上工作后,输入案件事实的文本,首先通过分类模型得到对应的要素,再基于事先建立的要素与法条的对应关系实现适用法条的推荐.由于要素-法条对应关系是法学专业人员人工整理建立,可以认为这一步没有误差,从而表3要素推断的F1分数值即可以作为最终法条推荐的精度衡量指标.
接下来讨论要素标注模式与传统法条推荐模式的对比.
4.1 评估指标与数据集选取本文以宏观下的F1分数作为评估指标,同时为了控制变量,只选取要素所对应的法条的集合进行计算,即离婚案由中24个与诈骗案由中的19个法条.
本文从数据集1中2个案由分别抽取1%的数据,分别对其使用传统法条推荐与“要素-法条”推荐模型.其中“要素-法条”推荐模型在不同案由上根据表3选择精度最高的模型.
4.2 实验结果与样本案例展示经过实验得知:在离婚与诈骗案由中,传统法条推荐F1分数分别为0.760 9与0.735 7,“要素-法条”推荐模式分别为0.821 1与0.761 6,高于传统法条推荐,在庭审辅助系统中能有更高的精度.
除此之外,要素标注模式具有更好的适应性.2021年,《中华人民共和国民法典》正式施行,婚姻法、继承法、民法通则、收养法、担保法、合同法、物权法、侵权责任法、民法总则同时废止,文本学习推荐模式的模型将需要重新训练;而要素标注推荐模型不需要重新训练,只需修改要素所对应的法条,即可继续投入使用.
5 结论与展望
本文使用基于BERT的语言模型,以数据集1作为语料库对模型进行了预训练.在此基础上使用数据集2中的要素标注数据训练了要素推断模型,极大改善了传统法条推荐任务中标签数量过多的难题,取得了更高的法条推荐精度,并且能够根据案件事实文本推荐具有针对性的地方法规和司法解释.同时本文实验探索了BERT与传统语言模型的契合度,并在数据不均衡问题上寻找了一种可能的改善方案.
本文研究的要素在法学上不仅与适用法条相关,还与涉案证据等庭审因素有类似的对应关系,后续研究将尝试把要素推荐模型运用到智慧法院建设的其他场景中,以充分发挥该模式的最大价值.
注释
① 中国裁判文书网地址:https://wenshu.court.gov.cn/.
② 《婚姻法》于1981年起开始实行,2021年1月1日废止,同时《民法典》实行.
③ 标注数据集样本示例地址:https://github.com/OpenWaygate/Law-article-recommendation.
④ChnSentiCorp_htl_all数据集下载地址:https://raw.githubusercontent.com/SophonPlus/ChineseNlpCorpus/master/datasets/ChnSentiCorp_htl_all/ChnSentiCorp_htl_all.csv.
⑤Simplifyweibo_4_moods数据集下载地址:https://pan.baidu.com/s/16c93E5x373nsGozyWevITg#list/path=%2F.
⑥ 今日头条新闻数据集下载地址:https://github.com/aceimnorstuvwxz/toutiao-text-classfication-dataset.
猜你喜欢
邯郸学院学报(2022年2期)2022-07-05
今日农业(2022年2期)2022-06-01
法律方法(2021年3期)2021-03-16
民主与法制(2020年19期)2020-08-24
民主与法制(2020年16期)2020-08-24
安徽警官职业学院学报(2020年6期)2020-07-21
西夏学(2019年1期)2019-02-10
职工法律天地·下半月(2017年10期)2017-09-23
进出口经理人(2017年8期)2017-09-13
法制与社会(2016年32期)2016-12-01
