
基于多维缩放和KICIC的电力负荷聚类
2023-03-15 09:07刘诗语吴鸣李睿哲
科学技术与工程 2023年3期
刘诗语,吴鸣,2*,李睿哲
(1.上海电力大学电子与信息工程学院,上海 200090;2.中国电力科学研究院有限公司,北京 100192)
随着智能电网的建设,电力系统的智能化程度逐渐提升,电力负荷数据变得易于感知和测量,由此累积的用户负荷数据具有高维度、多类型和大体量等特点[1]。通过负荷数据挖掘和用电模式识别,获取用户用电特征,为电网规划设计、用电客户精细分类和制定用电计划提供有力支撑[2-3]。
聚类算法可以有效提取用户用电的负荷特征,充分挖掘用户用电信息,发掘其中的相似点以用来分析用户用电模式[4]。目前,各种聚类分析方法已被应用于电力负荷聚类中,包含基于划分[5]、基于密度[6]、基于层次[7]的聚类算法等。如今,不少学者都使用欧式距离作为相似性判据进行负荷曲线的聚类研究。文献[8]通过奇异值分解的方式将原始负荷数据进行变换旋转至新坐标系中,进而得到对应的奇异值并以此确定负荷数据降维的权重大小,最后利用加权K-means方法进行聚类。文献[9]对负荷数据进行多维分析和降维,然后采用高斯混合模型提取数据的低维特征,以用于海量化负荷数据集的聚类研究。文献[10]采用卷积自编码器提取负荷数据的时序特征,再用自定义的聚类层对低维特征软化分,最后采用KL(Kullback-Leibler)散度作为损失函数对卷积自编码器和自定义聚类层进行联合优化,得到聚类结果。文献[11]对原始负荷数据提取,得到日峰谷差率、日负荷率、日最大利用时间等7个日负荷特征指标,使用熵权法对各指标配置权重进行聚类分析,从而提高聚类效率。文献[12]通过多维缩放(multi-dimensional scaling,MDS)对原始电力负荷数据进行非线性降维进而获得低维数据特征,对低维特征进行加权K-means聚类,进而获得聚类结果。然而,海量化和高维化的负荷数据往往存在模糊的簇边界,上述方法只考虑簇内距离判断簇相似度,而忽略簇间距离的影响,导致聚类质量较低。由于存在簇间模糊样本,也可能会增加聚类算法的迭代次数,进而降低计算效率。
鉴于以上方法仅考虑簇内距离,而忽略簇间模糊样本导致聚类质量下降等问题,有学者提出考虑簇内、簇间距离的聚类方式并获得不错的进展。文献[13]提出增强的软子空间聚类方法,该方法扩大簇间距离的方式是最大化全局中心与各个簇中心的距离。但该方法移动簇中心的效果较差,最大化全局中心与每个簇中心的距离并不等同于最大化簇间距离,即最大化任意两个簇之间的距离,当簇间分布不均匀时会反而会导致几个相近的簇中心更紧凑。
针对以上问题,现提出基于多维缩放(MDS)和KICIC(a weightingK-means clustering approach by integrating intra-cluster and inter-cluster distances)的聚类算法,通过MDS对原始数据非线性降维提取原始数据的低维特征,将获取的低维特征矩阵和归一化的特征向量作为输入,再通过KICIC算法最大化簇间距离和最小化簇内距离来对日负荷曲线进行聚类。对此,通过将改进的算法和传统算法在聚类有效性指标上对比分析,以期能够在聚类效率和质量方面得到提升,为在需求侧实现有序用电管理做准备。
1 聚类算法的基本理论
1.1 MDS的数学理论
假设给定一个由m条负荷曲线和n维数据所构成的X=[X1,X2,…,Xm]为m×n阶实矩阵,其中第i条负荷曲线表示为Xi=[xi1,xi2,…,xin],n为负荷曲线的数据维度,由此可以计算出n维数据的距离矩阵D=[tij]∈Rm×m。MDS算法是为获得原始数据样本在d′维空间的表示,Z∈Rd′×m,d′≤n[14]。Z=[Z1,Z2,…,Zn]是n×m的数据输入矩阵;Zi=[zi1,zi2,…,zim]表示第i个数据对象。
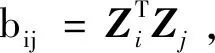
(1)
(2)
(3)
(4)
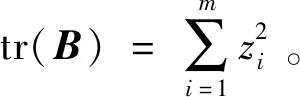
(5)
(6)
(7)
将式(2)~式(7)代入式(1)可得
(8)
由式(8)可计算内积矩阵B,对矩阵B进行特征值分解,即
B=VΛVT
(9)
式(9)中:Λ=diag(λ1,λ2,…,λd)是内积矩阵B的特征值所组成的对角矩阵,对应的特征值由大到小排列,V是对应的特征向量矩阵。由式(9)及B=ZTZ可知
(10)
具体算法步骤如下:
步骤1对于给定的数据集矩阵X,求得距离矩阵D∈Rm×m,同时确定低维空间的维数d′。
步骤2以距离矩阵D∈Rm×m的元素tij为输入,通过式(5)~式(7)计算出结果并代入式(8)求内积矩阵B。
步骤3对内积矩阵B做特征值分解B=VΛVT,取Λ=diag(λ1,λ2,…,λd)前d′个最大的特征值构成对角矩阵Λd′,Vd′为相应的特征向量矩阵,通过式(10)求低维矩阵Z。
1.2 KICIC聚类算法
传统聚类算法一般采用簇内欧式距离作相似性判据。然而,实际的负荷数据往往存在模糊的簇边界。如图1所示,簇边界处的数据可能会产生误分,进而降低聚类质量。由于存在簇间模糊样本,也可能会增加聚类算法的迭代次数,降低计算效率。
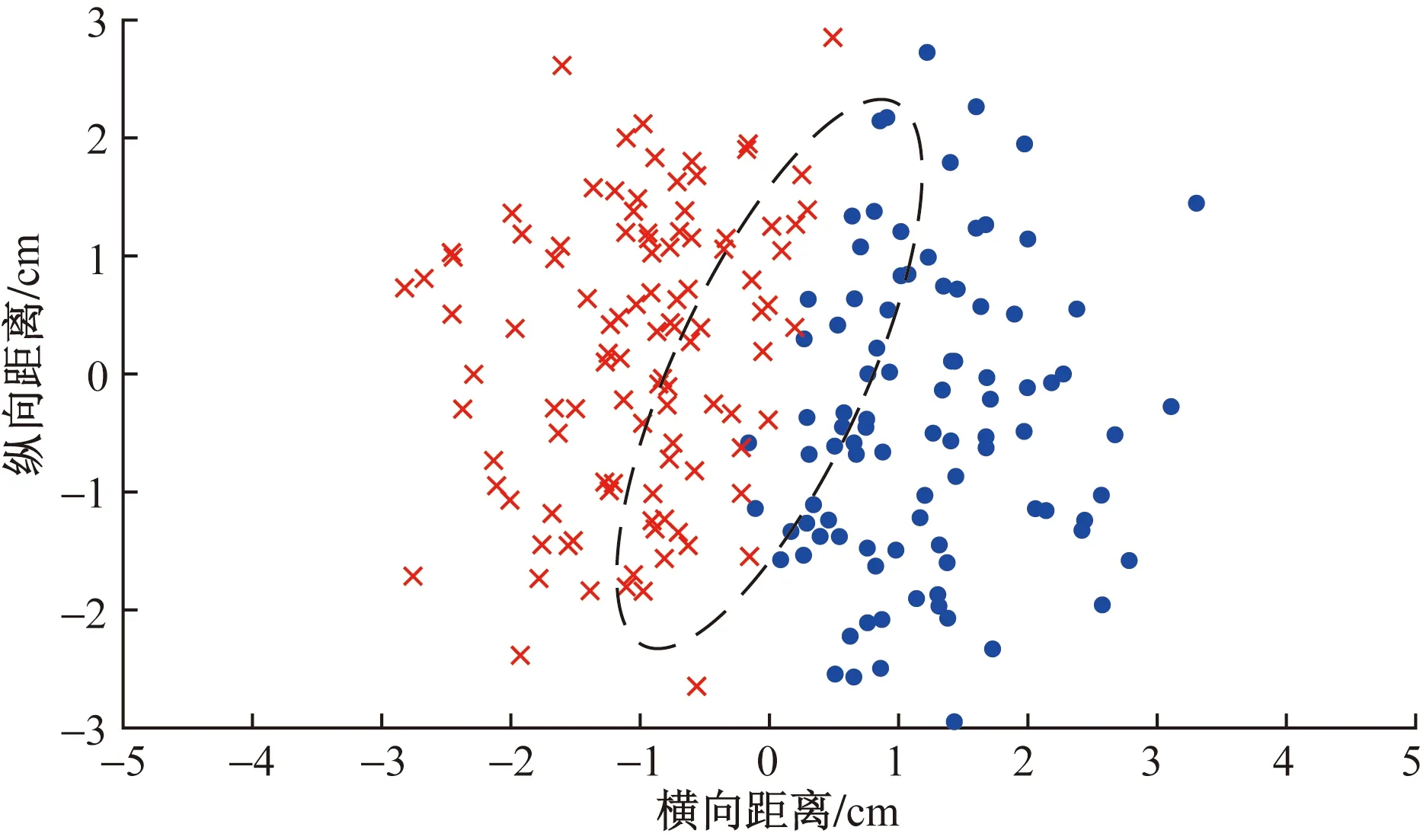
图1 簇间样本模糊图Fig.1 Inter-cluster sample fuzzy map
对此提出集成簇内距离和簇间距离的KICIC聚类方式,该聚类方式通过在子空间内最大化簇中心与其他簇样本的欧式距离的方式对簇间距离最大化,同时对簇内距离进行最小化处理以提升簇内紧密度,基于该思想设计了该算法的目标函数,然后,通过迭代优化目标函数获得算法的更新规则,最后,根据更新规则给出了算法的执行过程。KICIC算法的目标函数为
S=S(U,W,R)
(11)
约束条件为
(12)
式中:R=[R1,R2,…,Rk]为k个簇中心向量组成的簇中心矩阵,Rp=[rp1,rp2,…,rpm]为第p个簇中心;W=[W1,W2,…,Wk]为k个特征权重向量;U为数据对象分配矩阵,该矩阵为n×k的0-1矩阵,uip=1为第i个特征被分到第p个簇。
2 基于MDS-KICIC算法的电力负荷聚类分析
2.1 数据预处理
2.1.1 数据选取
本实验的数据集来源于SEAI(sustainable energy authority of ireland)发布的2009—2013年爱尔兰智能电表实测数据,该数据集以30 min为时间间隔,每日可采集48数据点。距今较近的2013年用户用电数据作为本文的实验数据。
2.1.2 异常数据的识别与修正
现实中采集的负荷数据,往往会出现环境因素干扰、测量设备故障、通信中断等问题,引起数据异常或丢失[15]。负荷数据异常或缺失不严重时,通过多阶拉格朗日内插法进行数据的矫正或填充,负荷曲线的数据缺失严重时则剔除该负荷曲线,如式(13)所示。计算某点数据相对前一点的数据变化率,若超过一定阈值则视为异常数据点,如式(14)所示,也可以用多阶拉格朗日内插法对该点数据予以修正。
(13)
式(13)中:x(t)为异常数据点的修正值;a1、b1为向前和向后所取的样本点数目,一般取4~6。
(14)
式(14)中:x(t)表示t时刻数据点,p表示该点的数据变化率,超过设定的变化率阈值p=0.75视为异常数据点,用多阶拉格朗日内插法对该点数据予以修正。
2.1.3 数据归一化处理
收集的不同用户负荷数据的幅值可能会有较大差异,对不同数量级的负荷数据直接聚类会使聚类结果缺乏可靠性。在本研究中,对此使用最大值归一化原理处理负荷数据。该处理方法的表达式为
(15)
式(15)中:xij是第i条负荷曲线的采样点j处的数据,x′ij为对应点的归一化数据,然后通过元素x′ij可获得归一化矩阵X′。
2.1.4 数据平滑处理
实际上,在负荷数据的测量和采集过程中常出现信号干扰和测量误差等情况会直接造成电力负荷曲线出现一定程度的波动,对数据进行平滑处理能减少噪声影响,更加突显曲线的走势。而高斯法能较好地滤除噪声,采用高斯法对数据进行平滑处理,进一步反映出曲线总体走势[16]。负荷数据预处理前后的变化见图2。
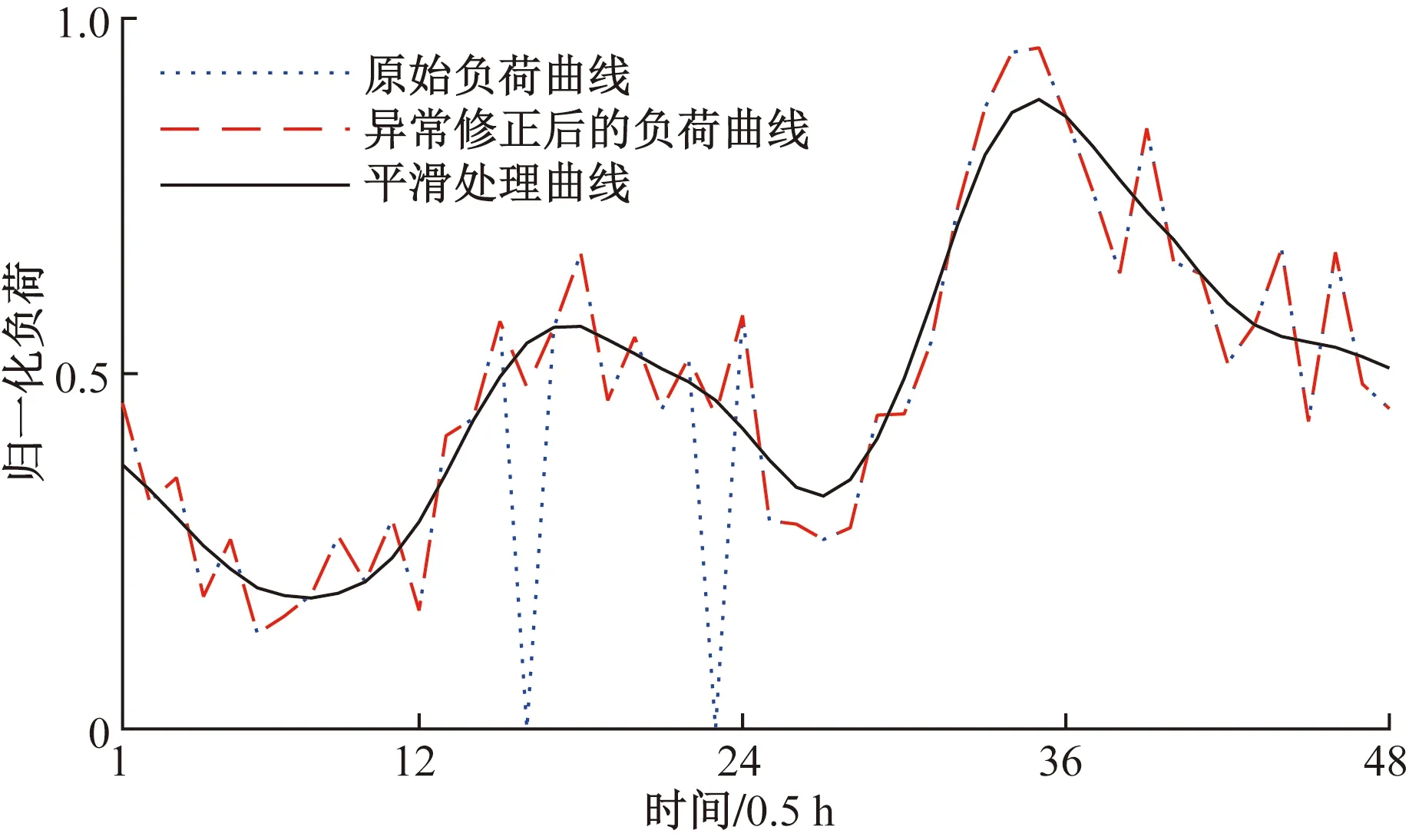
图2 负荷曲线的修正和平滑处理Fig.2 Correction and smoothing of the load curve
2.2 MDS-KICIC算法
不同于K-means等传统聚类算法,KICIC是集成簇内和簇间距离的新型聚类算法,该算法需要对目标函数进行迭代更新,因此,对于较大的样本量,KICIC算法计算过程复杂,易造成计算效率低下等问题,对此设计MDS算法对数据降维处理以提升KICIC算法的聚类效率和质量。基于MDS的理论可知,若降低到d′维空间中去,则取出前d′个最大特征值,这说明该维空间的权重可以通过对应的特征值大小体现。对此,使用MDS降维得到特征矩阵Z用作KICIC算法的输入,基于MDS方法得到的特征值λ归一化处理后作为KICIC算法的权重向量W,可以提高KICIC聚类算法的速度和性能。
2.2.1 MDS-KICIC目标函数
KICIC算法目标函数[式(11)]的第三项即为的特征权重项,由于特征权重向量W由MDS降维后已经给出,该项不参与迭代,可以对目标函数进行优化,表达式为
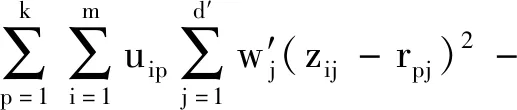
(16)
约束条件为
(17)
在该目标函数中,需要求解两个参数矩阵:数据对象分配矩阵U和簇中心矩阵R。常用的优化求解目标函数S的方法是固定其中一个参数矩阵,然后求解另一个参数矩阵。特征权重矩阵W已知,进而降低聚类计算复杂度。此外,MDS-KICIC算法使用降维得到特征矩阵Z作为输入,而不是高维的数据信息,从而提高算法分析海量数据能力。
目标函数的优化原则是通过不断迭代分配矩阵U和簇中心矩阵R的值使目标函数S达到最小。固定簇中心矩阵R,目标函数S(U,R)可以最小化当且仅当
(18)
可以看出,式(18)是把数据对象分配到带权距离最小的簇中。
固定数据对象分配矩阵U,目标函数S(U,R)可以最小化当且仅当
(19)
固定簇中心矩阵R,最优化目标函数(16)可得到式(18),同理固定分配矩阵U,最优化目标函数(16)可得到式(19)。
整体算法步骤如下:
步骤1对于给定的数据集X,经过MDS降维得到特征矩阵Z和特征值向量。
步骤2使用MDS降维得到特征矩阵Z和归一化处理后的特征值向量用作KICIC算法的输入和权重向量,并随机簇中心矩阵R。
步骤3固定矩阵R,通过式(18)得到分配矩阵U;固定分配矩阵U,再通过式(19)得到簇中心矩阵R。
步骤4迭代计算。计算目标函数(16)是否最小,若是则算法结束,否则重复步骤3。整体算法流程如图3所示。
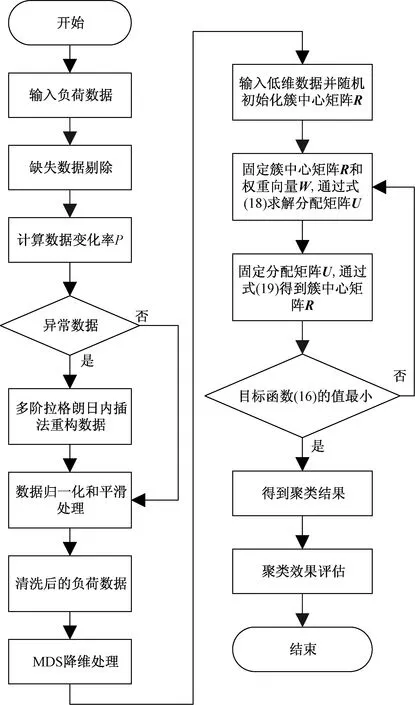
图3 整体算法流程图Fig.3 Overall algorithm flow chart
2.2.2 聚类有效性指标
由于文中所选的是无标签数据集,其类别未提前确定,需使用内部评价指标对聚类效果进行评判。本文选取戴维森堡丁指数(davies-bouldin,DBI)和卡林斯基-哈拉巴斯指数(calinski-harabaz index,CHI)分析聚类质量。簇内相似度越高,簇间相似度越低,则聚类质量越优。上述指标的计算公式如下。
(1)DBI指标。
(20)
(21)

(2)CHI指标。
s(N)=[trB(k)/(k-1)]/[trW(k)/(n-k)]
(22)
式(22)中:n为聚类样本的数目;k为聚类的类别数目;trB(k)为簇间离差矩阵的迹;trW(k)为簇内离差矩阵的迹。CHI是通过计算簇间分离度和簇内紧密度的比值得出,所以簇间越分散,簇内越紧密,CHI越大,得到的聚类质量越优。
3 算例分析
文章中的实验是在配置有AMD R5-4600H,CPU 3.0 GHz,RAM16GB的PC上实现的。为验证文中方法的有效性,以K-means算法、MDS-WK-means算法和KICIC算法作为文中的对比方法。
3.1 实际日负荷曲线聚类
文中数据来源于SEAI所发布的爱尔兰智能电表实际测量数据,共选取2013年某工作日1 346条日负荷曲线数据,每30 min进行一次采样,每条负荷曲线得到48个采样点。由于数据缺失或异常,预处理后得到1 229条数据曲线,进而形成1 229×48阶的数据矩阵。
MDS处理数据矩阵,降到d′维通过计算累计贡献率Sd′可得,d′≥4时累计贡献率Sd′可以达到95%以上。因此,输入矩阵X经过MDS降维处理后表示为一个1 229×4的特征矩阵Z,可求得4个维度对应的权重向量为W0=[0.585,0.337,0.049,0.029]。
通过对不同聚类数目的DBI指标观察,如图4所示,观测到DBI指标在聚类个数k=4时取得最小值。因而,文中的聚类个数选择k=4进行分析。
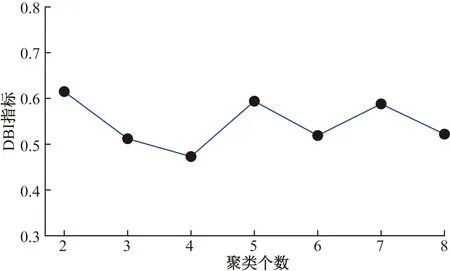
图4 聚类数与DBI指标的关系Fig.4 Relationship between the number of clusters and DBI index
基于文中聚类算法得到的聚类结果如图5所示。从00:00—24:00共计48个时间段,该算法将1 229条日负荷曲线分成4类。各类负荷曲线的数量分别为312、224、408和285。传统K-means聚类算法的各种负荷曲线数分别为306、224、406和293。文中方法的聚类结果如图5所示。

图5 聚类仿真结果Fig.5 Clustering simulation results
图6为4类用户负荷曲线的聚类中心,每类用户都有相异的用电特点,表现的四种类型依次有:双峰、平峰、单峰和错峰。第一类用户属于双峰型用户,有两个用电高峰,分别在7:00—11:30以及14:30—20:00,同时该类用户大部分功率都在高峰时间内消耗,该类用户多为学校、写字楼和机关单位等,用电稳定并且规律。第二类用户属于平峰型用户,该部分负荷水平相对较高且整日负荷变化不大,该类负荷属于保障类型负荷,多属于供水、供热、供能等基础设施。第三类是单峰型用户,在22:00—次日6:00属于休息时间,该时段的用电量较少,而该类用户的用电量主要集中在6:30—17:00,用电量提升较快并且处于较高负荷水平,该部分用户多为小工业用户。第四类用户属于错峰型用户,在18:00—23:00用电高峰,并且在凌晨时段仍有较高负荷,由于该部分用户用电时间多为晚上,这表明其用户可能有很大的潜力遵循需求侧管理策略来避免高峰期的用电行为。
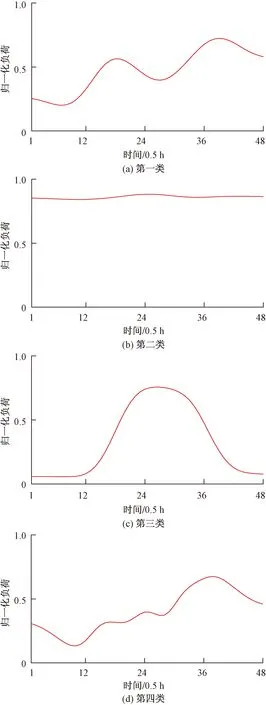
图6 典型日负荷曲线聚类中心Fig.6 Cluster center of a typical daily load curve
3.2 对比分析
通过对表1中10次测试得到的聚类指标平均值的对比分析,相较于直接进行聚类,其他三种算法在指标上更优,而MDS-KICIC算法比KICIC算法聚类效率提升了60.23%,比K-means算法聚类效率提升71.41%。本文所采用的算法使负荷的簇内距离最小,簇间距离最大,充分考虑簇内和簇间距离,使聚类中心尽可能地远离非类样本,降低非类样本的干扰,增加聚类精度,加快聚类迭代过程。
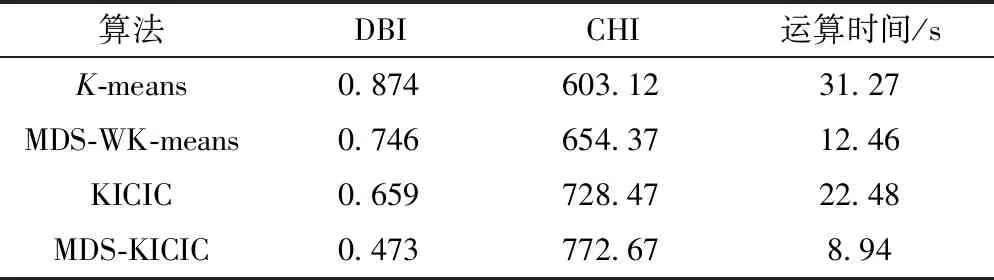
表1 4种算法聚类结果对比Table 1 Comparison of clustering results of 4 algorithms
因此,文中算法比传统的K-means、MDS-WK-means和KICIC算法运行时间更短,聚类质量更高。
3.3 聚类用户特征总结
结合表2可知,第一类用户属于双峰型用户,该部分用户的负荷系数、最小负荷率相对适中;在负荷系数和最小负荷率方面来看,第二类用户的数据均为最高,这表明第二类用户比其他类用户的需求侧管理潜力较小;第三类用户的负荷系数、最小负荷率最低,该类用户曲线相较于前两种更平滑,而且该类用户最小值时间和峰值时间与前者也有所不同;第四类用户的峰值时间不同,同时该类用户用电高峰多集中在夜间,这表明,相较于前三类用户,第四类用户需求侧管理的潜力更大。
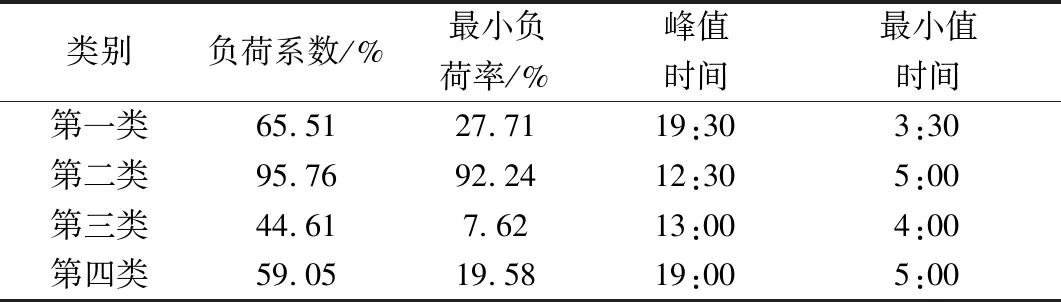
表2 典型日负荷曲线聚类中心特征总结Table 2 Summary of typical daily load curve clustering center characteristics
4 结论
(1)提出基于MDS-KICIC的电力负荷聚类方法,首先采用MDS降低负荷数据的维数,对负荷数据的低维特征进行提取,并通过特征值向量确定KICIC的权重向量,减少迭代计算的次数,最后结合KICIC算法获得最终聚类结果。算例研究表明,本文算法与传统的K-means、MDS-WK-means以及KICIC聚类方法相比,本文所提方法可充分考虑数据的簇内和簇间距离,进一步提高聚类的质量和效率,并对不同类簇的用户用电特征进行分析,有助于电网进行负荷建模、负荷特性模拟和需求侧响应等工作。
(2)通过本文方法对负荷类型分析可知,爱尔兰某地区存在4种不同的用电类型,分别是双峰型、平峰型、单峰型和错峰型,这也符合国内部分地区负荷曲线的走势。其中平峰型的需求侧管理的潜力较小,错峰型的需求侧管理潜力较大,错峰型用户更有利于解决不同类用户间的需求侧管理。
针对海量化的数据,考虑到高维数据同时具有不同类簇的特征,因此在后续的研究中可以通过对目标函数进行修改以适应复杂的簇结构,进一步提升算法的应用领域范围。
猜你喜欢
中学生数理化·中考版(2020年12期)2021-01-18
铁道通信信号(2019年6期)2019-10-08
活力(2019年15期)2019-09-25
中学生数理化·中考版(2018年12期)2019-01-31
小学生必读(中年级版)(2018年10期)2019-01-04
小学生导刊(2018年34期)2018-12-18
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
山东青年(2016年3期)2016-02-28
智能系统学报(2015年4期)2015-12-27
