
基于生成对抗网络与双注意力的糖网分类方法
2023-03-16 06:19郭妮妮乔钢柱张光华
中北大学学报(自然科学版) 2023年1期
郭妮妮, 乔钢柱, 张光华, 王 龙
(1. 中北大学 大数据学院, 山西 太原 030051; 2. 太原学院 智能与自动化系, 山西 太原 030032; 3. 山西智能大数据产业技术创新研究院 医疗健康大数据研究中心, 山西 太原 030006)
0 引 言
糖尿病是一种异质性代谢紊乱, 一直以来都是全球面临的巨大挑战, 预计到2045年, 全球糖尿病患者的数量将达到7亿[1]。 由糖尿病引起的眼科疾病有很多, 其中糖尿病视网膜病变(DR)就是最常见的一种, 眼底由正常到增殖性病变的DR图像如图1 所示。 正常的眼底图像中无任何异常; 轻度非增殖性病变(mild NPDR)的眼底图像中仅有微动脉瘤(MA)出现; 中度非增殖性病变(moderate NPDR)图像中含有存在程度轻于重度非增殖性病变(severe NPDR)的MA; severe NPDR图像中会出现视网膜内出血、 静脉串珠样改变、 微血管异常; 增殖性病变PDR图像中会出现较为严重的变化, 如新生血管形成、 玻璃体积血或视网膜前出血等。

图1 正常眼底图像和4类DR图像
延迟或预防糖尿病视网膜病变致盲的关键在于早期发现和适当治疗[2]。 虽然糖尿病视网膜病变在早期基本无症状, 但实际上此时视网膜神经的损伤和临床看不见的微血管变化都已存在[3], 这是糖尿病视网膜病变早期无法准确诊疗的原因之一。 此外, 由于眼科医生对DR的手动诊断费时费力, 且容易发生误诊, 也加大了视网膜病变早期诊断的难度。 因此, 引入计算机辅助诊断系统可以及时诊断病变、 避免误诊, 有效地管理病情进程, 减少治疗的成本、 时间和精力投入。
在一些公开的DR数据集中, 5个类别的DR图像数量不均衡是影响最终分类效果的原因之一。 如图2 所示, 在Kaggle, Messidor2, APTOS2019 3个数据集中正常眼底图像的数量与严重病变或增殖性病变的图像数量相差达到2个数量级, 间接影响了最终的分类效果。

图2 数据分布不均衡的3个DR数据集
为解决眼底图像数量少和人工诊断带来的问题, 研究者们提出了多种机器学习方法用于视网膜眼底图像分类。 如Harun等[4]利用人工神经网络训练Levenberg-Marquardt(LM)和贝叶斯正则化对视网膜病变数据分类, MLP(Convolutional Block Attention Module)网络显示的准确率为67.47%; Bodapati等[5]从多个预训练卷积神经网络模型中提取特征, 并使用提出的多模态融合模块将其混合, 用于预测糖尿病视网膜病变的严重程度, 得到的准确率为80.9%; Gangwar等[6]在Inception-ResNet-v2上添加了自定义的卷积块, 构建出了混合模型, 将准确率提高到82.18%; Al-Antary等[7]提出了多尺度注意力网络, 应用编码器网络将图像嵌入到高级表示空间, 通过多尺度特征金字塔描述不同位置的视网膜结构, 使用多尺度注意机制增强了特征的辨别能力, 最终准确率达到84.6%。 虽然这些算法都致力于通过各种方法提取病变特征, 提升分类效果, 但仍存在微小病变识别能力不足、 数据集未均衡处理等问题, 且在分类效果方面仍有很大的提升空间。
本文针对数据集不平衡、 分类效果不佳的现象, 提出一种AIDnet网络。 该网络使用迁移学习的方法对模型超参数进行初始化, 以加快网络收敛并减少过拟合的发生; 使用生成对抗网络(GAN)[8]生成更多的图像, 以平衡原始数据集; 引入双注意力, 在加强网络模型重点关注内容的同时, 增强特征区域的表征, 从众多的信息中选择出对DR分类任务更有用的信息, 提高模型分类的准确率。
1 方 法
1.1 迁移学习
在医疗领域研究中, 已标记数据的缺乏一直是研究者所要面对的一大难题。 由于训练样本过少, 容易导致训练过拟合, 影响模型的泛化能力, 无法达到预期的分类效果。 为克服因医学数据量少导致的此类问题, 迁移学习是目前使用较多的样本数据增广方法。
迁移学习是一种深度学习方法, 用于快速、 准确地训练卷积神经网络(CNN), 其思想类似于人们常说的举一反三, 基本思路是: 使用预训练, 把现有大型数据集上训练好的权重值作为初始值, 将它迁移到实际问题的数据集上再次训练并且微调参数, 相当于在预训练中进行学习从而得到一些基本特征, 如颜色或边框特征等, 达到提高准确率并节省训练时间的目的[9]。
近年来, 关于视网膜病变分类的模型有很多, 如并行的分支网络和串联的跳层连接网络, 通过多尺度特征融合提升网络的分类性能。 InceptionV3[10]网络中的Inception基本模块通过使用不同大小的卷积核提取不同尺度的特征, 通过拼接操作实现特征融合, 达到提升分类性能的目的。
1.2 生成对抗网络
生成对抗网络是利用两个相互竞争的卷积神经网络生成合成图像, 它的基本框架由1个生成模型和1个判别模型组成, 通过对抗过程来迭代更新所生成模型的性能。 判别模型的目标是降低D(G(z))出现的概率, 生成模型的目标是保证G(z)与x尽可能相近, 通过不断训练, 使二者在博弈中达到平衡。 原始GAN的生成器只能根据随机噪声生成图像, 至于这个图像是什么或它属于哪一类(即标签是什么)无从得知, 判别器也只能通过接收图像来判别其是否来自生成器。 而CGAN(Conditional Adversarial Network)[11]的主要贡献是在原始GAN的生成器和判别器的输入中加入额外信息, 如标签, 由1个潜在空间点和1个类标签作为生成器的输入, 生成与给定标签对应的图像。 鉴别器提供了1个图像和1个类标签, 由它决定图像是真还是假。 ACGAN(Auxiliary Classifier Generative Adversarial Network)[12]是一种CGAN, 它通过转换鉴别器来预测特定图像的分类标签, 而不是将其作为输入接收。 ACGAN稳定了训练过程, 并允许学习一种独立于类标签的表示来生成高质量的图像[11]。
1.3 注意力机制
在医学图像中, 往往会有许多无关的信息影响图像最终的分类。 在糖尿病视网膜病变5分类的任务中, 一些病变部分, 如渗出物、 微血管瘤、 玻璃体积血等, 微小特征在各类别之间很难被察觉, 这些具有微小差异的细粒图像是分类的关键。
近年来, 注意力机制在计算机视觉和医学领域中应用的研究颇多。 引入注意力机制后, 在模型训练过程中, 能够让模型在提取特征时自主地选择需要关注的区域, 对糖尿病视网膜病变的各类特征加以关注和学习, 以此获得更多有用的信息。 注意力机制就像临床医生那样专注于依据关键特征进行分类诊治, 加入到模型中可以对分类效果有所提升。
2 模型设计
2.1 网络结构
本文提出的AIDNet模型如图3 所示。 该网络主要由3部分构成, 第一部分是改进的ACGAN网络, 主要生成分辨率为512×512×3的轻度非增殖性病变(DR1)、重度非增殖性病变(DR3)和增殖性病变(DR4)图像, 第二部分是基础的InceptionV3网络, 最后一部分是双注意力模块。 基础的InceptionV3网络和双注意力模块共同构成分类网络。 AIDnet网络结合了Inception块中不对称卷积的优点, 以及DAM充分利用有效特征且能减少计算开销的优点, 使得最终的分类效果较现有方法有所进步。
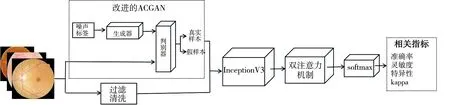
图3 本文提出的AIDnet模型
2.1.1 改进的辅助分类器生成对抗网络(Enhanced ACGAN)
生成器将数据大小为2 000的原始噪声和类别标签输入到ACGAN网络, 基本的ACGAN网络生成的图像大小为28×28×3。 为生成最终实验所需要的分辨率为512×512×3的图像, 生成器的网络结构首先在原来的生成器基础上加入步长为1, 卷积核大小为7, padding值为1的反卷积, 生成32×32×3的特征图, 进而再输入到4个转置卷积生成512×512×3的图像, 具体扩展见图4 所示。 生成器网络输入随机噪声和标签值, 并通过上采样层生成图像, 上采样层使用转置卷积算法, 噪声通过Reshape函数和激活函数变换成7×7×1 024的特征图, 经过多个反卷积层, 生成大小为512×512×3的图像。 在生成器模块实验中通过Embedding层进行融合, Embedding层类似于one-hot的形式, 利用其优势指定每个位置的值都是1个浮点数, 把输入映射到多维空间, 从而使得空间特征更加丰富。 判别网络的输入是512×512×3的图像, 图像通过下采样、 全连接层和LeakyRelu函数进行处理, 从而判别样本是真实样本还是假样本, 改进的CGAN网络详细结构见图5。

图4 在生成器原生成图上所作的扩展

图5 改进的ACGAN网络
由于ACGAN增加了类别, 所以加入了分类损失函数。 分类损失函数与判别损失函数分别对应判别器的两个输出, 两个损失函数加起来就是总的损失函数。 判别损失和分类损失的形式为
Ls=E[logP(S=real|Xreal)]+
E[logP(S=fake|Xfake)],
(1)
Lc=E[logP(C=c|Xreal)]+
E[logP(C=c|Xfake)],
(2)
式中:Xreal表示真实图片;Xfake表示生成器伪造的图片。
判别器的目标函数
L(D)=-Ex~PdatalogD(x)-
Ezlog[1-D(G(z|y))]-
Ex~PdataP(c|x)-EzlogP(c|g(z|y))。
(3)
生成器目标函数
L(G)=-Ex~PdatalogD(g(z|y))-
EzlogP(c|g(z|y))。
(4)
实验首先将正常图像和轻度NPDR图像作为训练数据集, 得到轻度NPDR图像, 以满足扩充图像数量的需要。 类似地, 正常和重度NPDR、 正常和PDR图像分别生成与重度NPDR和PDR相似的图像来扩充图像数量。 由于ACGAN网络需要的训练数据集较大, 重度NPDR和PDR图像数量有限, 故生成的图像数量和质量与轻度NPDR图像相差较大。
2.1.2 双注意力机制(Dual Attention Machine)
本文在backbone网络的全连接层之前加入双注意力机制(DAM), 其是在CBAM(Convolutional Block Attention Module)[13]模块基础上将通道注意力中的全连接共享层用一维卷积代替, 在一定程度上改善了之前数据计算量较大的问题。 DAM由两部分构成: 第一部分是通道注意力机制。 首先将输入的特征图F∈RC×H×W分别经过基于宽和高的全局最大池化和平均池化, 然后分别经过卷积核长度为k的一维卷积,k的大小由聚合领域内通道的数量决定, 计算公式借鉴ECAnet[14]。 将两部分输出的特征进行基于element-wise的相加操作, 再经由sigmoid激活, 生成最终的F1。 将F和F1按照元素作乘法操作, 生成空间注意力模块需要的特征F3。 具体的通道注意力模块计算过程为
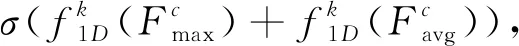
(5)
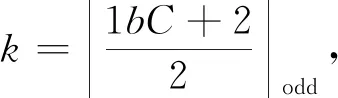
(6)
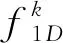
第二部分是将通道注意力模块输出的特征图作为本模块的输入特征图, 即F1。 首先做的是基于通道的全局最大池化和平均池化, 将两个二维向量基于通道做拼接操作后进行卷积, 降维为1通道, 经过sigmoid生成二维空间注意力F2∈R1×H×W, 具体空间注意力模块的计算过程为
F2=σ(f7×7([GMP(F1)];[GAP(F1)]))=

(7)
最后将空间注意力和F3按元素相乘, 得到最终生成的特征。 双注意力网络详细结构如图6 所示。 因其轻量级的特性, 与InceptionV3网络进行集成有利于从多方位、 多角度对特征进行提取。

图6 双注意力网络(DAM)
2.2 损失函数
损失函数用来评估模型预测值与真实值之间的不一致程度, 损失函数的值越小, 证明模型的鲁棒性越好。 样本数量较少的类别往往是分类中需要关注的重点。 在模型训练过程中, 不同类别之间的数据存在着较大的数量差距, 如本文使用的开源数据集, 模型所关注和学习的总是样本数量较多的类别, 导致对少数类样本的拟合过差, 进而无法得到准确的分类结果。 使用focalloss代替交叉熵解决类别不平衡的问题,focalloss定义式为
Lfocal loss=-αy(1-y′)γlogy′-
(1-α)(1-y)y′γlog(1-y′),
(8)
式中: 参数α用于平衡正、 负样本对损失值的影响;y为实际类别;y′为类别预测值;γ是一个正的可调参数, 它能够自适应地调节样本被减权重的速率, 使模型更多地关注不易区分的样本, 减少容易区分的样本的影响。
focalloss可以自适应地改变难分类的样本和易分类样本在损失函数里的权重, 解决严重的样本不平衡问题, 而且不需要计算复杂的权值映射,使模型能够更好地捕捉图像特征。
3 实 验
3.1 数据集与评价指标
Kaggle Eye-PACS数据集由Eye-PACS(https://www.kaggle.com/c/diabetic-retinopathy-detection/overview)提供, 于2015年在Kaggle上公开, 共有35 126幅训练图像和53 576幅测试图像。 数据集由专业的临床医生根据糖尿病视网膜病变的严重程度对每张图像进行了0级~4级的分类, 分别为正常, 轻度、 中度、 重度非增殖性DR和增殖性DR。 其中正常图像25 810幅, mild NPDR图像2 443幅, moderate NPDR图像5 292幅, severe NPDR图像873幅, PDR图像708幅。
Messidor2数据集是由Messidor计划合作伙伴提供的公开数据集, 包括1 748幅视网膜图像, 其中4幅图像未被定级, 其他图像被分为0级~4级 5个DR阶段。 1 744幅图像中, 正常图像1 017幅, mild NPDR图像270幅, moderate NPDR图像347幅, severe NPDR图像75幅, PDR图像35幅。 相较于Kaggle数据集, Messidor2数据集样本量较少。
3.1.1 数据预处理
预处理是提高图像质量的基本操作, 因为低质量的图像会产生不适当的结果, 从而降低精度。 将预处理后的数据作为训练的数据样本, 有利于更好地对眼底图像进行分类。 原始眼底图像会有多余的黑色背景, 利用中值滤波去噪, 将其转为灰度图, 设置阈值生成掩膜, 通过OpenCV中的findContours函数检测眼底对象的轮廓, 进而生成轮廓的最小矩形框, 裁剪去除黑色区域。 将去除黑边得到的图片分为3个通道, 对各个通道进行阈值化处理, 最终将其合并输出, 得到有更加明显病变特征的图, 如图7 所示。

图7 原始图像的初步处理
3.1.2 数据增强
两个数据集中健康的眼底图像数量远远多于病变的眼底图像数量, 在网络训练的过程中加入数据增强的操作有助于在一定程度上减弱数据集的不平衡, 降低过拟合的风险。 本文数据增强的方法是: 随机水平垂直翻转, 按中心点随机旋转90°, 按照一定尺度和比率随机裁剪出512×512的图片, 增加明亮度与对比度。
3.1.3 评价指标
使用准确率(Accuracy)、 特异性(Specificity)、 敏感性(Sensitivity)以及kappa系数来评价本文方法的性能[15]。
准确率(Accuracy)表示对于给定的测试数据集, 预测正确的样本数占样本总数的比例。
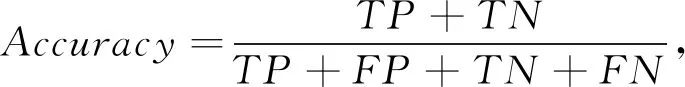
(9)
式中: 变量TP表示正确预测正样本的数量;FP表示将正样本错误判断为负样本的数量;TN表示正确预测负样本的数量;FN表示将负样本错误判断为正样本的数量。
特异性(Specifificity)是指在实际是阴性的样本中, 预测为阴性的样本的比例, 特异性的值越大说明“误检”(FP)越少。
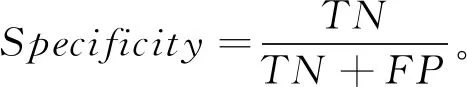
(10)
敏感性(Sensitivity, 也称召回率Recall)用来表示在实际为阳性的样本中正确判断为阳性的比例, 敏感性的值越大说明“漏检”(FN)越少。

(11)
Kappa系数的计算是基于混淆矩阵的, 是一种衡量分类精度的指标, 其计算公式为
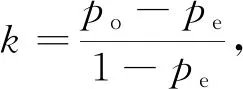
(12)
式中:po等于每一类正确分类的样本数量之和除以总样本数, 即总体分类精度。 假设每一类的真实样本个数分别为a1,a2,a3,…,ac, 而预测出来的每一类样本数分别为b1,b2,b3,…,bc, 总样本个数为n, 则有

(13)
3.2 ACGAN实验
将过滤后的数据集输入到ACGAN网络进行训练, 在GPU为GeForce RTX 2080 Ti的服务器上进行实验。 Inception Score (IS)是ACGAN的评价指标之一, IS评价指标越大, 说明p(y|x)与p(y)的分布的差异越大。
IS(G)=exp(Ex~pgDKL(p(y|x)‖p(y)))。
(14)
首先, 在数据集中提取正常、 轻度、 重度和增殖性DR 4个层次的图像, 并分别使用3个网络进行训练。 这3种模型用Adam优化器和交叉熵损失函数训练了4 000次。 其次, 依据在ImageNet训练的InceptionV3进行测试, 得到每一模型的Inception分数, 保存最佳的生成模型参数, 并利用生成图像的代码随机生成1 000幅图像。 由于重度NPDR和PDR图像的数量过少, 需在这两个模型上进行多次生成。 由最高Inception Score和人工筛选确定出最终模型生成的3类眼底图像如图8 所示, 前2列为Kaggle数据集中的眼底图像, 后3列为生成器生成的图像。

图8 真实图像与生成图像
由于目前GAN网络存在研究的局限性, 对于GAN网络生成的图片还没有一个权威且实用的评价指标。 本文根据训练过程中最高的Inception Score指标来确定模型, 分别生成32幅眼底图像, 再通过人工筛选的方法将扩充图像和真实图像进行比较, 筛选出最终的模型, 并生成相应类别的图像。 原始数据集眼底图像数量和由ACGAN网络清洁扩充后得到的数据集眼底图像数量如图9 所示, 清洁扩充后的数据集中, 原样本图像数量与扩充图像数量的比例分别约为: 1∶0, 5∶6, 1∶0, 1∶5, 1∶6, 可以看出, 在重度NPDR与PDR的类别中, 生成样本数占比较大。
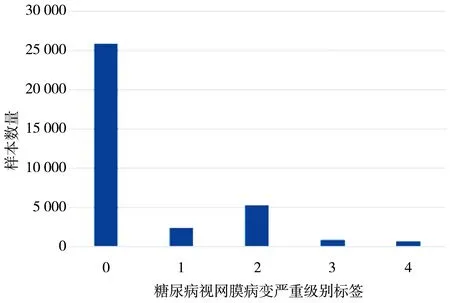
(a) 原始Kaggle数据
3.3 Kaggle数据集的实验结果
本实验使用SGD优化器和焦点损失函数, 初始学习率设置为0.001, weight-decay为1×10-4, momentum为0.9, 采用pytorch框架。 使用焦点损失函数的原因是使用该函数得到的准确率(0.881 5)高于交叉损失熵函数的准确率(0.879 8)。
将Kaggle数据集按照8∶1∶1的比例划分, 分别在VGG、 Resnet和InceptionV3网络3个基础模型上进行分类训练, 结果见表1。

表1 基础分类模型结果对比
由表1 可知, InceptionV3的准确率为0.881 5, 高于其他2个模型, InceptionV3在分类效果上具有一定的优势。 在3个基础模型中分别引入CBAM、 DAM, 进行参数增量和准确率的对比实验, 结果见表2。

表2 加入注意力模型的参数增量和准确率结果对比
由表2 可知, 3个模型引入CBAM后参数增量均明显高于引入DAM的参数增量; 在Resnet网络上引入DAM较引入CBAM的准确率有所下降, 在InceptionV3网络中引入DAM的准确率较基础模型提升了0.97百分点, 较引入CBAM模型提升了0.22百分点。
将平衡后的Kaggle数据集按照8∶1∶1的比例划分出训练集、 验证集和测试集。 根据数据集中各级的个数及比例, 选取20 736幅图片作为训练集, 2 592幅图片作为验证集, 剩余图片作为测试集, 输入到InceptionV3网络进行图像分类, 实验结果见表3。
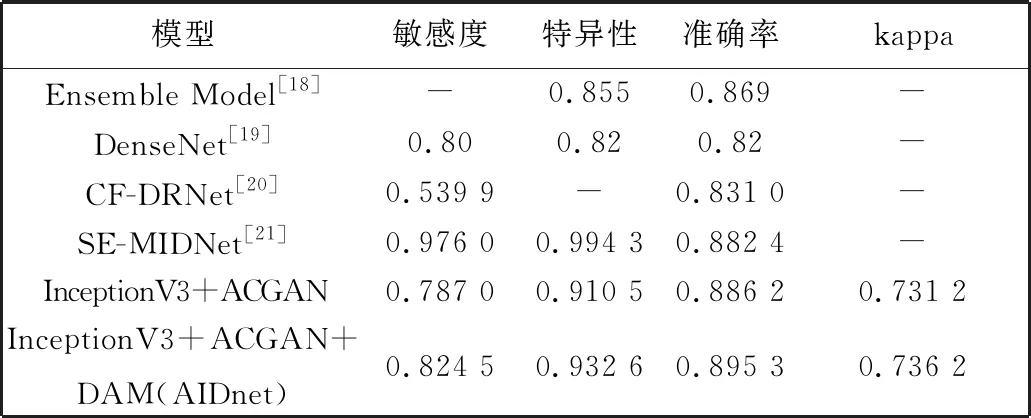
表3 Kaggle上的分类结果对比
与表1 中的InceptionV3模型数据比较可得, 数据集平衡后的准确率提升0.47百分点, 敏感度下降0.12百分点, 数据集平衡前后的损失曲线如图10 所示, 图中平滑度数设置为0.6。 由图10 可见, 验证损失曲线趋于平缓, 表明参数达到局部最优。
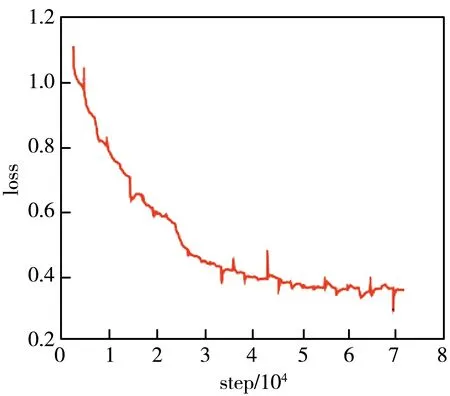
(a) 数据平衡前的训练损失曲线
3.4 Messidor2数据集上的实验结果
为进一步评估性能, 将本文所提出的方法应用于另一公开数据集Messidor2进行糖尿病性视网膜病变分级。 由于Messidor2只有1 744幅图像, 对于训练CNN来说, 图像的数量比较少, 所以先在InceptionV3上进行预训练, 冻结前后参数, 训练全连接层。 在训练过程中采用的训练验证数据比为8∶1, 并训练30个批次。 本文方法与文献[22]方法的分类结果对比见表4。 可以看出, AIDnet网络在Messidor2数据集上的敏感度更高, 且准确率为 0.903 1。

表4 Messidor2上的分类结果对比
综上所述, 本文提出的模型在糖尿病视网膜病变分类任务中用较小的计算代价取得了更好的分类效果, 对糖网分类具有良好的鲁棒性。
4 结 论
本文提出了结合生成对抗网络与双注意力的分类方法AIDnet, 用于解决现有方法中特征提取不充分、 准确率不佳的DR分类问题。 该方法采用改进后的ACGAN生成图像, 使得网络训练时平等地关注每一类特征, 训练时利用InceptionV3网络, 并行融合通道维度上不同尺度的特征, 通过双注意力机制实现通道与空间特征的融合。 实验结果表明, AIDnet网络在Kaggle数据集上的分类准确率达到89.53%, 在Messidor2数据集上的准确率达到90.31%, 本文方法比其他分类方法具有更明显的性能优势。
今后的研究将关注各阶段血管与病变变化特征之间的关系, 以进一步满足临床辅助的需要。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
