
Squeezing More Past Knowledge for Online Class-Incremental Continual Learning
2023-03-27 02:38DaYuMingyiZhangMantianLiFushengZhaJungeZhangLiningSunandKaiqiHuangSenior
Da Yu, Mingyi Zhang, Mantian Li, Fusheng Zha, Junge Zhang,,Lining Sun, and Kaiqi Huang,Senior
Abstract—Continual learning (CL) studies the problem of learning to accumulate knowledge over time from a stream of data.A crucial challenge is that neural networks suffer from performance degradation on previously seen data, known as catastrophic forgetting, due to allowing parameter sharing.In this work, we consider a more practical online class-incremental CL setting, where the model learns new samples in an online manner and may continuously experience new classes.Moreover, prior knowledge is unavailable during training and evaluation.Existing works usually explore sample usages from a single dimension,which ignores a lot of valuable supervisory information.To better tackle the setting, we propose a novel replay-based CL method, which leverages multi-level representations produced by the intermediate process of training samples for replay and strengthens supervision to consolidate previous knowledge.Specifically, besides the previous raw samples, we store the corresponding logits and features in the memory.Furthermore, to imitate the prediction of the past model, we construct extra constraints by leveraging multi-level information stored in the memory.With the same number of samples for replay, our method can use more past knowledge to prevent interference.We conduct extensive evaluations on several popular CL datasets, and experiments show that our method consistently outperforms state-of-the-art methods with various sizes of episodic memory.We further provide a detailed analysis of these results and demonstrate that our method is more viable in practical scenarios.
I.INTRODUCTION
DEEP neural networks (DNNs) have achieved great success in many fields over the last decade.For example,DNNs significantly improve object detection, object tracking,and semantic segmentation in computer vision [1]–[3] and also promote the development of reinforcement learning in many applications such as robot navigation and Atari games[4] and [5].Typically, this learning paradigm assumes a prerequisite, where the model is trained to solve a single task and training data are independent and identically distributed(i.i.d.).However, in practical applications, data usually comes in the form of a stream, and the distribution shifts continuously over time.If no effective strategy is adopted, DNNs are only updated to solve the currently presented task and can not maintain the previously acquired knowledge.This phenomenon is defined as catastrophic forgetting [6]–[8], which is an intractable problem that DNNs suffer from.
Continual learning (CL) [9], also called lifelong learning[10] or sequential learning [11], aims to accumulate and consolidate knowledge from a never-ending data stream while alleviating the catastrophic forgetting of networks.Current CL settings are mainly divided into two branches based on whether task identity is available at the inference time [12]and [13].The first one, referred to as task-incremental learning (Task-IL), assigns different output layers to each task and relies on task-specific information during evaluation, which is the easiest CL evaluation protocol.The second setting is described as class-incremental learning (Class-IL), in which a task identity is not provided to assist in making the inference and the model must perform predictions from all seen classes after the learning procedure.In addition, it assumes that new classes arrive sequentially.
However, the above two settings relax the constraints that the CL actually should keep to different degrees.They assume that the data distribution is i.i.d.within each task and the model has access to all data of the current task.Moreover,offline training for multiple epochs is allowed to be performed.In this work, we focus on a more realistic and challenging CL setting, termed online class-incremental CL [14],[15].Under this setting, new data arrives in the form of a data stream, and the model may continuously experience new classes.More specifically, due to the single pass through the data stream, the training samples can be seen only once;namely the model has only one chance to perform an update on new data.Therefore, determining how to fully tap more potential knowledge and improve the utilization of the samples will directly affect the performance of online CL.Furthermore, no prior knowledge is provided during evaluation,and the model must predict all seen classes using a single output layer.
Meanwhile, many methods have been proven to be effective.Based on how previous data are used and whether they are stored, these methods can be classified into three broad categories [16].Regularization-based methods estimate the parameter importance and use a regularization term to penalize the parameter drifts.This kind of method avoids storing raw data.Parameter isolation methods assign specific model parameters or add new neurons to different tasks.Replaybased methods gain inspiration from neurobiology [17] and[18] and employ an episodic memory to store a subset of previously seen data.These data are replayed from the memory to consolidate previous knowledge while learning a new task.
Compared with the first two approaches, many efforts have shown that replay-based methods could achieve more competitive performance under limited memory consumption.Consequently, we consider replay-based methods as the basis of our work.In real scenarios, to overcome forgetting, we can not store all previously seen data for retraining the model, which is totally impractical and will cause enormous computing resource consumption.Existing replay-based methods employ a fixed episodic memory to store small amounts of previous data.It is crucial for CL to efficiently use limited memory samples for knowledge transfer.Current approaches usually just retrain these samples together with new data or construct a constrained optimization by utilizing the gradients of old data.These strategies consider sample usages only from a single level to alleviate forgetting.As a result, lots of valuable information that can be further exploited is ignored.In fact,from the perspective of representation learning and knowledge transfer, feature representations from different network layers produced by the intermediate process of the training can provide more affluent and diverse cross-information,which can be leveraged to acquire the abstraction and strengthen supervision.The information can be introduced to the CL method to construct extra constraints, which can improve model generalization and preserve more past knowledge.
To address this issue, we propose a novel online class-incremental CL method.Specifically, as shown in Fig.1, to fully tap the potential of training samples, we introduce logits and features produced by training samples at different network positions and store them in the memory with raw inputs.The raw data are retrieved randomly from memory and concatenated with the incoming batch.In addition, we match the corresponding logits and features to construct multi-level constraints, which simulates the original network’s prediction of previous data.Moreover, the intermediate information is the by-product of the regular training process, thus avoiding additional computation.More importantly, these intermediate products are stored in a low-dimensional vector manner, so the training procedure is efficient and consumes few memory requirements.Under the limited samples and memory resources, our method can squeeze out more valuable information and effectively consolidate the knowledge acquired in the past.Our method is evaluated on five class-incremental CL datasets, and the experimental results show that the proposed method outperforms state-of-the-art methods.
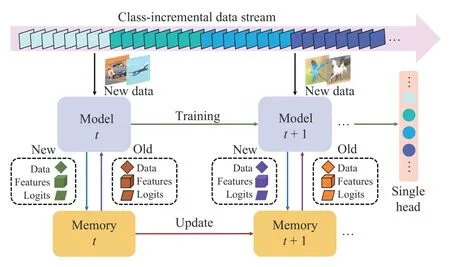
Fig.1.Overview of our proposed method.Data arrive continuously in a class-incremental manner where the model experience new classes.Our method employs a fixed memory to store previous data information.In each learning batch, the model receives new data from data stream and retrieves old data from memory.To imitate the previous predictions, we leverage logits and features generated during training to squeeze more past knowledge.The model and the memory are concurrently updated for the next step, as new classes are encountered.Moreover, the entire training process does not need any prior knowledge and can predict all seen classes using a shared output layer.
The key contributions of this work are summarized in three folds:
1) To preserve more supervision information while avoiding additional computational overload, we propose a hierarchical replay-based method for online class-incremental CL,which leverages multi-level representations produced by the intermediate process of the training for replay.
2) Apart from the previous raw samples, we store the corresponding logits and features generated during training and construct multi-level constraints to imitate the predictions of the past model by leveraging the abundant information stored in the memory.With limited resources, our method can squeeze out more knowledge from previous data.
3) The proposed method achieves state-of-the-art performance on five CL datasets.Experimental results further demonstrate that fully tapping the potential of samples is an effective way to alleviate catastrophic forgetting.
II.RELATED WORK
A.Regularization-Based CL
Regularization-based methods add an extra regularization term to the loss function to consolidate previously gained knowledge when learning a new task.This kind of method does not need to store the raw data and further ensures data privacy.They can be classified into prior-focused and knowledge distillation methods.
Prior-focused methods estimate importance weights for model parameters that are usually assumed independent and use a penalty term to constrain the changes to important parameters.This allows the model to stay in a feasible region for all the seen data and avoid overfitting on certain classes.Elastic weight consolidation (EWC) [19] estimates the parameter importance by computing the Fisher information matrix.Synaptic intelligence (SI) [20] computes the importance measure in an online fashion, based on the contribution to the drop of the loss.oEWC [21] is a modification of EWC.It avoids the need for identifying task labels and does not make the computational cost linear in the number of tasks.Aljundiet al.[22] accumulate importance weights in an unsupervised manner based on the sensitivity of the outputs.From a Bayesian perspective, Nguyenet al.[23] propose a general variational continual learning framework, which merges online variational inference (VI) with Monte Carlo VI for neural networks.Ahnet al.[24] propose the notion of node-wise uncertainty and design novel regularization terms to freeze important weights.Weiet al.[25] propose a class-incremental method for the embedding network by leveraging zero-shot translation to bridge the semantic gaps between different tasks.
Other methods exploit knowledge distillation (KD) to alleviate forgetting.Learning without forgetting (LwF) [26] fuses fine-tuning and KD for neural networks by using the outputs of the previous model as soft labels for previous tasks.The work presented in [27] is built on top of LwF and mitigates forgetting by constraining the distance between resulting representations.In addition, Guet al.[28] utilize multi-teacher networks to consolidate previous knowledge and adapt to new classes for incremental instance segmentation.Yanget al.[29]propose an incremental semantic segmentation method by leveraging a contrastive distillation loss.Finiet al.[30] devise a continual self-supervised learning framework that converts self-supervised loss into a distillation mechanism.
B.Parameter Isolation CL
Parameter isolation methods dedicate different network parts or model parameters to each task.Based on whether the network structure is changed, these methods can be divided into dynamic architecture and fixed network methods.
Dynamic architecture methods allocate more neurons or network layers for new tasks by increasing the architecture size of the model.The works presented in [31] and [32] grow new network branches for new tasks while freezing previous branches learned for past tasks.Expert gate [33] develops a gating mechanism to forward test samples to activate the corresponding model during evaluation.The dynamically expandable network [34] adds additional neurons for new tasks when the loss of the retrained network exceeds a certain threshold.Douillardet al.[35] leverage a transformer architecture to dynamically expand special tokens, and the encoder and decoder can be shared among all tasks.
Without changing the network structure, Fixed Network methods assign part of model parameters to different tasks.The parameters specified for previous tasks are masked out when learning a new task.PackNet [36] frees up redundant parameters after finishing a task, and multiple tasks will be sequentially packed into a single network.PathNet [37] generates different parameter paths for each task within a fixed network.The work proposed in [38] learns a hard attention mask for each task.
C.Replay-Based CL
Replay-based methods have biological significance and use a subset of past samples to consolidate knowledge.These samples can be raw inputs or pseudo-samples.We summarize this kind of method as follows.
Rehearsal methods store a subset of previous data into memory and retrain them at each learning batch.FDR [39]stores network outputs at task boundaries and utilizes them to align old and current outputs.GDumb [40] greedily stores samples in memory and trains a model from scratch only using memory samples during evaluation.Adversarial Shapley value experience replay (ASER) [14] leverages Shapley value to score memory samples in memory retrieval.Hindsight anchor learning (HAL) [41] uses bilevel optimization to regularize the training objective.Banget al.[42] propose a memory management strategy to enhance the diversity of samples in episodic memory.Jinet al.[43] edit memory samples based on a small gradient update to create more challenging examples for replay.Wanget al.[44] utilize data compression to reduce the storage cost of old samples.Guet al.[15] propose a novel gradient-based memory retrieval strategy and effectively mine semantic information between dual view image pairs by maximizing mutual information.The works presented in [45] and [46] explore more representative online memory selections from a data stream.iCaRL [47],dark experience replay (DER) and DER++ [48] hybridize knowledge distillation with rehearsal to prevent interference.
Pseudo-rehearsal methods employ generative models to generate pseudo-samples that are replayed when new data arrives.Shinet al.[49] propose a deep generative replay framework that separately trains a generator and a predictor.Riemeret al.[50] compress high-dimensional experiences to a compact latent code with a variational AutoEncoder (VAE).Venet al.[51] propose a brain-inspired replay that can scale up generative replay to complicated tasks.Weiet al.[52]introduce a novel incremental zero-shot learning setting and leverage generative replay and knowledge distillation strategy to tackle the setting.Tanget al.[53] develop a feature generator to encourage diversity of generated samples that are semantically consistent with memory samples by exploiting unlabeled data.However, pseudo-rehearsal relies on an additional generator which also suffers from catastrophic forgetting.
Constrained optimization methods constrain the direction of gradient updates over new data to improve knowledge transfer.Gradient episodic memory (GEM) [54] projects the gradient of new data on the feasible region constructed by past data gradients in the memory.A-GEM [55] provides a more efficient variant of GEM.Gradient-based sample selection (GSS)[56] maximizes the diversity of samples in the memory to approximate the best feasible region.In addition, Farajtabaret al.[57] leverages the gradient directions of network predictions to prevent interference with previous tasks.

Fig.2.Illustration(ofthe)proposedr(eplay )process.Inthisfigure,xM,FMand zMdenotetheprevioussamples,features andlogitsretrievedfromthememory,respectively.F¯=ΨxM;θandz ¯=φxM;θshowthememorysamples' featuresand logitsproduced bythecurrentmodel.The complete replay procedurecontains memory update, memory retrieval and constraint construction.Specifically, for each learning step, we concatenate the incoming mini-batch from the data stream and the retrieved mini-batch from the memory and utilize the augmented batch to train the model.Apart from raw inputs, we retain the corresponding features and logits generated in the intermediate process.To imitate the prediction of the previous model and strengthen supervision, our method constructs multi-level constraints by matching the features and logits.Consequently, the generic loss L c, the features loss Lfeaand the logits loss L logform the final loss function to prevent interference.
Overall, regularization-based methods may completely fail in the class-incremental setting with long task sequences, as the penalty term has a limited ability to restrict parameter drifts.This also can be reflected in our subsequent experiments.Parameter isolation methods usually need to rely on task identities to make inferences, which is not available for real scenarios.As the size of network architectures increases,more computing and memory resources are consumed, resulting in poor efficiency and scalability.In this work, we consider replay-based methods, which have been shown to obtain a trade-off between model performance and resource consumption.Moreover, many replay methods have been proven to be suitable for an online setting.Therefore, we will carry out the following work to alleviate forgetting, based on this kind of method.
III.PROPOSED METHOD
In this section, we first introduce the definition of online class-incremental CL and formulate the optimization objective.We then show how to squeeze more knowledge from previous samples and further construct extra constraints by matching different levels of information.Finally, we present the overall replay procedure that consists of memory update,memory retrieval and constraint construction.An overview of our method is shown in Fig.2.
A.Problem Formulation


model will not have access to these previous samples in the future.In each learning step, a mini-batch of samples is retrieved from the memory for replay.We seek to minimize the following loss with only access to the current mini-batch and the mini-batch from M :

B.Response-Based Matching

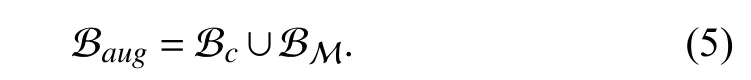
Therefore, different from the relaxed task-based CL assumption, we update the model over a sequence of batches during the optimization trajectory.A generic experience replay strategy minimizes the following loss:
where Lcindicates the loss incurred by the raw inputs and labels and ℓceis the cross-entropy loss.This direct method is simple but effective in alleviating the forgetting of networks.
To further consolidate previously accumulated knowledge,as shown in Fig.2, we introduce the network’s logits z=φ(x;θ)as the outputs of the last fully connected layer of the deep model.The relationship between the logits and the corresponding probability distribution over the classes can be defined asf(x;θ)=softmax(φ(x;θ)).
Apart from retaining the raw past samples, we store the corresponding logits in the memory during training.Without using the ground-truth labels, we leverage the logits to imitate the previous prediction of the model and transfer the past knowledge to alleviate forgetting.Specifically, the logits stored in M indicate the previous response of the model.For every learning step, the current model calculates the logits of the mini-batch retrieved from the memory.We match the corresponding logits throughout the optimization trajectory.The objective can be defined as
where ℓ2isL2loss.Explicitly, our goal is to squeeze more valuable information with limited data.Therefore, we further add the loss Llogto the generic loss Lc, and get the following objective:
whereαindicates a hyper-parameter balancing the trade-off between the terms.The idea of response-based matching is straightforward and easy to understand, especially in the context of image classification problems.The loss Lcand Llogare complementary in essence.Without softmax processing, the current model can imitate the previous response by matching the logits that retain more past information.Under the online class-incremental setting, the data distribution may experience gradual or sudden changes.Logits observed at the suboptimal have high bias and might be sampled into the memory for later replay.Lcuses ground-truth labels for the augmented batch, which is explicit and robust to the distribution shift.Therefore, we can effectively learn new data while consolidating the predictions of previous samples at each learning step.These two loss terms work together to prevent interference.
Note that there are three main differences between the algorithm DER++ and the loss function Lr.The first is that DER++ trains the model independently on the mini-batch retrieved from the memory and utilizes the acquired loss as an extra regularization term.In contrast, we concatenate the incoming mini-batch with the retrieved mini-batch and feed the augmented batch into the model.Secondly, DER++ needs to retrieve two mini-batches from the memory in each learning step, which are used for computing different loss terms.Our method only uses one retrieved mini-batch to compute the generic loss Lcand logits loss Llogrespectively.Finally, we focus on training at the mini-batch level, which is more suitable for online CL setting.
C.Constructing Features Constraint
In fact, logits indicate the class probability distribution and are suitable for the supervised classification task.However,using past knowledge only via logits has some limitations and drawbacks.Firstly, its effectiveness is limited to the softmax loss function, which relies on the number of classes and cannot be applied to low-level vision tasks [60].Secondly,although logits could represent each sample by a class distribution and transfer intra-class variations, its performance is susceptible to model capacity [61].Moreover, it fails to address intermediate-level representations, which means that lots of valuable information is ignored to strengthen supervision.Thus, it is necessary to introduce features to construct stronger constraints.
From the perspective of representation learning, DNNs are good at learning multiple levels of feature representation with increasing abstraction [62].Many works focus on better interpretation of feature representations and have shown that features might contain more affluent supervisory information[63]–[65].From the perspective of knowledge transfer, the similarity-preserving knowledge from intermediate features expresses not only the representation space, but also the activations of object category, which is similar to the class probability distribution [66].Therefore, feature knowledge is a good extension of logits and can provide better generalization to problems without class labels.
To acquire more knowledge from previous samples, as shown in Fig.2, we further introduce features F=Ψ(x;θ) to construct an empirical constraint.Without an additional computation procedure, the algorithm retains network’s features generated at the final pooling layer.As a result, raw inputs together with the corresponding logits and features form data triplets and are stored in the memory by a specific sampling strategy.For each incoming mini-batch, we randomly retrieve another mini-batch from memory M which contains different data triplets used for replay.Note that the past features stored in memory are not changed, and the retrieved raw samples will be retrained by the current model to get new features.We try to align feature representations and learn the predictions of the previous model’s intermediate representations.Thus, indirect replay makes up for the constraint that the prediction of the same sample at different time steps, which provides more advantageous and diverse cross-information to the current model.According to this consideration, we optimize the following objective by matching the features:
Instead of just playing back the raw inputs, multi-level information from different positions is exploited to consolidate previous knowledge, which improves the generalization of the model with limited samples.The overall CL loss function, composed of the generic loss Lc, the logits loss Llogand the features loss Lfea, is calculated as
whereβis a hype-parameter to balance the last term.We use the loss function Lallto update parameters during the optimization trajectory and keep the model in a region that is feasible for previously seen samples.
D.Online Replay via Multi-Level Information
For replay-based methods, the memory M will be updated together with the network model, as new data arrive continually.To maintain a fixed memory, we need to decide whether a new input is stored in the memory and which data triplet is removed from the memory when memory is full.As an important component of replay, the quality of memory update will directly affect the performance of algorithms.Specifically, a memory update must be performed in an online manner due to the data stream that is seen only once.Moreover, any prior knowledge is not provided during updating.
In this work, we adopt reservoir sampling (RS) to update M.RS ensures each data has the same probabilityM/Nto be sampled into the memory, whereMis the size of memory andNis the number of samples observed up to now.Note that we do not need to know the length of the data stream in advance.In addition, RS avoids relying on the task identity to populate the memory for different tasks, which is more suitable for the online CL scenario.In addition to memory update, a complete replay process includes memory retrieval.To ensure that each memory sample has the same chance to be replayed, we randomly select a mini-batch of samples from memory.Similar procedures can be found in neuro-biological systems.According to the complementary learning system, the formation and consolidation of human memory, namely short-term memory to long-term memory, contain information integration, retrieval and replay.Specifically, our method continually retrieves previous samples from memory for replay at each learning step, which effectively alleviates forgetting and improves the generalization of the model.
The entire learning process is presented in Algorithm 1.We combine generic experience replay with additional constraint terms and acquire a joint loss, which squeezes more knowledge from previous samples to prevent interference.After the model is updated with the joint loss, the raw inputs, together with the corresponding logits, features and labels, are used for memory update.As the outputs of the intermediate process,logits and features avoid extra computational requirements.In addition, this information provides richer knowledge but consumes limited memory resources.This increases flexibility for performance improvements.From the constraint optimization perspective, leveraging multi-level knowledge can result in a more feasible parameter space during the optimization trajectory, which is more advantageous than using only the raw inputs and labels.

Algorithm 1 Online squeezing experience replay Input: data stream , parameters θ, learning rate λ, memory ,mini-batch size bM ←{}S M 1 Initialize ;Bc∼S 2 for doBM←MemoryRetrieval(M,b)3 ;Baug=Bc∪BM4 ;[ℓ(f(x;θ),y)]5 Generic loss: ;Lc=E(x,y)∼Baug[ℓ2(φ(x;θ),z)]6 Logits loss: ;Llog=E(x,z)∼BM7 Features loss: ;Lall=Lc+αLlog+βLfeaLfea=E(x,F)∼BM[ℓ2(Ψ(x;θ),F)]8 Joint loss: ;θ ←θ −λ·∇θLall9 ;(x,y) Bc10 for in do z=φ(x;θ)11 ;F=Ψ(x;θ)12 ;M ←MemoryUpdate(M,((x;z;F),y))13 ;14 end 15 end
IV.EXPERIMENTS
In this section, we review the commonly used datasets and metrics for CL evaluation.Then, details about baselines and experimental settings are introduced.Finally, we present and analyze the results compared to state-of-the-art methods.
A.Datasets and Evaluation Metrics
To verify the effectiveness of the proposed method under the online class-incremental CL setting, we conduct comprehensive evaluations on five CL datasets as follows:
Split MNIST splits the MNIST [67] dataset into 5 disjoint tasks based on the labels.Each task has two different classes,and each class has around 6000 3×28×28 training images and 1000 testing images.
Split CIFAR-10 divides the CIFAR-10 [68] dataset into 5 disjoint tasks with two classes in each task, where each class contains 5000 3×32×32 images for training and 1000 images for testing.
Split CIFAR-100 is constructed by splitting the CIFAR-100[68] dataset into 10 different tasks with non-overlapping classes.Each task has 10 classes, and every class consists of 500 3×32×32 training images and 100 testing images.
Split MiniImageNet splits the MiniImageNet [69] dataset into 10 disjoint tasks with 10 different classes in each task.Every class consists of 500 3×84×84 images for training and 100 images for testing.
Split TinyImageNet is a variant of the TinyImageNet [70]dataset.This benchmark contains 20 disjoint tasks, each with 10 different classes.Every class consists of 500 3×64×64 training images and 50 testing images.
It can be seen that original datasets are split to form a sequence of tasks.The algorithm is asked to learn each task sequentially while accumulating knowledge over time.Unlike the task-based setting where the data arrive one task at a time,our setting receives a mini-batch of samples at each time step and does not need to provide the task boundaries in advance.That is, although the aforementioned datasets are presented in the form of tasks, we actually train the model in a streaming manner, which is more challenging and suitable for practical scenarios.Furthermore, different from the conventional machine learning paradigm, CL aims to learn and consolidate new knowledge while alleviating the forgetting of networks.Following [54] and [71], we use two popular metrics to measure the performance of CL algorithms:

B.Baselines
In this work, we focus on comparison with regularizationbased methods and replay-based methods.For a fair comparison, all baselines are unified to the online class-incremental CL setting.Note that we do not consider parameter isolation methods such as progressive neural networks (PNN) [31], as they rely on task identities and are not suitable for the online CL setting.Specifically, we compare our proposed method against the following baselines:
1) Regularization-Based Baselines:We compare the proposed method with three regularization-based methods that avoid storing previous samples.For prior-focused methods,we consider SI [20] and oEWC [21], which are variants of EWC [19].In addition, LwF [26] is adopted as a data-focused method that combines knowledge distillation and fine-tuning.
2) Replay-Based Baselines:We select several baselines from rehearsal and constrained optimization methods respectively.In particular, we do not consider pseudo-rehearsal methods, as they need to train a generator that also suffers from catastrophic forgetting.Among all baselines, FDR [39],GDumb [40], ASER [14] and HAL [41] are typical rehearsal methods that explicitly retrain samples stored in memory.Moreover, iCaRL [47], DER [48] and DER++ [48] leverage knowledge distillation to improve performance.GEM [54], AGEM [55] and GSS [56] belong to the constrained optimization methods, which need additional computation of gradients.Different from regularization-based methods, these baselines employ a memory to store previous samples.We will evaluate the performance of algorithms on different memory sizes.
3) i.i.d.Offline:It trains the model offline for multiple epochs with i.i.d.data and can be regarded as the upper bound performance.We use five epochs in all the experiments for this baseline.
4) i.i.d.Online:It considers training the model on an i.i.d.data stream in an online manner.
5) Fine-Tuning:It involves training the model online without any mechanism to prevent forgetting and can be regarded as the lower bound of performance.
C.Experimental Settings
All baselines are required to use the same neural network architecture.For a fair comparison, our choices here are largely affected by previous work.Specifically, for Split MNIST, we follow [54] and train a fully-connected network with two hidden layers, each one consisting of 100 ReLU units.Due to more complex samples, we use a ResNet18 without pre-training, similar to [48], on Split CIFAR-10, Split CIFAR-100, Split MiniImageNet and Split TinyImageNet.Following [56] and [71], the mini-batch size is set to 10 for the incoming samples.To better evaluate the ability to acquire knowledge from previous samples, the size of the mini-batch sampled from the memory is also set to 10 irrespective of memory size.
Under the online CL setting, we adopt a shared output layer to predict all seen classes during evaluation.Moreover, we perform only a single gradient update on the incoming minibatch for all experiments, which is more suitable for realistic scenarios.We train all models using the stochastic gradient descent (SGD) optimizer.Following [72] and [73], the features used to construct constraints are derived from the final pooling layer.For all datasets, we set the value ofαto 0.5 andβto 0.2.For all experiments, we report the average and standard deviation over five runs, each with different random seeds.
D.Experimental Results
1) Average Accuracy With Different Memory Sizes:As shown in Tables I and II, we report the average accuracy on Split MNIST, Split CIFAR-10, Split CIFAR-100, Split Mini-ImageNet and Split TinyImageNet.We can find a clear difference in performance between the regularization-based and replay-based methods.Regularization-based baselines do not cope well with the online class-incremental setting.This suggests that only using penalty terms makes it hard to constrain the model to a feasible parameter space when task identity isnot provided.In contrast, replay-based methods show the potential to perform well in this setting.Furthermore, the model acquires better performance, as the memory sizeMincreases.This is because a larger memory can ensure that more diverse samples are used for replay by memory retrieval at each learning step, which further avoids overfitting on previous samples.Moreover, we can observe that the increase of the average accuracy slows down noticeably when the memory is large enough.Therefore, in practical applications, we should choose an appropriate memory size according to the specific scenario and try to achieve a trade-off between performance and memory consumption.
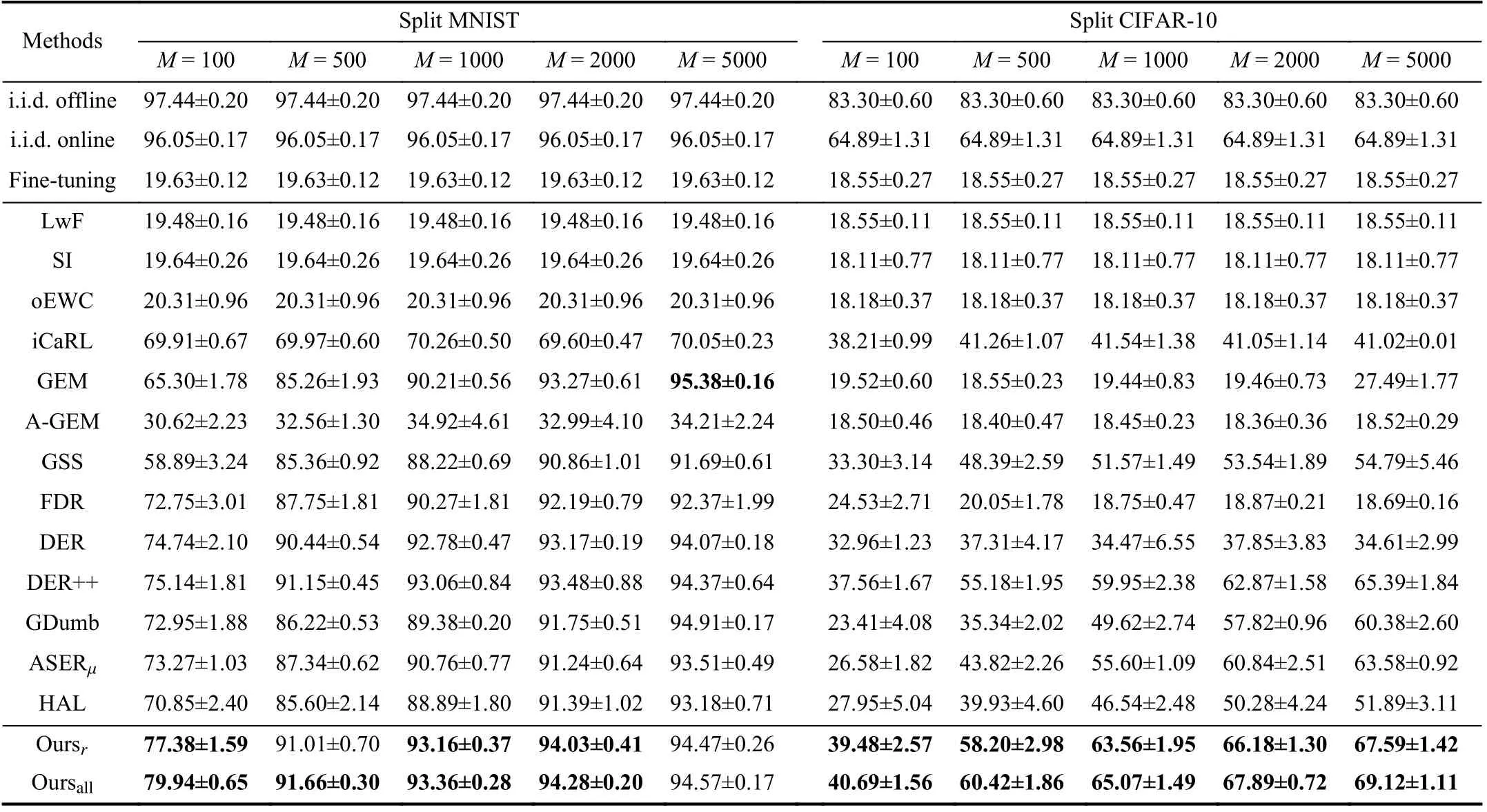
TABLE I COMPARISON OF AVERAGE ACCURACY (HIGHER IS BETTER) ON SPLIT MNIST AND SPLIT CIFAR-10 WITH DIFFERENT MEMORY SIZES.AVERAGES AND STANDARD DEVIATIONS ARE COMPUTED OVER FIVE RUNS USING DIFFERENT RANDOM SEEDS

TABLE II COMPARISON OF AVERAGE ACCURACY (HIGHER IS BETTER) ON SPLIT CIFAR-100, SPLIT MINIIMAGENET AND SPLIT TINYIMAGENET WITH DIFFERENT MEMORY SIZES.AVERAGES AND STANDARD DEVIATIONS ARE COMPUTED OVER FIVE RUNS USING DIFFERENT RANDOM SEEDS
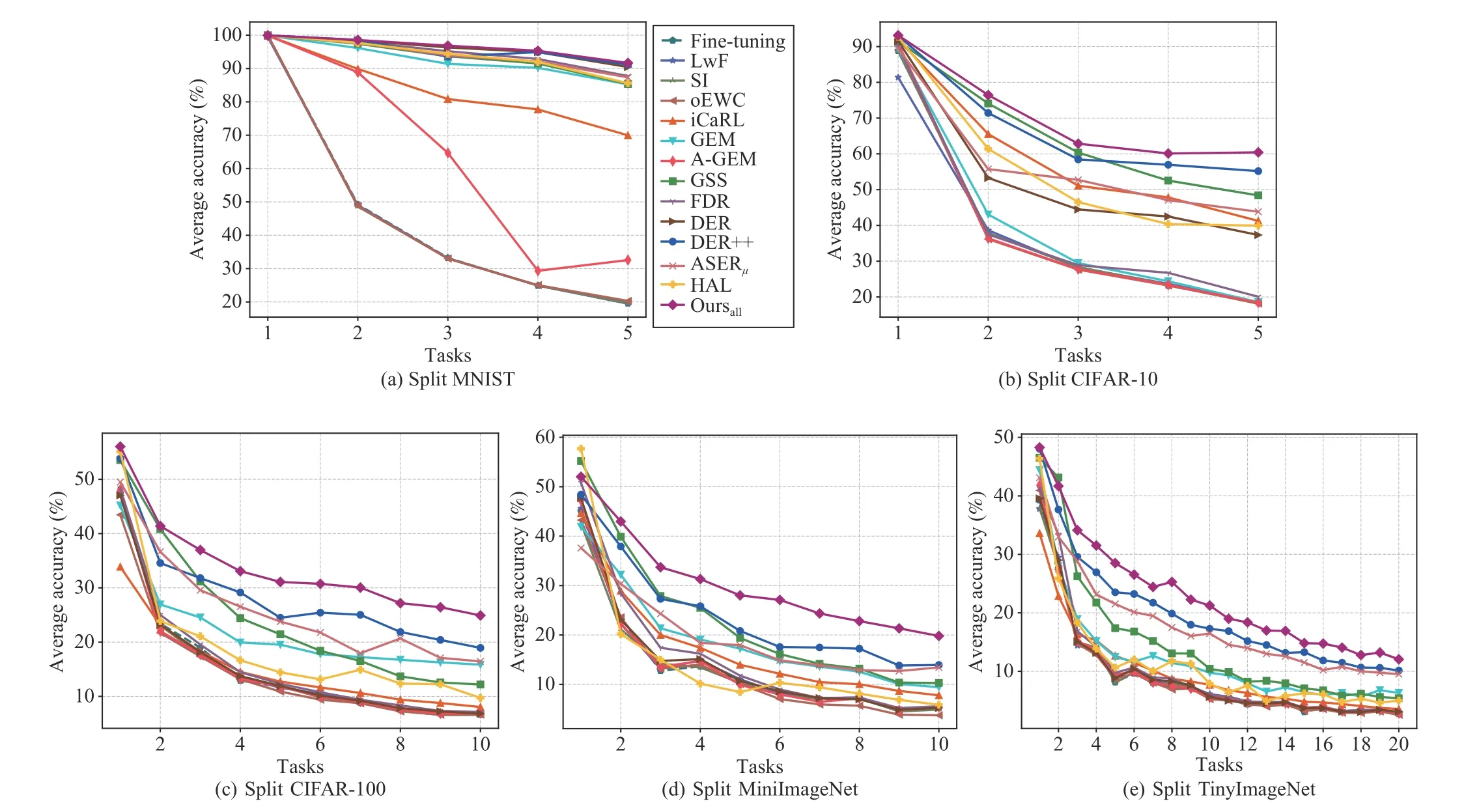
Fig.3.Evolution of the average accuracy as new tasks are learned in different datasets.For Split MNIST and Split CIFAR-10, we set memory size M=500,and for Split CIFAR-100, Split MiniImageNet and Split TinyImageNet, we set memory size M=1000.The average accuracy keeps decreasing gradually with the increase in the number of tasks, especially on challenging datasets that contain more classes and tasks.Under the online class-incremental setting, we consistently achieve improvement during the optimization trajectory.
We use Oursrto denote the model optimized by loss function Lrthat adds an extra logits loss.Oursallrepresents the model that leverages the loss function Lall, which retains multi-level information from raw inputs, logits and features.A significant improvement can be observed, especially when memory size is limited.This demonstrates the effectiveness of squeezing past knowledge by matching the logits and features.For more challenging datasets, especially for Split TinyImageNet, which contains more classes and tasks, our method shows competitive performance although all methods suffer from more performance degradation.However, there is a large gap between our methods and i.i.d.offline, which suggests that current CL methods still have great room for improvement.Overall, our method achieves state-of-the-art performance on different datasets and memory sizes.
2) Evolution of Average Accuracy:To better illustrate the performance of algorithms during optimization trajectory, as shown in Fig.3, we further show the evolution of the average accuracy as new tasks are learned on different datasets.Note that the results of i.i.d.offline and i.i.d.online are not available due to training on stationary data distribution.In addition,the performance of GDumb is not reported since we only train a model for it at the end of the data stream.We can see that most methods achieve better performance on easier Split MNIST.Moreover, on other datasets, the average accuracy exhibits faster decline in the initial stages of the learning procedure, but the rate of decline slows down with increasing new tasks.This happens because the model does not accumulate enough knowledge to forget, as more classes are learned.Specifically, regularization-based baselines completely fail in all tasks and obtain similar performance to Fine-tuning.The constrained optimization baseline also shows poor average accuracy on complex datasets.In contrast, DER++ and ASERµsurpass other replay-based baselines, which suggests that replaying raw inputs can effectively prevent interference in the online class-incremental setting.Our method shows consistently better performance throughout training.This further demonstrates that constructing extra constraints is favorable for consolidating knowledge.
3) Effectiveness on Different Task Lengths:The desiderata of CL is to accumulate knowledge from a never-ending data stream.Therefore, it should have the ability to address long sequence tasks.To evaluate the effectiveness of our method on different lengths of task sequences, as shown in Table III,we report the average accuracy on Split CIFAR-100 which is split into different numbers of disjoint tasks.For example,Split CIFAR-100 consists of 50 disjoint tasks with two classes in each task, whenTis set to 50.The number of samples per class used for training and testing remains constant.We consistently perform the online class-incremental setting for differentTvalues.We can see that i.i.d.offline and i.i.d.online are not affected by dataset division due to training on station-ary distribution.

TABLE III COMPARISON OF AVERAGE ACCURACY (HIGHER IS BETTER) ON SPLIT CIFAR-100 WITH DIFFERENT TASK SEQUENCES T.AVERAGES AND STANDARD DEVIATIONS ARE COMPUTED OVER FIVE RUNS USING DIFFERENT RANDOM SEEDS
Experimental results clearly indicate that all methods suffer from greater performance degradation, as the model experiences more tasks.This phenomenon is reasonably straightforward, since it is difficult to optimize networks into a parameter space that is feasible for all seen tasks when the sequence of tasks becomes longer.Specifically, we can see that many baselines are completely ineffective and achieve similar performance to Fine-tuning.Moreover, apart from regularizationbased methods, using only distillation or gradient optimization, replay-based baselines also make it difficult to cope with long sequence settings.On the contrary, our method leverages multi-level information of samples to construct constraints and consolidate knowledge.Although performance degradation is unavoidable, we consistently maintain better performance on different lengths of tasks.This further suggests that squeezing more knowledge from previous samples could be considered for more challenging scenarios.
4) Effect of Different Retrieved Mini-Batch Sizes:Memory retrieval is an important procedure for replay-based methods,since it determines how many previous samples can be replayed at each learning step.As shown in Table IV, we set different mini-batch sizes BMretrieved from the memory to evaluate the impact of this process on the performance of algorithms.We report the average accuracy of all replaybased baselines on Split CIFAR-10 and Split CIFAR-100.As the size of BMincreases, it can be seen that the performance continuously decreases on Split CIFAR-10.These results seem counter-intuitive, since increasing the size of BMmeans that more previous samples can be learned to alleviate the forgetting of networks.We argue that this is because retrieving more samples from memory will lead to overfitting on past tasks when the length of the task sequence is short, which interferes with the model in learning new knowledge.
In contrast, for Split CIFAR-100 which consists of longer sequences of tasks, the average accuracy of baselines remains comparatively flat or decreasing.However, our method consistently shows improvement when the mini-batch size BMis set to 32 and 64, but suffers from performance degradation when BMis 128.This suggests that appropriately increasing the number of samples for replay can help to consolidate previous knowledge when experiencing longer sequences of tasks.In general, our method achieves state-of-the-art performance with different mini-batch sizes BM, especially on the more challenging Split CIFAR-100 dataset.Moreover, we can conclude that blindly increasing the size of BMmay have an adverse effect on the final results, due to the imbalance between old and new samples.Therefore, according to the specific scenario, it is necessary to choose a reasonableBMvalue, which may improve the performance of the algorithm.
5) Evaluation of Average Forgetting:As shown in Table V,we show and analyze the average forgetting of the algorithms from two aspects.Note that i.i.d.offline and i.i.d.online train the model on stationary data distribution.Hence, the average forgetting is not available.In addition, we only train a model for GDumb at the end of the data stream and do not show the forgetting metric in the table.On the one hand, we report the average forgetting on Split CIFAR-10 with different memory sizesM.Among them, Fine-tuning and regularization-based baselines are not related to memory and fail to retain any previous knowledge.We can observe that the average forgetting of replay-based methods decreases continuously with increasing memory size.This suggests that replaying more diverse samples is beneficial for alleviating the forgetting of networks.Our method consistently obtains lower forgetting on differentMvalues.
On the other hand, we show the average forgetting on Split CIFAR-100 with different task sequencesT, and the memory sizeMis uniformly set to 1000.Experimental results clearly indicate that all methods suffer from more forgetting, as the model encounters more tasks.We can see that iCaRL and HAL achieve lower average forgetting compared with our method.However, these two baselines do not acquire good performance for the average accuracy, as shown in Table III.This is mainly because the average forgetting is a self-relative metric, which measures the change between the past best and the current performance of the method.If an algorithm performs poorly throughout training, a lower average forgetting can be observed as it has little knowledge to forget from the beginning.As a result, the comparisons of the average forgetting between different methods may be misleading.Hence, we cannot arbitrarily evaluate the performance of an algorithm by only observing the average forgetting.This is why the best baseline for this metric is not bolded in Table V.To better illustrate the issue, as shown in Fig.4, we show the evolution of the accuracy values of each task whenTis set to 5, as new tasks are continuously encountered.iCaRL and HAL show consistently worse performance on each task than our method.Many tasks have very poor accuracy from the beginning,especially for iCaRL.Although these baselines achieve lower average forgetting, they actually do not accumulate sufficient knowledge and alleviate the forgetting of networks.Moreover,compared with the algorithms with close average accuracy,such as DER++ and ASERµ, our method obtains a lower average forgetting, which shows that the proposed method has better control over the negative transfer.
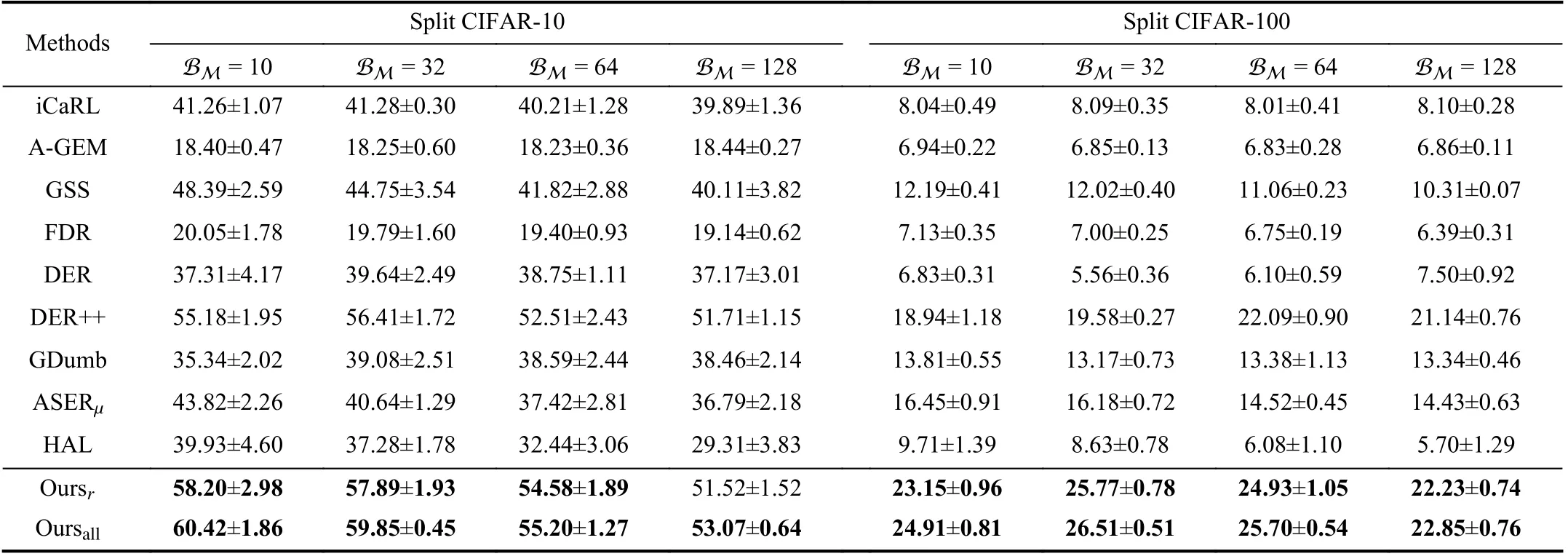
TABLE IV COMPARISON OF AVERAGE ACCURACY (HIGHER IS BETTER) ON SPLIT CIFAR-10 AND SPLIT CIFAR-100 WITH DIFFERENT RETRIEVED MINI-BATCH SIZES B M.AVERAGES AND STANDARD DEVIATIONS ARE COMPUTED OVER FIVE RUNS USING DIFFERENT RANDOM SEEDS

TABLE V COMPARISON OF AVERAGE FORGETTING (LOWER IS BETTER) ON SPLIT CIFAR-10 WITH DIFFERENT MEMORY SIZES MAND SPLIT CIFAR-100 WITH DIFFERENT TASK SEQUENCES T.NOTE THAT THE LOWEST VALUE IS NOT BOLDED DUE TO THE SELF-RELATIVE PROPERTY OF THE METRIC.AVERAGES AND STANDARD DEVIATIONS ARE COMPUTED OVER FIVE RUNS USING DIFFERENT RANDOM SEEDS
E.Ablation Study

Fig.4.Evolution of the accuracy values of each task as new tasks are learned on Split CIFAR-100 where the number of tasks Tis 5.We can see that the best accuracy obtained by iCaRL is only 20.6% in all tasks.HAL shows poor accuracy from the beginning of the second task.Although these two baselines get a lower average forgetting metric, they do not actually accumulate more knowledge and alleviate the forgetting of networks.In contrast, our method achieves consistently better performance than iCaRL and HAL in each task.
1) Effect of Different Replay Selections:We have shown some ablation studies in the previous paragraphs.Specifically,we have introduced the impact of different memory sizesM,task lengthsTand retrieved mini-batch sizes BMon performance.In this subsection, we aim to illustrate whether different replay selections affect our method.Without loss of generality, we conduct the experiment on Split CIFAR-100 and Split TinyImageNet with two different memory sizes,M=1000 andM=5000, respectively.A generic experience replay is adopted as the basis for the algorithm.As shown in Table VI, we provide logits and features during replay and report the performance of different replay selections.We can see that the generic experience replay has proven to be a strong CL baseline.Apart from replaying the raw inputs,when logits or features are introduced separately, the performance of the algorithm is improved to varying degrees.Moreover, using logits achieves better average accuracy than replaying features individually.This is because, from a task perspective, logits are more suitable for supervised classification.We need to note that this does not negate the importance of features, which is a good extension of logits and might contain more knowledge that can be used for low-level vision tasks.If we select logits and features concurrently during the optimization trajectory, we can obtain much better performance, which can also reflect that the feature information can strengthen supervision.Overall, leveraging multi-level information of samples can provide more valuable knowledge and alleviate catastrophic forgetting of networks.
2) Effect of Different Feature Extraction Layers:In this work, we employ ResNet18 for CL and leverage the final pooling layer to construct feature constraints.ResNet18 has 4 sequential residual layers and each residual layer outputs a corresponding feature.To explore the impact of different feature extraction layers on algorithm performance, we compare different residual layers of ResNet18, i.e., Layer1, Layer2,Layer3 and Layer4 with the final pooling layer.Specifically,we add the feature constraint produced by different network layers to a generic experience replay.The value ofαis set to 0, and the value ofβis set to 0.2, 0.5 and 1.0, respectively.As shown in Table VII, we report the average accuracy on Split CIFAR-10 with memoryM=500.We observe that, in the context of image classification problems, the features derived from the final pooling layer achieve better performance.In addition, as the valueβincreases, the accuracies show a decline of varying degrees.From the perspective of representation learning, the final pooling layer produces the final embedding and mainly focuses on high-level semantics, which is more suitable for classification.
3) Effect of Varying Different Hype-Parameters:We investigate the influence of the hype-parametersαandβon algorithm performance.As shown in Fig.5, we show the change of average accuracy on Split CIFAR-10 by varyingαandβ,respectively.The memory sizeMis uniformly set to 500.Firstly, Fig.5(a) shows the impact ofαon the loss function, in which the value ofβis set to 0.In general, the value ofαbetween 0.1 to 0.5 works well.Then, under the setting ofα=0.5, Fig.5(b) reports the average accuracy by varying theβ.We find that a high value ofβleads to inferior performance.Overall, these results indicate that introducing the logits and features and constructing multi-level constraints can consolidate knowledge and improve performance.In this work, we set α =0.5 and β =0.2 for all other experiments.

TABLE VI ABLATION STUDY ON SPLIT CIFAR-100 AND SPLIT TINYIMAGENET WITH DIFFERENT REPLAY SELECTIONS AND MEMORY SIZES M.AVERAGES AND STANDARD DEVIATIONS ARE COMPUTED OVER FIVE RUNS USING DIFFERENT RANDOM SEEDS

TABLE VII ABLATION STUDY ON SPLIT CIFAR-10 WITH DIFFERENT FEATURE EXTRACTION LAYERS.AVERAGES AND STANDARD DEVIATIONS ARE COMPUTED OVER FIVE RUNS USING DIFFERENT RANDOM SEEDS
F.Training Efficiency

Fig.5.Average accuracy of varying hype-parameters αand βon Split CIFAR-10 for ablation study.
Under the online class-incremental setting, new samples arrive in the form of a data stream.Therefore, so as to not miss incoming samples, the metric of training time also needs to be considered, which is directly related to whether an algorithm can be deployed in real applications.As shown in Fig.6,we show the training time of all methods after completing the learning of Split MNIST.To guarantee a fair comparison, we conduct all evaluations under the same computing platform.For replay-based baselines, the memory size is set to 500.We repeat the learning process for all methods five times and report the average training time.Although regularizationbased baselines avoid storing and playing back previous samples, they do not spend less time, especially for oEWC and LwF.We observe that our method achieves a comparable running time compared with other replay baselines such as AGEM, FDR, DER and HAL.This suggests that the process of matching logits and features is efficient, which is viable for practical scenarios.In contrast, GEM and GSS consume more training time than other methods.This is a main bottleneck of constrained optimization, which needs the additional computation of gradients that are used for constraining model updates.

Fig.6.Comparison of training time on Split MNIST.The memory size is set to 500.Our proposed method achieves a comparable performance with the replay-based baselines.
V.CONCLUSIONS
In this paper, we discuss continual learning under the online class-incremental setting in which the model experiences new classes sequentially and all samples are seen only once due to the single-pass through the data stream.Moreover, task identities are unavailable during training and evaluation.To improve the utilization of samples in this setting, we first introduce the logits generated at the last fully connected layer and imitate the previous response of networks by matching the corresponding logits.Furthermore, to acquire more knowledge from previous samples, we construct an empirical constraint by aligning feature representations during the optimization trajectory and learn the predictions of intermediate representations.Our method can fully tap the potential of training samples and use more past knowledge to strengthen supervision.Extensive evaluations demonstrate that the proposed method achieves state-of-the-art performance and can effectively consolidate previously gained knowledge.
 IEEE/CAA Journal of Automatica Sinica2023年3期
IEEE/CAA Journal of Automatica Sinica2023年3期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Meta-Energy: When Integrated Energy Internet Meets Metaverse
- Cooperative Target Tracking of Multiple Autonomous Surface Vehicles Under Switching Interaction Topologies
- Distributed Momentum-Based Frank-Wolfe Algorithm for Stochastic Optimization
- A Survey on the Control Lyapunov Function and Control Barrier Function for Nonlinear-Affine Control Systems
- Group Hybrid Coordination Control of Multi-Agent Systems With Time-Delays and Additive Noises
- Observer-Based Path Tracking Controller Design for Autonomous Ground Vehicles With Input Saturation