
基于遗传算法优化的随机森林钻井机械钻速预测模型研究
2023-04-19 06:38徐英卓王若禹王六鹏
智能计算机与应用 2023年3期
徐英卓, 王若禹, 王六鹏
(1 西安石油大学 计算机学院, 西安 710065; 2 西安石油大学 石油工程学院, 西安 710065)
0 引 言
随着经济的快速发展,石油天然气等自然资源的消耗量也在不断增加。 机械钻速(ROP)是影响钻井效率的关键因素之一,是石油工程钻井作业的重要经济指标。 传统工艺技术实现“硬”提速,但由于各井之间地质条件不同导致提速效果差异大,从而陷入提速瓶颈。 所以快速、准确地提高机械钻速,得到主要影响因素,进而优化钻井参数,该课题已成为钻井工程领域亟需解决的研究热点。
2007 年,范翔宇等学者[1]利用地震资料提出以数理统计方法对钻速进行预测,符合率达到70%,然而由于地震资料的精度导致准确率难以进一步提升。 2019 年,刘胜娃等学者[2]建立基于误差反向传播神经网络设计的机械钻速预测模型,但因为数据有限、特征较少导致对机械钻速影响规律未能进行有效探索。 2021 年,许明泽等学者[3]研究多模型集成学习应用于机械钻速预测中,预测效果优于单一模型。 但并未对单一模型进行调参,并不能解释集成模型优劣。
综上所述,目前学界对机械钻速影响因素的研究并不全面,导致机械钻速模型的精确度也不高。本文提出遗传算法-随机森林(GA-RandomForest)机械钻速预测模型,仿真实验结果表明所建预测模型具有更高精度。
1 GA-Random Forest 算法模型
(1)随机森林算法。 该方法是一种通过集成学习思想将多个决策树集成在一起的算法。 随机地从数据集中抽取数据用作决策树[4]的训练集,并随机地从特征数据中选取特征节点建立决策树,重复操作后形成森林。 在此基础上,对所有树得出的值进行选择,被选择最多的即是最终的输出结果。
(2)遗传算法。 该方法是解决复杂优化问题最常用的方法[5]。 遗传算法模拟生物遗传进化的过程。首先,初始化总体,每个染色体代表一个解决方案。其次,适应度函数决定了种群进化的方向,适应度函数的值决定了解的质量。 适应度函数定义为:
然后,按照适者生存的自然选择原则,优秀的个体更有可能保留自己的基因,因此具有高适应值的个体更有可能被选为下一代的父母。 本研究用轮盘赌法进行选择操作,使个体被选择概率与其适应度值成正比,个体α被选择的概率pα可表示为:
其中,Fα为个体α的适应度值,Fα′为个体α′的适应度值。
最后,通过交叉和变异生成下一代种群,当得到满意解或达到定义代数时,则结束进化过程。
(3) GA-Random Forest 算 法[6]。 GA-Random Forest 机械钻速预测模型的建模过程如图1 所示。由图1 可看到,首先,将随机森林中的每一个决策树作为染色体对其进行编码,规定决策树的数量就是染色体的长度。 然后,设置条件函数来计算该树的准确率,用来评价决策树组合的优缺点。 每个决策树组合的分类正确率作为对应染色体的适应度。 其次,用轮盘赌法进行选择操作,规定其中每一代优秀率高的组合具有更高的被选择遗传下来的概率。 最后,通过交叉产生子代,变异可为决策树的组合提高随机性,从而避免陷入局部最优。 通过上述步骤,得到了更加优秀的个体,如此即可以加快进化速度。
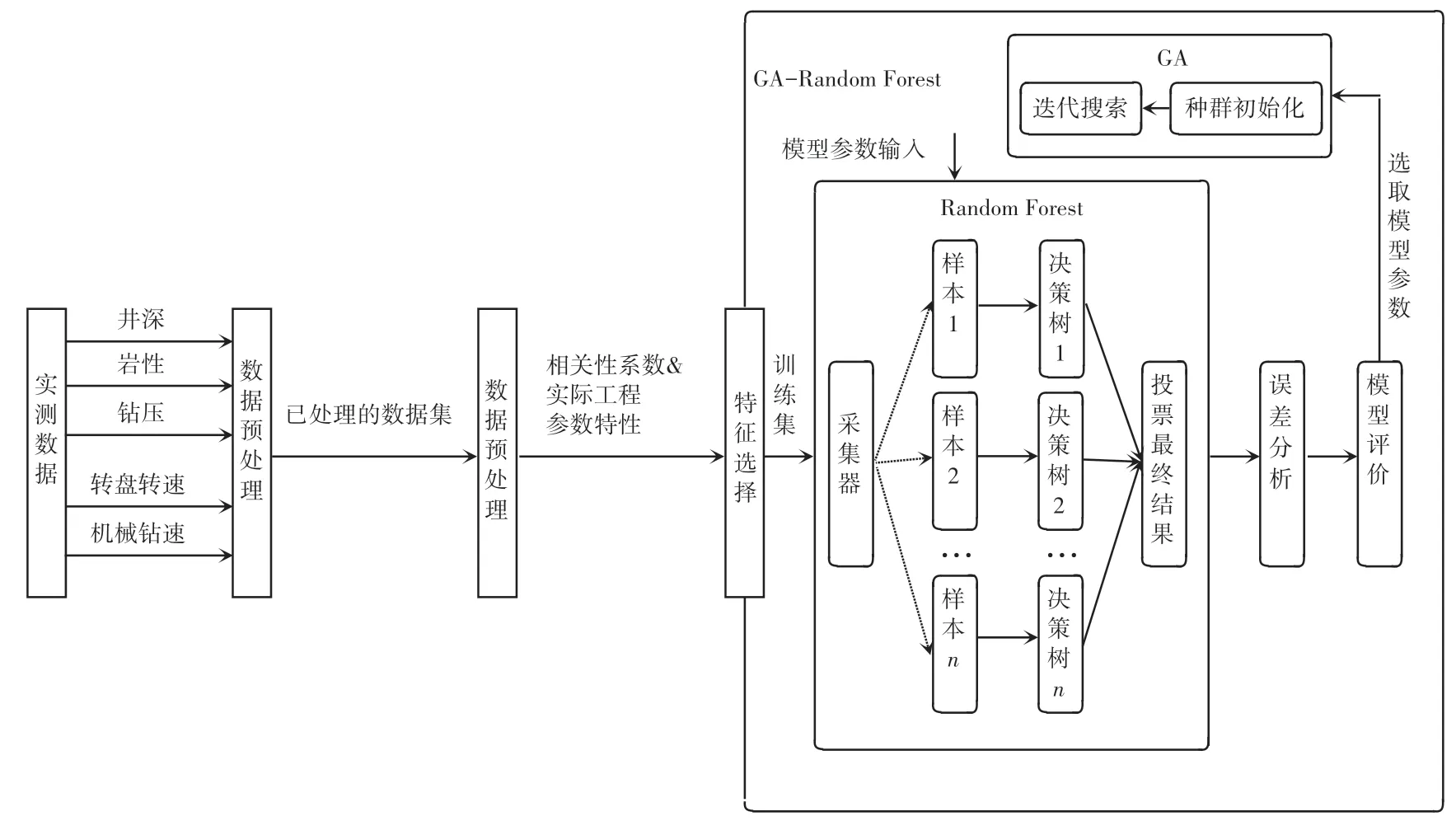
图1 模型框架结构图Fig. 1 Model frame structure
2 基于GA-Random Forest 的机械钻速预测建模
2.1 机械钻速影响因素分析
本次实例数据选用某油田特定区块下的井史数据。 表1 列举了部分数据。 文中对此进行初步筛选后,拟以表1 中的特征参数作为影响因素。
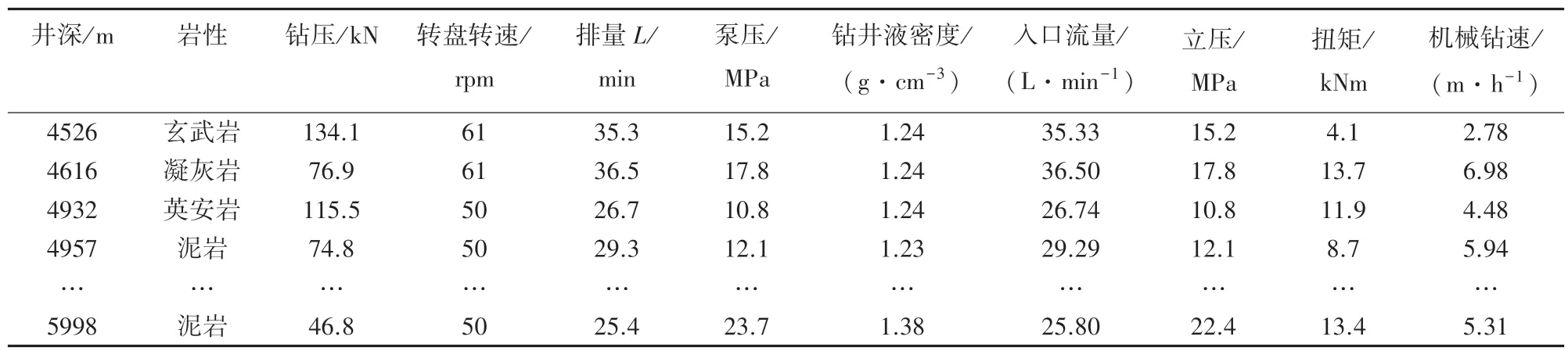
表1 机械钻速预测模型输入数据表Tab. 1 Partial data of ROP prediction
2.2 输入参数预处理
2.2.1 CatBoost 对类别变量的处理
CatBoost 编码器可以避免均值编码对y变量敏感的弊端,并减少过拟合且不改变数据集的大小。其基本思想也是计算某一行数据的特征编码时,避免使用到该行的目标值(Target)。 首先,将相同类别的元素分组,求出每一组target的平均值作为其对应的编码。 然后,引入“前缀和”的思想,即对于某一类别的某一个值,其对应的编码值等于其之前行的所有该类别值的对应target的平均值。 前缀和定义如下:
本文中,岩性作为有11 种类别的变量,将采用CatBoost编码器对类别特征无序且对类别数量较多的目标变量编码方式进行处理。 编码结果见表2。

表2 类别变量编码结果表Tab. 2 Category variable coding results
2.2.2 卡尔曼滤波数据降噪处理
卡尔曼滤波是一种借助线性算法的方程,通过系统输入输出观测数据,对系统状态进行最优估计的算法。
卡尔曼滤波分为2 个步骤。 第一步,基于上一时刻状态数据预测当前时刻状态。 第二步,是综合第一步预测出的当前时刻状态和实际观测状态,估计出最优的状态作为滤波的结果。 对此数学方法,可用如下公式进行描述:
这里,式(4)是状态预测;式(5)是误差矩阵预测;式(6)是卡尔曼增益计算;式(7)是状态校正,运算输出的就是最终的卡尔曼滤波结果;式(8)是误差矩阵更新。
卡尔曼滤波对其中机械钻速数据的降噪前后对比如图2 所示。 分析图2 可知,经过卡尔曼滤波处理,本来包含许多尖峰和突变的原始数据相较于之前变得轮廓更加清晰,峰值不再尖锐。 所以卡尔曼滤波有效去除了原始数据中明显的信号干扰,在处理过后并未改变原数据的变化特性。

图2 卡尔曼滤波降噪处理对比图Fig. 2 Comparison of Kalman filter denoising
2.3 特征选择
在工程实践中获得的钻井数据类别繁多,将收集到的所有特征参数输入机器学习模型进行训练,会导致模型维度过多,也就无法有效提升拟合程度。为此,利用最大互信息系数(MIC), 最大程度地根据信息寻找参数之间线性或者非线性的关系。
最大互信息系数计算公式如下:
其中,a、b分别表示在x,y方向上的区域分割个数;B表示可设置参数;I(x;y)表示MIC值。 式(9)为在不同规定范围下得到各自的MIC值,并在归一化处理后来求得最大值。
钻井特征参数最大互信息相关分析图如图3 所示。 由图3 可见,立压与泵压、相关性极强(0.98),排量和入口流量、相关性极强(0.98)。 因此,通过MIC计算值与实际工程原理结合筛选井深、岩性、钻压、转盘转速、钻井液密度、入口流量、立压、扭矩等8 项参数筛选作为机械钻速预测模型的输入变量。

图3 钻井特征参数最大互信息相关分析图Fig. 3 MIC of drilling characteristic parameters
2.4 机械钻速预测模型的建立与实验验证
这里,研发建立了GA-Random Forest 机械钻速预测模型。 随机森林模型中涉及到的2 个主要参数是树的深度和决策树的数量,所以利用遗传算法对其进行优化。 首先,根据经验设定树的深度和决策树的数量,并在遗传算法中设定繁殖的代数为100,种群的数量为500,同时设定交配的概率为0.6,变异概率为0.01。 当代数达到设定的100 代时算法停止,给出最优的一代和其中解码后的参数。 研究中得到的繁殖迭代过程参数见表3。

表3 每一代繁殖参数表Tab. 3 Parameters value of each generation
最终,确定最优代为第76 代,n_estimators为120,max_depth为16,R2_score为0.937 4。
为了证明GA-Random Forest 机械钻速预测模型在本次实验中与其他模型相比具有更高精度,故选取决策树回归模型、KNN 回归模型、SVR 回归模型进行对比分析,实验结果如图4 所示。
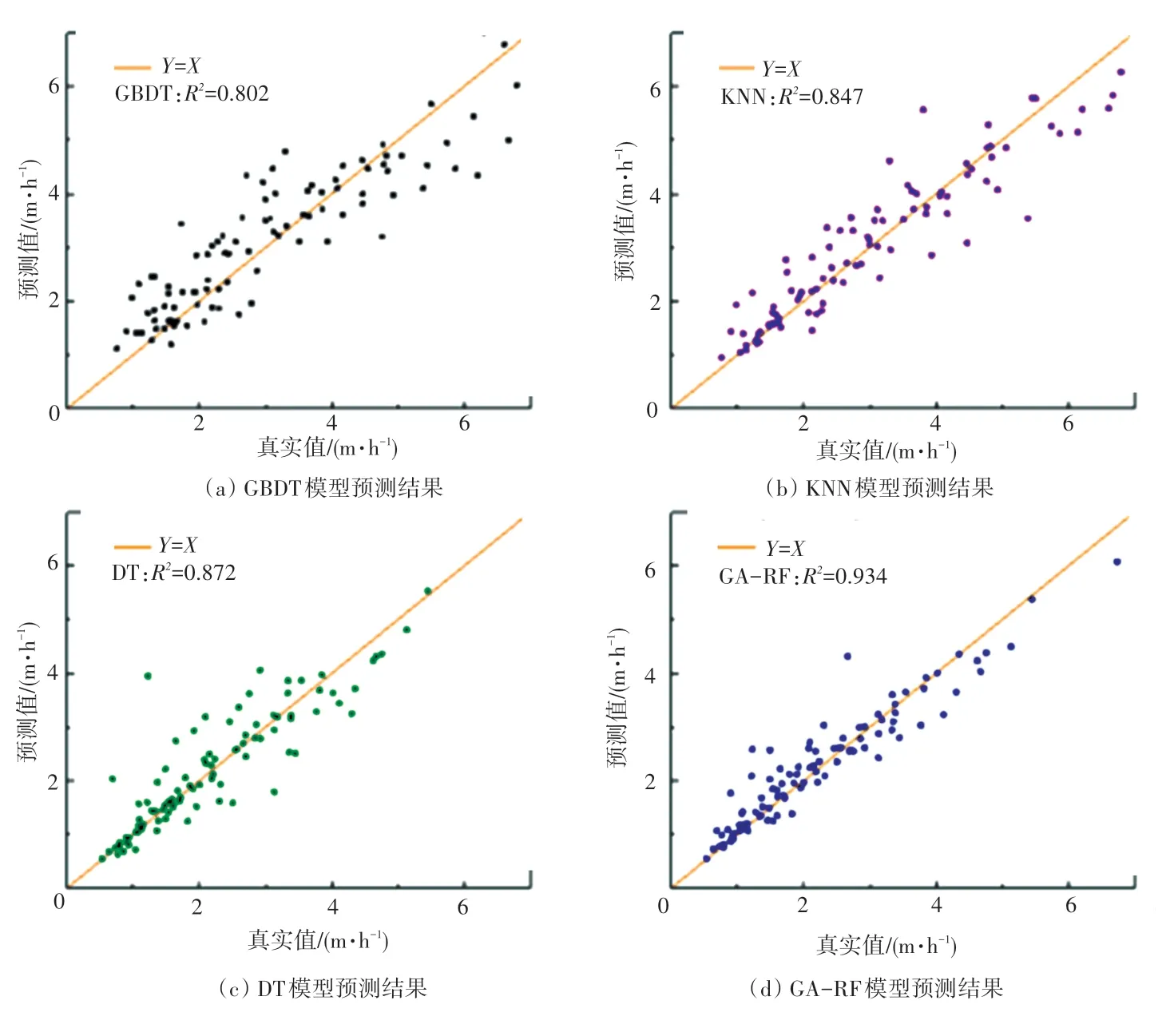
图4 多模型预测结果对比图Fig. 4 Prediction results of multiple models
为比较模型的优劣,用拟合优度R2作为区别的标准。R2越大,模型的解释程度越高,预测点在回归直线附近越密集。 由图4 可见,GA-Random Forest 模型的预测值与实测数据曲线变化一致、对应数值点相近,并且该模型的R2值优于其他3 种算法模型。 因而可知,本文研究的机械钻速预测模型精度更高。
3 结束语
(1)使用CatBoost encoder 得到更直接表示分类变量和目标变量之间的关系的目标编码,并且有效降低模型过拟合。
(2)去除多余的干扰获得真实有用的数据,使用卡尔曼滤波降噪处理后达到信噪分离的效果,进一步提高算法模型的拟合程度。
(3)本次研究提出的方法在随机森林的基础上又提高了计算准确度和适应能力,并通过简化模型的结构,有效提高了计算速度。
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
北京航空航天大学学报(2017年9期)2017-12-18
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
电源技术(2016年9期)2016-02-27
电源技术(2015年1期)2015-08-22
郑州大学学报(医学版)(2015年1期)2015-02-27
现代电子技术(2014年10期)2014-07-19
电子设计工程(2014年6期)2014-02-27
