
基于SOM-Kmeans算法的司机驾驶风格研究
2023-04-21 12:12罗雲潇张海瑞张振京宋业栋屈亚祥
时代汽车 2023年8期
关键词:因子分析
罗雲潇 张海瑞 张振京 宋业栋 屈亚祥



摘 要:本文以车辆历史运行物理参数为研究对象,使用SOM-Kmeans聚类模型识别出司机的驾驶风格,为发动机经济优化提供实际指导意义。首先基于K-means聚类优先识别出了九种行驶工况,从中选取加速行为对应的三类标签以驾驶循环为单位做特征统计;随后利用因子分析对数据降维,并通过SOM-Kmeans模型进行聚类,得到温和型、普通型和激进型三种类别的驾驶风格。
关键词:行驶工况 驾驶风格 因子分析 SOM-Kmeans
Study on Driving Style of Drivers based on SOM-Kmeans Algorithm
Luo Yunxiao Zhang Hairui Zhang Zhenjin Song Yedong Qu Yaxiang
Abstract:This paper takes the physical parameters of vehicle historical operation as the research object, and uses the SOM-Kmeans clustering model to identify the driving style of drivers, providing practical guidance for engine economic optimization. Firstly, nine driving cycles were identified preferentially based on K-means clustering, and three types of tags corresponding to acceleration behaviors were selected to make feature statistics in driving cycles. Then factor analysis was used to reduce the dimension of the data, and the SOM-Kmeans model was used for clustering, and three types of driving styles, mild, ordinary and radical, were obtained.
Key words:driving cycles, driving style, factor analysis, SOM-Kmeans
1 引言
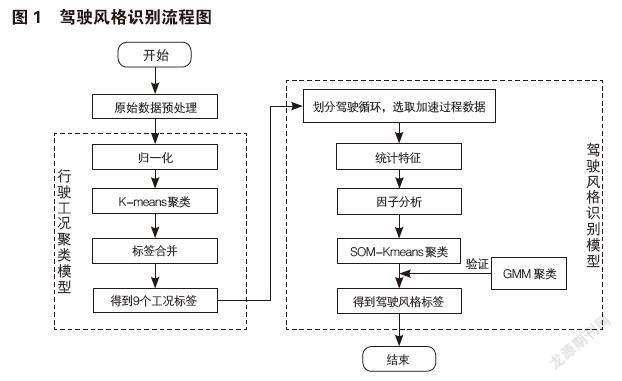
卡车、工程车等大型车的高耗油量使众多企业运营成本居高不下,且鉴于能源危机与全球变暖愈发严重,节省燃油已成为全球共识[1]。本文通过对司机在驾驶过程中的加速行为进行分析,辨识不同司机驾驶风格,针对不同驾驶风格优化油门踏板MAP,为节省油耗提供方法支持。汪益纯等[2]从交通安全出发,根据实际案例构建出影响初驾者的驾驶行为类别及其差异性;黄斐等[3]采用问卷调查的方式,按照因子分析与AHP相结合的模型对驾驶员倾向性进行建立评价体系进行辨识;吕明等[4]从对车辆的性能要求出发,使用SOM神经网络对起步工况进行聚类得到三种风格标签:温和型、普通型和激进型;王科银等[5]使用SVM驾驶风格识别模型方法与ANN模型进行了对比,得到SVM模型识别精度更高;姚柳成等[6]先使用相关分析与主成分分析对数据进行筛选与降维,再根据K-means算法对驾驶行为进行分类辨识,也得到三种驾驶行为风格。本文从节省油耗出发,使用SOM-Kmeans分类方法有效了解数据内部所隐藏类别,构建行驶工况聚类模型与驾驶风格识别模型,将司机驾驶风格分为三类,其中具体技术路线如图1所示。
2 数据的采集及预处理
2.1 数据采集
本文选取某车辆(路线:许昌-上海)2021年6月至2021年12月的行驶数据,采集频率为1s,共计300多萬条。数据集共包含有车速、加速度、油门踏板开度、踏板需求扭矩、瞬时油耗、刹车等变量。
2.2 数据预处理
2.2.1 异常值处理
车辆在行驶过程中可能因为信号不稳定使得数据传输产生错误和偏差,从而导致异常。依据参数的物理意义,对于异常数据使用前三个相邻的数据均值进行替换。对于数据原本的缺失值同样以上述方式进行填补。由于本文研究侧重驾驶过程中的司机行为,故排除速度为0的样本点。
2.2.2 加速度滤波
加速度传感器在采集数据过程中,可能由于人为、技术以及环境等因素的不确定性,使得原始数据产生各种噪声,为了得到平衡有效的频带幅度,利用巴特沃斯低通滤波算法来抑制噪声。
2.2.3 巴特沃斯低通滤波算法
巴特沃斯滤波器其幅度平方函数的表达式为
式中:为滤波器阶数,为3dB低通滤波器截止频率。该滤波器在通带和阻带内的幅度响应随截止频率的增加而减小,且下降速度与滤波器阶数有关,阶数越大,幅度下降就越快,过渡带就越窄。故巴特沃斯低通滤波器的特性完全由阶数和3dB截止频率决定[7]。通过对比不同参数模型,选取3dB截止频率为0.2,阶数为4。相关结果如图2所示。
3 行驶工况聚类模型
3.1 归一化
不同变量间量纲不同,使得模型训练过程中对数值大的变量学习过多,而对数值小的变量训练不够充分,最终模型表现不好,为消除量纲影响,对数据进行标准化处理。
最大最小归一化,是利用数据列中最大值和最小值进行标准化处理,将原始数据线性化地转换到[0,1]之间,具体公式为
式中:为样本数据的最小值,为样本数据的最大值。本文使用最大最小归一化的方法对原始数据进行标准化处理。
3.2 k-means聚类
3.2.1 K-means聚类原理
K-means属于无监督聚类算法[8],其基本思想为对于给定的数据集,按照样本间的距离大小将样本集划分为K个簇,使簇内的点尽量紧密相连,而簇间的距离尽可能大。我们的学习目标就是让平均误差最小化,即
式中:是簇的均值向量,也称为质心,表达式为
K-means算法流程:
输入:样本集,聚类类型数量值;
输出:簇划分;
1)从数据集中随机选取个点,作为初始化的中心点:;
2)计算剩余每个样本到中心点的距离:,将归属到距离最小的中心点簇上;
3)对重新计算簇中心;
4)如果簇中心改变,则返回步骤2,如果簇中心保持不变,则算法结束。
3.2.2 K-means聚类及合并
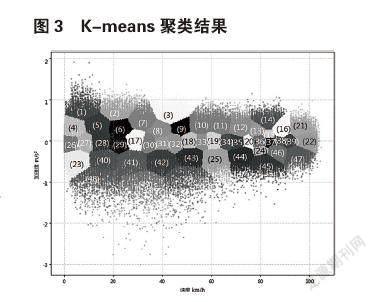
对于聚类数量的选择,本文主要考虑两方面。一是聚类数量是否能够完整划分驾驶员的数据分布空间,二是要保证聚类类别尽可能少,使得模型复杂度降低,减少运行时间。为保证最终分类边界合理且便于后续模型使用,采取从少到多的逐步搜索方法选定k值,选定k=50进行建模,最终聚类效果见图3。
为简化模型,尽可能减少标签数量,将速度按照(0,30]、(30,60]、(60,],同时加速度按照(,-0.1]、(-0.1,0.1]、(0.1,]区间进行划分,两两组合后合并聚类中心,最终得到低速减速、低速巡航、低速加速、中速减速、中速巡航、中速加速、高速减速、高速巡航、高速加速这9类行驶工况,合并结果如图4所示。
4 驾驶风格识别
4.1 特征统计和因子分析
4.1.1 特征统计
为更好识别驾驶风格,本文将数据按照驾驶循环(从点火开始至熄火结束)划分为若干子集,并对其进行相应的特征统计。驾驶风格可以体现在很多具有统计意义的特征数据上,比如速度和加速度的分布区间能够体现出驾驶员某种驾驶偏好、加速度和踏板开度的均值和众数可反应驾驶员对车辆动力性需求、速度和加速度的方差又可体现驾驶员的操作稳定性等等。在行驶工况合理分类情况下,驾驶员的驾驶行为具有统计意义上的规律性。由于本文数据采集于上海至许昌往返线路中的某台快递车,其在固定条件下体现出的规律性将更加明显,具有较强的工程意义。
鉴于本文着眼于加速状态,故选取低速加速、中速加速与中速巡航三類行驶工况进行特征统计。首先统计车速和加速度分布情况,并对不同行驶工况下的车速、加速度、踏板开度和扭矩分别计算其均值、方差和众数,随后统计不同驾驶循环下的平均油耗以及踩刹车的总次数。
4.1.2 因子分析
因子分析是一种成熟的指标体系构建方法,其主要目的是找出不可观测的潜在变量作为公共因子,并解释公共因子含义来探讨数据内部结构。该模型可将观测变量分解为公共因子、特殊因子与误差项三部分[2]。假设有个样品,个变量,是随机向量,是要找寻的公共因子。
最终的因子分析模型为:
其中,为公共因子,即各观测变量所共有的因子,解释变量间的关系;为特殊因子,表示变量不能被公共因子解释的部分;为第i个变量在第个公共因子上的因子荷载。
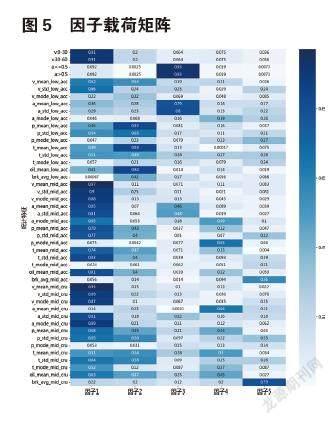
由于所统计的特征较多,且不同特征间相关性较大,故利用该方法进行降维以探讨结构。同时计算KMO统计量,并进行Bartlett’s test来观察变量间的相关程度。根据计算,KMO=0.827>0.8,表明变量间信息重叠度较高,适合因子分析[5]。由Bartlett’s test看出,P <0.01,应拒绝原假设,即认为变量间存在相关性。对于因子数量的选择,本文先使用Kaiser准则进行初步计算,再根据具体试验分析,最终选定5个公共因子。
图5为所得的因子载荷情况,可以看出第一公因子在速度相关变量具有高负载,将其称为速度因子;第二公因子与踏板开度和油耗相关,则称其为油门因子;第三公因子、第四公因子和第五公因子分别于加速度、踏板开度扭矩、刹车强相关,故称它们为加速因子、踏板因子和刹车因子。
4.2 驾驶风格聚类分析
4.2.1 SOM-Kmeans模型
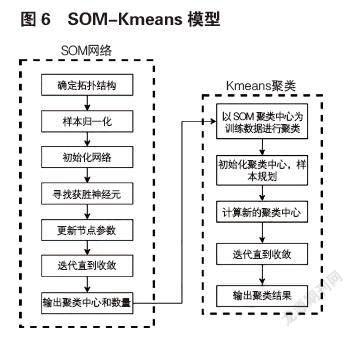
自组织映射神经网络(SOM)属于无监督学习,由Helsink大学的T.Kohonen教授在1981年提出。该模型具有良好的自组织性和可视化等特性,其结构包括输入层和竞争层,输入层负责接收数据,竞争层负责对输入进行比较分类。该网络主要利用迭代方法计算各输入向量与竞争层处理单元间的连接权值向量,通过竞争学习算法来不断调整连接权重值使其越来越接近原输入向量的值,直到输入向量与连接权值之间总距离为最小或最大学习循环时,停止训练。[4,9]
SOM-Kmeans模型基本思想为使用SOM算法进行初步聚类,随后在此基础上进行二次聚类来获取标签。其主要思路共两步:第一步,先利用SOM算法进行聚类,获得其聚类中心和中心个数;第二步,将SOM训练得到的聚类中心使用K-means算法再聚类,从而得到想要的聚类数量。
4.2.2 聚类结果验证
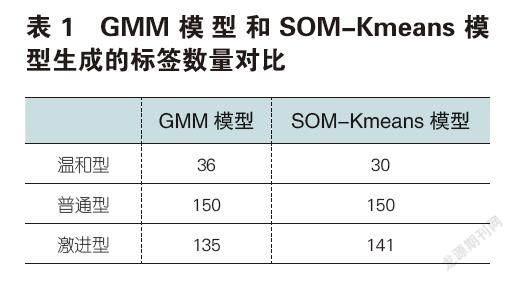
利用SOM-Kmeans模型对驾驶风格进行识别,最终将其划分为温和型、普通型和激进型三种类型。随后通过GMM模型进行验证,将两种模型产生的驾驶风格进行输出对比。如表1所示,左边是GMM模型产生的风格标签,右边是SOM-Kmeans模型产生的风格标签,两个模型的辨识结果吻合度达到91.3%,因此可认为驾驶风格的识别有效。
根据SOM-Kmeans模型得到的标签进行分析,将各个标签中的速度、加速度、喷油量相关统计量取其均值进行比较,得到如图7所示的结果,显而易见,激进型风格的速度、加速度和喷油量都是最高的,所成结果符合预期效果。
5 结论
本文基于固定路线研究驾驶员驾驶风格。通过SOM-Kmeans聚类划分出了温和型、普通型和激进型三种驾驶风格。利用GMM模型对其进行验证,根据对照模型吻合度达80%以上认为该模型有效。当前建立的驾驶风格识别模型为油门踏板MAP优化提供一个新的参数,根据不同的驾驶风格进行优化,以减少燃油消耗,降低运营成本。
参考文献:
[1]张贤彪.汽车驾驶油耗影响因素及节油策略分析[J].时代汽车,2020,(09):18-19.
[2]汪益纯,陈川.基于因子分析法的初驾者驾驶行为研究[J].武汉理工大学学报(交通科学与工程版),2012,36(05):1064-1068.
[3]黄斐,邹忠义,谢光旺. 基于AHP和因子分析法的驾驶倾向性评价体系研究[J]. 中国市场,2018,(21):67-75.
[4]吕明,张滢,冯先泽. 基于SOM神经网络的多工况驾驶风格识别[J]. 汽车实用技术,2021,46(02):108-112.
[5]王科银,杨亚会,王思山,等. 驾驶风格聚类与识别研究[J]. 湖北汽车工业学院学报,2021,35(03):1-6.
[6]姚柳成,邹智宏. 基于数据降维与聚类的车联网数据分析应用[J]. 汽车实用技术. 2022,47(04):24-28.
[7]张斐,刘志杰. 加速度传感器信号数据处理中滤波算法的应用[J]. 电脑与信息技术,2018,26(03):1-4.
[8]易茹. 基于K均值聚类算法的数字媒体推荐方法研究[J].长春工程学院学报(自然科学版),2020,21(04):99-102.
[9]赵文均.基于SOM和BP网络的K均值聚类算法分析[J]. 电脑知识与技术,2020,16(09):24-26.
猜你喜欢
旅游学刊(2016年9期)2016-12-06
中国集体经济(2016年26期)2016-11-19
大经贸(2016年9期)2016-11-16
大经贸(2016年9期)2016-11-16
中国市场(2016年38期)2016-11-15
企业导报(2016年20期)2016-11-05
中国市场(2016年33期)2016-10-18
商(2016年27期)2016-10-17
商(2016年27期)2016-10-17
商业经济研究(2016年14期)2016-09-14
