
分布式系统的可观测性建设
2023-04-25 03:51陈根
计算机应用文摘·触控 2023年8期
关键词:可视化
陈根
关键词:分布式系统;可观测性;可视化;链路追踪
1概述
随着社会生产力的进步,社会分工细化,新的职业出现,新的商业模式诞生,为满足人们的生产生活需求,信息系统的建设方式和架构也在与时俱进,信息系统处理越来越多的数据,处理速度也越来越快,同时要满足频繁多变的业务需求,分布式系统逐步浮出水面。本文不讨论分布式系统建设方案,重点就分布式系统的可观测建设展开论述。
2可观测基础能力建设
分布式系统不同于传统的单体系统或者MIS系统,由于其业务量庞大、系统架构复杂、组件关联密切,为运维带来极大挑战。当出现异常时,告警能力、故障根源分析判断能力、故障快速处置能力就显得非常重要,其中基础能力从监控数据的采集、汇聚、异常监测和告警等阶段进行阐述。
2.1采集能力
分布式系统的模型建设是先决条件,从分布式系统的特点来讲,往往采用容器化部署,使用Kubernetes作为容器编排工具,可以按照Deployment-Pod-container的结构来设计。模型建设后,通过各类数据采集器获取模型实例的运行状态和配置数据,此时需按照统一的规范来完成。数据采集分为3种类型,分别是指标数据采集、日志数据采集、其他类数据采集。
2.1.1指标数据采集
对于操作系统以及运行在操作系统上的数据库、中间件等基础软件,通常采集其CPU、内存、文件系统、磁盘10、网络吞吐量等使用情况数据。操作系统、数据库等IT基础设施的指标建议通过操作系统文件如/proc/stat等采集,避免使用操作系统命令,以减少对源系统的资源消耗。
对于应用系统来说,根据Google SRE指南,包括TPS、成功率、响应时间、交易量、错误率等黄金指标,数字化模型建设好后的各个模型实例都可以参考这些指标,采用key-value键值对方式以json格式上报。
采集容器指标可通过多种框架实现.如sidecar模式或demonset模式,也有多种开源框架支持,如Istio等,一般采用Prometheus进行容器指标数据的采集。
应用指标也有2种实现方式,一是通过应用系统计算好指标,通过API和Socket供数。二是监控系统采集应用输出的日志经过约定的规则计算。指标数据需覆盖各地域、站点、单元(租户)、集群、容器等维度,采集数据应携带必要的元数据信息,包括站点、单兀、IP、应用ID、集群ID等,以供后续的汇聚计算和故障定位使用。
2.1.2日志数据采集
日志包括普通文本日志、操作系统日志、Tracing日志等,利用文件采集器读取日志数据,逐行读取。Tracing日志也可以通过写临时文件的方式进行采集,最好是采用远程日志方式,类似指标采集的方案供数、时效性更高,如采用log4j的RemoteLogging功能,配置SocketAppender写到远程服务器。
2.1.3其他数据采集
以上2种模式是主动数据采集,为了满足其他场景需要,采集框架应该建立通用数据上报接口供其他应用或者组件调用。分布式系统的应用与组件应提供可用性探测接口,用于监测其可用性。
以上3种采集功能建设的同时,还应关注非功能性要求,以降低对源系统或者组件的影响。采集器需具备热加载能力,其行为可被灵活定义和配置,包括日志路径、采集频率、数据报送发送频率等,同时控制对CPU、网络IO等资源的消耗。采集器应具备限流能力,流量过大应进行限流,避免影响源应用,可以设置一定的采样频率(50%和10%等),以降低网络带宽消耗,不能因为采集器异常或者数据链路异常或者流量爆发而影响源端应用和业务。采集数据上报使用星型结构,如图1所示,叶子节点部署在被采集服务器上,汇聚节点负责集中所辖的叶子节点的数据,上报至核心节点进行汇总计算和存储。汇聚节点支持横向扩展,采集器与汇聚节点建立控制通信机制以感知汇聚节点的动态变化,灵活选择需要上报的汇聚节点。可借助ribbon组件或者自研算法实现负载均衡策略。
2.2汇聚计算和异常监测
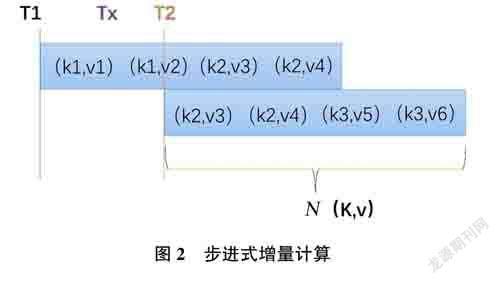
数据采集到汇聚节点后,根据不同数据类型采用不同计算法方法进行异常监测和计算。指标数据较规整,寻找异常点比较方便,适合直接进行程序计算,使用Java,Python,Golang等都可以对其进行简单编码、实现流式计算模式。同时,也能对接通用算法,如单指标异常监测、基线算法等。以计算CPU使用率是否超过阈值为例,程序开辟队列保存接收到的KV键值对(Tx为采集间隔),T1時刻读取队列中的Ⅳ个数值来计算平均值、峰值、中位数等,T2日寸刻再读取队列中的Ⅳ个数字进行计算。T1,T2,N(滑动窗口)可根据应用系统的业务特点、交易量等设定,』7v越小越灵敏,越大越迟钝。如果是联机系统,适当减少T1,T2间隔,缩小Ⅳ。当T1*N*T2时,步进式增量计算,每次计算的数据都是新鲜数据。具体如图2所示。
以上内容也可以采用通用的开源解决方案(如Zabbix,Prometheus等)实现。
除了直接计算,对于时效性有一定容忍度的指标,如数据库表空间、业务序号、当日累计交易量等,可引入趋势预测算法来计算,以获得更好的监控表现,进而提前发现异常,及日寸介入处置。
联机系统监控往往和业务模式有很大关系,参与交易的角色和渠道等因素都属于监控的范围,因业务需要可设计多维度灵活可配置的监控模型来支持。通常可以使用以下2种方案。
2.2.1预置模型的设计和实现
对于每笔交易,根据交易要素拆分成多个KV键值对,交易的成功失败结果也保存到每个KV键值对。用户根据实际需要,在管理页面端配置需要监控的交易角色、渠道等交易因素(维度),监控程序按照配置统计这些因素组成的维度的交易量、成功率等。
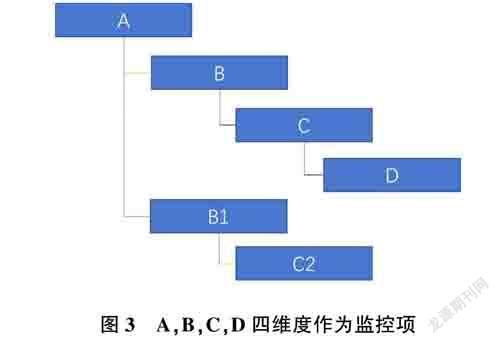
比如,配置A,B,C,D四个维度作为监控项,监控程序对每笔交易的A,B,C,D四个维度都进行统计,形成统计结果KV键值对,Key可以设置为A,B,C,D,根据不同取值统计汇总,并按照一定的时间周期判断是否超阈值,进而产生告警。设计维度配置时,按照一定的逻辑顺序组合,四因素的Key值缓存在内存中,以快速匹配,进而提升计算效率。具体如图3所示。
2.2.2动态计算模型的设计和实现
相较于预置模型,动态计算就更复杂。对交易做降维处理,减少计算量。对于N维的交易来讲,全维度动态计算是海量的,也带来一些没有价值的估算。降维计算有助于减少干扰,聚焦在有意义的数据上。具体流程如下。
(1)计算Ⅳ维中所有一维数据的指标(TPS、成功率、响应时间、交易量)。
(2)从中寻找指标最差的维度Dx。
(3)以维度Dx为基点,统计其他参与交易的角色指标,并找出可疑组合。
(4)列出组合供用户选择。
(5)告警收敛。
往往一个异常会产生多个报警,这时需要借助一些收敛算法压缩告警量,以减少干扰,快速定位问题。基于CMDB的关联关系,将同一个CI的告警归集到一个主要告警上,同时将与之关联的上游CI告警进行关联,以“组告警”的方式呈现给用户。在IT基础设施发生故障时,这种收敛算法能起到很好的效果。以某台物理机故障为例,监控系统产生诸多告警:硬件管理平台监测到硬件故障产生的告警、连通性监测发现物理服务器不可达告警、虚拟化平台或者容器管理平台发现虚拟机宕机或者容器下线的告警、分布式系统自身的服务调用发现某服务不可用的告警、交易监控系统发现瞬时的交易成功率下降后者交易响应时间变长的告警。这些告警都和物理机异常相关。告警收敛算法设定一定的时间(因分布式系统对基础设施异常的敏感度不同,通过测试可以得出这个值),如3分钟内,那么相关的告警都可以收敛到此物理服务器宕机的告警上,前提是在CMDB中建立相关的关系,即物理机与虚拟化服务器的关系、物理机与容器的关系、容器与逻辑服务的关系、交易和逻辑服务的关系(通过链路日志关联)[1]。
经过测算,此类收敛模型的有效率可达50%以上,大大降低了對信息的干扰,并可在可视化图表上直接显示异常点。
在Tracing日志中根据Tracingid形成链路,相同链路产生的告警也可以归集到一起,并结合CMDB关联到CI上,以收敛到较小的范围。
3可视化能力建设
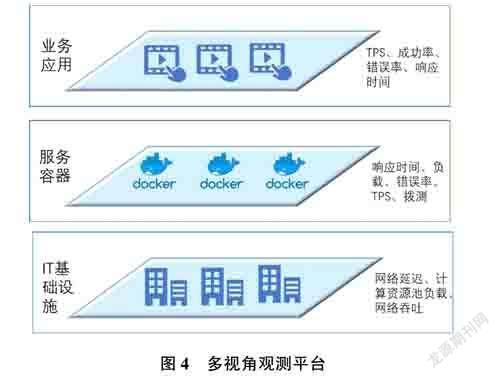
从分布式系统采集的运行数据,经过采集汇聚和异常监测计算,得到了分布式系统的运行状态数据以及可能的异常点,通过系统整合和集成,建立分层次、纵向关联的多视角观测平台,集中展示分布式系统的运行信息,从多个维度建立可视化展示配置视图、关注性能的指标视图、排查分析的日志视图以及链路视图等。具体如图4所示。
配置视图。用于展示分布式系统的配置数据及关联关系,包括服务器与操作系统配置、应用与容器、分布式数据库以及其他组件等。
指标视图。用于展示分布式系统的应用及依赖服务/组件的指标类数据,指标视图提供固定格式的数据,通过定制仪表盘方式实现个性化changing展示。
日志视图和链路视图。用于展示分布式系统的文本日志,包括系统日志、应用日志、数据库日志,以及相关的服务与组件的文本日志,提供常规的基于时间、节点、文件名、关键字等条件的搜索功能,并提供基于spl语法的高级查询功能。通过日志时间,所属的文件、进程、容器等与链路日志进行关联,以查询tracelD的单笔链路数据、指定时间和节点范围的链路数据清单[2]。
3.1全局健康视图
将分布式系统的SLA设定核心监控指标作为全局健康视图的主要展示数据,健康视图简明扼要地显示系统的状态,其具有高度的概括性,如全局交易成功率、资源可用率、全局交易响应时间等,若指标出现异常,则标记为红色,并结合其他的视图进行下钻分析,找到引发异常的根源。
可建立“应用全局性能指标”,以应用为中心,将Tracing,Metric,Log多维数据进行融合,从而基于业务视角,统一性能评价标准,主动发现性能瓶颈、快速感知故障、高效故障恢复,保障应用系统连续稳定。
3.2部署架构视图
综合性视图,将IT基础设施到分布式系统的各个组件进行全面展示。构建此视图时,可以自底向上展示网络、服务器、容器、逻辑服务、交易的数据,每个节点可显示更为详细的具体运行数据。当出现故障时,部署架构视图以红、橙、黄等颜色进行警示,打开故障点后即可进入故障排查视图。
3.3故障排查视图
直接显示故障内容,一般是告警或者收敛后的组合告警,视图展示关联该故障节点的交易运行情况和IT基础设施的情况,以及链路视图等,可根据展示的内容和故障染色等进一步打开故障点以分析故障。
分布式系统可观测性建设是一项系统性、综合性工程,其核心在于采集和汇聚计算上,利用成熟的异常监测算法可以定位到一些故障点,结合分布式系统建模以及告警收敛算法,将异常点与应用、IT基础设施的运行日志关联起来.可有效帮助开发和运维人员全面掌握生产运行信息,快速定位故障和解决问题,从而确保分布式系统高效稳定运行。
猜你喜欢
江苏安全生产(2022年7期)2022-08-24
世界科学技术-中医药现代化(2022年3期)2022-08-22
北京测绘(2022年6期)2022-08-01
选煤技术(2022年2期)2022-06-06
师道·教研(2022年1期)2022-03-12
云南化工(2021年8期)2021-12-21
北京测绘(2021年7期)2021-07-28
海洋信息技术与应用(2020年1期)2020-06-11
山东农业工程学院学报(2019年11期)2020-01-19
传媒评论(2019年4期)2019-07-13
