
基于深度学习目标识别的航天员训练场景理解技术
2023-04-26 08:27孙庆伟胡福超晁建刚
载人航天 2023年2期
陈 炜 孙庆伟 胡福超 晁建刚*
(1.中国航天员科研训练中心人因工程重点实验室, 北京 100094; 2.中国航天员科研训练中心,北京 100094; 3.航天工程大学宇航科学与技术系, 北京 101416)
1 引言
航天员增强现实(Augmented Reality, AR)训练是通过AR 头戴设备呈现虚拟辅助信息,如任务流程指引、设备操作模拟等,给航天员直观的操作展示,满足其自主训练的需求[1-2]。当前增强现实技术可以满足大部分地面训练任务,但针对场景空间布局发生较大变化,或者需改变操作物体空间位置时,可能发生虚实匹配失效的问题。这是因为目前的AR 定位技术依赖于几何方法,包括空间锚点(Anchor)和预设标志物(Mark)2类。这2 种方法中,目标位置在空间中是提前固定的,只能应用于静态场景。传统AR 设备[3]只能进行场景几何空间的识别,无法感知场景空间的动态变化。因此,为扩展AR 设备的应用场景,采用一种不受静态空间限制的目标定位方法尤为重要。
基于深度学习的目标识别技术依靠神经网络的拟合能力,不依赖场景结构,可在静态或动态环境中准确识别感兴趣的目标,解决航天员地面AR 训练中的虚实匹配问题。按照是否需要产生中间候选框,基于深度学习的目标识别算法分为Two-stage 与One-stage 算法2 类。R-CNN(Region-Convolutional Neural Networks)[4]是首个将卷积神经网络应用在目标识别上的Two-stage 算法,但其识别速度和精度都不高,后续的Faster-RCNN[5]、Mask-RCNN[6]在识别效率上不断提高。相比之下,One-stage 的识别算法不需要产生候选区域,而是端到端地直接得到目标的位置和类别概率,主流算法包括SSD(Single Shot MultiBox Detector) 和YOLO(You Only Look Once) 系 列。SSD[7]在识别速度和精度之间做了平衡,达到了多尺度识别的目的。YOLO v5[8]是目前应用最广泛的网络,采用了多尺度特征融合,在有限样本量的情况下也能获得较好的识别准确率,较适合场景固定、样本量小的航天训练场景。
除了目标识别,AR 空间定位还需要目标空间位姿信息,即三维位置和三维姿态。按照使用的输入数据,物体的空间位姿估计方法可分为基于图像的方法和基于点云的方法。早期基于图像的六自由度位姿估计方法处理的是纹理丰富的物体,通过提取显著性特征点[9-10],构建表征性强的描述符获得匹配点对,使用PnP(Perspective-n-Points)方法[11-12]恢复物体的六自由度位姿。对于弱纹理或者无纹理物体,适合基于模板匹配的方法[13-14],检索得到最相似模板图像对应的六自由度位姿,也可以通过机器学习投票[15],训练得到最优位姿。基于点云匹配的方法通过点云匹配算法与模板模型对齐,将位姿估计问题转换为2个点云之间的坐标变换[16]。基于点云匹配的方法具有不受纹理条件影响、计算简单、准确性高等优势。航天训练场景空间狭小、光照条件复杂,纹理信息变化大,更适合采用点云模板匹配的方法进行位姿估计。
本文针对航天员地面训练中AR 设备依赖预设标志物或空间锚点的情况,提出一种基于深度学习目标识别和点云匹配的空间定位方法,以动态实现空间目标识别与位姿估计。
2 方法
本文提出的方法实现流程如图1 所示。首先,利用AR 设备对航天训练任务场景进行扫描,采集彩色图像与深度图像;然后,利用彩色图像,通过YOLO v5 神经网络实现操作目标识别;根据识别获得目标像素区域,结合深度图通过几何反投影实现目标点云分割,与目标CAD 模型点云进行ICP(Iterative Closest Point)点云匹配后估计出目标的三维空间位姿;最后,通过空间坐标系变换,实现目标在AR 空间的动态定位与虚实匹配。

图1 算法结构总览Fig.1 An overview of the algorithm
2.1 任务场景扫描
本文采用的AR 设备为微软的Hololens 2 增强现实眼镜,其内嵌的SLAM(Simultaneous Localization and Mapping)功能可以实时确定自身所在的世界坐标系位姿。Hololens 2 集成了多种相机传感器并在研究模式下提供了接口,可实时获取视频帧及相关信息(如分辨率、时间戳等),本文用到的彩色和深度图像格式如表1 所示。

表1 图像格式Table 1 Image formats
航天员佩戴Hololens 2 在任务场景中自由活动,视觉传感器扫描任务场景,实时获取彩色和深度图像数据流,通过局域网传输给后端服务器。
2.2 基于YOLO v5 神经网络的目标识别
2.2.1 数据集制作
神经网络的训练高度依赖数据,针对航天员地面训练场景制作目标识别数据集。实验人员佩戴Hololens 2 模拟航天员训练,在任务场景中自由运动,视觉传感器获取的彩色图像通过局域网传输到后端服务器并保存。本文应用场景相对固定,对网络的泛化能力要求不高,因此不需要制作超大数据集即可满足对网络的训练需要。
局域网的传输速率为3 fps,实验中在3 min内采集500 张有效图像(去除运动模糊样本),每隔10 帧选取一帧作为数据集,共得到50 帧。YOLO v5 集成了数据增强功能,且航天员地面训练场景为固定结构,因此少量的数据即可完成对网络的训练。
使用LabelImg 作为标注工具,对场景中阀门结构进行标注。标注格式如[0 0.490132 0.757009 0.140789 0.224299],其中0 表示类别标签,后面4 个数字表示阀门所占像素坐标的4个顶点。
2.2.2 网络结构
航天员地面训练场景相对固定,需要操作的结构多为阀门、开关等小目标,其像素数量占整幅图像的比例较小。YOLO v5 是目前综合性能最强的目标识别神经网络之一,该神经网络推理速度快,精度高,自带数据增强算法和多尺度金字塔特征融合算法,在训练数据样本量较小、图像分辨率较低的情况下,仍能获得较好的识别结果。因此本文目标识别算法采用YOLO v5 深度神经网络。
该神经网络结构[17]如图 2 所示。其中Focus结构用来拓展特征图的通道数;BottleneckCSP 结构借鉴了CSPNet 的思想,降低了网络计算参数;Conv 为卷积网络层;SPP 为空间金字塔池化层;Upsampling 为上采样层;Contact 为连接层。网络采用经典的金字塔特征融合方法进行多尺度特征融合,将相同尺度的特征进行拼接,最终得到了3个不同尺度的深度图像特征,每个尺度中同时包含其他尺度的信息。在3 种不同尺度的特征图上分别设置了3 组不同大小和形状的锚框,每个锚框中的特征经过两层卷积,预测目标类型的同时回归目标的包围框。

图2 YOLO v5 网络结构图[17]Fig.2 Structure of YOLO v5[17]
误差函数通过最小外接矩形交并比构造。损失函数见式(1):
式中,A为神经网络输出包围框,B为包围框真值,ρ(A,B) 计算了2 个包围框中心点的欧氏距离,c表示2 个包围框最大外接矩形的对角线长度。式中IoU,v,α的表达式见式(2)~(4)。
式中,IoU为神经网络输出包围框和包围框真值的交集与并集的比值,wgt,hgt,w,h分别为包围框真值与神经网络输出值的宽和高,v用来度量长宽比的相似性,α为权重系数。
2.2.3 网络训练
实验电脑GPU 为GeForce RTX 2060,CPU 为Intel i7-8750H,网络训练基于pytorch 框架。bach size 设为4,Epoch 设为400。网络训练Loss 曲线如图3 所示,Box_loss 表示Bouding Box 的loss,Obj_loss 表示目标的loss。可以看到,网络训练Loss 下降很快,且在Epoch 为300 时趋于稳定。

图3 Loss 曲线Fig.3 Curve of loss
2.3 基于点云匹配的位姿估计
2.3.1 几何反投影模型
在目标识别过程中已经获得了目标在彩色图像中对应的像素位置。因彩色图像和深度图像分辨率不一致,因此需要采用图像配准算法将彩色图像与深度图像对齐,获得2 种图像像素间的映射关系。经过配准,可以将彩色图像采样到与深度图像相同的分辨率,并将目标像素位置映射到深度图像。
图4 为相机模型,深度传感器获得了相机坐标系下点的深度值,即Zc。目标在图像上的像素坐标由Bounding Box 确定,如图4 中绿色矩形框所示。几何反投影的目的是确定Bounding Box 范围内像素所对应点云的三维坐标。结合相机内参可以获得目标在相机视场内的点云。该过程见式(5):
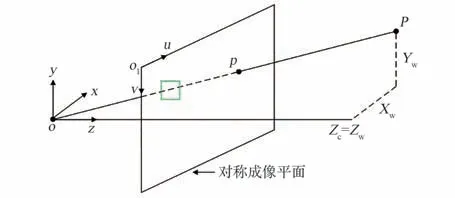
图4 相机模型Fig.4 Camera model
其中,p=(u,v) 表示像素坐标,Zc=Zw表示该像素对应的深度,cx、cy、fx、fy为相机内参数,P= (Xw,Yw,Zw) 为该像素对应的空间三维点坐标。
2.3.2 目标点云的生成如图5 所示,配准后的彩色图5(a)经过神经网络识别确定目标所在Bounding Box 的坐标见图5(b)。通过彩色图像向深度图像对齐确定Bounding Box 区域在深度图像上对应的像素坐标见图5(c),使用式(5) 计算像素对应的点云见图5(d)。

图5 目标点云的生成Fig.5 Generation of partial point cloud
2.3.3 基于ICP 算法的位姿计算
利用上述步骤提取的目标点云,通过点云匹配算法与其三维模板点云对齐,从而获得2 个点云之间的坐标变换关系。模板点云是指从该目标CAD 模型对应的标准点云。本文中使用迭代最近点算法(ICP)[17]实现点云匹配,它是一种点集对点集的配准方法,基本思路是以其中一个点云为基准,变换另一点云的位移和姿态,使得2 个点云尽可能重合。ICP 算法需要构造目标函数,通过迭代优化获得2 种点云之间的旋转矩阵和位移向量。
给定2 个点云集合见式(6)、式(7):

其中,P表示模板点云,Q表示目标点云,R为旋转矩阵,t为位移向量。此时,式(8)中优化问题转化为寻找P和Q中对应点。假设2 个点云中欧式距离最近的点为对应点,每次迭代求得新的旋转矩阵和位移向量后都重新寻找对应点,直到目标函数足够小为止。算法流程如图6 所示,配准完成后即可得到目标在相机坐标系下的位姿。根据相机位姿可进一步得到目标在全局坐标系中的位姿。

图6 ICP 算法流程图Fig.6 The flow chart of ICP algorithm
通过上述步骤,系统已获得目标相对AR 设备的位姿信息,为了在AR 空间实现动态目标的识别与定位,还需对位姿信息进行坐标系变换。坐标变换包含两方面:一是由于AR 设备使用Unity 作为渲染引擎,其显示空间遵从左手坐标系,所以首先需将位姿信息从右手系转为左手系;另一方面,需要将位姿信息从相机坐标系转到世界坐标系。假设目标相对于AR 设备坐标系的位姿为Thv,AR 设备提供了自身相对于世界坐标系的位姿Twh,则可以计算目标相对于世界坐标系的实时位姿Twv见式(9):
3 结果与分析
3.1 重点目标识别
3.1.1 评价参数
目标识别精确率(Precision)的计算见式(10):
其中,TP(True Positive)为真阳性样本数量,FP(False Positive)为假阳性样本数量。
召回率(Recall)的计算见式(11):
其中,FN(False Negative) 为假阴性样本数量。
平均精度(Average Precision,AP)是对Precision-Recall 组成的曲线(简称PR 曲线)上的Precision 值求均值,对应的就是 PR 曲线下的面积,其定义为式(12):
其中,p(r)为PR 曲线函数表达式。
3.1.2 实验结果
实验中所有结果设置IoU阈值为0.5。即TP为IoU>0.5 时的检测框样本数量;FP为IoU≤0.5 时的检测框数量;FN为未检测出的样本数量。实验中,Precision为0.995,Recall为1,AP为0.995。高精度的原因是本应用场景中训练集和测试集高度相似,且样本数较少。对于航天操作这种固定场景的任务来说,不要求网络具备较强的泛化能力,只要能准确识别出场景中的目标结构即可。
本文方法对单张图像的预处理耗时为0.2 ms,前向推断耗时为4.6 ms,非极大值抑制耗时为9.2 ms。相比于位姿传输用时(与图像流帧率相同,3 fps),目标检测耗费的时间可以忽略不计。
3.1.3 可视化效果
本文所述场景目标位姿识别算法可以在线实时运行,为了验证YOLO v5 网络的识别效果,图7展示了离线状态下的部分结果。图中绿色矩形框为网络预测的Bounding Box,准确地定位了目标所在的位置。

图7 目标识别结果Fig.7 Result of target recognition
3.2 位姿估计结果及AR 效果
图8(a)为本文方法使用的模板点云,图8(b)为使用计算结果位姿配准模板点云与目标点云的可视化效果。可以看到,虽然由于深度值的误差,目标点云与模板点云在形态上差别很大,但是通过ICP 算法仍然能够找到匹配的点云并配准成功。

图8 模板点云及匹配效果Fig.8 Effect of point cloud registration
在AR 空间中,将上式计算得到的位姿值赋于目标的虚拟三维模型,可以使其准确叠加在真实目标上,效果如图9 所示。图中虚拟阀门准确与真实阀门匹配,此过程不依赖任何标志物或空间锚点。当目标物体移动,系统可实时计算其空间位姿信息,实现动态目标的空间定位。

图9 通过AR 设备实现操作目标的显示与增强Fig.9 Information display and enhancement in the AR device
4 结论
1)本文针对航天员AR 训练需求,提出了一种基于深度学习目标识别的航天员训练场景理解技术,可不依赖任何标志物或空间锚点,动态实现AR 空间目标的定位。
2)通过YOLO v5 神经网络实现了航天员训练场景操作目标识别,获得目标的边界框,进而结合深度信息分割出目标点云,借助ICP 算法计算出目标位姿,从而实现了AR 空间动态目标的空间定位,可有效增强AR 设备场景理解能力,扩展了航天员AR 训练手段。
3)由于本文采用的AR 设备传感器能力限制,其采集的深度图分辨率较低,当采集距离较远或者目标结构复杂时会出现显著的深度误差,由此获得目标点云信息同样失准,从而导致ICP 配准估计出的位姿信息出现较大偏差。后续将从提升深度信息准确性和提高ICP 配准算法等方面进一步优化系统性能。
4)本文方法依赖目标点云的提取质量,当目标被遮挡时无法有效提取完整的点云文,后续可采用多种技术路线互补的方式满足实际工程需要。
猜你喜欢
军事文摘(2023年4期)2023-03-22
军事文摘(2022年8期)2022-05-25
小哥白尼(趣味科学)(2019年10期)2020-01-18
电子制作(2019年19期)2019-11-23
军事文摘(2019年18期)2019-09-25
光学精密工程(2016年5期)2016-11-07
光学精密工程(2016年4期)2016-11-07
重型机械(2016年1期)2016-03-01
湖北工业大学学报(2016年5期)2016-02-27
大连工业大学学报(2015年4期)2015-12-11
