
基于知识图谱的隐私保护推荐算法
2023-04-27 04:00周雨晴汤卫东刘美玲
电脑知识与技术 2023年7期
周雨晴 汤卫东 刘美玲
关键词: 知识图谱;隐私保护;推荐算法;RippleNet;差分隐私
0 引言
智能技术与人类生活紧密结合在一起,为人类的衣食住行各个方面提供了极大的便利,但也存在信息冗杂的问题。为了挖掘用户的兴趣并辅助用户在大量的数据信息中快速找到自己的目标信息,本文采用推荐算法能够较好地解决这一需求。通过对用户和项目之间的交互行为的深入研究,推荐算法可以准确地识别出用户的兴趣偏好,并将最适合他们的选择作为最终的决策依据。当前,推荐算法的发展趋势表明,协同过滤、内容分析和深度学习等技术已经成为主流,并且在不断改进和完善[1]。然而,由于推荐内容和用户数量的不断增加,传统的推荐算法面临瓶颈,包括诸如数据稀疏、冷启动和用户偏好的变化等问题[2]。为了解决上述推荐算法存在的问题,考虑通过融合知识图谱加以改善[3]。
知识图谱通过将推荐项目中的实体和关系表达为由头实体、尾实体以及描述这两个实体之间的关系组成的结构化三元组的形式,能够有效提取用户和推荐项目中的关系,探索用户有可能感兴趣的项目,进一步提升推荐的准确率。尽管融合知识图谱的推荐算法可以提高推荐的准确性,但它也会增加用户的信息量,可能会使攻击者获得更多的背景知识,从而给用户带来更大的隐私安全风险[4]。
差分隐私技术(Differential Privacy,DP)能够有效地阻止攻击者利用其丰富的背景知识来窃取用户敏感信息,从而为用户提供更加安全的隐私保护。差分隐私技术通过对数据查询结果进入随机噪声,从而有效地防止攻击者利用公开的查询结果来推测出数据集中单个元素的敏感信息,并且可以保证查询结果不会因为单个元素的变化而产生显著变化。这种查询结果的不可区分性为数据集中的个体信息提供了语义保证,因而能够实现数据隐私保护。差分隐私技术是一种有效的数据安全保护机制,面对处理数据挖掘任务时能够起到更为良好的效果[5]。
近年来,差分隐私技术在数据挖掘领域得到了广泛的应用,如分类、推荐等,以确保用户隐私安全。Boutet等人[6]提出矩阵分解算法可以利用差分隐私机制,将用户评级数据和随机梯度下降过程中添加不同隐私预算的噪声保护用户隐私,但这并不适用于包含多个实体及其关系的知识图谱推荐中;Yu等人[7]提出一种隐私保护的多任务推荐框架,该推荐框架通过在梯度下降过程和多任务模型的相关参数中添加噪声提高推荐效率和隐私安全,但也存在较高的计算量。
本文提出了一种基于知识图谱的隐私保护推荐算法。该算法将用户历史交互记录作为知识图谱中的种子集,根据用户兴趣与历史交互数据的相关度分配不同额度的隐私预算,对与种子集中历史交互数据的特征向量中添加拉普拉斯噪声,以种子集为中心,通过水波纹的形式沿知识图谱向外扩散探索用户的兴趣传播,发掘用户对项目的潜在兴趣,并计算用户对项目的交互概率。
1 知识图谱
“知识图谱”通常被描述为在某一知识领域中包含许多相互联系的实体的语义网络图,这种语义网络图通常具有有向性,并且能够帮助更好地理解这些实体之间的相互联系。知识图谱应用在推荐算法中能够体现精准、多样和可解释的特点。通过采用知识图谱,能够清晰地展示出特定领域内的实体之间的关系,并且能够更加直观地展示出这些实体之间的相互联系[8]。
知识图谱G可以以三元组的形式(h,r,t)来描述,其中h 表示头实体,t 表示尾实体,r 代表头尾实体间的关系。例如三元组(大话西游,主演,周星驰)表达了《大话西游》电影是由“周星驰”主演,“大话西游”是该三元组中的头节点,“周星驰”是尾节点,“主演”是两个节点间的语义关系。将若干个相同领域的三元组放入特定的空间,就可以建立起一个完整的知识图谱。
2 差分隐私
Dwork等人[9]于2006年提出的差分隐私技术旨在要求攻击者不能通过分析发布的结果来推断出其所属的数据集。差分隐私算法实现隐私保护的主要方法是在公开的输出结果中添加噪声,从而避免遭到差分攻击而泄露用户的隐私信息,同时需要控制加入噪声的大小以确保公开的输出结果不会受到显著的影响。差分隐私不仅能够防止被攻击,同时也能够提供更加严格的语义安全,使其成为一种广泛应用于隐私保护领域的有力工具。
定义1 差分隐私:Pm 是一个随机算法M 可以输出的所有值的集合,Sm 是Pm 的任意子集,如果随机算法M 作用于任意的一对相邻数据集D 和D’上都能满足如下性质:
可以认为算法M 满足ε -差分隐私,其中参数ε为隐私保护预算。随着隐私保护预算ε 的降低,差分隐私算法对于一对相邻数据集的检索结果的准确性会有显著提升,使得攻击者更加困难地识别和分析这对数据集,进而提升了隐私安全的水平。反之,参数ε越大时,保护程度越低。
定义2 全局敏感度:差分隐私在查询结果上加入的噪声是影响隐私保护以及数据效用的关键量。为了确保用户的隐私得到较好的保护,同时避免由于添加的噪声过多而降低数据的性价比,可以通过设置全局敏感度对加入的噪声量进行控制。
对于一个形式为f:D → Rd 的查询函数f,R 是查询函数的返回结果。当其作用于任意一对相邻数据集D和D’上,则将查询函数f 全局敏感度定义为:
其中,d 表示函数f 的查询维度,p 代表度量Δf 所使用的Lp 距离,通常是L1。
定义3 拉普拉斯机制:给定任意查询函数f:D → Rd,其全局敏感度为Δf,如果算法M 的输出结果满足下列等式,则称算法M满足ε -差分隐私。
3 融合知识图谱和隐私保护的推荐方法
RippleNet框架的输入为一个用户u 和一个推荐项目v,输出为该用户u 访问该项目v 的预测概率。u ={u1,u2…}和v = { v1,v2…}分別表示推荐场景中的用户集合和待推荐项目的集合,根据用户是否与某个待推荐项目产生过交互行为,可以定义一个用户—项目交互矩阵yuv:
RippleNet推荐过程中除了采用交互矩阵yuv外,还需要采用知识图谱G。知识图谱G 由包含着大量实体及实体间关系构成的实体三元组(h,r,t) 组成。通过RippleNet,可以利用用户的历史交互信息,自动地从知识图谱G 中推断出用户在实体集上的潜在偏好。当给定知识图谱G和用户—项目交互矩阵yuv 时,可以将用户u的k 阶相关实体集合定义为:
其中,ε0u = vu 代表用户u 的历史交互记录,这些记录可以成为用户u 在知识图谱G上进行兴趣传播的基础,而H则是最大传播跳数。
与用户u 的偏好相符度较高的项目可以被视为用户u 的在该知识图谱G 上的延伸偏好项目;根据用户的历史交互记录,以vu为起点,生成用户u 相关的各阶偏好波纹集,头实体在εk - 1 u 中的三元组集合可定义为用户u的k 跳的偏好波纹集合(ripple set):
RippleNet通过将所有推荐内容映射到一个向量v,然后利用推荐内容v,用户u 的历史交互记录vu和一阶波纹集上的三元组(hi,ri,ti )计算相关性概率pi:
可以将相关性概率pi 定义为在关系ri 的前提下用户的历史交互记录vu与推荐内容v 的关联程度,Ri 表示关系ri 的嵌入,是一个d*d 的矩阵,其中d 是特征维度。在一阶波纹集S1u中,用户的潜在偏好将会由头实体hi 传播到尾实体ti,最终在尾部形成潜在兴趣偏好的累积。最终,将相关性概率pi 作为一阶波纹集S1u上与其相应的尾实体ti 的权重,并对所有一阶波纹集S1u上的尾实体ti 按其相应的权重进行累加,从而获取一阶波纹集S1u上的潜在兴趣偏好表示O1u:
通过使用O1u来替换候选推荐内容v 向量,可以有效地表示用户u 在二阶波纹集的潜在兴趣偏好。因此,重复上述迭代步骤,可获得更高阶数的偏好波纹集。用户u 的向量可以用来表示其在不同阶的波纹集上的兴趣偏好的累积值,以反映其偏好特征:
本算法主要通过对用户u 的历史交互记录vu 添加拉普拉斯噪声来实现隐私保护。本文考虑了用户历史交互记录对推荐结果的影响权重不同,将根据相关性概率pi 对历史交互记录vu 分配不同的隐私预算,因为这些相关性概率较高的历史交互记录对推荐内容的影响更大,因此根据相关性概率pi 来添加不同大小的噪声能有效地保证推荐结果的准确率不会因为加入的噪声而产生太大的变化。其中特征向量的全局敏感度△f 计算如下:
其中,va 和vb 分别为用户u 的历史交互记录vu 中两个不同的历史交互记录所表示的向量。
根据相关性概率pi,可以对推荐内容的向量表示v 分配不同大小的隐私预算,以保证推荐内容的准确性。对于具有较高的相关性概率的特征向量,给予更多的隐私预算,以求减少噪声的影响。因此,vu 中每个特征向量vi对应的隐私预算εi可计算如下:
4 实验分析
在实验数据方面,本实验使用了movielen这个电影推荐领域中最流行的数据集,从https://grouplens.org/datasets/movielens/1m/获取,movielen 数据集包含了6 036个用户以及他们对2 445部电影的评分数据。
实验参数方面,本文的知识图谱嵌入模型选取TransE,将数据集中评分低于4选取为负样本,评分高于4的选取为正样本。通过对模型的验证集的分析不断改善模型的性能,在其他参数不变的情况下,把嵌入维度d设置为16;考虑到用户偏好兴趣将随着传播逐渐减弱,波纹集的跳数Hop的次数设置为2,学习率l设置为0.02。将电影数据集细分为训练集、评估集和测试集,其中训练集、评估集与测试集的数据量之比为6∶2∶2,最终的测试结果将由10次实验的平均值来决定。
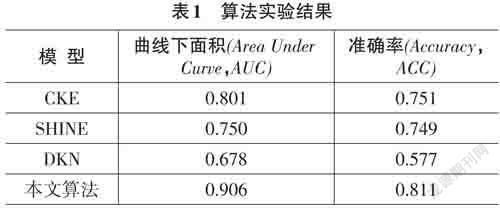
本实验使用准确率(Accuracy,ACC)和曲线下面积(Area Under Curve,AUC) 作為评价指标。ACC可以作为一个重要的参考指标来评估推荐的精确性,其值越大,说明推荐的有效性就越强。AUC是一种常用的分类器评估指标,可以帮助解决样本分布不均衡的问题。AUC越接近1,说明分类器的性能越优秀。
通过本次实验发现,改进后的算法在处理推荐问题时,其表现优于CKE、SHINE和DKN等传统模型,具有显著的提升。本文提出的算法ACC和AUC的性能都有显著改善,而且实验数据也有明显差异,详情可见表1。
5 结论
基于知识图谱推荐算法,本文提出了一种新的方法,将差分隐私技术应用于Ripplenet推荐模型,以有效降低用户隐私泄露的风险,实现更加安全、可靠的知识图谱推荐。经过多次实验,该算法不仅可以保护数据隐私,而且能够提供准确可靠的推荐结果。下一步的工作方向是进一步优化算法以争取兼顾推荐的准确度、算法的效率以及隐私的保护。
