
基于深度学习的液相流粒子图像测速估计
2023-05-04 13:30毕晓君何明洁于长东范毅伟
哈尔滨工程大学学报 2023年4期
毕晓君, 何明洁, 于长东, 范毅伟
(1.中央民族大学 信息与工程学院, 北京 100081; 2.哈尔滨工程大学 信息与通信工程学院, 黑龙江 哈尔滨 150001; 3.哈尔滨工程大学 船舶工程学院, 黑龙江 哈尔滨 150001)
粒子图像测速(particle image velocimetry,PIV)是一种非接触的、全局的、定量的流体可视化技术[1]。通过从连续粒子图像中获取流体的速度场信息,可以帮助研究者更深入地了解复杂流体的物理特性。从粒子图像中计算速度场的软件算法主要有互相关法[2]和变分光流法[3]2种。互相关法通过提取图像对应的2个查询窗口来执行互相关计算,搜索查询窗口的互相关最大值来确定位移。最具有代表性的一种互相关算法是多重网格迭代算法(window deformation iterative multi-grid,WIDIM)[4]。由于互相关算法计算的是窗口内的统计平均位移,仍无法实现稠密(像素级别)的速度场估计。另一常用方法是变分光流方法,其优点是易于嵌入先验物理知识和特定几何约束知识[5-6],但是光流法在进行变分优化的过程会花费大量时间和计算量,而且对噪声非常敏感。
此外,在实验流体力学中,发展两相流、多相流场景下的PIV算法已成为一个有前景的研究方向。例如,在船舶与海洋工程领域,研究物体入水的两相流PIV具有广泛的应用价值[7-8]。针对具有复杂边缘的物体入水两相流PIV图像,对液相区域的速度场计算具有很大的挑战性。研究者通常手动完成非计算区域的掩模工作,而后期仍通过互相关算法WIDIM计算速度场,但基于查询窗口准则的互相关法,在不同相位边缘位置很难获得准确的稠密速度场[9]。随着深度学习的发展和成熟,部分研究工作开始将深度学习技术用于单相流PIV估计问题的研究[10-13]。在计算机视觉领域,深度学习光流模型[14-15]在运动估计任务中取得了杰出的性能。受此启发,Cai等[12]提出改进的PIV-LiteFlowNet-en模型将其成功用于单相流PIV估计,该模型在速度场估计精度和计算效率上具有一定的优势。然而,目前的深度学习算法在单相流PIV速度场计算中取得了突破性的进展,但是并未在两相流PIV实验领域获得广泛应用。
本文提出一种同时用于单相流和物体入水两相流速度场估计的深度学习运动估计器。本文对先进的光流模型RAFT[16]进行改进,是对文献[17]的进一步扩展。去掉了模型的冗余部分,旨在不影响估计精度的同时,减少模型参数量。为了更好地训练和优化模型参数,制作了相应的单相流和物体入水两相流PIV数据集,并对训练后的模型进行多种测试和评估,结果表明提出的算法不仅能用于单相流速度场估计,也可用于物体入水的两相流PIV图像中的液相速度场计算。
1 光流神经网络及改进
1.1 光流网络RAFT
本文利用的网络基础架构是一种用于光流估计任务的卷积神经网络循环全对场变换(recurrent all-pairs field transforms,RAFT)的深度学习框架[16]。该网络结构如图1所示,主要由3部分组成。

图1 光流模型RAFT网络结构Fig.1 The optical flow model RAFT network structure
1)特征提取模块。
该模块利用卷积神经网络来提取图像的特征。特征编码器Feature encoder功能为提取输入第1帧、第2帧图像中的特征F1和F2,将输入图像映射为1/8分辨率的特征图。Feature encoder包含6个残差块,每经过2个残差块后特征图的分辨率变为原来一半,对应的特征通道数分别为64、128、192和256。同时存在的上下文编码器Context encoder与特征提取模块的结构基本类似,作用为提取第1帧图像的上下文信息特征。在光流估计任务中通常会存在遮挡和大位移等问题,Context encoder可以为下一阶段的特征信息融合提供更多有用的上下文信息。
2)相关计算层。
扭曲层[18](Warp)和代价体层[19](cost volume)是光流法在计算光流过程中非常重要和关键的部分。Warp层的作用是减少图像特征和的距离,从而解决大位移的光流估计问题。而Cost volume的作用是构建和已经扭曲的像素匹配损失,从而得到粗略的速度矢量估计。而RAFT在结构设计中不再使用Warp操作层,创新性的直接构建4D Cost volume代价体模块来进行全局的特征匹配搜索。该模块通过对所有向量进行对应内积来构建4D(W×H×W×H)的相关层。相关计算层由4层不同分辨率的相关金字塔结构构成{C1,C2,C3,C4},从而可以获得图像的全局和局部的特征信息。然后相关性查询操作L被用来在不同分辨率的相关层上进行查询,生成的特征图用于后面的迭代式光流计算。
3)更新迭代模块。
更新迭代模块利用卷积GRU循环网络迭代计算出光流。模块输入由4部分组成:Context编码器输出,Cost volume输出,上层隐藏状态信息以及上层迭代过程输出的光流。每次计算出相对于上次迭代过程输出的残差光流Δf,然后与上次迭代输出的光流进行相加用于目前的流估计:fk+1=Δf+fk。RAFT无论在训练还是测试的过程中,都可以选择更新迭代次数,直到估计出最合适的估计光流。
该模型的损失函数为L1范数:

(1)
式中:γ取值0.8;fgt表示真值场。
1.2 光流网络RAFT的改进
实际上,基于深度学习的光流估计和PIV估计任务存在一定的区别,其区别主要反映在应用场景和数据方面。光流估计任务所描述的通常是生活场景中具有稳定突出特征的刚性运动或准刚性运动。因此,光流数据集是一种复杂而具有挑战性的数据集,图像带有RGB彩色信息并含有丰富的特征信息。光流数据集中通常包括遮挡、真实光照、大位移等其他经典问题;另一方面,粒子图片通常是灰度图像,具有低分辨率、特征信息少的特点。具体的比较如图2所示。

图2 粒子图像和光流数据集图像Fig.2 Particle image and optical flow dataset image
经过以上分析,本文对RAFT进行如下改进:
1)RAFT特征提取部分的上下文编码器Context encoder可以捕获额外的上下文信息,这对于光流估计非常重要。然而, 由于灰度粒子图像的简单性,所以上下文网络提取的信息对PIV的估计几乎不起作用。因此,本文移除RAFT的Context encoder模块。同时,将第2帧图像的提取特征直接馈入到4D Cost volume和更新迭代模块。根据实验验证,移除Context encoder对PIV估计的准确性几乎没有影响,同时删除Context encoder也大大减少了参数量;
2)光流数据集的图像通常具有高分辨率的特点,相反,构建的PIV数据集中的粒子图像通常是具有较低分辨率(256×256像素)。因此,粒子图像经过特征编码器Feature encoder的8倍下采样后,特征信息太少,对后面的流推理阶段无法起到应有的作用。本文对特征编码器Feature encoder进行了改进,删除相应的2个残差模块,将其输出分辨率提高到原始图像的1/4。在提高分辨率和获得更多图像特征信息的同时,也进一步减少了模型的参数量。图3对比了改进前后特征编码器的结构,当输入粒子图像为256×256大小时,编码器最后的输出分辨率为64×64:

图3 改进前后的特征编码结构对比Fig.3 Comparison of feature encoder structure before and after improvement
g(Ii)=EF(Ii):R256×256×3→R64×64×256
(2)
式中EF(·)表示特征编码器函数。
改进的模型如图4所示,模型的输入既可以是只包含液相的单相流PIV图像对,也可以是对非计算区域掩膜后的两相流图像对,以重点对液相区域进行速度场估计。

图4 改进的RAFT网络结构Fig.4 Improved RAFT network structure diagram
2 粒子图像测速数据集生成
提出的流动估计深度学习模型采用监督学习策略,所以需要具有真实值的数据来训练和优化模型参数。按照实验流体力学的方法[11],首先生成粒子图像以及流动速度场,然后通过速度场对称地移动粒子的位置以获得粒子图像对。注意,本文在粒子图像中叠加了少量的高斯噪声以模拟真实的流动条件。将具有不同参数的粒子图像和流动速度场随机组合,即可以组成单相流PIV数据集。最后,本文生成的PIV数据集的数量和流场种类分布如表1所示,关于数据集的具体介绍可参考文献[17]。制作的PIV数据集合包括据集包括超过29 000项的粒子图像对及速度场真值,流场种类达13种。庞大的数据量和数据的多样性可以帮助更好的训练模型,增加模型的泛化能力。

表1 PIV数据集的描述Table 1 Description of the PIV dataset
此外,为充分模拟两相流物体入水的场景,本文制作了两相流PIV数据集。首先生成掩膜数据。使用Matlab软件中的 PIVLab 工具包[23], 对物体入水图像进行人工精确标定,对非计算区域进行掩膜处理,标定结果以二值化图片形式储存,非液相区域像素值为0, 含有粒子的液相区域像素值为1,从而获取物体入水的掩膜数据。本文研究的入水物体目标是楔形体,其手动掩膜具体标准可参考文献[24],经人工标定的部分结果示例如图5所示。
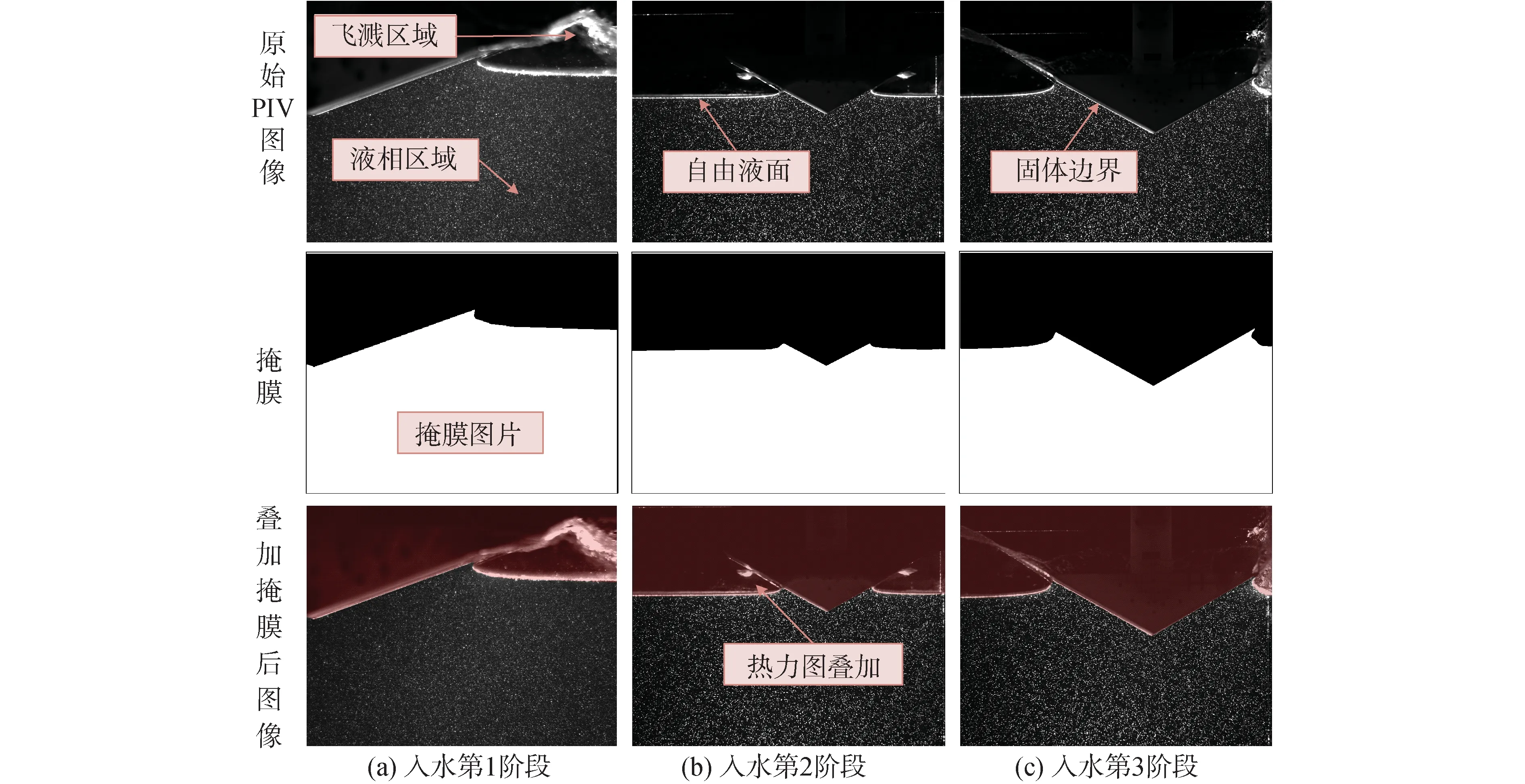
图5 人工标定的楔形体入水的两相流PIV图像示例Fig.5 Samples of manually calibrated two-phase flow PIV image of a wedge entering water
其次,将单相流数据集和生成的掩膜数据相乘。为了使模型更好的学习到两相流图像中物体的边缘特征,本文将掩膜数据和单相流的粒子图像对及真实速度场随机地相乘,从而获得两相流PIV数据集。掩膜相乘过程为:
I′(i,j)=I(i,j)⊗M(i,j)
(3)
V′(i,j)=V(i,j)⊗M(i,j)
(4)
式中:M(i,j)表示掩膜数据;⊗表示点乘操作;I(i,j)和V(i,j)表示原来的图像和真实速度场;I′(i,j)和V′(i,j)分别表示掩膜后的图像和速度场。通过在此数据集训练中,模型可以更好地学习两相流PIV图像的边缘特征信息,提高对此的泛化能力。部分数据集示例如图6所示。
3 粒子图像测速实验与结果分析
3.1 实验环境及训练
本次实验中采用的硬件环境配置为Intel(R) Core(TM) i7-9700K CPU@3.00 GHz,32 G内存,并采用RTX 1080Ti GPU进行运算加速,操作系统为64位Ubuntu 18.04采用基于Python的深度学习框架PyTorch来完成程序编程。
在训练过程中,首先将改进的RAFT在表1的单相流PIV数据集进行训练,使其具有估计多种典型速度场的能力,训练集和测试集按照9比1的比例进随机划分,在训练过程中,批尺寸大小为6,初始学习率设为λ=10-4,采用AdamW梯度优化器,其衰减权重为0.000 05。经过1.18×106迭代后,模型参数达到收敛;其次,将训练好的模型在本文构建的两相流PIV数据集上再进行训练微调,使得模型进一步有效学习图像中的相位边缘特征信息,最后训练而成的模型称为PIV-RAFT-2P。
3.2 评价标准与参考算法
当在具有真实值的数据集上评估时,评估粒子图像测速算法最 常 采 用 的 是 均 方 根 误 差(root mean square error,RMSE):
(5)

本文选择具有代表性的3种图像测速算法进行对比,一是基于相关分析法的窗口变形迭代网格方法[4](window deformation iterative multi-grid, WIDIM);多尺度金字塔的HS变分光流算法[3]。WIDIM算法的参数设置为三通道多重判读窗口(判读窗口大小分别为64、32、16)。HS变分光流法则采用3层金字塔迭代结构,光滑系数在实验中进行适当调整;3)深度学习基准PIV算法PIV-LiteFlowNet-en[12]。
3.3 单相流数据集评估
本文首先在单相流PIV数据集上对包含不同种类的流场的图像进行了测试。为了增加对比性,这里本文选择与WIDIM相关、HS光流法和PIV-LiteFlowNet-en进行了精度的比较,如表2所示。

表2 单相流PIV数据集测试误差Table 2 Single-phase flow PIV dataset test error
如表2所示,本文改进的光流神经网络PIV-RAFT-2P在不同种类的流场都取得了最高精度的计算结果。除了在复杂流场DNS-turbulence取得0.115的测试误差外,在其他流场上计算精度都提高了一个量级。尤其在一些简单的流场测试中,如Sink流场,更是取得了0.017的低误差结果。这证明了本文提出的方法具有很好的泛化能力和鲁棒性。接着通过不同方法计算的速度场来比较算法获取细节涡结构的能力。二维湍流流场DNS-turbulence的粒子图像是国际公认的 PIV 测试基准之一, 对其进行了测试和比较。
如图7所示,WIDIM和HS算法所计算的涡心位置不够连续,与真实值相差较多,而本文的模型所计算的速度场,基本与真实值一致,误差只有0.076。尤其是在小尺度涡结构的估计上(圈处),神经网络模型PIV-RAFT的优势更明显,这是由于该方法能够提供稠密速度场。
3.4 两相流PIV数据集评估
接着在两相流PIV数据集上对模型性能进行了评估。图8展示了不同算法在Back-step, DNS-turbulence和Cylinder流场的估计速度场。由于HS算法和PIV-LiteFlowNet-en在两相流PIV估计上表现较差,误将非计算区域当作可测区域,这里对其结果不进行展示。可以看到,本文方法的速度场计算结果与真实流场基本一致。在掩模区域与计算区域交界面位置处,可以对边界矢量进行有效估计。对于复杂流场DNS-turbulence,PIV-RAFT-2P可以获得更稠密的速度场(圈处)。这是因为相关法WIDIM是基于窗口查询的方式,获得的速度场是稀疏的形式,而本文的方法则可以获得更多的小尺度涡结构。
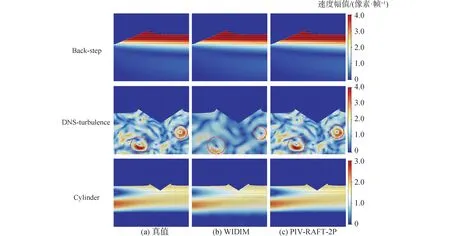
图8 不同方法在两相流图像估计的速度场Fig.8 The velocity field estimated by different methods in two-phase flow images
为了定量的分析和比较,本文对包含4种经典的流场的两相流测试集进行测试并对结果取平均。如表3所示,WIDIM计算的误差较大,而深度学习估计器PIV-RAFT-2P在不同流场上都取得了最低的误差,同时本文的方法可以获得像素级别的高分辨率速度场。

表3 两相流PIV图像测试RMSE结果Table 3 Test error of two-phase flow PIV images
3.5 真实图像测试
本文首先实际流场单相流图像进行测试,所选取的实际粒子图像对是涡流对[25]。该图像成像质量较高(粒子分布均匀、浓度合适、粒直径合适),是非常适合 PIV 分析的粒子图像,如图9、10所示。

图9 不同方法在涡流对图像估计的速度场Fig.9 Velocity fields estimated from laboratory PIV images

图10 不同方法在两相流图像估计的速度场Fig.10 The velocity field estimated by different methods in two-phase flow images
可以看到,由于受到噪声影响,HS光流法估计的速度场不够光滑,结果较差。而WIDIM算法因为其发展多年,取得比较好的估计效果,但是其因为计算得到低分辨率的速度场,难以获得涡心位置的细节流动。本文的方法也可以取得和WIDIM方法相一致的效果,获得了光滑的速度场和更多的细节信息,尤其在涡心位置和在下面的喷嘴位置也可以得到有效估计。
然后在PIV实验系统平台中拍摄获得实际的楔形不同时刻入水的粒子图像对(t=5 ms, 10 ms, 20 ms),对其进行测试。可以看到2种算法都能展现楔形体堆积区射流根部的高速射流现象,但是PIV-RAFT-2P在堆积区的计算的速度场分布更为平滑,而基于窗口查询方式计算的WIIDM算法因为获得的速度场是稀疏的,所以在边界位置的速度场呈现锯齿形状的分布。在楔形体入水不同时刻算法都展现出了相同的趋势。
3.6 计算效率评估
本文分别利用大小为256×256的PIV图像对不同算法进行了计算效率的评估。如表4所示,PIV-RAFT-2P在计算效率上占有很大的优势。在计算时间上,PIV-RAFT-2P远远超过了传统算法,快于PIV-LiteFlowNet-en。相比于WIDIM,本文的方法可以计算出更多的速度矢量个数。另外,与深度学习方法相比,本文的改进后的模型PIV-RAFT-2P参数量只有3.73 MB,仅为PIV-LiteFlowNet-en的59.8%。

表4 计算效率对比Table 4 Comparison of computational efficiency
4 结论
1)本文提出的改进的光流卷积神经网络PIV-RAFT-2P方法,可同时用于单相流和物体入水两相流的液相区域速度场估计。对光流模型RAFT的上下文编码器进行移以及将特征编码器部分的输出分辨率提高到原来的1/4以获取更高分辨率的粒子图像特征;相应的单相流PIV数据集和两相流PIV数据集用于训练和优化模型参数。
2)本文提出的模型可以同时用于单相流和物体入水两相流PIV估计并取得高精度的估计效果,表明模型具有较强的泛化能力。此外,模型还具有参数量少(3.73 MB)、计算速度快的轻量化优势。
深度学习光流模型在PIV估计任务中具有很大的潜力和优势。然而,本文两相流中的液相区域的提取是利用人工掩膜方式,比较耗时和消耗人力,本文将进一步深入研究,提出一种级联的深度学习框架自动进行非液相区域的掩膜及液相区域的速度场计算。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
中国体视学与图像分析(2021年3期)2021-11-24
电光与控制(2018年10期)2018-10-13
制造技术与机床(2017年10期)2017-11-28
科技资讯(2016年21期)2016-05-30
通信电源技术(2016年4期)2016-04-04
电测与仪表(2015年11期)2015-04-09
中国铁道科学(2014年6期)2014-06-21
电测与仪表(2014年11期)2014-04-04
河南科技(2014年24期)2014-02-27
