
多视角原型对比学习的小样本意图识别模型
2023-05-10 13:57张晓滨李玉茹
西安工程大学学报 2023年2期
张晓滨,李玉茹
(西安工程大学 计算机科学学院,陕西 西安 710048)
0 引 言
意图识别是面向任务对话的重要组成部分,旨在识别话语所代表的意图,进行自然语言理解,为后续的对话管理和自然语言生成做准备[1-3]。现有的意图识别模型大多需要大量标注数据进行训练,在仅有少量标注数据可用时意图识别的准确率将显著下降[4]。而在现实场景中,意图识别往往缺乏训练数据[5],因此人们开始关注FSID问题[6]。
元学习中的基于优化和基于度量的方法已经成功应用于自然语言处理领域[7],用以解决FSID等问题[8]。JIANG等提出了注意任务不可知元学习方法,在学习与任务无关的表征的同时调整注意力参数,以此来快速适应特定任务[9]。DENG等将任务不可知和特定于任务的特征学习分隔开,并利用元学习学习新任务的初始化参数,从而验证了任务间隐式共同语言特征的有效性[10]。但是与模型无关的元学习[11]等方法相比,基于度量学习的网络更容易优化和扩展,具有更简单的归纳偏差和更高的内存效率,因此更加适用于FSID问题。
SNELL等提出的原型网络属于经典的基于度量的学习方法,原型网络首先学习一个度量空间,然后通过计算实例与原型之间的距离进行分类[12]。DOPIERRE等在原型网络框架中引入无监督释义的一致性损失,并在多样化波束搜索生成中引入了约束条件,提高了网络的表征能力和多样性[13]。LI等提出了一种结合了大型预训练语言模型的表征能力和通过自监督增强原型网络的快速适应能力的半监督元学习方法解决FSID问题[14]。GENG等提出了动态记忆归纳网络,该模型利用动态路由更好地适应和泛化支持集,从而为小样本学习提供更大的灵活性[15]。
然而上述基于度量学习的网络在构建代表支持集的原型时完全不依赖查询实例,导致构建的原型在参与查询实例匹配时缺乏有效性,因此部分学者在小样本意图学习任务中侧重于研究支持实例和查询实例之间的匹配信息,构建更有效的原型。YE等提出了多级匹配聚合网络,该模型以交互方式对查询实例和支持集进行编码,最终通过对支持实例的表示进行聚合获得支持集的类别原型[16]。SUN等设计了一种基于特征级、词级和实例级多重交叉注意的层次注意原型网络,以此来增强模型的语义空间表达能力,学习更具代表性的原型[17]。但是上述方法在构建原型时并没有考虑各类别原型之间的语义约束,代表各支持集的类别原型之间没有明显的区分度,使得最终在进行FSID任务时意图识别的准确率会受到限制。
受近期对比学习在自然语言处理领域成功应用的启发[18-19],本文提出了一种基于MVPCL的FSID模型,旨在解决在FSID任务中基于度量学习的网络未考虑所构建的类别原型之间的语义约束问题。首先在语义匹配时结合查询实例和支持集的动态信息构建支持集的多个语义模块,随后以各模块为基础构建多视角原型,之后结合对比学习多维度的考虑类别原型之间的约束。通过多视角的对比学习来有效区分代表各支持集的类别原型,从而提高了模型为查询实例匹配相应类别原型的准确率。
1 MVPCL模型
1.1 理论基础
本文将训练中涉及的标签空间表示为Ys,新出现的仅有少量标记样本的标签空间表示为Ym,Ys∩Ym=∅,定义新出现仅有少量标签的数据集为Dm={(x1,y1),(x2,y2),…,(xm,ym)},其中(xm,ym)表示话语和其所代表的的意图标签,m表示新出现仅有少量标签数据的样本总数。

1.2 模型结构
基于MVPCL的FSID模型包括语义编码模块、基于MVPCL的聚合模块和类别匹配模块,其中基于MVPCL的聚合模块主要包含多视角原型的构建、对比学习和语义聚合3个部分。首先,语义编码模块通过BERT(bidirectional encoder representations from transformers)模型将支持实例和查询实例映射为语义丰富的特征向量,之后通过注意力机制捕获重要的语义信息作为下一模块的输入。其次,基于MVPCL的聚合模块会从多个视角构建动态的匹配信息,一方面用于构建多视角原型,之后结合对比学习对所构建的各类别原型进行约束;另一方面通过长短期记忆(long short-term memory,LSTM)网络聚合后用于类别原型的构建,从而进行查询实例的类别匹配。
1.2.1 语义编码
给定输入的实例为x=[x1,x2,…,xt],其中t代表该语句有t个单词,本文通过预训练的BERT将每个词映射到高维空间,之后为了更好捕捉双向的语义依赖信息,使用双向长短期记忆(bidirectional long short-term memory,Bi-LSTM)网络捕获句子中单词之间的上下文信息,并利用自注意力机制提取句子的重要语义成分,最后将注意力和所捕获的上下文信息相结合,得到最终的表示U。
(1)
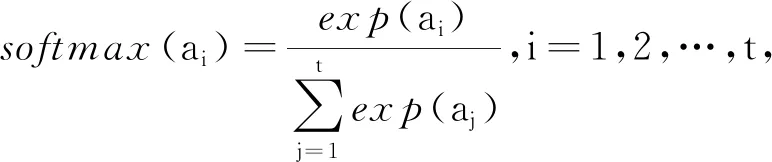
1.2.2 多视角原型
本文分别构建了头视角原型、最大池化原型、注意力原型、最大注意力原型,为后面的MVPCL做准备,下面将分别进行介绍。
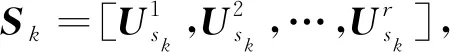

(2)
注意权重可表示为
(3)
式中:V2和W2是可训练的参数。
(4)

(5)
(6)
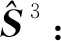
(7)

(8)
1.2.3 对比学习
在获得每个类别的多视角原型后,本文利用对比学习来进行约束性的训练,使得最终构建的用于类别匹配的原型不仅能够准确代表支持集的信息,也能够使各类别原型之间具有一定的区分度,并且由于是从多个视角进行对比学习,在进行原型约束时充分考虑了多个维度的信息,从而避免了对单一原型的过度依赖。
给定支持集S,S中含有N×K个文本实例,则对于头视角原型可以通过对比损失来优化最终原型的表示,对比损失可表示为
(9)

根据式(9),可以得到其他辅助原型下的对比损失Ls2、Ls3、Ls4。
1.2.4 语义聚合
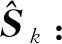
(10)
1.2.5 类别匹配
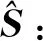
(11)
综上所述,MVPCL模型的总体结构如图1所示。

图1 MVPCL模型结构
2 实 验
2.1 数据集
本文在2个人机交互数据集SNIPS[20]和NLUE[21]上分别评估了所提出的模型在FSID任务和GFSID任务上的准确率。原始的SNIPS和NLUE数据集分别含有7个和64个类别意图。对于SNIPS,本文随机选取5个意图作为有足够训练数据的可见意图,剩下的2个意图作为新意图;对于NLUE,则随机选取16个意图作为新意图,剩下的48个意图类别作为有足够训练数据的可见意图。此外,本文将20%的可见意图和新意图混合在一起构建联合数据集,用于评估模型在GFSID任务上的效果。
2.2 实验设置
FSID模型通常采用特殊的情景训练[22]方法模拟每个类只有少量实例可用的情景学习知识,从而使得模型达到最佳的意图识别效果。模型的整个训练过程由多个情景构成,模型会在每一情景训练阶段从训练集随机抽取N个类别,每个类别中随机选取K个实例,将其定义为支持集。模型在支持集上进行训练时,会再次随机抽取M个实例,将其定义为查询集。模型在查询集上进行修正时,支持集和查询集共同构成了模型在训练期间执行的元任务。模型在测试的过程中依旧会划分支持集和查询集,因此FSID任务通常被定义为N-wayK-shot问题。
本文随机采样1 000个情景,采用Adam优化器训练模型。在SNIPS和NLUE数据集上,对K=1和K=5的情况进行了实验,其中SNIPS对应的N值为2,NLUE对应的N值为5,M值均为20。学习率为0.000 1,在语义部分提取的头部数量r为4。本文实验使用的操作系统为Ubuntu18.04,处理器为Intel Xeon Platinum 8255C CPU,主频为2.50 GHz,显卡为NVIDIA RTX3080。
2.3 实验结果与分析
为验证所提出模型的有效性,本文将所提出的模型与近年来用于解决FSID问题的模型进行比较。本文是采用度量学习的思想构建的MVPCL模型,因此首先选取了典型的基于度量学习的网络PN[12]和RN[23]进行对比。其中PN是通过比较查询实例和类别原型之间的欧几里得距离进行分类;RN则是采用可学习的非线性相似性度量方式实现小样本学习任务。其次,本文重点关注的是类别原型之间的语义约束问题,因此本文选取了典型的关注类别原型构建的网络HATT[24]、HAPN[17]和SMAN[25]。其中,HATT通过混合注意力的方式减轻噪声数据和稀疏特征对类别原型的干扰;HAPN通过多交叉注意机制突出支持实例的重要性,从而学习更具有甄别性的类别原型;SMAN则是通过多头注意力和动态的正则化约束提取有效的语义成分,使得所构建的类别原型更加具有代表性。
2.3.1 FSID任务中模型准确率对比
为验证本文模型在FSID任务中意图识别的效果,本文将所提出的MVPCL模型与基线模型的准确率进行了对比,实验结果如表1所示。
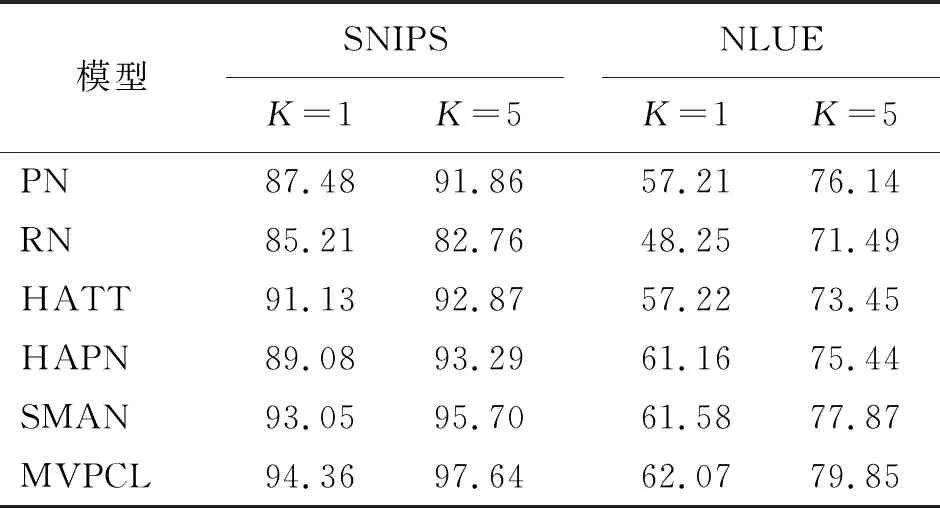
表1 FSID任务中MVPCL模型和基线模型准确率对比
从表1可以看出,在FSID任务中,本文所提出的MVPCL模型在SNIPS和NLUE数据集的准确率都优于基线模型。从SNIPS和NLUE数据集的整体观察可知,本文的MVPCL模型相较于PN和RN而言,准确率至少分别提高了3.71%和8.36%,这是因为PN和RN并未充分考虑查询实例对于支持集的影响。HATT和HAPN的意图识别准确率虽然都高于PN和RN。但是仍然低于本文所提出的MVPCL模型,至少分别相差了3.23%和0.91%。这主要是因为HATT和HAPN在编码支持集中的实例时考虑了不同查询实例对于支持集的影响,因此二者的实验结果整体而言要优于PN和RN。但是HATT和HAPN并没有以一种交互的形式具体表示查询实例,未充分发掘其中的信息,因此整体效果均低于MVPCL模型。此外,MVPCL模型相较于SMAN而言意图识别的准确率至少提高了0.49%,这主要是因为MVPCL模型充分考虑了各类别原型之间的约束,增加了类别原型之间的区分度,从而使得在进行类别匹配时不易将话语错误分类到相似意图。
2.3.2 GFSID任务中模型准确率对比
在CG-BERT[26]的GFSID任务中,将只有少数标记实例的新类合并到已有足够标记数据的类中,构成一个联合标签空间,旨在测试所构建的FSID模型能否准确对联合标签空间中的话语进行意图识别,这相比于FSID任务更加具有挑战性。因此本文也对比了所提出的MVPCL模型和基线模型在联合标签空间中的准确率,实验结果如表2所示。

表2 GFSID任务中MVPCL模型和基线模型准确率对比
从表2可以看出,在GFSID任务中本文所提出的MVPCL模型在SNIPS和NLUE数据集上的准确率均高于基线模型。对于SNIPS数据集而言,当K=1和K=5时,MVPCL模型与基线模型相比至少分别提高了0.41%和0.99%;对于NLUE数据集而言,当K=1和K=5时,MVPCL模型与基线模型相比至少分别提高了1.01%和0.39%。这主要是因为基线模型过于关注细粒度的词级语义信息,只有与支持集中某些词高度重叠的查询实例才能与所属类别进行匹配,忽略了粗粒度的语义表达。本文通过多视角的语义组件从全局的角度捕获粗粒度的信息,可以有效适应话语的多样化表达,有利于模型在联合标签中准确识别意图话语。
2.3.3K值对模型准确率的影响
为了探索在元任务中支持集所包含的每个类别的样本数K对于模型性能的影响,本文比较了K值为1、3、5、10、15情况下,本文所提出的MVPCL模型和基线模型在SNIPS数据集上准确率的变化情况,实验结果如图2所示。
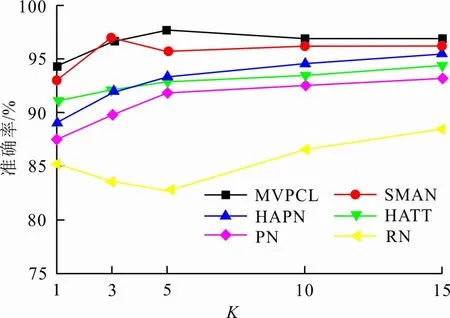
图2 K值对MVPCL模型和基线模型准确率的影响
从图2可以看出,随着K值的变化,本文所提出的MVPCL模型的意图识别准确率普遍高于基线模型,并且MVPCL模型在K值为5时意图识别的准确率达到了最高。这主要是因为支持集所包含的每个类别的样本是用于构建各类别原型,一些相似意图的样本会对类别原型的独立性产生干扰,而基线模型并没有考虑类别原型之间关系,MVPCL模型在对比学习的作用下使得不同类别原型在嵌入空间中的距离增大,因此整体效果优于基线模型。
3 结 语
现有的用于解决FSID问题的基于度量学习的网络过分关注支持集的语义表示,从而忽略了所构建的各类别原型之间的语义约束。本文通过构建多视角原型并且与对比学习相结合,有效地解决了上述问题。在FSID任务中的实验结果表明,本文方法对各原型进行了有效约束,提高了模型的意图分类准确率,此外,在GFSID任务中的实验结果表明,本文方法在构建各类别原型时充分考虑了多维度的粗粒度语义,有利于模型在联合空间中准确识别话语意图。
猜你喜欢
法律方法(2022年2期)2022-10-20
福建基础教育研究(2022年4期)2022-05-16
法律方法(2021年3期)2021-03-16
小资CHIC!ELEGANCE(2021年45期)2021-01-11
英美文学研究论丛(2018年2期)2018-08-27
剑南文学(2016年14期)2016-08-22
人间(2015年20期)2016-01-04
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
延河(下半月)(2014年3期)2014-02-28
