
基于异构信息网络与TF-IDF的核心药物发现算法
2023-05-14 08:06梁尘逸姚远哲
计算机时代 2023年5期
关键词:聚类
梁尘逸 姚远哲


摘 要: 提出一种基于异构信息网络和TF-IDF的核心药物发现算法。其核心思想是建立包含症状、方剂等多种类型对象的异构信息网络,并使用PathSim算法得到方剂之间的相似度来完成方剂聚类。以此为基础使用综合了剂量因素与TD-IDF算法原理的药物重要性系数计算方法完成核心药物发现。本文从《伤寒论》的方剂中划分出9个主要聚类并给出了各个聚类上重要性排名前5的药物,该算法可以考虑到多方面的信息,合理地挖掘出核心药物。
关键词: 异构信息网络; PathSim; TF-IDF; 聚类; 核心药物
中图分类号:TP311.5 文献标识码:A 文章编号:1006-8228(2023)05-31-05
Core drug discovery algorithm based on heterogeneous information network and TF-IDF
Liang Chenyi, Yao Yuanzhe
(School of Information and Software Engineering,University of Electronic Science and Technology of China, Chengdu, Sichuan 610054, China)
Abstract: In this paper, a core drug discovery algorithm based on heterogeneous information network and TF-IDF is proposed. The core idea is to set up heterogeneous information network including symptoms, prescriptions and other types of objects, and use PathSim algorithm to get the similarity between prescriptions to complete the clustering of prescriptions. Based on this, the core drug discovery is completed by using a drug importance coefficient calculation method that integrates the dose factor and the principle of TD-IDF algorithm. Nine main clusters are divided from the prescriptions of "Treatise on Febrile Diseases" and the top five drugs in each cluster are given. The algorithm can take into account many kinds of information to mine the core drugs reasonably.
Key words: heterogeneous information network; PathSim; TF-IDF; clustering; core drugs
0 引言
中醫是一个巨大的知识宝库,目前中医领域的数据挖掘研究受到了许多学者的关注,但受制于中医学本身的复杂性以及技术的局限性,不少研究都是基于简单的统计分析,例如频数统计,对药物使用频率、药物味数等指标进行统计分析[1,2],能在一定程度上发掘出数据中的规律,也有一些研究者将关联度分析[3]和复杂网络的方法引入到中医数据挖掘中,能够挖掘出一些更深层的信息。
核心药物发现是中医数据挖掘领域一项非常有价值的工作,如果能有效地挖掘出不同类别方剂中的核心药物,则能为开发新方剂提供参考,同时能帮助新手医生快速掌握方剂精髓。目前大量关于核心药物发现的研究都是针对治疗某一种疾病的方剂,在此基础上进行频数统计与关联度分析[4,5],这种方法不适用于有大量不同类型方剂混杂的数据集。还有一些学者基于复杂网络及社区检测算法来进行核心药物发现工作[6]。
本文结合异构信息网络与TF-IDF算法,提出一种有效的核心药物发现算法,首先构建一个包含了症状、方剂等不同类型对象的异构信息网络,利用PathSim算法全面衡量方剂之间的相似度,并以此为基础进行聚类,然后利用综合了剂量因素与TF-IDF算法原理的药物重要性系数来评估各个方剂聚类中所包含药物的重要性,得出每个聚类中的核心药物。
1 数据预处理
本文所使用的原始方剂数据来自《伤寒论》,采用正则表达式对方剂的主治症状、药物名称与剂量等进行拆分,设置判断条件筛选拆分不合格的数据并进行手动修正。
拆分完成后还需对症状和药物进行标准化工作,例如:头痛与头疼表达的意思相同;黄耆与黄芪实则为同一种药物。本文采用手动搜索替换加人工检查的方式对数据进行标准化。并且为方剂集中包含的药物匹配了对应的药物功能信息,这些信息主要来源于《中药大辞典》和《中华本草》。
对于方剂中药物的剂量单位,重量单位统一换算为“两”;体积单位统一换算为“斗”,其余单位如“枚”等则不变。由于本文算法需要使用药物剂量信息,因此忽略半夏散(汤)、十枣汤、牡蛎泽泻散、烧裈散这几个不含剂量信息的方剂,使用剩下的109条方剂数据作为实验数据。
2 相关技术与算法设计
整个算法的主要流程如图1所示。
2.1 异构信息网络与PathSim相似度
目前在方剂相似度计算上使用最多的是Jaccard相似度[7],其计算公式如式⑴,其中X与Y分别表示待对比的两个方剂所包含的药物组成的集合,这种方法能从药物组成这一个维度较好地衡量两个方剂之间的相似度。
[s_Jaccard(X,Y)=|XY||XY|] ⑴
该算法只考虑了方剂的药物组成,而现实中一些方剂的药物组成可能完全一样,例如桂枝汤与桂枝加桂汤,二者都是由桂枝、芍药、甘草、大枣、生姜5种药物组成,只是药物剂量不同,但主治的病症并不一样,而在Jaccard相似度下,二者的相似度就是1,这显然不合理。
本文使用PathSim算法来计算方剂之间的相似度,该算法是一种基于异构信息网络的相似度计算方法[8],原本用于以文献为核心的文献信息网络挖掘中。通过分析网络中的多种类型对象以及不同类型对象间的多种边,可准确地区分信息网络中的不同语意,挖掘出更加具有意义的知识。
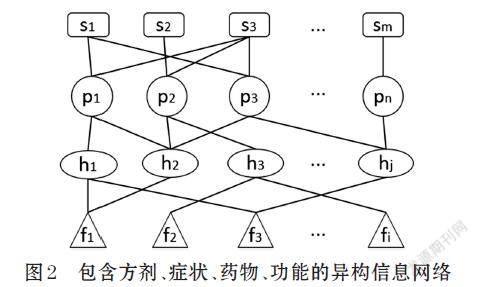
本文建立一个包含4种对象和3种边的异构信息网络,如图2所示。其中S表示症状,P表示方剂,H表示药物,F表示功能;3种边均为无向边且权重值为1,P-S边表示方剂P可治疗症状S,P-H边表示方剂P包含药物H,H-F边表示药物H拥有功能F。
通过选择不同的元路径可以包含不同的相似度信息,例如本文中的元路径P-H-P代表两个方剂使用了相同的药物;P-H-F-H-P代表两个方剂使用的药物拥有相同的功能。指定元路径下方剂之间的相似度计算方法如式⑵,其中Ml为指定的对称元路径l下方剂之间的路径数量矩阵。
[s_PathSiml(px,py)=2Ml(x,y)Mlx,x+Ml(y,y)] ⑵
M可以通过相邻对象之间的路径数量矩阵相乘得到,以元路径P-H-P为例,MP-H-P=MP-HMH-P,其中MP-H表示从P到H的路径数量矩阵。网络中的边均为无向边,则MH-P=MP-HT,MP-H-P=MP-HMP-HT,其余元路径对应的路径数量矩阵同理可得。对不同的元路径赋予不同的权重值w,可实现多重元路径的组合,r条元路径组合得到的相似度计算方法如公式⑶所示。
[s_PathSim(px,py)=l=1rwls_PathSiml(px,py)] ⑶
2.2 谱聚类
得到方剂之间的相似度矩阵后需以此为基础进行聚类。目前聚类最常用的算法是经典的k-means算法,用于方剂聚类时一般通过一些量化方法将方剂用向量表示,然后运行算法[9]。然而k-means算法的步骤中有一步是计算聚类中心,直接给出方剂的相似度矩阵并不能计算聚类中心,因此无法直接使用k-means算法进行聚类。
本文采用谱聚类[10]的方法来完成聚类步骤,这是一种基于图论的聚类方法,该算法的核心思想是:将带权无向图划分为两个或两个以上的最优子图,使子图内部尽量相似,而子图间尽量距离较远,从而完成聚类。谱聚类的一般流程如下。
⑴ 根据输入的相似矩阵生成方式构建样本的相似矩阵S。
⑵ 根据相似矩阵S构建邻接矩阵W,构建度矩阵D。
⑶ 计算出拉普拉斯矩阵L。
⑷ 构建标准化后的拉普拉斯矩阵D-1/2 L D-1/2。
⑸ 计算D-1/2 L D -1/2 最小的k1个特征值所各自对应的特征向量v。
⑹ 将各自对应的特征向量v组成的矩阵按行标准化,最终组成n×k1维的特征矩阵V。
⑺ 将V中的每一行作为一个k1维的样本,共n个样本,用输入的聚类方法进行聚类,聚类维数为k2。
⑻ 得到簇划分C(c1,c2,…,ck2)。
本文不采用谱聚类中常用的方法来生成相似矩阵,而是直接采用PathSim算法得出的相似度矩阵作为S,由于PathSim算法满足自身最大化性质,即每个对象跟自己的相似度最大,为1,因此,S的主对角线元素全为1,则邻接矩阵W=S-I,I为单位矩阵。
2.3 综合了剂量因素与TF-IDF算法原理的药物重要性系数
TF-IDF算法原本用以评估一字词对于文件集中某一份文件的重要程度,已有研究者尝试将其用于核心药物的发现[11]。参考其原理,则药物j在方剂聚类k中的重要性系数采用公式⑷来计算,其中|p_set|表示整个方剂库大小;|{n:hj∈pn}|表示包含药物j的方剂数量;|{n:hj∈pn,pn∈cluster(k)}|表示聚类k中包含药物j的方剂数量,可以发现该值变大时也会导致|{n:hj∈pn}|增大从而降低log函数的值,但只要该值不过大,则不会逆转药物j在方剂聚类k中的出现次数优势。
[TF_IDFjk=logp_set{n:hj∈pn}×{n:hj∈pn,pn∈clusterk}] ⑷
相比直接利用药物出现频率来发掘核心药物[12],该算法综合考虑了药物在指定类中的出现次数与在整个方剂库中的出现次数,能有效降低在所有类型方剂中都频繁出现的“百搭”药物的影响。但不同于文件中的字词,方剂中的药物每一次出现都伴随着不同的剂量,只考虑药物的出现次数不够全面,本文采用以下步骤来引入剂量因素:
⑴ 将每种药物各自使用最多的单位作为其指定剂量单位,采用其余单位的剂量数据则忽略,以保证同种药物使用同种剂量单位。
⑵ 分别计算每种药物在各方剂聚类中的代表剂量,药物j在方剂聚類k中的代表剂量D_REPjk=median(D(hj,p1),…,D(hj,pn)),p1,…,pn∈cluster(k),D(hj,pn)表示药物j在方剂n中的剂量,为0则不计。通过取中位数来减少特殊剂量的影响。
⑶ 将D_REPjk值标准化,药物j在方剂聚类k中的标准化代表剂量D_STDjk用公式⑸计算,其中D_REP_MAXj为药物j在各方剂聚类中代表剂量的最大值。使得不同药物间的剂量有可比性。
[D_STDjk=D_REPjkD_REP_MAXj] ⑸
综合考虑药物的剂量与TF-IDF算法原理,则完整的药物重要性系数IMPjk计算方法如公式⑹所示。
[IMPjk=TF_IDFjk×[logD_STDjk+1+1]] ⑹
当药物j在方剂聚类k中使用次数与剂量水平都较高且在其余类中使用次数与剂量水平都较低时,IMPjk值增大,说明药物j在方剂聚类k中重要性较高。
3 实验设置与结果讨论
3.1 方剂相似度计算
基于2.1节中构建的异构信息网络,本文选取5条元路径来运行PathSim算法,每条元路径的相似度信息及权重分配如表1所示。
计算得到方剂之间的相似度矩阵,能从多个维度综合衡量方剂之间的相似度,例如桂枝汤与桂枝加桂汤,在使用Jaccard相似度的情况下相似度为1,而本文得出的二者相似度为0.65,更加合理。
3.2 方剂聚类
进行聚类需要决定聚类数K,在此参考清代徐大椿所著《伤寒论类方》,其将《伤寒论》中方剂分为了11个主类以及22个杂方,可知聚类数K大约为30左右,经过调试,确定聚类数K为26时聚类结果最合理。
值得注意的是,不同于其他领域数据,方剂之间大多都具有一定相似性而没有明显的边界,一些方剂归于多个类别都是合理的,并没有一个绝对正确的结果,通过聚类算法得出的结果很难与《伤寒论类方》或其他著作基于作者主观看法得出的结论高度一致,只能通过对比在一定程度上说明聚类结果的合理性。
忽略只包含1个或2个方剂的聚类团,仅关注较大且能在《伤寒论类方》中找到相似类的主要聚类团,则聚类情况如表2所示。
由此可以看出,本文得出的聚类结果是有效的,能够从方剂集中较为合理地划分出9个主要聚类团,9个类各自的大小如图3所示。
3.3 药物重要性系数计算
基于完整的聚类结果使用公式6计算各个方剂聚类中药物的重要性系数,并将结果与仅计算TF_IDFjk以及使用频数统计的情况进行对比,依然只关注主要的9个聚类,则核心药物的挖掘情况如表3所示。
相比频数统计,其余两种方法都去除了一些高频药物,尤其是甘草,现实中甘草在各种方剂里使用非常频繁,常起“调和诸药”的作用,多数时候并非核心药物,引入TF-IDF算法的思想后,能有效排除其影响。
完整算法与仅计算TF_IDFjk的情况整体区别不大,部分药物的排名有调整,这与实际情况相符,因为TF_IDFjk已能较好评估药物的重要性,其给出的核心药物理应在剂量上也占有优势,而完整算法能进一步改善其结果,例如将聚类8即桂枝汤类中的桂枝重要性提高。
需要指出的是,由于《伤寒论》方剂数量少且聚类数量多,使得部分聚类太小,其中各种药物出现的次数都极低,这导致独有药物凭借剂量优势排名较高,例如聚类7中的栝楼根,其实只在柴胡桂枝干姜汤中出现了一次。数据集大一些时,此问题便不会产生。
3.4 实验结论
经过《伤寒论》的数据验证,说明了构建异构信息网络并使用PathSim算法对方剂进行相似度计算是可行的,且相较于使用传统的Jaccard相似度,能从多个维度更加全面地评估方剂相似度,在此基础进行方剂聚类,得到的结果也是合理的,而综合了剂量因素与TF-IDF算法原理的药物重要性系数能有效降低通用药物的重要性,还能体现出药物在剂量上的优势,更加全面地评估药物是否为核心药物。
4 结束语
本文提出的基于异构信息网络与TF-IDF的核心药物发现算法能够有效地对方剂数据进行相似度计算与聚类,并以此为基础挖掘出各个方剂聚类中的核心药物。目前中医学领域内还有大量未被仔细研究的方剂数据,本文的方法为挖掘其中的知识提供了一种新的工具。
不过需要承认的是,本文虽然对方剂的主治症状手动做了一些标准化的工作并对药物的剂量进行了换算,但由于现实中症状表述复杂且药物剂量情况多样,导致使用这些信息时很难考虑得非常全面,中医数据挖掘的研究还需做得更细致才能取得更好的效果。
参考文献(References):
[1] 武文星,郭盛,尚尔鑫,等.基于数据挖掘的补骨脂药用源流及其配伍用药特点分析[J/OL].世界中医药:1-23[2021-12-16].http://kns.cnki.net/kcms/detail/11.5529.R.20211118.2226.025.html
[2] 胡慧明,翁家俊,朱彦陈,等.基于数据挖掘的《中医方剂大辞典》含山楂组方用药规律研究[J].中国现代应用药学,2021,38(21):2713-2720
[3] 方永光,陈楠楠,李岩.基于数据挖掘分析黄世林教授治疗重症系统性红斑狼疮的用藥规律[J].中国中医急症,2017,26(6):947-951,962
[4] 刘根,贺文彬,赵子强,等.基于中医传承辅助平台对老年性痴呆防治方剂核心药物组合的筛选研究[J].中国实验方剂学杂志,2016,22(7):223-228
[5] 潘文.基于数据挖掘的治疗原发性痛经方证与核心药物配伍规律分析[J].西部中医药,2015,28(12):75-77
[6] 张云.基于知识发现的中药方剂核心药物识别研究[D].博士,电子科技大学,2021
[7] 李新龙,刘岩,周莉,等.基于方剂相似度的核心方药及其适应症挖掘方法研究——以失眠症为例[J].中医杂志,2021,62(2):118-124
[8] Sun Y,Han J, Yan X, et al. PathSim: Meta Path-BasedTop-K Similarity Search in Heterogeneous Information Networks[J]. Proceedings of the Vldb Endowment,2011,4(11):992-1003
[9] 刘广,孙艳秋.基于K-Means聚类算法的消渴方剂研究[J].中华中医药学刊,2017,35(1):173-178
[10] Luxburg U V . A Tutorial on Spectral Clustering[J].Statistics and Computing,2004,17(4):395-416
[11] 周伟.中药方剂核心药物及其配伍规律挖掘[D].硕士,南京大学,2013
[12] 娄方璐,刁庆春,刘毅,等.湿疹中医外治处方用药规律分析[J].陕西中医,2012,33(1):97-100
猜你喜欢
铁道通信信号(2019年6期)2019-10-08
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
光学精密工程(2016年5期)2016-11-07
互联网天地(2016年1期)2016-05-04
自动化学报(2016年8期)2016-04-16
管理现代化(2016年3期)2016-02-06
智能系统学报(2015年4期)2015-12-27
电子设计工程(2015年6期)2015-02-27
河南科技(2014年23期)2014-02-27
