
使用Ray的知识图谱分布式模型研究
2023-05-15 07:27方志聪李廷元
现代计算机 2023年5期
方志聪,李廷元
(中国民用航空飞行学院计算机学院,德阳 618300)
0 引言
知识图谱(knowledge graphs,KG)已成为当前的一个颠覆性的数据处理方式,提供统一和语义丰富的、庞大和多元化的数据源访问。大型图谱的“理解”能力至关重要,在数据集成、实体解析、搜索、数据提取、数据交换等方面中可以体现,表示学习(RL)/KG 已经成为一个关键性促进因素。
强化学习[1]的目标是将一个高维但非常稀疏的KG 嵌入到低维空间中,同时保留原始图的特征。KG 嵌入模型,如TransE[2]、DistMult[3]和ComplEx[4]处理三元组。三元组(s,o,r)代表一个事实,其中s是主语,o是宾语,r是它们之间的关系。这些方法独立处理知识图中的每个三元组,它们学习各种结构关系模式,例如实体之间的对称关系。知识图表示学习[5]的最新进展表明,基于图神经网络的知识图嵌入方法表现出优于传统嵌入方法的性能[6]。用于链路预测的最先进的KG 嵌入方法[7-8]通常遵循编码器-解码器架构,其中编码器聚合多处上下文以生成节点嵌入,而解码器学习节点之间的关系。
1 分布式知识图谱
由于KG 的规模和计算复杂性不断增长,分布式KG 嵌入训练最近在研究界引起了相当大的关注。现有框架[9-11]采用分布式、数据并行架构来应对高计算量和大内存需求。在这些架构中,首先对KG 进行分区,然后将分区分布在计算节点上进行训练。这些框架采用不同的方法进行训练,例如使用环AllReduce 通信架构进行梯度交换[10]。PBG[9]和DGL-KE[11]是以传统的KG嵌入模型设计的,例如TransE 和DistMult,它们独立处理三元组。这些模型不能用于需要k-hop邻域信息的基于图神经网络的KG 嵌入模型的分布式训练。图神经网络架构分布式训练的技术挑战之一是有效地将图划分为足够多的分区,以使每个计算节点都有相对少量的、自给自足的数据可供使用,并且工作负载在所有计算节点之间保持平衡,以避免SSGD期间的空闲时间。
Sheikh 等[10]提出了一种基于图神经网络的KG 嵌入模型的分布式训练模型,使用邻域展开方法使分区自给自足。首先使用边缘划分方法对KG 进行分区,然后使用邻域展开过程对分区进行扩展。邻域扩展过程包括了一个分区中所有节点的所有k-hop 邻居,以避免训练过程中的交叉分区通信开销,以节点和边缘复制为代价。本文还引入了基于约束的负抽样方法进行训练。实验表明,从分区内抽取负样本是有效的,避免了分区中的负样本,进一步减少了交叉分区的传输。
文献[12]中的分布式训练方法基于PyTorch分布式API。使用PyTorch 等底层框架的核心级API,对扩展和部署具有挑战性。最近的分布式框架,如Ray[13]简化了扩展和部署的底层细节。Ray是一个通用集群计算框架,提供通用、简单的API,使开发人员能够使用现有的库和系统进行分布式计算。丰富的Ray框架提供了用于训练(Ray Train)、调优(Ray Tune)、在线服务(Ray Serve)和分布式数据管理(Modin)[14]的API。Ray Train 提供了一个简单易用的API,用于使用深度学习框架(如PyTorch)对神经网络模型进行分布式训练。此外,它提供了可组合性,允许Ray Train与Ray Tune 互操作以进行超参数学习。本文的贡献总结如下:
(1)介绍了一个使用Ray 的分布式KG 嵌入训练框架,并在KG上展示了性能结果。
(2)使用Ray提供和评估分布式属性预处理。
(3)使用RayTrain API 对KG 嵌入模型进行分布式训练,并在执行复杂任务时展示API 的简单性。
2 模型概览
使用Ray 对KG 嵌入模型进行分布式训练的模型架构如图1所示。模型的输入是原始图、节点属性和关系以及图的分区。该模型由两个主要组件组成:分布式数据预处理和分布式训练组件。分布式数据预处理组件接收节点的原始属性,并使用Ray 在分布式设置中处理它们以生成特征向量。分布式训练组件的目标是学习KG嵌入模型。分布式设置的组件如下所述。
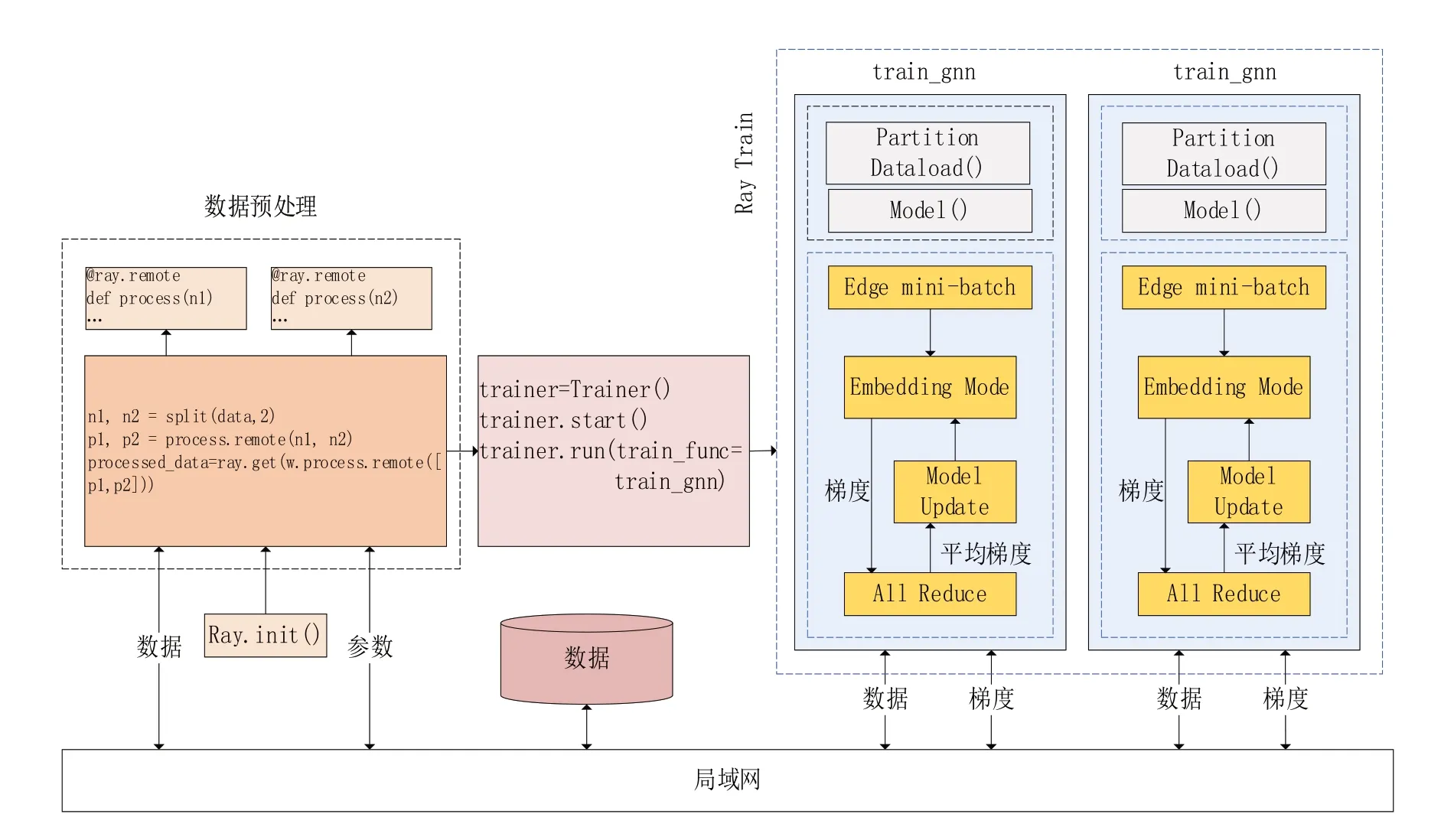
图1 使用Ray训练知识图谱架构
2.1 分布式数据预处理
本文的输入数据由编码为特征向量的节点属性组成,以便训练图神经网络。 这些节点属性可以是不同的格式,例如文本、数字、日期和分类类型。具体来说,将日期转换为数值,本文使用scikit-learn KBinsDiscretizer 和One-HotEncoder(或MultiLabelBinarizer)对数值和分类值进行编码,并使用预训练的BERT 语言模型对文本属性进行编码。
对节点属性进行编码的过程分为两个阶段:在第一阶段,本文加载了一个预训练的BERT模型并将KBinsDiscretizer、OneHotEncoder 和MultiLabelBinarizer 模型拟合到输入数据中的所有节点。学习模型的过程不是以分布式方式执行的。 在第二阶段,本文将学习到的模型应用于节点属性,将它们转换为特征向量。这个转换步骤是使用Ray以分布式方式执行的。
本文使用@ray.remote 实现了一个Ray 远程工作,它接收作为输入的节点子集及其属性和对预训练模型的引用。通过拆分节点数据并将数据分布在多个Ray 通道之间,可以并行化属性转换。由于所有Ray 通道使用相同的预训练scikit-learn 和BERT 模型,因此使用ray.pu(t)将模型放置在分布式对象存储中,并将返回的对象ID传递给通道。
转换结果是使用ray.get()从Ray 通道收集的,并连接到一个数组中,其中包含所有数据的转换节点属性。
应对实体属性的异质性,本文将属性建模为实体的直接邻居,并使用类似没有自环的1-hop GCN[15]网络来获得实体属性嵌入。也就是说,本文使用一个虚拟节点来表示一个实体,其属性嵌入是其属性邻居嵌入聚合的结果。与GCN不同,每个属性类型都有一个专用的嵌入矩阵用于转换,创建的实体属性图仅用于属性嵌入,在知识嵌入模型训练期间,实体嵌入用作初始节点特征。
2.2 分布式训练
本文使用Ray 训练API,对本文的图神经网络模型进行分布式训练。该API 支持Torch、Tensorflow 和Horovod 库,使用文献[12]中描述的训练架构,并将其封装在Ray Train中进行分布式训练,如图1所示。当Ray通道运行trainier.run(),每个通道加载其图形分区并初始化模型以进行培训。通道的数量是由图分区的数量决定的。使用文献[12]跟踪训练函数逻辑,在每个epoch之后,Ray训练允许从分布式通道内收集中间结果。本文使用PyTorch 作为后端。因此,Hence,Ray分布式会将梯度共享和更新。
3 实验环境
本文使用Ray 1.8.0[8]作为分布式训练框架,PyTorch Geometric 1.7.2[15]作为图嵌入框架,Py-Torch 1.9.0[12]作为深度学习后端。本文在一个由2台机器组成的集群上进行了实验。集群安装并运行的是CentOS Linux 7.9,并且每台机器上有一条16 GB RAM 的内存条和一块RTX1080 GPU图形处理器。
4 实验和评估
本文针对链路预测任务的非分布式训练评估了使用Ray 的分布式训练的准确性和可扩展性性能,在两种设置中使用了相同的超参数。RelGNN 将链接预测视为二元分类任务,即预测给定的三元组是否有效。
在本节中,本文使用第2节中描述的数据描述KG 嵌入模型训练的评估设置。数据由2.8 KB节点、24 KB 边和5 种关系类型组成。通过处理节点属性获得的每个节点的特征向量的维度为32。为了训练KG 嵌入模型,本文将数据分为训练集、测试集和验证集。本文随机选择80%的数据作为训练集,测试集和验证集各使用10%的数据。
本文的输入数据包含1万多个节点,这些节点均匀分布在Ray 通道之间进行预处理,其中每个通道根据任务分配到一个GPU 或CPU。由于scikit-learn 不支持GPU 计算,因此属性转换是在CPU 上计算的,而BERT 转换是在GPU 上计算的。本文测量了1、2 通道的属性处理时间。如图2、图3 所示,使用1 个通道处理所有节点属性的进程处理时间和一个epoch 时间分别为104秒和15秒,使用2个通道进程处理时间和一个epoch时间分别减少到35秒和5秒。通道从1增加到2时,处理时间缩短为原来的1/3。

图2 Ray分布式节点属性处理时间
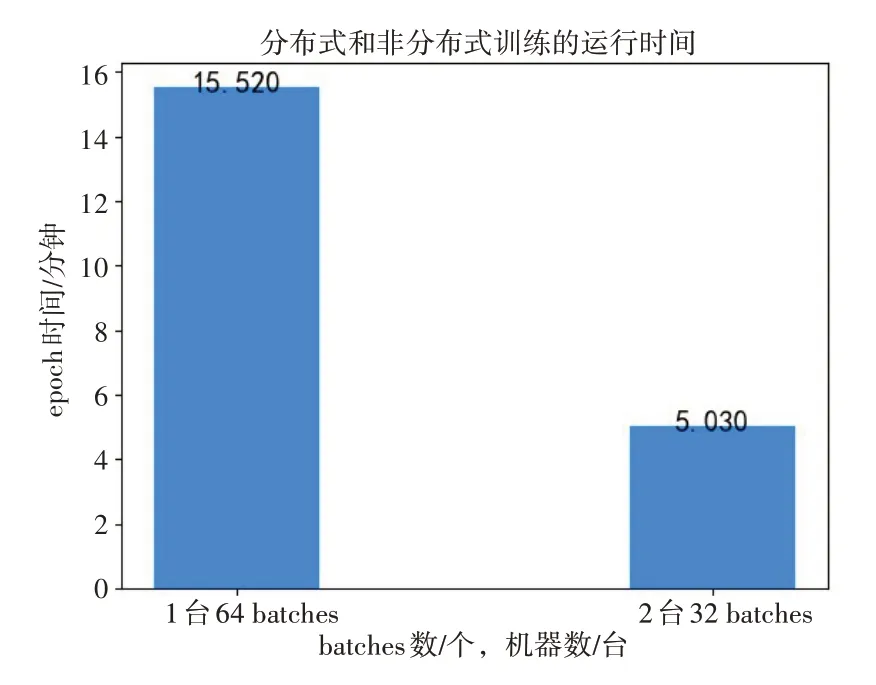
图3 Ray中RelGNN训练的epoch
使用Ray Trainer API 引入的开销可以忽略不计,大约在开始训练的部分时间会有差异。我们还使用pytorch.distributed API 进行了评估,发现这两种方法的运行时间没有显着差异。因此,使用Ray API 开发应用程序可以简化分布式训练过程,而无需或可忽略额外的时间成本。
本文评估的训练精度测试集使用曲线下的面积(AUC)。由于模型和输入数据都很大,GPU内存有限,所以不能利用GPU 加速。因此,在小区采样CPU 上执行训练和使用。如图4 所示,与非分布式训练相比,分布式训练精度几乎没有下降。

图4 Ray中RelGNN训练的AUC分数
5 结语
本文实现了一个分布式模型,使用Ray API对知识嵌入模型进行分布式训练。 Ray 提供了易于使用、功能强大且灵活的API,它们隐藏了用于扩展和部署的底层细节。本文有效地使用这些API 进行分布式数据预处理和训练。对Ray集群的实验评估表明,本文能够在数据预处理任务上实现1 倍的加速。在分布式训练任务上,本文在Rel 图神经网络上实现3 倍的加速,并获得了与非分布式训练设置相同的分数。Ray API引入的开销可以忽略不计。在接下来的工作中,计划利用Ray 支持对输入知识图谱的可扩展模型推理,进一步对知识图谱分布式训练进行加速。
猜你喜欢
环球时报(2022-03-29)2022-03-29
知识经济·中国直销(2018年7期)2018-07-27
能源(2017年10期)2017-12-20
制导与引信(2017年3期)2017-11-02
能源(2017年5期)2017-07-06
工业设计(2016年11期)2016-04-16
雷达与对抗(2015年3期)2015-12-09
环境科技(2015年6期)2015-11-08
电测与仪表(2015年8期)2015-04-09
电测与仪表(2015年7期)2015-04-09
