
基于深度学习的端到端人岗匹配模型
2023-05-18 08:14魏嘉银卢友军
智能计算机与应用 2023年4期
朱 瑜, 魏嘉银, 卢友军, 王 琳, 江 漫
(贵州民族大学 数据科学与信息工程学院, 贵阳 550025)
0 引言
为了找到满足岗位需求的人才,传统方法是由招聘人员手动审查求职者的简历,以决定是否提供面试机会。 然而,面对海量的简历,招聘人员不得不花费大量的时间和精力筛选简历,优中选优以便能够找到合适的求职者。 传统的简历审查方式存在招聘速度慢、成本高等问题。 因此,如何从简历中挖掘出求职者自身的价值并将其与已有的职位相匹配成为一个亟待解决的问题,这个问题则称为人岗匹配问题。
职位推荐作为人才招聘中的一项重要任务,已经有许多学者对其进行研究。 早期研究者根据用户的学历以及用户在每个职位上的点击、浏览时间等交互信息,采用协同过滤等推荐算法向用户推荐职位[1]。 早期方法忽视了工作和简历文档的文本语义信息,因此,为了充分利用简历和职位要求中丰富的文本语义信息,大多数研究将人岗匹配任务视为文本匹配任务,就是将工作描述和简历内容表示为维数相同的隐藏向量,然后计算2 个向量的匹配得分,并据此预测简历与职位的匹配程度[2]。
CNN 作为近年来最流行的深度学习算法之一,已被广泛应用于人岗匹配领域。 Nasser 等学者[3]将简历分为不同的类别,并提出了一个CNN 模型,将简历与工作配对。 Zhu 等学者[4]提出了一个PJFNN模型,将简历和职位描述中嵌入的每个词分别用2个CNN 模型进行建模,并利用简历和职位之间的余弦相似度计算匹配分数。 Khatua 等学者[5]使用Twitter 中的双卷积网络来匹配招聘人员和求职者。虽然CNN 模型提取局部特征效果较好,但是容易忽略单词之间的顺序和关系,导致语义特征提取不够准确[6]。 LSTM 可以更有效地处理文本信息,更高效地挖掘文本潜在的语义信息,缓解梯度爆炸问题。于是,Zhou 等学者[7]将LSTM 应用于文本分类领域,提高了文本分类的准确度。 Qin 等学者[8]将分层RNN 模型应用于工作文档,提出了一种基于分层能力感知注意力机制的循环神经网络结构来学习文本的语义表示。 Jiang 等学者[9]通过LSTM 模型学习求职者和招聘人员的隐含意图,结合语义生成求职者和招聘人员的有效表示。 为了充分发挥CNN与RNN 提取特征时的优势,许多研究者将CNN 与LSTM 结合使用,以便提高模型提取特征的能力。如:李超凡等学者[10]提出了一种基于注意力机制结合CNN-BiLSTM 的文本分类模型,解决了中文电子病历文本高度稀疏且分类效果不佳的问题。 吉兴全等学者[11]使用CNN 与LSTM 对短期电价进行预测,提高了电价预测的精度及预测效率。 任建吉等学者[12]针对电网数据具有非线性和时序性的特点,将CNN 与BiLSTM 结合提取数据本身的时空特征,提高了模型的预测精度。 以上模型虽然提升了模型提取特征的效果,但大多采用递进式网络结构,导致提取到的信息向后传递时容易发生梯度消失或梯度爆炸的问题,同时递进式网络结构提取文本特征时只用到单一网络的优势,无法融合CNN 和RNN 提取文本信息的优势,因此最终效果有待提升。
为了提高人岗匹配的效果,本文提出一种端到端的人岗匹配模型BATPJF,该模型采用并列式网络结构,充分发挥了CNN 提取局部特征的优势与BiLSTM 记忆功能的优势,有效改善了模型的整体结构,提升了人岗匹配的效果。
1 模型构建
1.1 问题定义
令jobi={jobi,1,jobi,2,…,jobi,p} 为一条岗位招聘信息,其中jobi,j(j∈[1,p]) 为具体的岗位需求或职责,令表示岗位jobi,j的信息中包含的s个词。 又令ri={ri,1,ri,2,…,ri,q} 表示一份简历,其中ri,j(j∈[1,q]) 表示该简历包含的具体工作经历,再令表示工作经历ri,j的信息中包含的u个词。 给 定 一 组 数 据S =〈J,R,Y〉, 其 中,J =为 招 聘 信 息,R =为简历信息,Y为招聘结果标签。 本文的目标是训练一个匹配函数M,并根据M来快速精准地预测一份简历ri与jobj之间的匹配结果。 由于人岗匹配问题很难直接得到一个绝对的匹配分数,且很可能会导致过拟合和模型偏差[13],因此采用Top-K 的方法优化排名。
1.2 模型概述
本文提出的模型BATPJF 主要由TextCNN 网络、BiLSTM-Attention 网络、融合层和匹配预测层构成。 模型的总体框架如图1 所示。
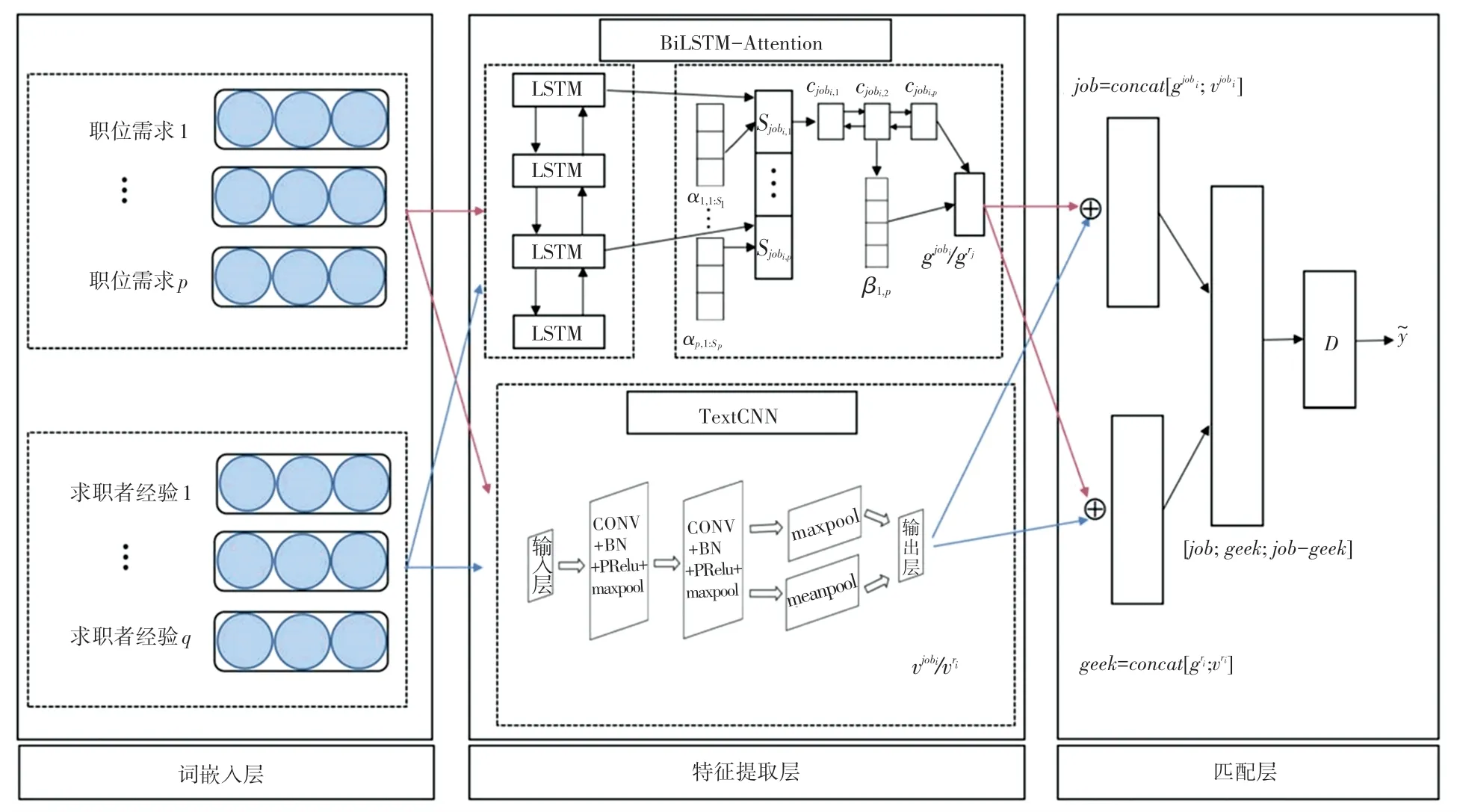
图1 BATPJF 模型图Fig. 1 Structure diagram of BATPJF
考虑到职位描述和简历中包含大量描述职位要求或求职者经历的词语,而TextCNN 在捕捉文本数据的层次关系和局部语义方面效果较好,因此本文运用TextCNN 模型用于提取数据中的关键性词语。卷积层与池化层的交替结构对于数据特征的提取是有效的,因此在TextCNN 中,使用卷积层和最大池化层以交错堆叠的方式自动提取职位描述和简历文本数据的局部特征,并将所得特征向量输出。
TextCNN 模型通过卷积核提取输入文本的局部特征,但是滤波器的大小限制了模型学习文本数据前后的依赖关系。 所以本文使用BiLSTM-Attenion模型用于提取文本上下文依赖关系并分别对不同的词和句子分配相应的权重。 具体如下:首先使用BiLSTM 分别获取简历和职位描述的词级别的文本表征,然后将文本表征作为注意力机制层的输入来预估每个单词的重要性,接着根据每个能力要求的隐藏状态和所有能力要求的上下文向量之间的相似性计算出每个能力要求的重要性并输出。
最后,将TextCNN 模型捕捉到的局部特征,以及经过并行的BiLSTM-Attenion 模型提取到的上下文特征进行特征拼接后,输入到全连接层,并经由Softmax层输出结果。
1.3 TextCNN 层
TextCNN 主要由输入层、卷积层、归一化层和池化层构成。 本文以岗位描述部分为例进行说明。TextCNN 层模型如图2 所示。
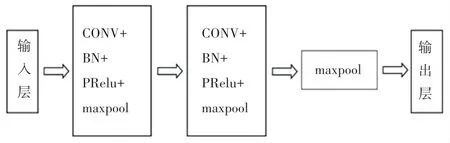
图2 TextCNN 层Fig. 2 TextCNN layer
对于jobi,j中的第l条需求中的第t个词的d0维词向量于是第l项需求对应的矩阵可表示为。 首先,使用卷积层提取第l项需求的文本特征,然后对卷积层的输出应用批归一化处理以降低训练成本,接着运用Prelu激活函数对输出值做非线性变换操作,最后使用池化层压缩提取到的特征以减少模型的计算量,同时增加模型识别特征的抗干扰能力。在此基础上,将所有需求项的向量通过最大池化层投 影 到 一 个 向 量 上:vjobi=[max(vjobi,1),max(vjobi,2),…,max(vjobi,p)],以表示职位描述。
简历部分的模型与岗位部分的相似。 唯一不同的是最后一层使用均值池化将求职者经验表示集成到简历表示中。 对此可用如下公式进行描述:
1.4 BiLSTM-Attention 层
1.4.1 BiLSTM
LSTM 模 型 是Hochreiter 等 学 者[14]为 了 解 决RNN 模型因处理信息过多导致的梯度消失或梯度爆炸问题提出的模型。 BiLSTM 作为LSTM 的一种变体,由一个正向LSTM 和一个反向LSTM 模型拼接而成。 其结构如图3 所示。首先获得招聘信息中jobi,j的词向量表示:其中,表示第l条需求中第t个词的d0维词嵌入,We是参数矩阵,表示jobi中第l条需求的第t个词向量。 对jobi,l中的每个词,计算对应的语义表征可表示为:。 同理,可得R对应的语义表征:
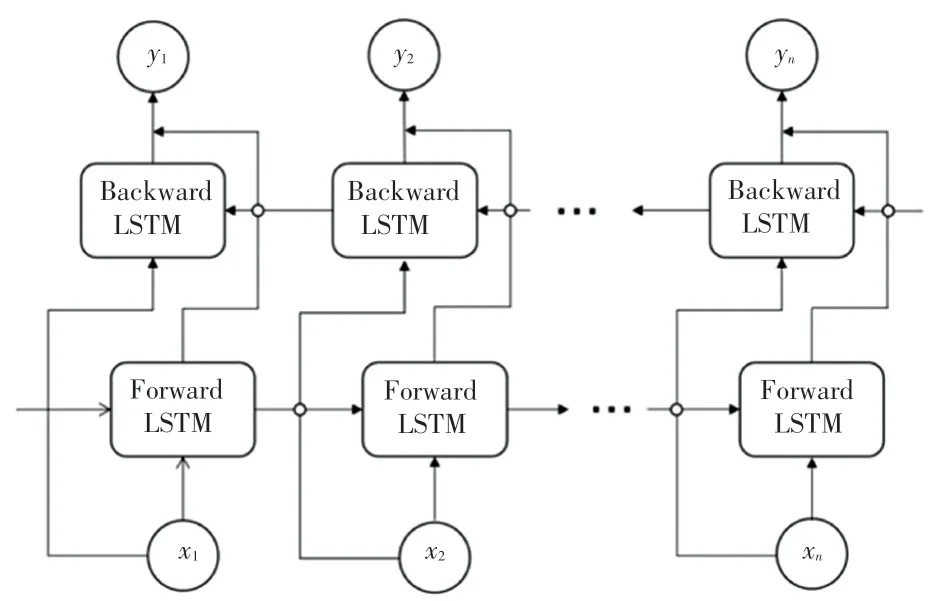
图3 BiLSTM 结构图Fig. 3 Structure diagram of BiLSTM
1.4.2 注意力层
在自然语言处理领域,注意力机制被用来为不同重要性的词或句子分配权重,权重越大的词越重要。将经过BiLSTM 处理后的语义表征作为全连接层的输入,计算字符级别文本向量间的关联度,然后使用Softmax函数计算注意力分数α,即:
其中,vα、Wα和bα分别表示训练过程中的可学习参数;vα表示jobi,l的上下文向量。 接着通过式(5)计算词级别的岗位需求表征:
再将词级别的岗位需求表征{sjobi,1,sjobi,2,…,sjobi,p} 作为BiLSTM 层的输入,并可推得:
运算得到隐层状态向量{cjobi,1,cjobi,2,…,cjobi,p},此后根据每个能力要求的隐藏状态和所有能力要求的上下文向量间的相似性计算出每个能力要求的重要性βt,即:
其中,Wβ、bβ和vβ是可学习参数,最后句子级别的岗位需求表征可用式(9)计算:
同理可得简历的需求表征为:
1.5 匹配预测层
将TextCNN 层输出的职位需求向量vjobi与通过BiLSTM-Attention 表示的职位向量gjobi进行融合,即job =concat[gjobi;vjobi],同理可以得到简历的特征为geek =concat[gri;vri]。 为了预测彼此之间的匹配程度,将其输入全连接网络预测人岗匹配程度,即:
其中,Wd、bd、Wy、by是可学习参数。
2 实验结果与分析
2.1 数据集描述
为验证BATPJF 模型的有效性,实验使用智联招聘人岗匹配数据集。 为保护用户隐私,所有简历都做了脱敏处理。 原始数据集包含4500 份简历、269534 份招聘信息和700938 条申请记录,在剔除职位描述为空、没有成功申请的数据之后,最终数据集见表1。 将数据集按8 ∶1 ∶1 的比例划分为训练集、测试集和验证集。 本文为每个正样本均匀地抽取一个负样本组成训练集。

表1 数据集的基本统计信息Tab. 1 Basic statistics of data set
由表1 的交互(申请、成功、失败)记录可知,成功率仅约为4%,这从侧面反映了人才招聘工作的困难,而这正是本文工作的意义与价值所在。
2.2 实验描述
本文以申请成功的工作-简历对作为正样本,以未申请成功的工作-简历对作为负样本对模型进行训练。 以下是实验中的一些基础设置:batch_size设置为128,epoch设置为300。 测试集的大小设置为128,验证集的大小设置为1024,若验证集上的评估结果连续10 个epoch没有增加,训练将提前停止。 为了尽可能地避免过拟合现象的发生,将drop_out设置为0.5,并在TextCNN、BiLSTM 中分别选择Prelu、LeakyRelu作为激活函数,以提高模型的非线性表达能力并加速模型收敛速度。 为了更好地学习模型参数,选择Adam 作为优化器进行训练。模型的具体参数见表2。

表2 参数设置表Tab. 2 Parameters setting
2.3 实验结果
为验证本文提出的BATPJF 模型性能,将其与BPR[15]、 BPJFNN[16]、 APJFNN[16]、 LightGCN[16]、PJFFF[17]模型进行比较,评价指标主要采用命中率(Hit Rate @ k,HR) 和 归 一 化 折 损 累 计 增 益(NDCG@k) 来综合判断模型的性能。 实验结果见表3。 表3 中,带“∗”符号的表示对比模型中的最佳结果。
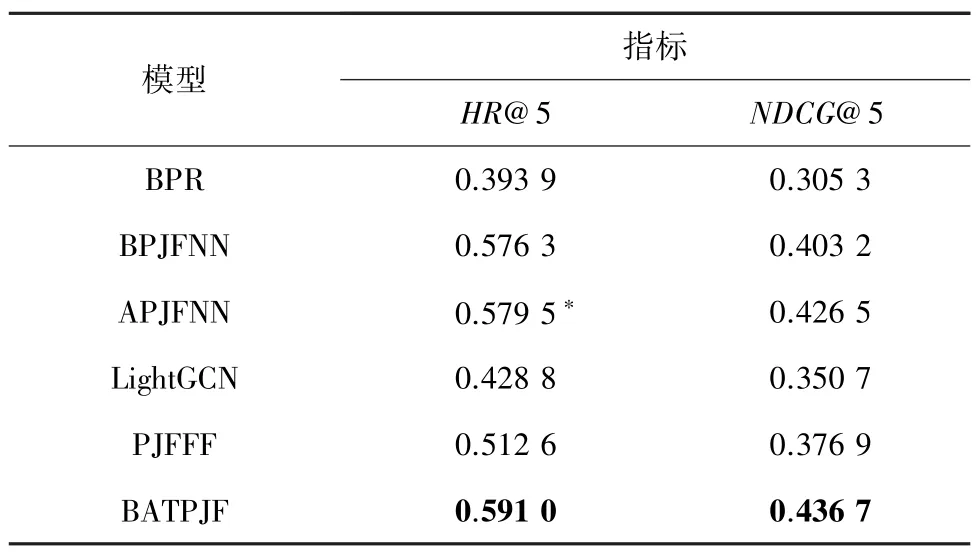
表3 不同模型在数据集的结果Tab. 3 Results of different models in the dataset
由表3 可知,本文提出的模型相比参照模型中最好的模型APJFNN 在指标HR@5 和NDCG@5 上分别提高了1.98%和2.39%。 由此可见,BATPJF 模型能充分发挥TextCNN 提取局部特征的优点与BiLSTM 具有记忆功能的优点,且注意力机制的加入,可以计算工作要求对不同工作经验的重要性以及工作经验对不同工作要求的贡献,因此性能优于其他对比模型。
3 结束语
本文针对人岗匹配问题提出了一种基于深度学习的端到端人岗匹配模型,模型首先通过词嵌入将文本表示成低维词向量矩阵,接着利用TextCNN 和BiLSTM 分别提取职位描述和个人经历文本中的局部关键信息和上下文信息,最后将得到的结果进行融合,提高了人岗匹配的效果。 通过与其他模型进行对比,证明了本文模型BATPJF 的有效性。 由于人岗匹配包括结构化和非结构化数据的匹配,而本文仅考虑了非结构化文本数据的匹配,所以下一阶段的工作是将结构化的信息也考虑进模型中,以便进行更好的人岗匹配。
猜你喜欢
中国医院院长(2022年2期)2022-11-09
英语文摘(2022年9期)2022-10-26
今日财富(2020年1期)2020-01-30
环球时报(2018-01-10)2018-01-10
——内部人身份感知和创新自我效能感的作用
商业经济与管理(2017年7期)2017-08-27
中国社会保障(2017年3期)2017-06-07
近代史学刊(2017年2期)2017-06-06
黄河黄土黄种人(2017年4期)2017-04-26
福利中国(2016年4期)2016-02-10
海外星云 (2014年22期)2015-01-19
