
基于Albert 和句法树的方面级情感分析
2023-05-18 08:14王跃跃
智能计算机与应用 2023年4期
王跃跃
(上海理工大学 管理学院, 上海 200093)
0 引言
情感分析,也称为观点挖掘[1-2],是自然语言处理中的重要任务。 与文档级情感分类任务[3-4]不同,方面级情感分类是一种细粒度的情感分类任务。具体目的是识别上下文句子中某一特定方面的情绪极性,如积极、消极、中性。 例如,给出一个句子“食物很好,但服务很慢”,“食物”和“服务”这2 个方面词的情绪极性分别是积极的和消极的。 方面级情感分类任务克服了一个句子中出现多个方面词时文档级情感分类的局限性。 在前面的例子中有两个方面词,整个句子的情感极性并不是单一的,而是掺杂着积极和消极2 种情感,如果忽略了方面词信息,就很难确定一段文本中表达的情感极性。 这种错误在一般的情感分类任务中普遍存在。 Jiang 等学者[5]通过实验显示40%的情绪分类错误是由于没有考虑方面词。
针对方面级情感分析任务,目前已经提出了很多的方法。 典型的方法是通过监督训练来构建机器学习分类器。 在基于机器学习的多个方法中,主要有2 种不同的类型。 一种是基于人工创建的特征构建分类器[3,5]。 由于神经网络能够在不进行繁杂的特征工程的情况下从数据中学习到数据中的知识,现已广泛应用在诸如机器翻译、问答任务等NLP 任务中,其应用效果明显优于传统的机器学习方法。近年来,研究学界针对方面级情感分析相继做了很多工作,如TD-LSTM[6]、TC-LSTM[6]。 但是在注意力机制[7]提出之前,对于上下文中的哪些词对于方面词的情感分类虽是重要的,却一直未能获得有效解决。
通过分析以往的方面级情感分析模型和相关的数据集,并且基于神经网络的优点,本文提出了一种基于Albert 和句法树的方面级情感分类模型,简称Albert-DP。 前期,基于LSTM[8]的方法主要集中于文本建模,本文的方法使用Bi-GRU[9]同时建模方面词和上下文信息。 即如前文的例子“食物很好,但服务很慢”中,这句话中有2 个方面词:食物、服务。 根据日常的语言经验,可以知道消极的词语“慢”更可能描述的是“服务”,而不是“食物”。 类似地,对于方面词“服务”,“很好”和“慢”两个修饰语与“服务”的距离都很近,如果采取PBAN[10]的位置信息的方法,这2 个修饰语会得到很相近的权重,这会使神经网络得到错误的分类。 所以应该尽可能降低“很好”的权重,引入句法树进行上下文位置信息的编码,可使这个问题得到有效缓解。 同时,本文使用Albert[11]预训练模型、而不是Glove[12]词向量可以解决语言表达中的一词多义问题,就能更加充分地利用句子的潜在语义信息。
1 相关工作
1.1 情感分析
情感分析的目的是检测文本的情感极性。 为此已陆续提出多种方法[13]。 现有的研究大多使用机器学习算法、如朴素贝叶斯和支持向量机算法等,以监督的方式对文本进行分类[14-15]。 这些方法中的大多数或者依赖于n-gram 特性,或者依赖于手工设计的特性。 为此,建立了多个情感词汇[4,15-16]。 近年来,神经网络在情感分类方面取得了长足的进步。基于神经网络的方法自动学习特征表示,不需要大量的特征工程,为此研究人员提出了多种神经网络结构,经典的方法包括卷积神经网络[17]、递归神经网络[18-19]。 这些方法在情感分析中取得了良好的效果。
1.2 细粒度情感分析
方面级情感分类是情感分类的分支之一,其目标是识别句子中某一特定方面的情感极性。 一些早期的研究设计了几种基于规则的方面级情感分类模型[20-21]。 Nasukawa 等学者[21]首先对句子进行依赖解析,然后使用预定义的规则来确定关于方面词的情感。 随后,又引入了多种基于神经网络的方法来解决这一层面的情感分类问题,典型方法是基于LSTM 的神经网络。 TD-LSTM[22]通过2 个LSTM 网络在建模上下文过程中考虑方面词的信息,并利用2 个LSTM 的最后一个隐藏状态进行情绪预测。 为了更好地捕捉句子中的重要部分,Wang 等学者[23]利用方面词嵌入生成注意向量,将注意力集中在句子的不同部分上。 以此为基础,Ma 等学者[24]使用2个LSTM 网络分别建模句子和方面。 可进一步使用句子生成的隐藏状态,通过池化操作计算对方面目标的注意,反之亦然。 因此,研究中的IAN 模型可以兼顾句子中的重要部分和目标。 Zhang 等学者[25]提出了两门控神经网络。 一个门用来捕获句子的语法和语义信息,另一个门建模左右上下文的交互关系。 Chen 等学者[26]采用基于Bi-LSTM 的多层架构,每一层都包含基于注意力的词特征和句子特征,该模型可以从不同的上下文中关注到对方面词分类的不同贡献程度。 Fan 等学者[27]提出多粒度的注意力网络,使用细粒度的注意力网络捕获方面词和上下文之间的词级别的交互。 Gu 等学者[10]认为距离方面词较近的词语对方面词的情感极性的贡献较大,反之贡献则较小。
预训练模型基于大量的文本语料训练,在微调时可以将语训练阶段学习到的语言知识运用到下游任务中,而且也陆续展开了基于预训练模型的方面级情感分析的多项工作。 Xu 等学者[28]提出了一种新颖的用于问答任务的后训练方法,同时也将其成功应用在方面级情感分析任务中。 BERT-SPC 模型[29]是利用BERT 对句子对分类的优势,将上下文和方面词一起作为模型的输入进行分类。
2 模型
2.1 任务定义
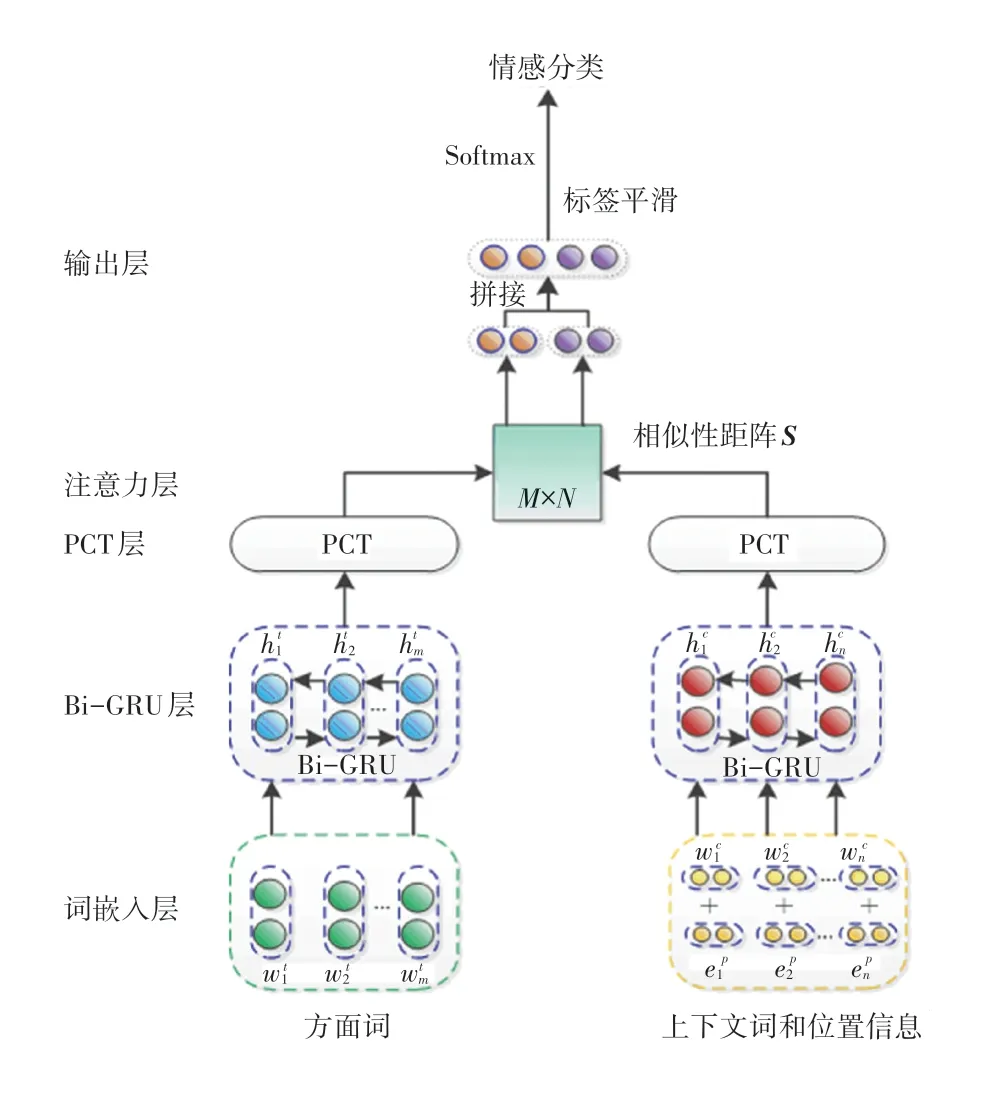
图1 Albert-DP 模型架构Fig. 1 The architecture of the proposed Albert-DP
2.2 词嵌入层
Albert 模型的全称是A Lite Bert,类似于一个轻量级的Bert 模型[30]。 因为预训练模型动辄有几千万或者上亿的参数,使用预训练模型在下游任务中微调时计算成本很大,并且在生产环境中部署预训练模型也是一个重要问题。 为了解决上述的问题,Lan 等学者[11]提出了Albert 模型,该模型使用矩阵分解和编码层参数共享的方法降低了模型参数。 以Albert-xlarge 为例,该模型的参数量为6000 万,Bert-base 模型参数量为1.08 亿,而本文中的Albert模型均指Albert-xlarge,Bert 模型都指Bert-base。Albert 嵌入层使用预训练模型Albert 生成序列的词向量,为了便于利用Albert 模型的预训练和微调过程,本文中则将给定的上下文和方面词信息数据转换为“[CLS] +上下文+[SEP]” and “[CLS] +方面词+[SEP]” 的格式。
为了更好地与基准模型进行对比,本文使用预训练后的Glove 词向量[11],词嵌入矩阵L∈ℝdemb×|V|,demb表示词向量的维度大小,|V |表示词表大小,通过从矩阵L中将每个单词wi映射为对应的向量ei。
2.3 引入句法树的位置信息
句法树描述了句子组织的层次结构,在自然语言处理中描述句子句法结构的树状表示。 通过构建句子的句法树,可以分析出单词之间的关系,更加准确地找出与方面词相关的情感词。 PBAN 模型[31]出于和方面词信息更靠近的上下文更有可能在修饰方面信息的考虑,提出了上下文距离方面词位置的绝对距离, 例如,在句子“The appetizers are ok, but the service is slow”中,当方面词是“appetizers”时,把方面词的权重设为0,给定上下文的位置索引则分别表示为p =[1,0,1,2,3,4,5,6,7],位置矩阵P是随机初始化,参数在模型训练中不断更新。 这样上下文中不同的词因为距离方面词的不同就会有不同的权重,可以能更加准确地找到修饰方面词的上下文,提高分类的准确率。 由于语言表达的多样性和复杂性,并且受到LCFS-BERT[32]的启发,引入句法知识可以更加有效判断与方面对应的情感意见表达,排除无关情感表达的干扰。 语义依存树可以获得句子中不同词之间的依赖关系。 通过句法树获得不同词之间的相对距离更符合语言表达的习惯,对于不同方面的情感分类会更加有效。 通过句法树形成的相对语义距离可以更准确地找到修饰方面词的表达。 句子“The appetizers are ok, but the service is slow”的句法解析如图2 所示。
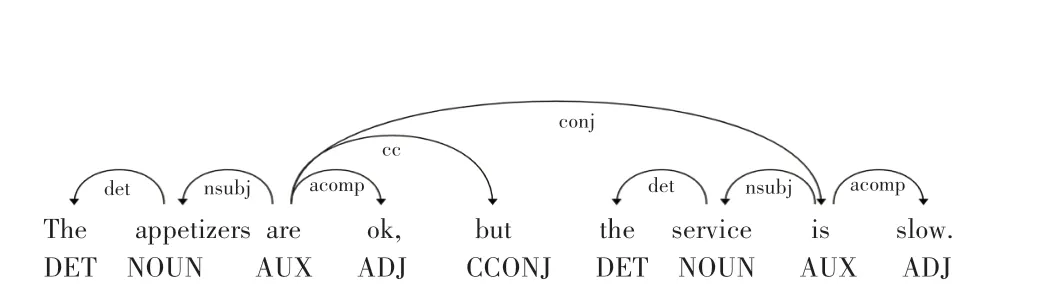
图2 句子“The appetizers are ok, but the service is slow.”句法解析图Fig. 2 Syntactic parsing diagram of sentence “The appetizers are ok, but the service is slow.”
SpaCy 工具能够快速准确地解析句子的依存关系,SpaCy 使用head 和child 来描述依存关系中的连接,识别每个token 的依存关系,通过Spacy 工具研究构建了每个句子的语法树,见图2,该工具给出了句子中的每个词的词性,其中DET、NOUN、AUX、ADJ 和SCONJ 分别表示限定词、名词、助动词、形容词和从属连词。 而且还指示出各个词语之间的语法关系。 nsubj 表示名词性主语。 acomp 用于动词的形容词补语,mark 表示标记语。 通过构建语法树可以准确找到方面词 price 的情感表达词“reasonable”,方面词“sevice”的情感表达词“poor”。在建模上下文词时通过(is,price,nsubj),(is,reasonable,acomp),( is,sevice,nsubj),(is,poor,acomp)的限定语法,本次研究给予形容词词性“reasonable”、“poor”更好的权重,而如果采用计算上下文位置信息的方法[10,28],则会赋予距离方面词“price”更近的词“The”、“is”更高的权重,而词“reasonable”将会获得更低权重,当方面词时,句子中不同词与方面A之间的相对语义距离D ={d1,d2,…,dn},所以通过构建语法树的方法可以明显提高方面级情感分析的准确率。
2.4 Bi-GRU 层
在得到词向量之后,将这2 个向量集合分别送入Bi-GRU 层,本文使用这2 个Bi-GRU 网络来学习句子和目标中单词的隐含语义,每个Bi-GRU 由2 个GRU 网络叠加而成。 使用GRU 的优点是可以避免梯度消失或爆炸的问题、能够很好地学习句子长期依赖关系,并且相对于LSTM 有更少的参数和更低的计算复杂度。 把方面词向量输入到左边的Bi-GRU 得到前向隐层状态和后向隐层状态,最终的方面词的隐层状态表示为,这里dh表示隐层单元的数量。 对于右边的Bi-GRU 结构,本文把上下文词向量和位置向量的拼接,作为右边的Bi-GRU 的输入。
2.5 PCT 层
PCT 层[29]是Point-Wise Convolution Transformation点式卷积转换的简称,主要的作用可以转换从Bi-GRU 得到的序列信息,并且过滤到噪声信息,该卷积核的大小为1,PCT的定义如下:
其中,σ表示ELU激活函数,“∗”表示卷积操作;和分别表示卷积核的可学习权重参数;分别表示卷积核的偏置参数。
2.6 注意力层
传统神经网络在处理数据时往往会忽略原有数据之间的联系,特别是处理文本信息时,当输入句子较长时,中间向量难以存储足够的信息,从而限制了模型的性能。 在自然语言处理过程中,注意力机制[7]允许模型根据输入文本以及其到目前为止已经生成的隐藏状态来学习要注意的内容,不同于标准神经网络将全部原文本编码成固定长度的语义向量,注意力机制将研究聚焦到特定区域,很好地解决了中间向量存储信息不足的问题。 该机制灵活地为神经网络隐层单元分配不同的概率权重,使得关键节点信息得到有效关注,降低了冗余信息对情感走向的影响。 利用注意力机制可以使模型更好地理解语义信息,全方位地关注更重要的内容以及整体的情感走向。 在通过Bi-GRU 层得到上下文和方面词隐层语义表示和PCT 层转换序列信息后,由于在包含多个方面词的上下文中,不同的方面词对于相同的上下文的贡献不同,而不同的上下文的对于修饰的相同的方面词贡献大小也不一样,例如在句子“我喜欢苹果电脑的系统,但这台笔记本电脑的扬声器质量不如我那台惠普笔记本电脑”中,方面词“扬声器质量”是由多个词语组成,“质量”对于该上下文的影响应该比“扬声器”大,上下文中的词应该将更多的注意力放在“质量”这个方面词上,而对于这种注意力的量化方法,本次研究中采用注意力机制。 本文通过PCT 层的上下文输出H和方面词输出Q构建了一个相似性矩阵S,N表示一个批次中的最大句子长度,M表示一个批次中的方面词的最大长度。Sij表示第i个上下文的词和第j个方面词的相关性,相似性矩阵S的计算公式如下:
其中,Ws∈ℝ1∗6d是权重矩阵;[;]表示向量的拼接;“∗”表示逐点向量元素乘积。
通过相似性矩阵S可以计算出每一个上下文词对方面词的权重αi以及m1。αi和m1的计算公式具体如下:
同样地,通过相似性矩阵S可以计算出方面词中的哪一个词语对于上下文的词是更加相关的,用m2表示,则有:
2.7 输出层
在全连接层之前,如果神经元数目过大,学习能力过强, 可能出现过拟合问题。 本文引入dropout[33]正则化手段随机删除神经网络中的部分神经元,用来解决过拟合问题。 全连接层拼接所有特征,得到一个高质量的特征图并输入到输出层。输出层通过Softmax分类器输出预测分类节点,每个节点表示一种分类,节点之和为1。 接下来,又选择Adam 优化器[37]优化整体网络参数,模型在使用梯度下降时,可以合理地动态选择学习速率,分配梯度下降幅度。 当训练中损失函数接近最小值时减小每步的梯度下降幅度;如果损失函数曲线相对陡峭,则适当增大下降幅度。 进一步地,给出数学公式见如下:
其中,y∈Rc是预测的情感极性分布,是可学习的参数。
在标签平滑上[32],通过观察中性标签的数据发现中性情感是不太明确的情感表达,故本文在损失函数中加入了标签平滑,标签平滑可以通过防止神经网络在训练过程中为每个训练示例分配全概率来减少过拟合,用平滑的值(如0.1 或0.9)替换分类目标的0 和1 值。 研究推得的数学公式可写为:
其中,u(k) 表示标签的先验分布;ε是平滑参数,本文中使ε =1/C,这里C表示分类的个数。 标签平滑等同于KL 散度[34],需用到的公式如下:
其中,u(k) 表示标签的分布,pθ表示神经网络的预测的结果,则本实验要优化的目标函数是:
3 实验结果及分析
3.1 数据集
本文在SemEval2014 任务4 的笔记本电脑和餐厅两个领域特定的数据集[35]以及ACL14 推特数据集[36]上进行了实验。 这些数据集的标签有3 个,分别是:中性、积极和消极。 这3 个数据集的训练集和测试集的一些统计情况见表1。
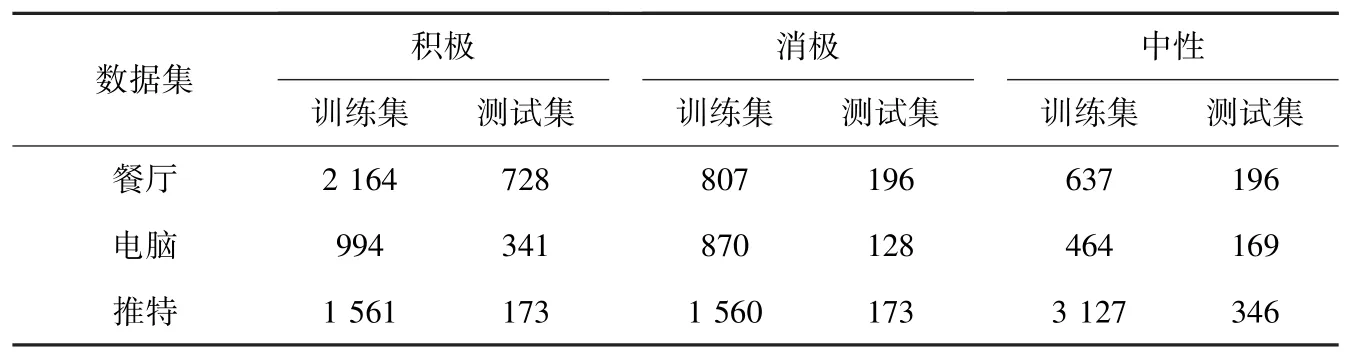
表1 3 个数据集的统计情况Tab. 1 The statistics of the three data sets
3.2 超参数设置
在实验中,首先随机选取20%的训练数据作为验证集来调优超参数。 所有权重矩阵从均匀分布U(-0.1,0.1) 随机初始化,所有偏差项设置为零。L2正则化系数λ=10-5,Dropout保持率为0.2。 词嵌入使用300 维Glove 向量进行初始化,并在训练过程中进行固定。 对于OOV 的单词,从均匀分布U(-0.01,0.01) 中进行随机初始化。 Adam 优化器[37]的初始学习率为0.01。 如果训练损失在每5个epoch后没有下降,将学习速率降低一半。 批量大小设置为64。 Bi-GRU 隐藏状态的维数设置为150,隐藏单元个数为200,模型的层数为2,采用ReLU作为激活函数。 迭代次数为10 轮,文本最大长度为一个批次中的最大句子长度。
3.3 模型对比
为了评估本文所提模型的有效性,将本文所提的模型与几种基线方法进行了比较,并且做了消融实验来进一步验证Albert-DP 模型的有效性。 通过在Restaurant、Laptop 以及Twitter 数据集上训练和评估模型,并且使用准确率和Macro - F1值来衡量模型的性能。 文中用到的数学模型详述如下。
精思的关键是善于提出问题和解决问题。读书的时候,要用脑子把作者的观点过滤一遍,提出有疑虑的地方,然后千方百计地解决疑问。这个过程能使我们在学习前人的基础上,取得发展和进步。
(1)TD-LSTM 模型[22]。 使用2 个LSTM 网络对围绕方面术语的前后上下文进行建模。 将2 个LSTM网络的最后隐藏状态连接起来,预测情绪极性。
(2)ATAE-LSTM[38]。 对隐藏状态采用注意力机制,并结合注意嵌入生成最终表示。
(3)IAN[24]。 使用2 个LSTM 网络分别对句子和方面词进行建模。 利用句子中的隐藏状态生成目标的注意向量,反之亦然。 基于这2 个注意向量,则输出句子表示和分类的目标表示。
(4)RAM[26]。 通过双向LSTM 网络对上下文词学习多跳注意,并且使用GRU 网络得到聚合向量。
(5)MemNet[39]模型。 对词嵌入进行了多重关注,所以能够从外部记忆中找出更多用于最终分类的依据,最后一层的输出被输入到softmax层进行分类。
(6)MGAN[27]模型。 在方面词是多个单词组成时或者方面词有着更长的上下文时会造成信息损失,提出多粒度的注意力机制。
(7)PBAN[28]模型。 编码方面信息时加入了上下文的位置信息,但仅仅采用距离方面信息的直线距离大小来衡量对方面信息情感极性的贡献。
(8)BERT-SPC[29]。 是使用预训练模型BERT进行句子对分类的任务,BERT-SPC 构造的模型的输入形式是“[CLS]”+global context +“[SEP]”+[asp]+“[SEP]”。
3.4 结果分析
表2 给出了本模型和其他模型的对比结果。 由表2 分析可知,Albert-DP 模型获得了最大的准确率和F1值的提升,这也表明本文所提模型的有效性。 TD-LSTM 的整体表现欠佳,因其对方面词的处理较为粗糙,在建模上下文词时没有充分利用方面词信息。 ATAE-LSTM、IAN 和RAM 是基于注意力机制的模型,并优于TD-LSTM 的表现,RAM 是比其他的基于RNN 的模型有更好的效果,但是在推特数据集上表现的效果却不好,可能是因为推文表达的不规范性。 IAN 模型注意到方面词和其上下文交互的重要性,在建模时使用交互的注意力机制,所以IAN 取得了比ATAE-LSTM 更好的表现。 MemNet因为从构建的外部记忆单元中获得了有用的信息,所以有关的各项衡量指标都超过了IAN 模型。PBAN 模型利用方面词的字符索引,并采用相对位置表示位置序列。 当不同的方面词中有相同的词语时,MemNet 并不能捕捉到这种差异。 BERT-SPC 模型和LCF-BERT 模型在建模时主要利用了BERT预训练模型的强大特征表示能力,各项指标都有很大的提升。 PBAN 模型由于在编码上下文位置时采用的是距离方面词的绝对距离,会存在一些不足。本文所提的模型,能够有效地弥补这种不足。 由于语言表达的复杂性,距离方面词很近的上下文不一定是修饰方面词,本文构建的通过句法树可以准确找到方面词的上下文词语,这更符合语言表达本身的特性。 所以能够明显提高分类的准确率。
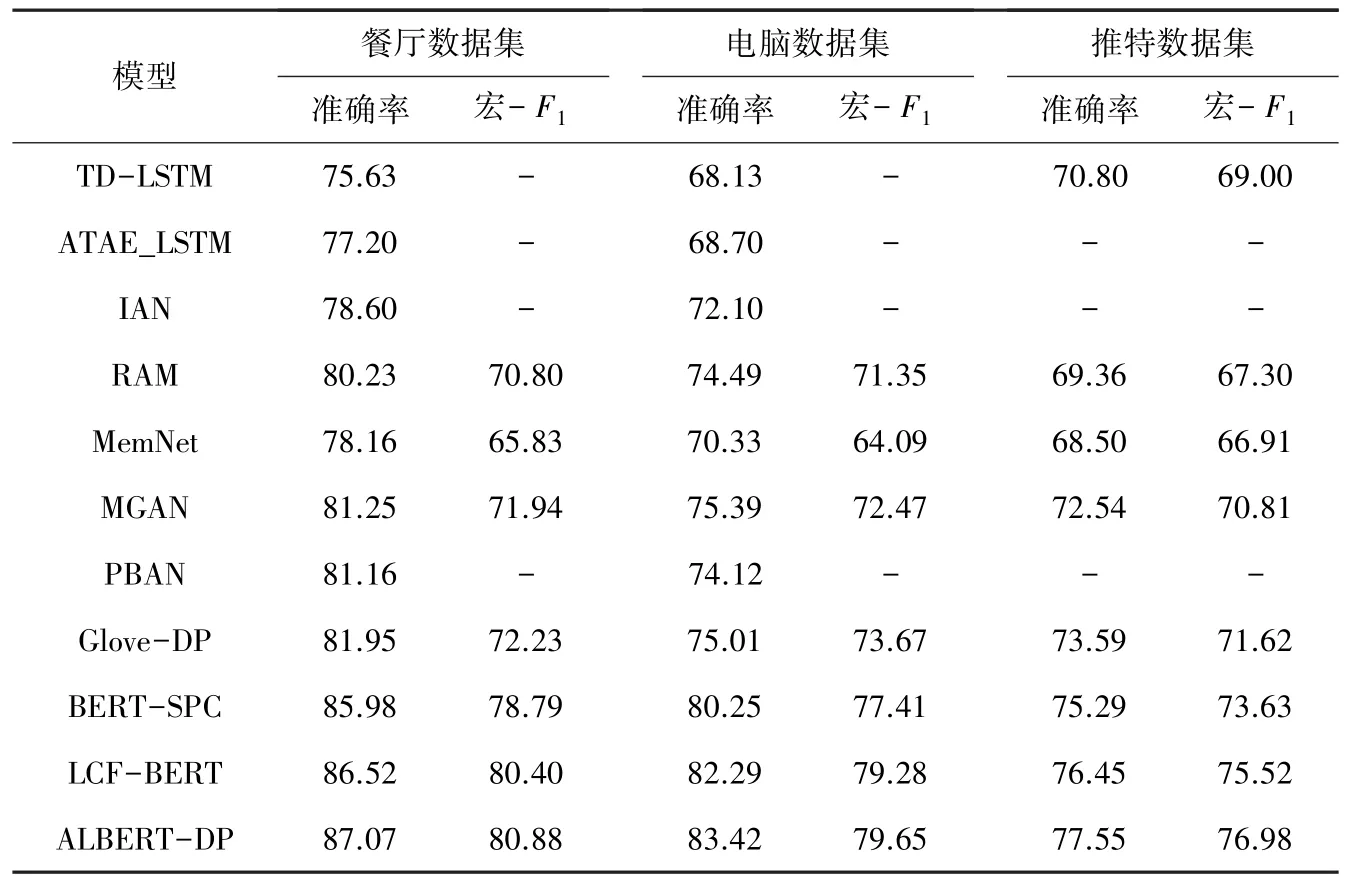
表2 3 个数据集上的不同模型的表现Tab. 2 Performance of different models on three datasets %
在表2 中,基准模型的结果来自于已发表论文中的结果,“-”表示论文中并未使用该衡量指标。
在实验中,本文发现性能随着随机初始化的不同而有很大的波动,这是一个在训练神经网络[41]时较为常见的问题,因此,运行了本文的训练算法10次,并将得到的平均准确率和F1值汇总列于表2中。
3.5 消融实验
为了验证本模型各个模块的必要性,本文做了一系列的消融实验。 借鉴AEN-BERT 论文中提出的PCT 方法,在经过Bi-GRU 获得的上下文和方面词语义信息后,使用PCT 层过滤掉干扰分类的噪声。 本文使用WP-PCT 表示去掉PCT 层,其他模块保持不变。 为了验证引入句法树对位置信息编码的有效性,本文采用了PBAN 模型中提出的位置信息方法来代替基于句法树构建的上下文位置信息的方法,简记为WO-DP。 GRU 相比于LSTM 模型有更少的参数,训练速度更快,但这2 个模型在不同的NLP 任务中都有着各自的优势,本实验通过改用LSTM 层来验证GRU 和LSTM 哪一个更适用于本文提出的任务,简记为W-LSTM。 Albert 模型相比于Bert 模型有很多的改进点,例如通过词嵌入层的矩阵分解、编码层的参数共享来降低参数以及将BERT 模型中的下一个句子预测任务(NSP)改为句子顺序预测任务(SOP)等。 在Albert 论文中作者在各大经典NLP 任务,如阅读理解、文本分类中都进行了实验,效果高于Bert 模型,但无法确定Albert模型在方面级情感分析任务中是否也能达到预期的效果,所以本文将Albert 模型改为Bert 模型进行验证。 实验结果见表3。
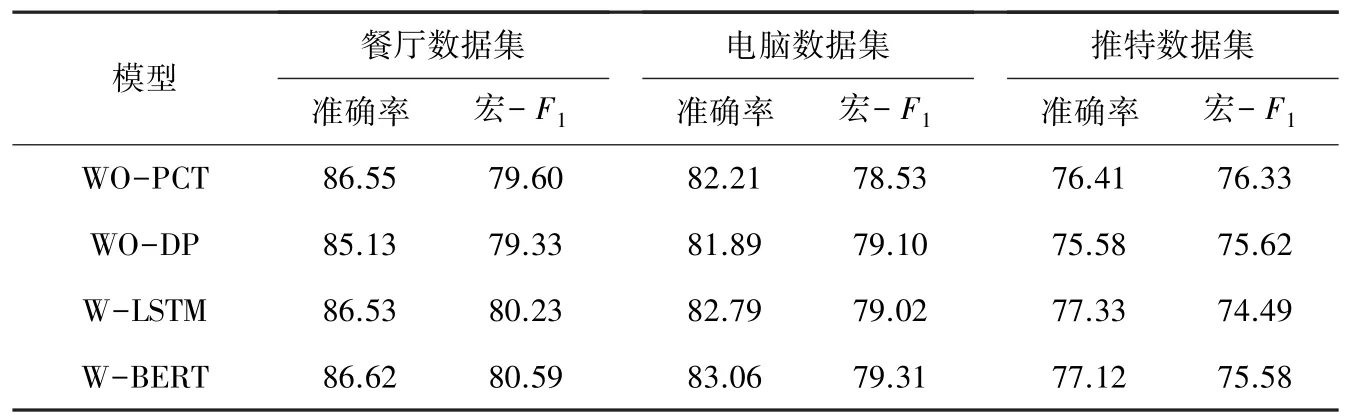
表3 4 种消融实验结果Tab. 3 Four kinds of ablation experimental results %
4 结束语
本文提出了基于Albert 和引入句法解析树的方面级情感分类模型Albert-DP。 以前的大部分工作都是基于静态词向量的词嵌入,不能对文本表达的多样性进行精确表示,同时对以往工作在建模上下文对方面词的位置信息存在的不足,提出了构建句子的句法树,来更准确地找到方面词的修饰语。 随后,研究又发现中性标签的数据集表达的不确定性,本文认为会存在一定的标签不可靠情况,所以在损失函数中加入了标签平滑的策略。 本文提出的模型在餐厅数据集(Restaurant)、电脑数据集(Laptop)和推特数据集(Twitter)上的实验表明,与那些基准方法相比,本文的模型Albert-DP 具有更好的性能,从而进一步验证了模型的有效性。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年19期)2019-11-23
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
高中生学习·高三版(2016年9期)2016-05-14
重型机械(2016年1期)2016-03-01
新高考·高二数学(2015年11期)2015-12-23
