
基于ESPnet的中文语音翻译实现
2023-05-23 10:13赵勇
无线互联科技 2023年6期
关键词:语音识别
作者简介:赵勇(1974— ),男,陕西高陵人,高级工程师,学士;研究方向:卫星通信。
摘要:当前,很多场合急需实现从语音翻译为文本的功能,如视频字幕制作、实时语译等。文章介绍了一种ESPnet语音识别框架架构,并基于ESPnet框架,训练得到最优模型,该架构模型能将语音识别过程扩展为网页在线识别,对目前主流语音识别框架进行对比试验并总结其优缺点。
关键词:ESPnet;语音识别;CTC
中图分类号:TP311.5 文献标志码:A
0 引言
随着计算机技术的快速发展,基于深度学习的翻译软件应运而生,但这些软件大多只能实现文本翻译功能,无法直接对语音进行翻译、转录为文字信息。事实上,在很多场合中急需从语音翻译为文本的功能,比如视频字幕制作、实时语译等。本文基于ESPnet框架,给出了一套网页端的语音翻译软件设计思路[1],该方案能够实时对上传到网页的语音进行翻译识别。本研究重点介绍了基于ESPnet框架实现语音识别翻译的原理及框架组成,将结果与其他主流框架进行对比,为后续其他学者研究提供参考方案。
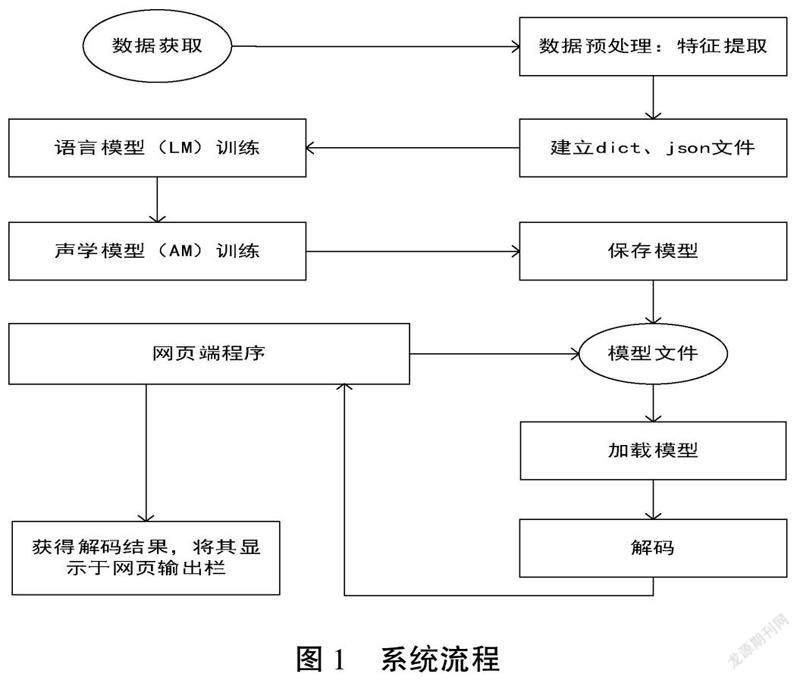
1 系统整体流程
系统整体实现流程如图1所示,整个系统流程可分为以下步骤。
1.1 特征提取
在数据预处理步骤时,对音频数据提取80维MFCC特征、三维基音特征归一化。
1.2 数据准备
在对音频数据进行特征提取之后,须对整个数据集音频中所包含的文字内容进行整合,提取数据集对应的转录信息,并保存为字典文件dict,后续对新语音翻译时所输出的文字内容也基于该字典文件,另外需要将每个训练语音的文字转录内容、发音者ID、音频编号等信息保存为json文件。
1.3 模型训练
首先训练语音模型(RNNLM),其网络结构能利用文字的上下文序列关系,更好地对语句进行建模,其次训练声学模型(AM),训练出基于CTC和attention混合的语音编解码器[2]。
1.4 网页端翻译服务
网页部分在接收到语音后,将会调用预设好的语音翻译程序,在语音翻译程序中对未知语音进行与模型训练时同样的预处理、特征提取过程,然后调用已训练好的最佳模型,对新的音频特征进行解码,得到最终预测结果,网页端在接收到反馈回来的结果后,将显示于网页上的翻译栏作为最终结果。
通过上述流程,实现数据处理、特征提取、模型训练、网页端语音翻译的整个系统性工作。
2 ESPnet网络架构
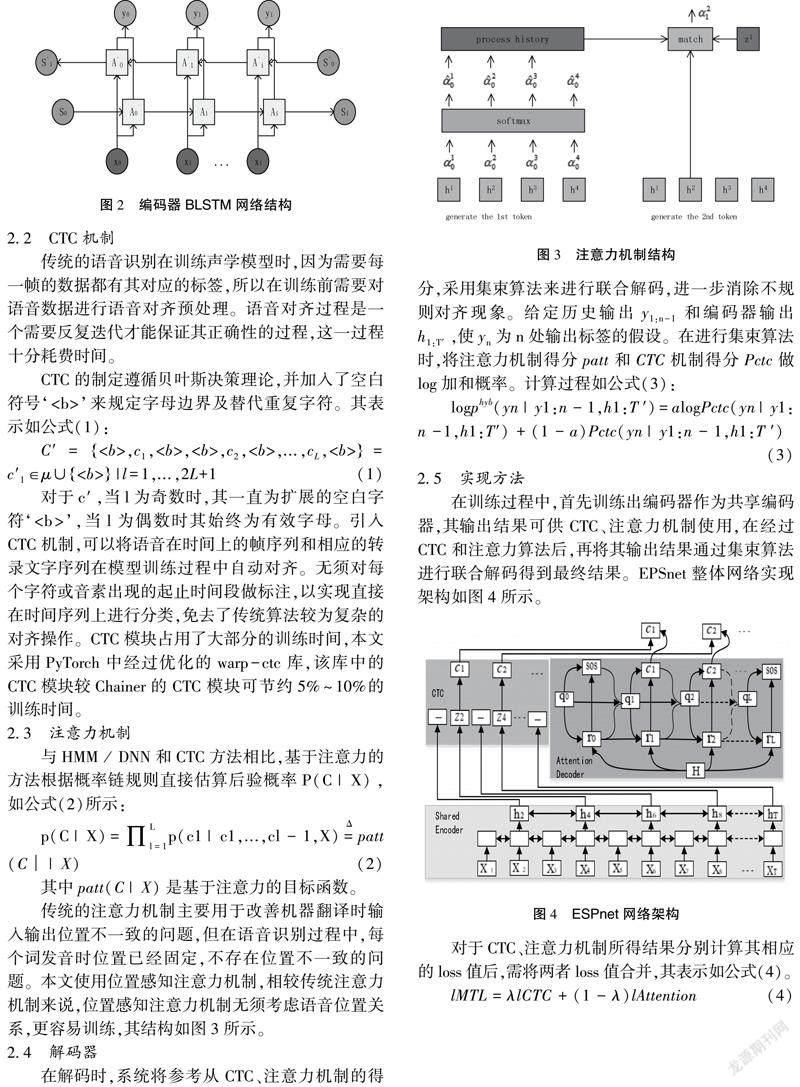
ESPnet的架构核心包括编码器、CTC机制、注意力机制、解码器4个部分[3]。
2.1 编码器
编码器网络采用双向长短时记忆网络(BLSTM),它能够更全面、准确地兼容语义信息,由两层LSTM构成,一个用于正向传递语义信息,一个用于反向传递语义信息,结构如图2所示。
2.2 CTC机制
传统的语音识别在训练声学模型时,因为需要每一帧的数据都有其对应的标签,所以在训练前需要对语音数据进行语音对齐预处理。语音对齐过程是一个需要反复迭代才能保证其正确性的过程,这一过程十分耗费时间。
CTC的制定遵循贝叶斯决策理论,并加入了空白符号‘来规定字母边界及替代重复字符。其表示如公式(1):
对于c′,当l为奇数时,其一直为扩展的空白字符‘,当l为偶数时其始终为有效字母。引入CTC机制,可以将语音在时间上的帧序列和相应的转录文字序列在模型训练过程中自动对齐。无须对每个字符或音素出现的起止时间段做标注,以实现直接在时间序列上进行分类,免去了传统算法较为复杂的对齐操作。CTC模块占用了大部分的训练时间,本文采用PyTorch中经过优化的warp-ctc库,该库中的CTC模块较Chainer的CTC模块可节约5%~10%的训练时间。
2.3 注意力机制
与HMM / DNN和CTC方法相比,基于注意力的方法根据概率链规则直接估算后验概率P(C|X),如公式(2)所示:
其中patt(C|X)是基于注意力的目标函数。
传统的注意力机制主要用于改善机器翻译时输入输出位置不一致的问题,但在语音识别过程中,每个词发音时位置已经固定,不存在位置不一致的问题。本文使用位置感知注意力机制,相较传统注意力机制来说,位置感知注意力机制无须考虑语音位置关系,更容易训练,其结构如图3所示。
2.4 解码器
在解码时,系统将参考从CTC、注意力机制的得分,采用集束算法来进行联合解码,进一步消除不规则对齐现象。给定历史输出y1:n-1和编码器输出h1:T′,使yn为n处输出标签的假设。在进行集束算法时,将注意力机制得分patt和CTC机制得分Pctc做log加和概率。计算过程如公式(3):
2.5 实现方法
在训练过程中,首先训练出编码器作为共享编码器,其输出结果可供CTC、注意力机制使用,在经过CTC和注意力算法后,再將其输出结果通过集束算法进行联合解码得到最终结果。EPSnet整体网络实现架构如图4所示。
对于CTC、注意力机制所得结果分别计算其相应的loss值后,需将两者loss值合并,其表示如公式(4)。
3 对比实验
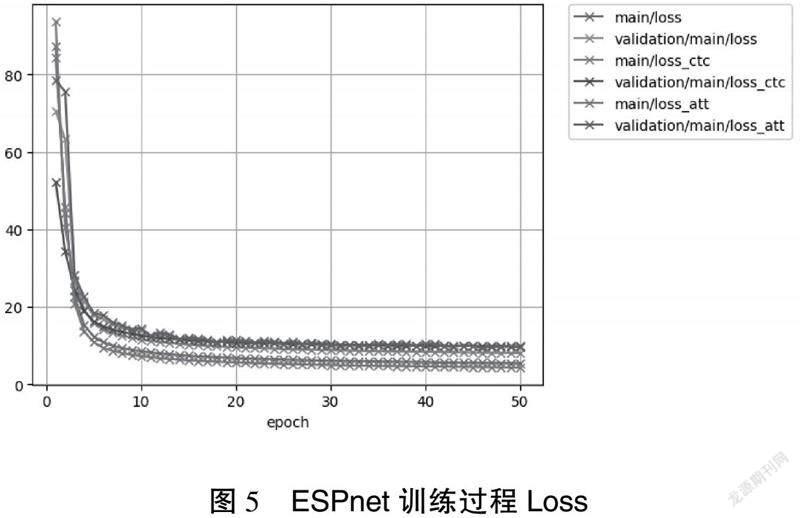
分别采用CTC和注意力机制时,获得了不同的结果,如图5所示,可以看出采用注意力方案时,模型在训练集的损失更小,但在测试集下损失较大,其鲁棒性不如CTC机制。本次实验数据集较小,对于更大的数据集,可以尝试注意力机制。
本文将ESPnet框架下的模型训练结果与其他框架、网络架构所得结果进行同条件下的语音识别正确率对比。这里使用到来自百度的Deepspeech深度学习语音识别框架,Kaldi语音识别框架。测试数据来自aishell数据集,结果如表1所示。从表1中看,采用ESPnet框架所得结果明显优于Kaldi和Deepspeech模型结果,但模型较大,须经过压缩、剪枝、稀疏化算法量化后才能具备可移植性。Kaldi模型虽然准确率稍低,模型稍大,但该框架中脚本大部分代码采用C++编写,效率更高,产出模型更小,更易于移植扩展。Deepspeech框架结构模型更大,受众面小。虽然基于百度的大数据优势,在超大型数据集上可能才会有更优的表现。
4 结语
从上述实验结果来看,ESPnet的准确性最高,Kaldi居中,但Kaldi的模型最小,易于移植,Deepspeech框架准确率稍低,模型最大。Kaldi的使用者虽众多,但Kaldi的自行调试较为复杂,其底层语音使用C++语音开发,代码量繁杂,不易调试;Deepspeech框架的使用者较少,代码调试过程复杂,其开发社区中可供参考的方案较少,使用起来专业门槛要求高。
ESPnet框架在数据处理时采用Kaldi工具库,依托于Kaldi活跃的开发社区,在数据处理时遇到问题可以十分快速找到解决方案。深度神经网络部分采用Pytorch框架进行编写,Pytorch是目前深度学习工作者都了解的深度学习框架。这些工作者根据自身任务不同对ESPnet的网络架构和模型参数进行修改,以达到最优结果。
参考文献
[1]SHINJI A, NANXIN C, ADITHYA R, et al. ESPnet: end-to-end speech processing toolkit[J]. Proc. Interspeech, 2018(18):2207-2211.
[2]GRAVES A, JAITLY N. Towards end-to-end speech recognition with recurrent neural networks[C]. Beijing: International Conference on Machine Learning(ICML), 2014.
[3]DUGGAN J, BROWNE J. Espnet: expert-system-based simulator of petri nets[J].IEE Proceedings D-Control Theory and Applications, 1988(4):239-247.
(編辑 傅金睿)
Abstract: At present, many occasions urgently need to translate from speech to text function, such as video subtitle production, real-time translation, etc.This paper introduces a speech translation based on ESPnet framework. Its optimal training model extends voice recognition to web page online recognition. It compares the current mainstream speech recognition framework and summarizes its advantages and disadvantages.
Key words: ESPnet; speech recognition; CTC
猜你喜欢
科技创新与应用(2017年3期)2017-02-18
中国新通信(2016年21期)2017-01-06
现代电子技术(2015年11期)2015-07-28
现代电子技术(2015年8期)2015-07-09
