
基于大数据分析的Service应用的设备升级方法
2023-06-03 12:10孟秀锦冉九红娄新燕
电脑知识与技术 2023年10期
孟秀锦 冉九红 娄新燕

关键词:Service 应用;应用升级;服务器;智能终端设备;预置应用;大数据
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2023)10-0078-03
0 引言
随着智能设备的普及,智能设备中预设的应用也越来越多,但是由于多种多样的问题,比如:网络问题、硬件问题、软件问题等等导致部分应用无法升级到高版本的应用,导致用户无法正常使用新版本的新功能,特别是涉及用户支付、用户账号由于低版本的应用导致用户数据不一致、无法支付等问题,对用户带来极大的不便利,用户体验也较差。目前主流的技术是修改底层的架构并且修改增加新的API(应用程序编程入口)来实现无法升级的应用的升级方式[1],该做法改动较大,成本高并且涉及物理改动,影响用户体验。本方案可以通过大数据分析不同平台、不同系统方案等导致的系统应用无法升级的预置应用(或者称为系统应用),在不修改底层逻辑,且已有的Service 应用(后台运行的应用并且该应用能够开机自动启动)上增加两个请求的方式来实现应用升级的方式,改动小且不会对现有的数据造成破坏,安全性更好[2]。
1 实现原理
1.1 前期准备
本方案采用的是客户端-服务器模式(人员与它们交互,以将请求发送到计算机服务器),通过将请求转发到服务器端进行处理,提高网络的并发性和处理速度,能够更好地提高用户体验。
1)大数据分析准备工作
采用hadoop-zookeeper-kafka大数据分析系统对所有在线机型(连接到互联网上的活跃的机型)的设备上运行的系统应用(也可以称为预置应用)的版本升级情况,对于一个升级周期之后(一般是一个月),对于系统应用无法升级的应用对其分析是否存在升级问题,如果存在升级问題无法正常升级的应用,通过配置Service应用升级策略。
使用hadoop 集群具有高可靠性,而zookeeper 是一个开源的分布式应用程序协调服务,可以用来保证数据在集群间事务上的一致性;kafka主要用于实现低延迟发送和收集大量的事件和日志数据——这些数据通常都是活跃数据;主要通过日志的形式记录下来这些数据信息,然后通过专门的系统来进行日志的收集与统计;kafka中存在消息生产者、消息消费者、主题、消息分区、Broker、消费者分组、Offset( 偏移量)[3-4]。
消息生产者:消息产生的源头、负责生成消息并发送到kafka服务器上。
消息消费者:是消息的使用方,负责消费kafka服务器上的消息。
主题:由用户定义并配置在kafka服务器上,用于建立生产者和消费者之间的订阅关系,生产者发送消息到指定的主题下,消费者从这个主题下消费消息。
消息分区:一个主题下会分为多个分区,消息分区机制和分区的数量与消费者的负载均衡机制有很大的关系。
Broker:kafka服务器,主要用于存储消息,在消息中间件中通常被称为broker。
消费者分组:用于归组同类消费者,在kafka中,多个消费者可以共同消费一个topic下的消息,每个消费者消费其中的部分消息,这些消费者就组成了一个分组,拥有同一个分组的名称,通常也称为消费者集群。
Offset:消息存储在kafka的broker上,消费者拉取消息数据的过程中需要知道消息在文本中的偏移量。
2)负载均衡
消费者如何实现负载均衡:设置PT为指定Topic所有的消息分区。
设置CG为同一个消费者分组中的所有消费者。
对PT进行排序,使分布在同一个Broker服务器上的分区尽量靠在一起。
对CG进行排序: 设置i为Ci在CG中位置的索引值,同时设置N =size(PT)/size(CG)。
将编号为i × \times× N ~ (i + 1) × \times× N – 1 的消息分区分配给消费者Ci。
重新更新ZooKeeper 上消息分区与消费者Ci 的关系。
3)日志的配置
获取升级日志的配置方式:
Config配置
Log_server的config文件可在hitv.conf中配置,安装后默认存储在/usr/local/fountain/conf目录,文件名为logconfig.info。
典型配置结构如下:
upgrade
{
msgid 23
filetag adeviewlog ; filename, if RT log,
means RT Queue Name.
max_file_size 10 ;Unit:M
rt 0 ;0:not RT ;1:RT
suffix_processor 0 ; 0: Normal; 1: Fill Cur?rent Time at Msg tail.
main_processor solve_common_log
rt_processor NULL
protocol 1;1:udp;2:tcp
init_processor 1 ; 1: initialize_log_file; 2: initial?ize_exception_log
}
zookeeper下的conf:
~/zookeeper-3.3.3/conf/zoo_sample.cfg
zoo.cfg的配置:
dataDir=/home/hadoop_server/zookeeper/data ——指向数据位置
dataLogDir=/home/hadoop_server/zookeeper/data ?Log ——指向数据日志位置
通过前面三步的配置和日志的分析获取,可以取得智能终端的預置应用的版本号和所在平台的相关信息[5]。
1.2 预置应用的升级
预置应用升级的具体步骤如下:
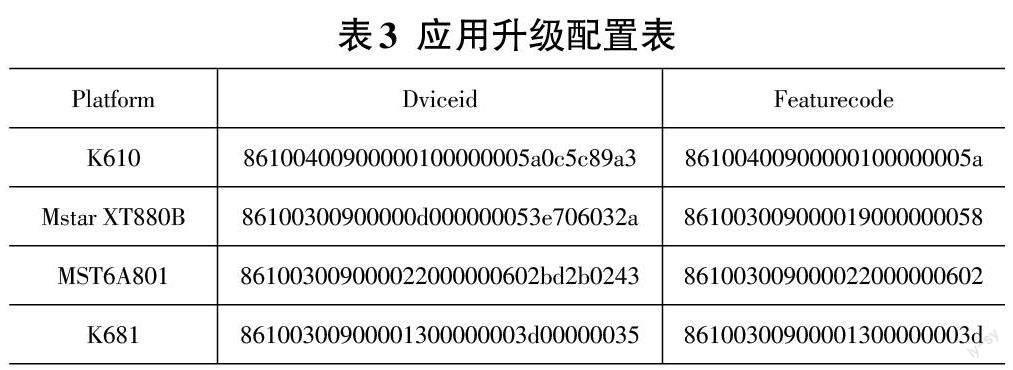
1)通过前述步骤获取无法升级的智能终端无法升级的预置应用的列表,运营后台根据设备类型和设备型号配置待升级的应用列表之后存储到数据库中;并配置对应应用的升级版本(源版本、目的版本、升级包、升级方式)。
2)智能设备开机之后,首先根据应用的appkey公钥、appsecret私钥(客户端和服务器端事先约定好)、用户名和密码,向服务器端获取认证鉴权所需的to?ken(用于请求的验证)信息。
3)智能终端携带第二步获取的token信息发送获取待升级的应用列表请求。
4)服务器端根据携带的token的信息对智能终端设备和应用进行鉴权认证。
5)认证通过之后,服务器根据终端设备的设备类型查询数据库中对应的应用升级列表。
6)智能终端设备根据获取到的应用列表,将本地的应用版本号和系统下发的应用版本号进行对比。
7)本地的应用版本号与系统下发的应用版本号是否一致,一致则保持不变,如果低于系统下发的应用版本号,则通过自启动的Service应用发送升级请求,该HTTP请求中包含应用当前版本的信息(包括当前版本号、appkey公钥、appsecret私钥、应用包名等)。
8)服务器收到该请求之后,对比数据库中的信息,根据数据库中配置的升级策略,通过业务服务器下发对应的目的版本、升级包。
9)智能终端设备根据获取升级包执行升级流程,首先获取升级包在文件服务器中的地址,然后通过后台下载,下载完成之后,将无法升级的应用包升级到更高版本。
该方案具体实现流程为:
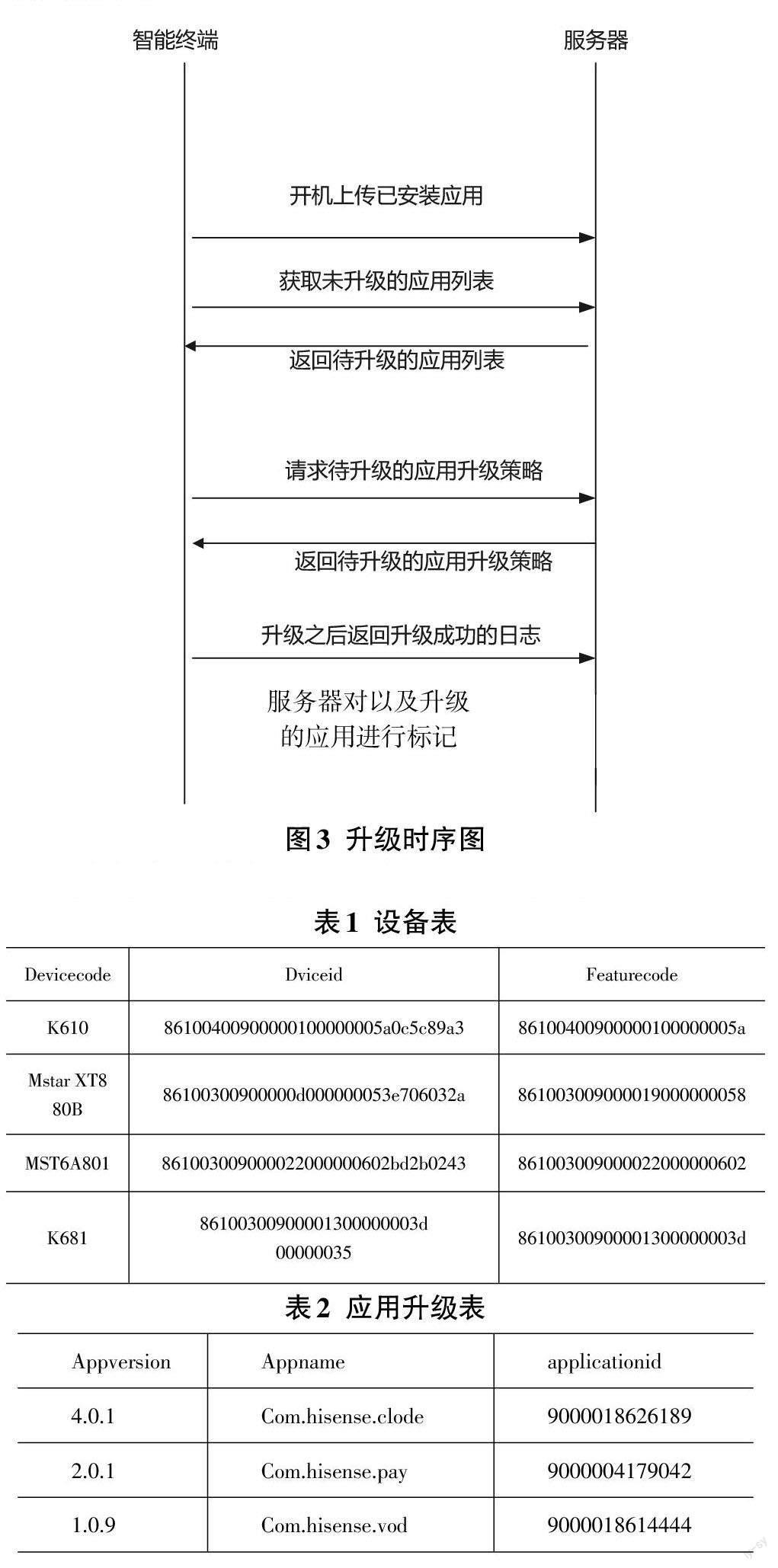
智能设备开机之后通过部署的大数据系统分析集群,上报本地已经安装的应用列表,服务器通过和数据库中的设备表进行对比,对获取到的应用进行分析(与对应机型根据机型的唯一标识进行识别的最高版本)。
查询对应的数据库(取出部分关键信息):
根据查询到的数据下发该机型对应的升级列表。
对比终端的应用版本,相同则不做升级请求的处理,不相同则发送升级请求。
系统端通过服务器下发该升级请求对应的升级版本目的版本以及应用的下载路径。
升级完成之后,系统端对升级成功的应用进行标识,对于升级成功的设备从数据库和缓存中进行删除。
2 总结
通过大数据系统分析预置应用的版本和平台信息,分析现在运行的应用软件的信息,通过在服务器端进行对比,能够检测出是否升级成功的信息,对于无法正常升级的应用(对于复杂的网络环境、终端设备兼容性等原因,导致已经预置的系统应用无法更新安装),业内主要采用修改底层设备和逻辑来实现应用的升级,对于这种方式修改的范围比较大,成本比较高,出现风险的可能性也比较高,并且用户的接受度也比较低,通过系统携带的Service应用,通过后台应用更新对于用户来说是透明的,不需要用户做任何操作,对用户来说接受度比较高,而且安全性也有保障,用户的数据信息不会发生变化和泄露,可以无感对接。
通过该方法可以使无法升级的固有应用能够正常升级,解决特别是老旧平台以及历史遗留的一些问题。
猜你喜欢
铁道通信信号(2019年9期)2019-11-25
网络安全和信息化(2017年10期)2017-03-08
知识产权(2016年8期)2016-12-01
网络空间安全(2016年3期)2016-06-15
