
基于BERT 的知识图谱文本生成系统*
2023-06-04 06:24蔡星娟
计算机与数字工程 2023年2期
梁 浩 蔡星娟
(太原科技大学计算机科学与技术学院 太原 030024)
1 引言
段落文本生成任务在自然语言处理(NLP)领域是一个非常具有挑战性的问题[1~2],该问题的核心是“语义鸿沟”,人类是依靠人的认知水平和生活经验为背景而产生的知识推理能力,而知识图谱正是可以模拟人类的知识背景,随着大数据时代的到来,构建一个大知识图谱将显著提升计算机的认知水平[3]。垂直领域知识图谱对于通用领域知识图谱更加准确,各个行业都开始建立自己的知识图谱。例如冯小兰等[4]构建了汉藏双语旅游领域知识图谱系统,解决了目前关于藏文景点的旅游知识匮乏的情况,构建了藏文旅游信息智能化服务系统。曹明宇等[5]利用知识图谱构建了关于肝癌的问答系统,增加了信息获取的便捷性。火力发电领域[6]是我国能源建设的重要组成部分,构建火力发电领域知识图谱亦有深远重大的意义。我们需要利用知识图谱技术[7],输入一些关键的词或者结论性的句子,根据知识图谱[8]的语义网络会生成相应的语句,这样省时省力。Xiaocheng Feng[9]等提出基于主题信息的神经网络文本生成模型,在传统的Sequence-to-Sequence 的框架下加入基于主题的Attention 机制和多主题覆盖机制,使得生成的文本具有跟主题相关的语义信息,但仅适用于通用领域,在专业领域的生成上效果不理想。孙博[10]提出一种基于生成对抗网络的文本自动生成方法在医疗领域取得较好的效果,但生成模型仍然是不可控生成,无法对生成的文本增加限制条件。Rik K[11]等提出了一种Graph Transformer 编码方法用于知识图谱表示学习,作者构建的图谱实体是在原文本中进行信息抽取,节点实体的描述类似自然语言的表达方式,取得了较好的效果,但是在非自然语言的文本生成[12]方面,仍然有很大的不足,对于专业领域的关键词仍然生成效果不够理想[13]。为此我们设计了一个基于知识图谱的火力发电领域段落生成系统来解决文本生成在专业领域方面的准确性不高的问题。
本文分析了文本生成领域的现状以及需要解决的问题,对火电领域本体进行建模,分步构建火力发电领域知识图谱,完成了基于知识图谱的火力发电领域段落生成系统,通过实验验证本系统可有效的对用户输入的文本进行语义扩充,即生成段落文本。
2 火力发电领域本体建模
2.1 分词
分词可以看作序列标注问题,结构化感知器是由Collins[14]在EMNLP 上提出来的,主要用于解决序列标注的问题。结构化感知机是以最大熵准则建模标注序列Y 在输入序列X 的情况下的score 函数判断:
其中,Φs(Y,X)为本地特征函数,给定X 序列,求解score函数最大值对应的Y序列:
但在专业领域下的分词效果不理想,效果如表1所示。

表1 LTP原始分词效果
使用LTP 分词之后有些实体并没有被精确的分出来,所以利用不断更新自定义词典的方法,来提高分词的准确性,我们在《中国电力百科全书(火力发电卷)》[15]和CNKI 论文关键字中提取了4586个精确的领域专有名词,以及1890 个法律法规名词,将其加入自定义词典中,分词效果有较大提升,如表1自定义分词所示。
2.2 词性标注
词性标注的方法分为基于规则的词性标注方法和基于统计的词性标注方法,基于统计的词性标注方法主要有HMM(隐马尔科夫模型)[16]。该模型可以由隐藏状态序列生成观测序列。利用该模型进行词性标注,如表2所示。

表2 Hanlp词性标注
可以看出利用词性标注并不能够很好地应用在火力发电领域语料中,因此需要增加一些人工的词性标注规则。人工标注的词性组合可以把它作为一个完整的名词,部分如表3所示。

表3 人工标注词性组合
基于人工标注的词性规则抽取专业领域实体,并把它补充到自定义词典中,可以大大增加命名实体识别的准确率。基于此规则我们抽取出2482 个专业领域词汇加入到自定义词典中。
3 构建火力发电知识图谱
3.1 数据获取
由于该领域尚未有公共语料库,因此本系统采用的语料由节能报告25 篇,每篇平均5 万字左右,可行性研究报告30 篇,每篇10 万~15 万字左右,CNKI 下载相关论文60 篇,每篇论文6000 字左右,在《中国电力百科全书(火力发电卷)》中的大量专业名词,以及文本语料构成。
3.2 知识三元组
知识图谱的核心是“实体(Entity)-关系(Relationship)-实体(Entity)”构成的三元组,可以表示为<EF,R,EE>其中EF代表头实体,EE代表尾实体,R代表实体之间的关系。以“实体-关系-实体”的三元组形式就可以描述实体之间大量的语义关系。本文从语料中整理出121868 个句子,在这些句子中我们提取出109565 对三元组关系,实体之间不同的关系表示为R,如图1列出了部分实体间的关系。

图1 实体关系图
3.3 火力发电知识存储
当前在知识图谱领域最为流行的知识存储工具Neo4J 图数据库。在专业领域的知识背景下,实体之间的关系比较单一,例如火力发电领域的设备“引风机”关于该设备的关系大致为“…达到…”、“…采用…”、“…为…”、“…是…”、“…符合…”、“…有…”等。如图2 展示了实体“引风机”的一部分网络关系图。经查询统计,本图谱共有46784 个节点,节点之间关系总数为90289个。
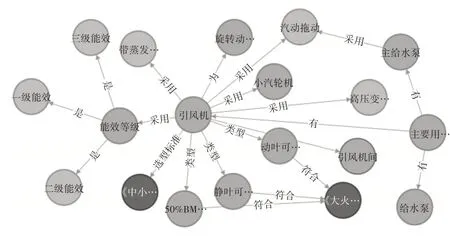
图2 实体“引风机”部分关系图
如图2 显示了节点的局部可视化知识图谱,图3 展示了实体的全部关系,可以看出实体与实体之间的关系比较复杂,两个不同的实体通过多级关系可以联系到一起,所以我们可以通过知识图谱挖掘实体之间复杂关系之后的知识。

图3 10000节点中具有多级关系的可视化图谱
4 基于知识图谱的段落生成系统
本文实现了基于知识图谱的段落生成系统,可以根据输入文本进行智能化生成,主要分为输入句子、实体识别、属性关系映射、知识图谱抽取、文本生成五个部分,本系统流程图如图4所示。

图4 系统流程图
4.1 基于BERT的命名实体识别
BiLSTM 模型[17]在许多自然语言处理任务中得到了广泛的应用,并实现了优异的性能。它代表了LSTM[18]的重大改进,有效地解决了简单RNN 中的梯度消失或爆炸问题。BiLSTM 层双向LSTM 层组成,即前向LSTM 层和向后LSTM 层,因此该模型能够更加精确地捕获序列的上下文信息。基本的LSTM单元由三个门(遗忘门,输入门,输出门)和一个记忆单元(cell),之间的横向箭头被称为cell state(单元状态),它就像一个传送带,可以控制信息传递给下一时刻,它保存了每个神经元的状态。通过门控机制控制信息传递的路径。给出了各LSTM单元的状态计算公式:
式中,it、ft、ot分别表示输入门、遗忘门、输出门,ct表示细胞状态,ht-1表示ht时刻的隐藏层特征,ht是隐藏状态,σ是sigmoid激活函数,⊙代表向量乘积。
传统的词向量模型有Word2Vec或者Glove等,可以将中文字符或者词转化成计算机可以计算的向量,但这些传统的向量模型本质上是利用一个浅层的神经网络模型把低维的向量映射到n 维的向量空间中。Google 在2018 年10 月底公布了预训练模型BERT 基于双向Transformer 编码器[19],刷新了11 项NLP 任务的记录。自此BERT 模型得到了广泛的关注,例如俞敬松等[20]利用BERT 模型进行古文的断句的研究,这里我们使用BERT 模型来代替之前的word2vec 来生成词向量。我们可以使用BERT 来生成词向量,BERT 相对于其他的词向量产生工具,可以解决一词多义问题,因为BERT 参考了大量的上下文信息。BERT 预训练模型如图5所示。
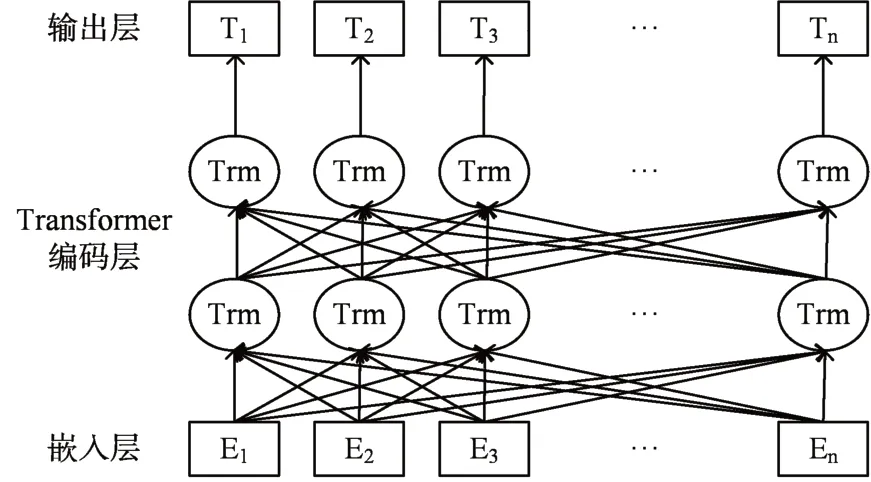
图5 BERT预训练模型
BiLSTM-CRF 模型是由word embedding 层、双向网络层和CRF 层构成。本文的数据采用BIO 标注形式,BIO 的每个字母表示:B-begin,I-inside,O-outside。实体的第一个字标注为B,之后的文字标注为I,其余实体之外的无关文字标注为O。
如图6 所示,我们先基于BERT 模型预训练文本字向量,然后将向量输入到双向LSTM 层来学习上下文特征,输出层可以使用softmax 来预测各个标签的概率,但是softmax 层的输出是相互独立的,不具备上下文关系,这就会发生B-EQU 后再接一个B-EQU 的问题出现,所以我们输出层接一个具有转移特征的条件随机场CRF模型,使得各个输出具有逻辑性顺序性,最终得到序列标签,完成命名实体识别任务。

图6 BERT+BiLSTM+CRF框架
4.2 状态词识别
状态词是指两个实体之间是否有支配关系,它是关系词和否定词的集合,否定词在两个实体之间的时候它也表示一种关系,但是在单个实体前后出现则是一种否定词。例如“引风机达到一级能效”中的状态词就是“达到”,说明实体2 之于实体1 是“达到”的关系;“磨煤机未达到一级能效”中的状态词就是“未达到”,说明实体2 之于实体1 是“未达到”的否定关系;目前关于否定词触发识别基于词表和基于双向长短期记忆网络的,首先对于输入的一个短句子,我们直接利用BERT+BiLSTM+CRF框架对本句子进行命名实体识别,识别出该句子中设备名和专有名词,并按照先后出现的顺序进行排序。首先我们提取出构建好的知识图谱中的所有关系R 构成关系词表Rword,利用抽取出的关系R 在词表中进行比对,得出确定的关系类型,若词表中未出现输入语句中的关系词,将利用BERT 产生的词向量来进行文本相似度计算,将与词表中最相似度最高的关系词作为该词的替换词。
4.3 知识查询与文本选择生成
依据识别出输入句子的关键词和状态词,根据neo4j 的Cypher 语句进行模糊匹配查询,例如查询实体“引风机”可用的Cypher 语句为MATCH(n:node)where n.name=~”引风机.*”return n;模糊查询关系“采用”可用的Cypher语句为MATCH p=()-[r]->()WHERE r[k]=[‘采用’]RETURN p;查询某特定实体的关系可采用语句:MATCH p=(n:node)-[r]->()WHERE r[k]=[‘采用’]RETURN p;利用知识图谱多级深度查询,查询与之所有的关系组合,根据返回的结果依据相应规则来生成一组相关的句子,随后我们利用文本相似度匹配来选择相似度最高的句子。
TF-IDF 算法是一种评估文本中一个词或短语重要程度的统计方法,具体公式如下:
其中,用tk来表示当前研究的特征项,nkj表示研究项tk在文档dj中的出现次数,∑inij表示文档dj中所有词语的出现次数之和,nk表示包含tk的文档总数,N表示文档总数。利用TF值和IDF值相结合就可以得到了TF-IDF 算法的计算公式,如式(11)所示。
所以当TF-IDF 值比较高时,说明该实体在文本中占有重要地位也就是该文本的关键词,具有较高的提取价值。最后根据NER 识别的实体以及关系名称分别计算在句中的TF-IDF值以及输入句子与查询句子的余弦相似度cosine 值求和来选取最优的句子并进行生成。
5 实验结果与分析
命名实体识别(NER)任务要求确定实体的边界以及实体的类别,故本文命名实体识别我们采用通用的标准评价指标,基于实验数据的TP、FP 和FN,计算出NER任务的P(准确率)、R(召回率)、F1值进行评价,具体评价公式如下:
上述公式中,TP 表示Test 测试集中被模型正确识别的实体数量,NP 表示在测试集中被错误识别的实体数量,FN 表示通过模型没有识别出的实体数量。为了验证本模型的有效性,针对本数据集采用HMM,CRF,BiLSTM,BiLSTM-CRF 模型进行对比实验,基于HMM 隐马尔可夫的命名实体识别模型在效果上要差于神经网络模型,基于CRF条件随机场的模型考虑了全局的标签信息,准确率大于HMM 模型,Bi-LSTM 模型和CRF 模型在准确率上相差1.35%,但均小于基于Bi-LSTM-CRF 模型,说明CRF 能够提高Bi-LSTM 的性能。本实验基于Bi-LSTM-CRF的基础上加上BERT预训练模型,在准确率上高于单独Bi-LSTM-CRF 模型0.86%,召回率提升1.89%,F1 值提升1.08%,验证了本模型的有效性。针对火力发电领域实体BERT-BiLSTM-CRF 模型在设备实体(B-EQU)、法律规章(B-LAW)、其他专业名词(B-OTHER)上达到了precision:97.39%;recall:98.07%;FB1:97.73%。具体实验数据如表4、表5所示。
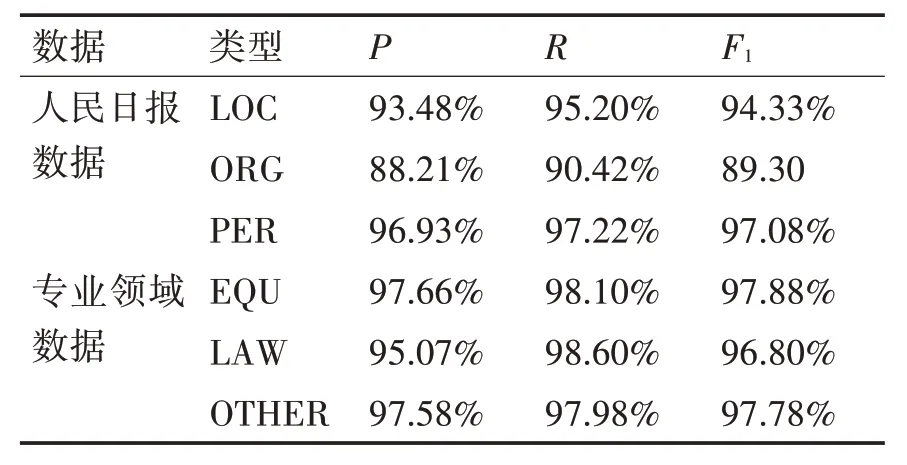
表4 BERT-BiLSTM-CRF模型测试结果
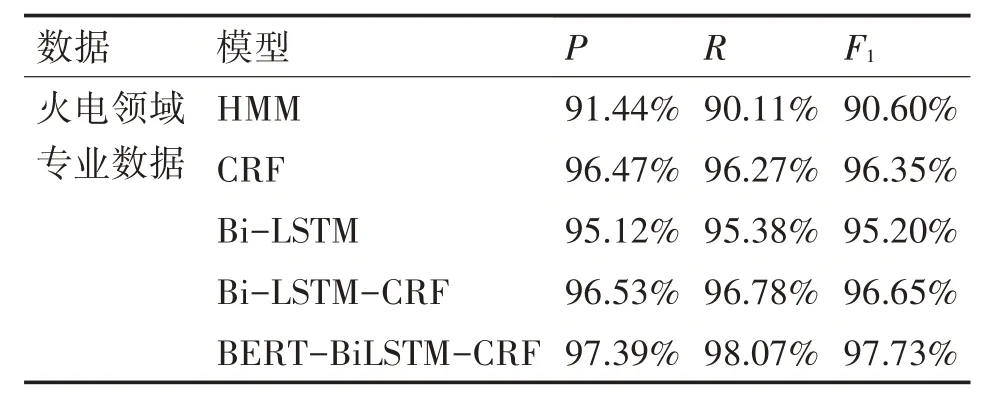
表5 各模型测试结果
自然语言生成是很复杂的,对于自然语言的生成至今没有一个统一标准的评价方式。因此对于本系统,我们通过邀请火力发电领域的专业人员总结出100 句领域相关的短句对结果的生成进行评测。通过对短句的测试,若能够输出包含短句中相应的实体的解释信息或者相关语句即可认为本次生成结果是正确的,若是生成的结果未包含正确的实体,且未能跟输入的句子的相关信息相吻合,则认为本次输出结果是错误的。由表6 系统对比实验可以看出,当输入相同的时候本生成系统的输出更为精准通顺,相比未采用知识图谱和命名实体识别的原系统的输出,原系统输出不可控,且表达语义不够完整,会出现一句话输出不完整的情况。表6显示了部分输入输出结果。

表6 系统对比实验
对本次测试的100 句短句有81 句可以正确生成相关语句,剩余句子生成无关语句主要问题在于对于输入实体的错误识别或者图谱中没有涉及到该实体的任何信息,之后的工作应该着重研究如何能够动态构建图谱,以及提高NER识别的精确度。
6 结语
本文针对火力发电领域的发电以及节能等方面的知识,从火力发电节能报告、建设电厂可行性研究报告、《中国电力百科全书(火力发电卷)》和CNKI 的相关论文中选取语料,依据火电特定领域的特点,完成分词、词性标注、实体识别并从中抽取事件三元组构建特定领域知识图谱。根据构建的领域知识图谱,可以对输入的语句根据专业知识进行知识推理和知识表示,利用BERT 预训练模型,能够生成一定量的专业描述。但由于采集的领域信息数量有限,构建的图谱实体以及属性关系等信息太少,使得生成的文本质量不高,下一步要继续对图谱进行扩充,丰富实体数量,扩大可生成文本的范围。
猜你喜欢
少先队活动(2020年12期)2021-01-14
中国外汇(2019年18期)2019-11-25
人民周刊(2017年11期)2017-08-02
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
领导科学论坛(2016年9期)2016-06-05
工业设计(2016年4期)2016-05-04
通信电源技术(2016年1期)2016-04-16
