
基于EnKF和PF的沙壕渠灌域土壤含盐量监测模型研究
2023-06-20 04:41张智韬贾江栋殷皓原姚一飞黄小鱼
农业机械学报 2023年6期
张智韬 陈 策 贾江栋 殷皓原 姚一飞 黄小鱼
(1.西北农林科技大学水利与建筑工程学院, 陕西杨凌 712100;2.西北农林科技大学旱区农业水土工程教育部重点实验室, 陕西杨凌 712100)
0 引言
土壤盐渍化已成为世界性问题,受到广泛关注。其严重影响农作物的生产,威胁人类的生存[1-2]。因此,及时大范围地准确监测土壤含盐量从而间接控制土壤盐渍化的方法成为当下的热点之一。
监测土壤含盐量的方法主要有地面观测、数学模型模拟和卫星遥感反演,但在实际运用中,这3种方法各有不足。地面观测方法是建立在实地单点采样的基础上,其虽精度高,但成本大,且难以在大范围的时空尺度上获取数据[3]。使用数学模型,例如Hydrus-1D模型模拟长时间大范围的土壤含盐量,模型中的误差会随着时间的增加而不断累积,导致精度降低,需花费大量的时间成本和人力成本,才可能获得具有良好精度的结果[4]。而卫星遥感虽可以通过使用大尺度遥感影像提取相关光谱信息,有效减少地面观测和数学模型模拟的试验时间,但其受限于云、雾等自然条件和卫星传感器的类型,很难获取短时间间隔的遥感图像,不利于长时间高精度的监测研究[5]。因此,本研究为达到在时间和空间尺度下准确监测区域尺度土壤含盐量的目的,使用数据同化的手段来耦合数学模型模拟和卫星遥感反演两种方法优点,并辅以地面观测数据作为验证。
目前,在不同领域,已有学者针对数据同化进行大量研究。例如在土壤湿度方面,CROW等[6]将遥感数据同化到水文模型中,提高了模型模拟精度;HAN等[7]发现数据同化有助于提升SWAT模型在水文模拟方面的潜力;陈鹤等[3]进一步将同化算法集成到水文模型中,有效减少了水文模型的误差;何涯舟等[8]利用土壤湿度同化提升了径流模拟精度。在作物产量方面,PAUWELS等[9]同化植被和土壤湿度状态的观测值,改善了WOFOST模型效果;CURNEL等[10]使用基于重新校准的同化方法在全球范围内显著提高了谷物产量的估计精度;程志强等[11]使用集合卡尔曼滤波同化WOFOST模型和无人机遥感数据,大幅提高了生物量估算精度;刘正春等[12]采用4DVAR和EnKF两种算法有效提高了冬小麦区域估产精度;王鹏新等[13]采用粒子滤波算法同化LAI和VTCI两种参数,提高了夏季玉米产量估计精度。
目前来看,与农业相关的数据同化研究多集中在EnKF(Ensemble Kalman filtering)算法方面[3,6-12],另一种非线性算法——粒子滤波(Particle filter,PF)研究较少[13-14],且很少有学者研究数据同化监测土壤含盐量领域[5,15]。因此,为了更好地监测土壤含盐量,本文引入与EnKF不同的误差处理方法PF进行对比[16-17],探讨不同数据同化方法对监测土壤含盐量精度的优化程度,从而确定最佳的土壤含盐量监测方案。
1 材料与方法
1.1 研究区概况
研究区域位于内蒙古自治区河套灌区沙壕渠灌域(40°52′~41°00′N,107°05′~107°10′E),位于河套灌区西北处。南窄北宽,多为平原地形,地势南高北低,海拔为1 034~1 037 m。灌域所处区域气候为温带大陆性气候,冬季寒冷少雪,夏季炎热干旱,全年平均降水量为140 mm,蒸发量却为2 000 mm,当地灌溉用水多取于黄河。长年缺乏降水加上当地不合适的灌溉制度,导致灌域土壤盐渍化情况较为严重[18-19]。
1.2 数据来源
1.2.1土壤样本数据
选取142个采样点进行土壤采样,具体位置见图1。采样时间为2018年4—9月。采样方法为五点法,用手持GPS进行定位,用铝盒将样本带回实验室进行处理。采用干燥法测定土壤含水率。样本经过干燥后,进行研磨,配成土水质量比1∶5的溶液,静置后待其沉淀,使用电导率仪(DDS-307A型,上海佑科仪器公司)测量溶液电导率(EC1∶5)。运用经验公式[20]计算土壤含盐量(Soil salinity content,SSC,单位g/(100g),后文使用%代替)。含盐量计算公式为

图1 研究区概况及采样点分布Fig.1 Overview of study area and distribution of sampling points
SSC=0.288 2EC1∶5+0.018 3
(1)
1.2.2高分一号卫星遥感数据
采用的高分一号卫星WFV数据从中国资源卫星应用中心(http:∥www.cresda.com/CN/)下载。遥感图像分辨率为16 m×16 m,具有蓝、绿、红、近红外4个波段。依据图像少云,且拍摄时间尽量接近实地采样的原则,选取6幅图像,具体日期为:2018年4月14日、2018年5月17日、2018年6月27日、2018年7月27日、2018年8月8日和2018年9月21日。运用ENVI 5.3.1软件,通过几何精校正、辐射定标、大气校正等步骤进行图像预处理,获取采样点反射率。
1.2.3其他数据
所需的气象数据(包括降水量、蒸发量等)以及地下水位数据均由河套灌区沙壕渠试验站提供。
1.3 土壤含盐量遥感反演
共采用6个月数据,且每月共有3个深度,故一共有18组含盐量数据需要建模。以4月深度0~20 cm为例,将该组数据按照SSC从大到小进行排列,以3个数据为1个单元来将该组SSC划分为47个单元,且每个单元前2个数据作为建模集,后1个数据作为验证集,使得建模集与验证集比例为2∶1。划分之后,选取较为常用的14种盐分光谱指数、14种植被光谱指数和卫星自带的4个波段作为自变量,建模集的土壤含盐量数据作为因变量,使用基于偏最小二乘的变量投影重要性(Partial least squares-variable importance for the projection,PLS-VIP)准则进行自变量筛选。当18组SSC数据中的自变量都被筛选出来后,使用ELM模型进行建模,获取SSC反演值。
1.3.1变量筛选
(1)光谱指数
选取表1中指数和波段作为备选自变量之一,共同构建遥感反演土壤含盐量模型。

表1 光谱指数与计算公式Tab.1 Spectral indices and calculation formulae
(2)指数筛选方法
一共选取32个自变量。为确定不同变量的重要性,并解决变量之间共线性问题,以及减少模型计算时间,选取基于偏最小二乘的变量投影重要性准则进行自变量筛选[43]。PLS-VIP准则原理为
(2)
式中p——自变量个数
m——偏最小二乘法从原变量中提取的成分个数
th——第h个成分
R(Y,th)——成分th对因变量Y的解释能力,是二者相关系数的平方

其中,当某个自变量的PLS-VIP值大于1时,表示此自变量对于解释因变量Y有着重要作用;小于1时,重要作用较小[44]。
1.3.2遥感反演模型
使用极限学习机(Extreme learning machine,ELM)模型作为遥感反演模型。ELM模型是由HUANG等[45]提出的一类性能优良的适用于广义单隐藏层前馈网络。传统神经网络训练模型会因为不适当的学习步长导致其需要花费大量计算资源进行迭代,最终才能获得较好的精度;但ELM模型可以通过一步计算得到网络输出的权值,大大减少了计算时间,并提高了网络泛化速度和学习效率[46-47]。
使用Matlab R2020a软件调整ELM模型参数。其中,通过敏感性分析选出最优隐藏神经元数量(Number of hidden neurons)需小于建模集的样本数;传递函数(Transfer function)选择Hardlim函数。
1.4 土壤含盐量数据同化反演
1.4.1Hydrus-1D模型
使用土壤水盐运移过程模型(Hydrus-1D)[48]作为数据同化中的模型算子,模拟土壤含盐量。该模型由美国农业部国家盐土实验室开发,可以求解变饱和水流的Richards方程和热、溶质输运的平流-弥散型方程。本文使用模型中的水分运移和溶质运移两个模块[13,49]。
模型所需的输入数据包括气象数据、地下水数据、相关参数和初始条件等。气象数据和地下水埋深数据由沙壕渠试验站提供。相关参数中包括溶质运移参数和土壤水力特性曲线参数等,使用参数反演优化法来确定。通过设定样本土壤实测参数作为初始值,分析这些参数对模型模拟结果的影响,确定Hydrus-1D模型敏感参数,与模型自带的标准参数结合,提高模型模拟结果与实测土壤含盐量之间的吻合程度,确定适用于研究区域不同地点的模型参数。
1.4.2集合卡尔曼滤波同化算法
EnKF属于顺序同化算法,同样基于Monte Carlo算法。EnKF分为预测和更新两个模块[50-51]。预测模块为
(3)
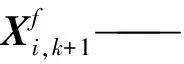
Mk,k+1——k时刻到k+1时刻的状态变化关系
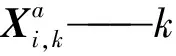
wi,k——模型误差
当k+1时刻有观测值时,需要对每个集合的状态进行更新,计算增益矩阵,更新同化参量计算误差,计算公式分别为
(4)
(5)
式中Kk+1——增益矩阵
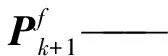
H——单位矩阵
Rk——观测误差扰动的误差协方差矩阵
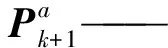
N——集合数
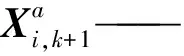
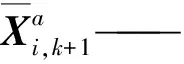
1.4.3粒子滤波同化算法
PF是一种基于蒙特卡洛(Monte Carlo)模拟的贝叶斯(Bayes)滤波算法[52-53]。PF步骤为:
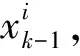
(6)
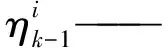
(7)

(2)更新权值。PF依靠模型随时间演进得到的观测预测和实际观测,计算每个粒子的重要性权重,并以此估算和更新状态粒子,公式为
(8)
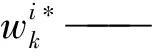
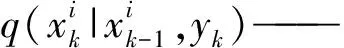
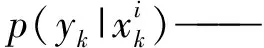
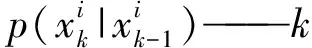
更新后计算权值归一化使权值总和为1,公式为
(9)
式中Nk——k时刻的粒子总数
(3)重采样阶段。此阶段为解决粒子退化问题,提高估计性能。采用多项式重采样,其基本解决了粒子滤波的粒子退化问题。
1.5 试验方案
基于土壤含盐量的数据同化方案的3部分包括观测算子、模型算子和同化算法。其中,观测算子为多时相的ELM土壤含盐量反演模型,模型算子为Hydrus-1D模型,用于模拟土壤盐分运移,同化算法则为EnKF算法和PF算法,作为耦合观测算子和模型算子的媒介,获取长时间序列的区域尺度土壤含盐量的时空特性变化信息。技术路线见图2。采用ELM模型和Hydrus-1D模型分别得到k时刻的3个深度土壤含盐量后,使用EnKF同化算法和PF同化算法进行同化,得到k时刻土壤含盐量同化值。当该时刻存在实测土壤含盐量时,则将3个深度土壤含盐量同化值作为Hydrus-1D模型运行的初始条件,进行模拟,得到k+1时刻的模型模拟土壤含盐量。重复上面步骤,继续与ELM模型反演土壤含盐量进行同化。若同化结束后没有下一时刻实测土壤含盐量,则同化结束,进行评价。
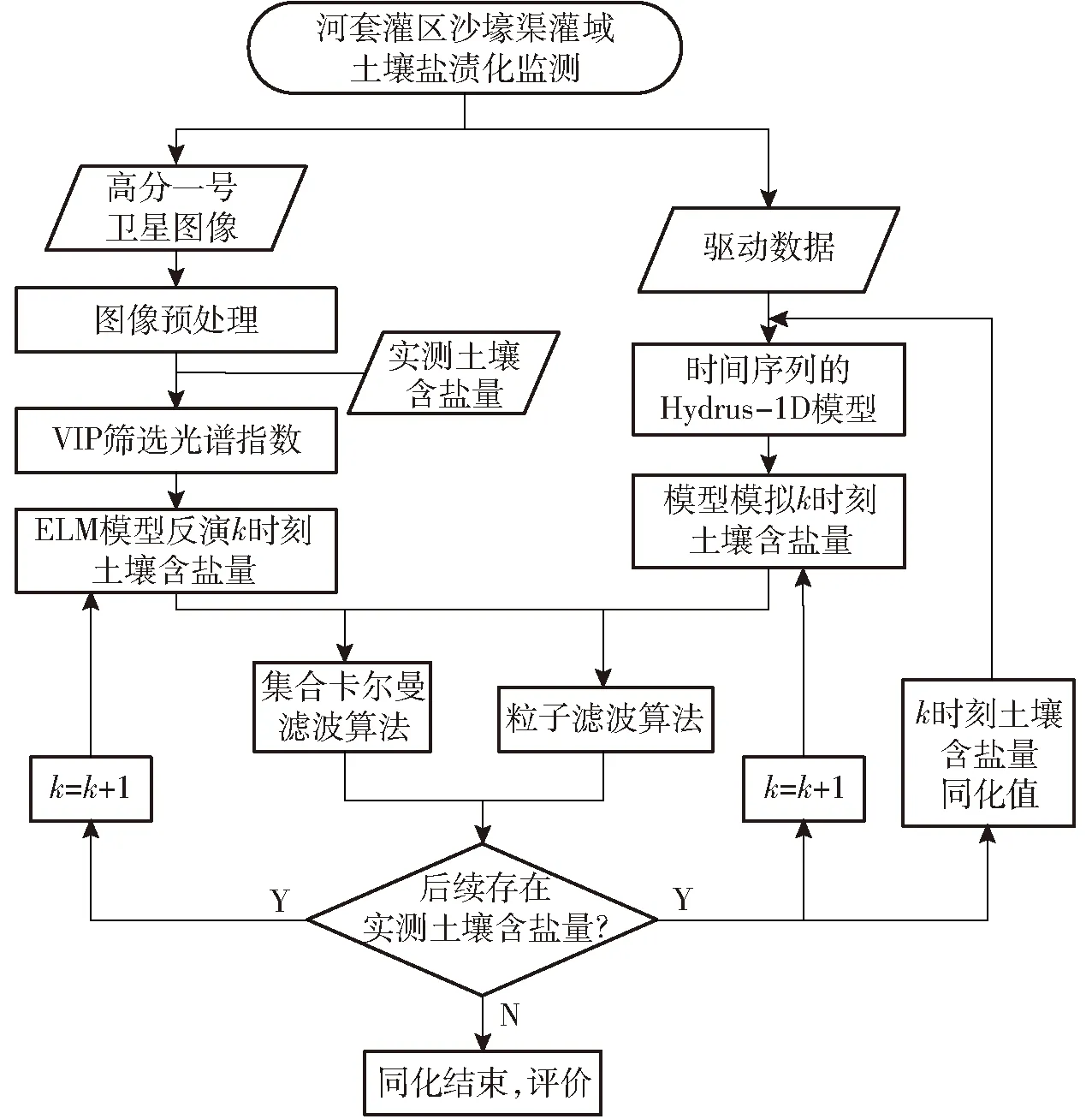
图2 技术路线图Fig.2 Technology roadmap
1.6 评价指标
本文采用一致性系数(Index of agreement,IOA)和平均误差(Mean error,ME)对模型和数据同化过程中的误差进行评价。其中,IOA越接近1,精度越高;ME越接近于0,误差越小。为了更好地衡量不同方法之间的差异,增加归一化平均偏差(Normalized mean bias,NMB)进行评价,NMB越接近于0,误差越小。
2 结果与分析
2.1 遥感反演结果与分析
2.1.1变量筛选
本研究采用基于VIP准则的筛选方法,用于确定包括4个遥感波段、14种盐分光谱指数和14种植被光谱指数在内的变量对于不同深度实测含盐量的重要性。本研究将VIP值大于1的变量视为对土壤实测含盐量重要的变量,并作为遥感反演模型的自变量,结果如图3所示。

图3 PLS-VIP计算结果Fig.3 PLS-VIP calculation results
由图3可知,在研究时段内每月选取3个深度进行18次筛选。其中,由于土壤取样深度以及生育期内自然环境和人工作业等因素共同作用下,18个模型的自变量并不一致。试验选取的32个变量在不同的筛选试验后均有所出现,证明试验选取的变量在不同时间和不同深度中对土壤含盐量都有显著重要性。从各个变量来看,变量S6通过筛选次数最多,为15次;变量b3、SI-T、EVI2、DVI、MSAVI、RDVI 6个变量通过筛选次数最低,仅有3次。这表示变量S6在4—9月的0~60 cm 3个深度中,对反演土壤含盐量起着极其重要且普遍性的作用;而变量b3等6个变量只在特定时间特定深度对含盐量有重要作用,但不具有普遍性。
从各个月份来看,5月所筛选出的变量个数最多,按0~20 cm、20~40 cm、40~60 cm分别为21、20、20个;6月最少,分别为6、5、5个。原因在于,5月处于灌域农作物生育期初期,在复杂的环境因子作用下,需要更多的光谱变量用于构建反演模型,从而更为准确地反演土壤含盐量。而6月已处于植被生长旺盛期,环境因子较为简单。5月和6月的光谱指数的VIP值亦能反映其中原因。在6月3个深度中,光谱指数BI的VIP值均大于2,可以很好地反映土壤含盐量的空间分布;而在5月3个深度中通过筛选的光谱指数,最大VIP值为1.280~1.332,远小于6月,因此需要引入较多的光谱变量用于监测土壤含盐量,提高反演精度。其余月份中,7、8月因植被生长茂盛且农作物种类增多,引入光谱变量个数较少,但多于6月。4月与9月的光谱变量数目差别不大,原因在于这2个月处于裸土期和农作物生长末期,环境因子基本相似,但较植被生长旺盛期复杂,因此略多于6—8月。
2.1.2遥感反演
选取通过VIP准则筛选的光谱变量作为自变量,4—9月0~60 cm 3个深度实测土壤含盐量作为因变量,构建基于ELM模型的不同月份不同深度的土壤含盐量反演模型,模型建模结果如图4所示。
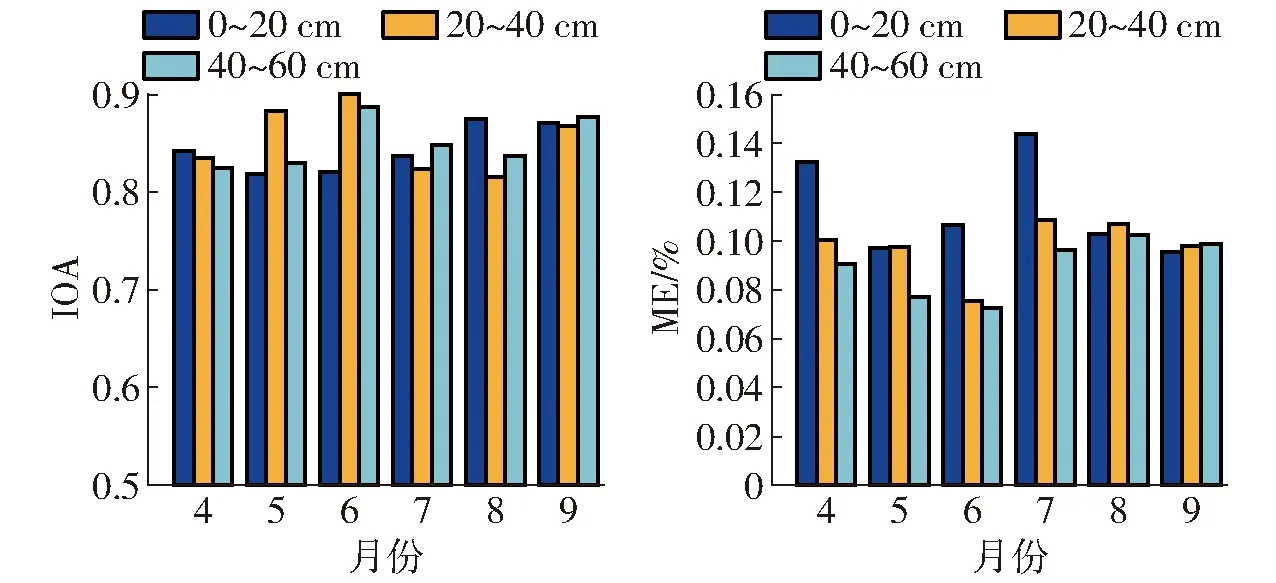
图4 ELM模型建模集评价结果Fig.4 ELM modeling set evaluation results
从图4可知,18个反演模型中,建模集IOA(IOAC)均大于0.8;建模集ME(MEC)均小于0.15%。这表明ELM模型在反演土壤含盐量中具有较好的监测精度。其中,IOAC精度最高的前3个模型分别是6月深度20~40 cm、6月深度40~60 cm和 5月深度20~40 cm,分别为0.901、0.887和0.883;MEC前3个模型分别是6月深度40~60 cm、6月深度20~40 cm和5月深度40~60 cm,分别为0.073%、0.076%和0.077%。同理,IOAC精度最低的后3个模型分别为8月深度20~40 cm、5月深度0~20 cm和深度0~20 cm,为0.815、0.819和0.820;MEC后3个模型分别为7月深度0~20 cm、4月深度0~20 cm和7月深度20~40 cm,为0.144%、0.133%和0.109%。
从深度方面看,深度0~20 cm中,平均IOAC为0.844,深度20~40 cm为0.854,深度40~60 cm为0.851。3个深度的平均MEC分别为0.113%、0.098%和0.090%。可以看出,模型精度随着深度的递增而递增。从时间方面看,4—9月平均IOAC分别为0.834、0.844、0.869、0.836、0.842和0.872,平均MEC分别为0.108%、0.091%、0.085%、0.116%、0.104%和0.097%。衡量以上信息,ELM模型中6月建模精度最高,7月最低。原因在于6月研究区经济作物品种单一,7月相对来说作物品种进一步增加。且7月深度0~20 cm的MEC最高则是因为此时处于农作物茂盛生长期,遥感图像所获取的信息多是植被表层反射波段,表层土壤信息被遮盖,模型因此无法较为精确反映地面实测信息。
ELM模型验证集精度见表2。
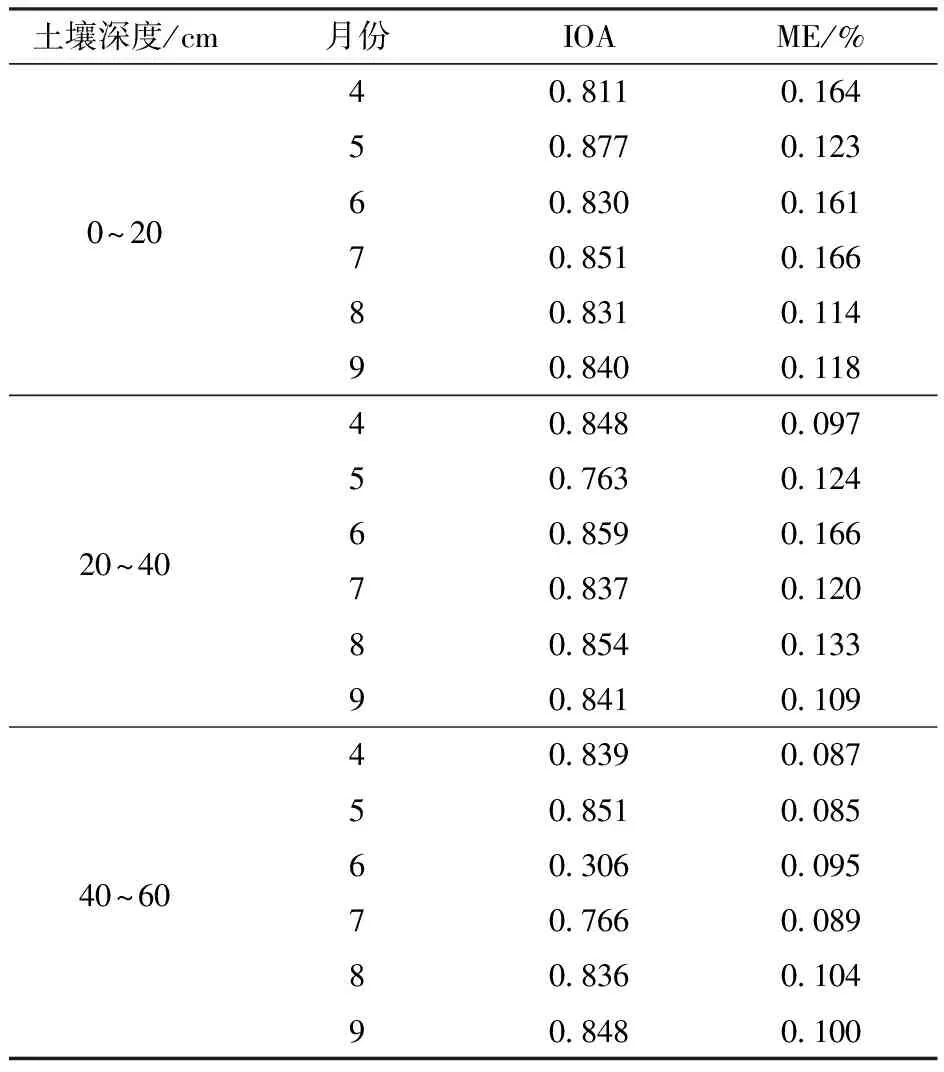
表2 ELM模型验证集评价结果Tab.2 ELM model validation set evaluation results
从表2可以得出,综合两个评价指标,ELM模型均能较好地验证模型精度。验证集IOA(IOAV)精度最高的前3个模型分别为5月深度0~20 cm、6月深度20~40 cm和8月深度20~40 cm,分别为0.877、0.859和0.854;精度最低3个为6月深度40~60 cm、5月深度20~40 cm和7月深度40~60 cm,为0.306、0.763和0.766。验证集ME(MEV)精度最高为5月深度40~60 cm、4月深度40~60 cm和 7月深度40~60 cm,分别为0.085%、0.087%和0.089%;精度最低3个为7月深度0~20 cm、6月深度20~40 cm和4月深度0~20 cm,分别为0.166%、0.166%和0.164%。
各深度平均IOAV分别为0.840、0.834和0.741,MEV分别为0.141%、0.125%和0.093%。可以看出,在前两层深度中两种评价指标差别不大,但在40~60 cm处IOAV有较为明显的下降,主要原因在于6月深度40~60 cm处的低精度。然而与其他模型相比,该深度的MEV无明显的精度降低趋势,推测原因在于研究区所种植的农作物根系所处深度主要位于20~40 cm,遥感提取的地表反射率较难反映深层土壤含盐量。
4—9月平均IOAV分别为0.833、0.830、0.665、0.818、0.840和0.843,平均MEV分别为0.116%、0.111%、0.141%、0.125%、0.117%和0.109%。与建模集相比,精度略有下降,但依然能较好反映实测土壤含盐量。
综上所述,在3个深度中,ELM模型能够较好地反演灌区多时相土壤含盐量。其中,6月深度20~40 cm模型精度最高,原因在于其在建模集中的两个评价指标均排在前3,并且其IOAV同样排在前3;7月深度0~20 cm模型精度最高,原因在于其MEC和MEV均处于后1/3。
2.2 模型模拟结果
基于Hydrus-1D模型进行4—9月不同深度土壤含盐量模拟,使用4月14日地面实测值作为模型初始模拟值,确定剩余遥感反演时间点各天的模拟土壤含盐量,以计算评价指标IOA和ME,结果如表3所示。从表3可以看出,就整体精度而言,模型模拟精度较好,可以较好反映长时间上的土壤含盐量变化情况。

表3 Hydrus-1D模型模拟精度评价Tab.3 Hydrus-1D model simulation accuracy evaluation
从不同土壤深度来看,3个深度各平均IOA分别为0.891、0.876和0.793,各平均ME分别为0.137%、0.131%和0.128%。表明Hydrus-1D模型在深度0~20 cm中模拟精度最高,20~40 cm次之,40~60 cm最差。从时间角度看,5—9月各月平均IOA分别为0.918、0.865、0.805、0.824和0.855,平均ME分别为0.117%、0.139%、0.155%、0.127%和0.122%。综合评价指标,Hydrus-1D模型模拟精度随着时间增加,表现为先减后增,但9月的Hydrus-1D模型模拟精度均较5月有所下降。其主要原因在于模型运行过程会导致误差不断积累,从而致使模型模拟精度下降。
IOA在深度0~20 cm中随着时间的递增先下降后上升,在深度20~40 cm和40~60 cm中总体均随时间递增呈下降趋势。ME在0~20 cm深度中,6月的模型模拟精度有下降,但在后续月份中精度有所提升;深度20~40 cm中,模型模拟精度在随时间的推移而下降;深度40~60 cm中,模型随时间递增精度先降后升。
2.3 同化算法结果
基于2018年4—9月的实际土壤样本测定的土壤含盐量,开展不同时空的区域尺度土壤含盐量数据同化研究。分别通过引入EnKF和PF两种同化算法,将观测算子(即ELM模型反演结果)和模拟算子(即Hydrus-1D模型模拟结果)进行耦合,建立数据同化方案,获取基于不同数据同化算法的长时间区域土壤含盐量的时空变化情况。使用IOA、ME和NMB对同化方案分别进行精度评价,结果如图5所示。

图5 综合评价结果Fig.5 Comprehensive evaluation results
从图5可以看出,4种方法都能较好地监测时间尺度下的土壤含盐量,IOA大多在0.8~0.9范围浮动;ME基本小于0.15%;NMB除EnKF算法和ELM模型的40~60 cm外,均小于0.2。综合各个评价指标,PF算法效果最优,Hydrus-1D模型模拟精度次之,EnKF算法精度第3,ELM模型反演精度表现最差。
从同化精度的角度分析,就IOA而言,4种方法的精度随着深度的递增而降低。其中,深度0~20 cm中,EnKF算法精度最高,PF算法较其降低0.89%,Hydrus-1D模型和ELM模型分别降低2.96%和1.26%。深度20~40 cm中,PF算法精度最高,EnKF算法、Hydrus-1D模型和ELM模型分别降低0.75%、2.36%和0.46%。深度40~60 cm中,与深度20~40 cm类似,PF算法精度最高,其余方法精度均有所下降,分别为7.78%、8.82%和26.19%。从基于两种同化算法的模型精度均高于数学模型模拟和遥感模型反演可以看出,同化算法在耦合二者并降低误差方面具有很大优势。
从同化误差的角度分析,就ME而言,PF算法、Hydrus-1D模型和ELM模型的精度随着深度的递增而上升,但EnKF算法精度表现与在IOA中类似,精度随着深度的递增而降低。其中,深度0~20 cm和 20~40 cm中,Hydrus-1D模型模拟精度最高,40~60 cm中,PF算法精度最高。ELM模型反演精度在表层深度最低,其余深度EnKF算法精度最低。NMB中,各种方法在深度20~40 cm精度最高,深度40~60 cm精度最低。
在深度0~20 cm,相较于EnKF同化算法,PF同化算法的IOA和ME分别下降0.9%和0.6%,差距很小,可以忽略不计;NMB中,PF较EnKF提高43.8%。在深度20~40 cm,IOA、ME和NMB中,PF同化算法较EnKF同化算法分别提高0.8%、10.3%和46.8%。在深度40~60 cm,3个评价指标(IOA、ME、NMB)中,PF同化算法较EnKF同化算法分别提高8.4%、42.9%和61.5%。因此,在3个深度上,与EnKF算法相比,PF算法对于提高土壤含盐量的同化精度有着更为显著的优势。
以2018年7月为例,使用PF算法数据同化方案得出的不同深度土壤含盐量如图6所示。
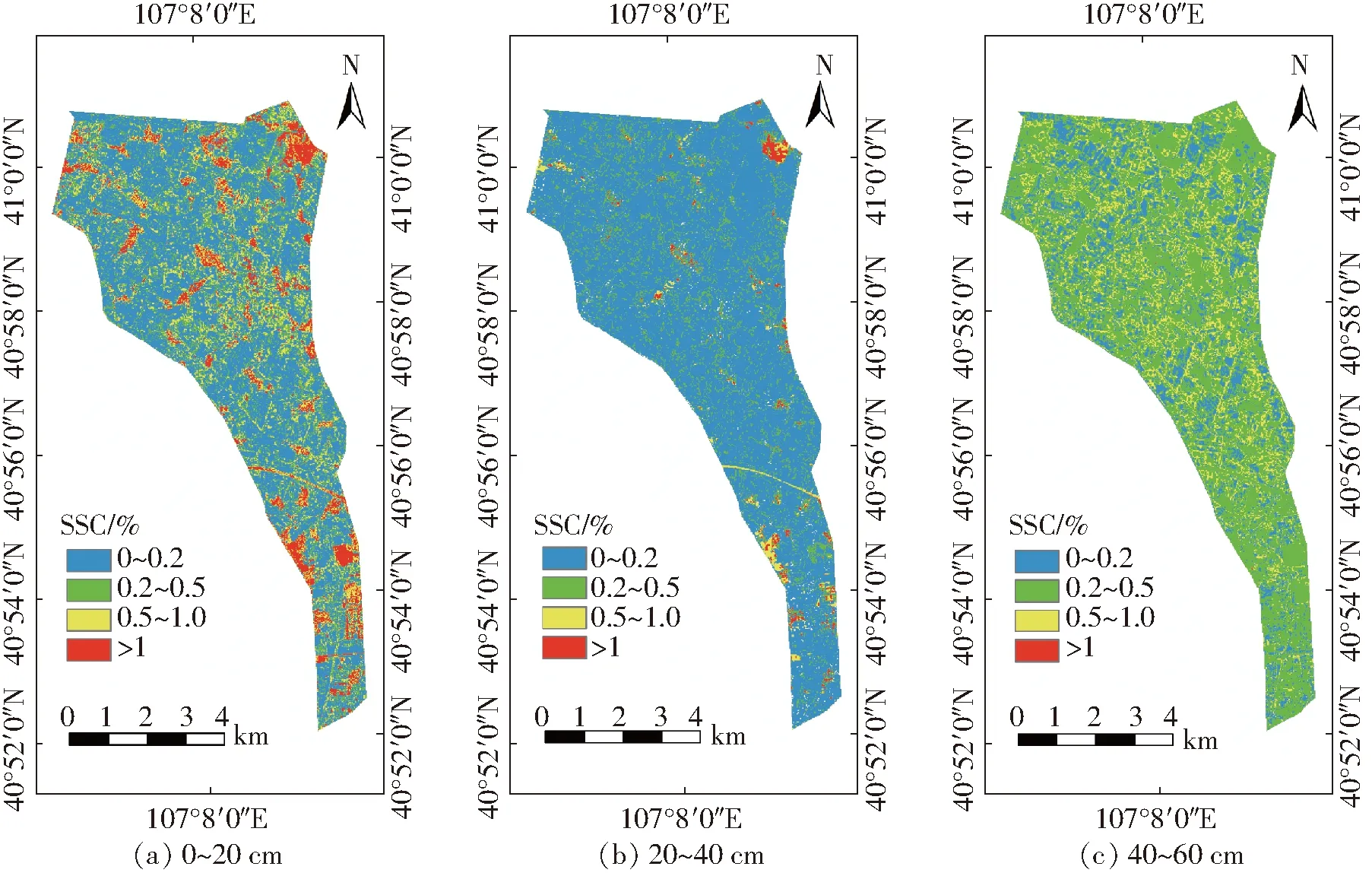
图6 不同深度土壤含盐量同化结果Fig.6 Results of soil salt assimilation at different depths
3 讨论
大范围的土壤含盐量监测受到很多人为因素和自然因素的限制,如地面采样点的位置受地面建筑和灌溉时间的影响,遥感卫星图像受大气云层覆盖面积的影响等。这些不利的影响被称为噪声,而本研究使用两种不同同化算法的目的就是尽可能地减小过程噪声。
本研究使用两种同化算法——EnKF同化算法和PF同化算法来同化观测算子和模型算子。观测算子中,使用PLS-VIP准则筛选不同种类的光谱变量,选取VIP值大于1的变量作为观测算子的自变量,目的在于减少自变量个数并缩减模型计算时间[54]。筛选结果中,由于研究区主要种植的经济作物如葵花、小麦、玉米和蔬菜等生长期各不相同[20],导致遥感光谱图像所获得的反射率差异较为明显,进而影响4—9月3个深度的自变量个数和种类。建立反演模型中,ELM模型采用筛选后的自变量建立了18个不同时间不同深度的遥感反演土壤含盐量模型,能够较好反映土壤含盐量的空间分布特征。相较于以往的线性回归模型,ELM模型能够很好地反映非线性条件下的光谱信息[45],能够更好地提升反演精度。模型算子中,土壤水力特征参数和溶质运移参数等会极大影响模型模拟的精度,为了更好地反映实际情况,本研究使用不同模型参数来模拟土壤含盐量,从而取得较好的精度。
以Hydrus-1D模型为代表的土壤水盐运移模型通常采用微分方程来计算溶质运移过程,但这会导致结构不够稳定,误差会随着时间的增加而不断累积,这从本文的Hydrus-1D模型模拟9月土壤含盐量精度可以看出。数据同化算法通过在观测时间点加入观测模型数据,及时更新土壤水盐运移模型的初始场域数据和参数,将原本的模型初始场域的使用时间缩短到一个观测周期内,有效降低了模型模拟误差的累积[55],提高了精度。
两种同化算法对比来看,综合3个评价指标,PF算法同化精度高于EnKF算法,其同化值更接近地面实测数据,因此PF算法在ELM模型和Hydrus-1D模型的同化系统中表现更好,同化效果更好。这可能是由于PF算法是基于统计和贝叶斯公式发展而来,其同时结合先验和后验概率密度分布来更新粒子状态,能够更好地解决非线性问题[16,53]。而EnKF算法使用蒙特卡洛方程积分控制的概率密度函数来描述先验的假设和误差统计,但针对高度非线性的模型,其在算法迭代中有很大的概率无法收敛,继而影响模型中误差协方差的准确性,最终导致精度降低[50]。但比较二者算法的状态更新步骤,即EnKF算法对每个集合使用卡尔曼增益计算状态变量的更新,而在PF算法中使用重采样的手段[56]进行状态更新,EnKF算法在更新步骤中不需要计算指数密度函数,与PF相比降低了计算成本[57]。此外,EnKF算法中集成滤波器的状态相关不确定性信息和集成构建能力,能够更好利用遥感信息[12]。这说明EnKF算法仍有改进的余地。
本研究只探究了两种单一同化算法对区域土壤含盐量的监测能力,对于复杂的环境存在一定的限制。在后续的研究中,可以构建耦合不同同化算法的同化方案,此外,本研究只使用土壤含盐量作为唯一的状态变量,在后续研究中可以将Hydrus-1D模型参数引入同化方案中,建立基于土壤含盐量和Hydrus-1D模型参数的多状态变量同化方案,进一步提升精度。
4 结论
(1)基于ELM模型的遥感监测土壤含盐量模型中,6月深度20~40 cm模型在所有模型中精度最高,7月深度0~20 cm模型在所有模型中精度最低,3个深度的平均IOA均在0.74以上,平均ME在0.14%以下,建模集和验证集之间精度相差较小。表明反演模型在2018年4—9月各层土壤含盐量监测中具有良好的精度。
(2)基于Hydrus-1D的数学模拟监测土壤含盐量模型中,3个深度平均IOA在0.79~0.89之间,平均ME在0.128%~0.137%之间,精度随深度递增呈下降趋势;5—9月各月平均IOA在0.805~0.918之间,平均ME在0.117%~0.155%之间,模型准确性随时间推移逐渐下降。综合各评价指标,Hydrus-1D模型能够较好地反映土壤含盐量在时间序列中的运移情况。
(3)基于EnKF算法和PF算法的数据同化监测土壤含盐量模型中,EnKF算法3个深度IOA分别为0.924、0.898、0.820,ME分别为0.141%、0.147%、0.157%,NMB分别为0.141、0.142、0.252;PF算法3个深度IOA分别为0.916、0.905、0.889,ME分别为0.142%、0.131%、0.090%,NMB分别为0.080、0.075、0.097。比较二者同化方案,PF算法同化方案在3个深度中精度均高于EnKF算法同化方案。且相较于ELM模型和Hydrus-1D模型,PF算法同化方案也具有明显的优势,因此PF算法能够很好地反映土壤含盐量在时间和空间上的分布情况。
猜你喜欢
中等数学(2022年5期)2022-08-29
甘肃科技纵横(2022年11期)2022-03-21
中国生态农业学报(中英文)(2021年8期)2021-07-28
工业水处理(2020年10期)2020-03-08
电子制作(2018年11期)2018-08-04
石油地球物理勘探(2017年4期)2017-12-18
石油地球物理勘探(2017年2期)2017-11-23
文物保护与考古科学(2016年4期)2016-05-17
测绘科学与工程(2016年5期)2016-04-17
电子设计工程(2015年3期)2015-02-27
