
纯XML语料库语义缓存中辅助翻译工具视图的查找算法研究
2023-06-23 04:37邢浩
青岛大学学报(自然科学版) 2023年1期


摘要:详细介绍了纯XML数据库系统的基础知识,包括XML文档缓存结构、基本定义和XML文档的解析方法等。重点分析了序列化XPath查询算法,在分析纯XML数据库语义缓存中辅助翻译工具视图的快速查找算法的优缺点后,给出了一种基于最长视图的补偿查询改进思路。
关键词:XML数据库;语义缓存;计算机辅助翻译工具;快速查找算法
中图分类号:TP311.13 文献标志码:A
经过几十年发展,数据库系统经历了层次数据库、网状数据库、关系数据库三个阶段的发展,在数据信息查询优化、数据仓库信息管理、数据信息挖掘、移动数据库打造等领域取得了突破性进展,很多研究成果被成功转化到商业应用[1]。实际操作中,XML数据库查询求解过程存在和传统关系查询求解不同的操作问题,具体实施时,依据数据自身半结构化的特点,数据信息查询往往会遇到一些困难[2]。例如,在计算机辅助翻译工具数据查询的过程中,如果使用了缓存物理页的简单缓存结构,虽然在开始运行时能够减少一定的I/O操作,但是无法减少最终相对的计算消耗。语义缓存能够针对以上问题给出解决方法,利用XML语义缓存视图回答新查询问题,实现对数据信息的小范围量化查询和精准判断[3]。为实现XML数据语义缓存,需要对视图组织结构实施优化设计。在客户端缓存查询结果的基础上打造XPath级的语义区[4-5];语义区构造完成之后对一组语义相关的XPath实施最小化量化处理,目的是减少网络通信负担[6];缓存结构框架能够在查询过程中实施缓存处理,在具体实施操作过程中所牵扯到的数据信息包含XML数据片段、数据数值、根点到叶子结点的全路径引用关系[7]。最小化、量化处理视图和查询之后,可以利用缓存回答数据信息处理问题,解决数据匹配视图中的数据信息查询问题。计算机网络技术的快速发展也使XML数据的使用面临更多的机遇和挑战[8]。随着时间的推移,应用领域的不断增长和XML数据库数据的日趋复杂化,各种应用对XML数据库数据的可查询、可定位、可存储的需求持续增加,特别是计算机辅助翻译工具,引发了对XML数据进行合理存储和快速查询的要求[9]。为了更好的发挥XML数据在人们社会生活中的指导作用,需要研究人员采取积极的措施拓宽数据库研究领域[10],强化对数据库资源的开发应用[11]。
1 纯XML数据库语义缓存中视图快速查找算法的基本问题
纯XML数据库系统(Native XML Database System,NXDS)在处理XML数据时,不需要转换,可对数据直接进行操作,减少了系统资源的消耗;其次,在NXDS中保存XML文件时,不仅能保存数据文件,还能保存与数据库数据具体描述有所关联的信息,如数据结构和数据类型信息等;最后,在NXDS中以原生的检索形式,不通过任何文件格式转换就能够检索到XML数据库数据,检索到二叉搜索树中每一层的每个节点。利用这种特性查询数据,为查询优化提供了有利条件[12]。
在计算机辅助翻译工具中,纯XML数据库利用语义缓存回答查询Q,基本步骤包含:1)缓存查找。通过缓存查找来找到缓存中可以用来回答Q的视图V,在查询过程中涉及到的内容有重写、查询同构和查询最小化以及判断关系;2)补偿查询的构造。本文所使用的算法能够提高第一步求解过程速度,在计算机辅助翻译工具的数据库构建过程中能够在第一时间寻找到适合的候选视图,从而提升缓存查询的性能,并为补偿查询的构造做好准备工作[13]。
1.1 基本定义和原则
(1)主路径,除了谓词节点以外,从根节点到结果节点的全部结点组成的一条路径。
(2)主路径长度,指路径上的结点个数,具体可以使用BP表示。
(3)带结果结点的唯一深度在第一时间出现在序列的首要位置,根据查询树中唯一的深度最优顺序标识,查询的构造节点,生成具有结果节点的唯一深度并优先遍历。实践操作中,顺序运算相对于树形运算更方便快捷,在特定的分析中,把XPath的查询模式转换为UDFTS-out。在数据信息的处理中,为了避免由于分支条件的相对位置不同而导致的不同顺序之间的差异限制,在将查询转化为顺序前,对其进行正规化处理。
(4)假设两个查询Qa和Qb的根结点Ra和Rb能够满足同根主路径判断条件,可以将Qb的主路径看作是Qa主路径的同根主路径,判断条件见表1。
(5)主路径子串,对UDFTS-out的两条查询Qa、Qb的主要通道的父节点的数据进行处理,获得Sa和Sb的序列,其中,序列Sa为A1、A2、A3、…、Am,序列Sb为B1、B2、…、Bn。
(6)同根主路径子串,若两个查询的UDFTS-out主路径Sa及Sb符合同一根主路径的串行要求,则Sb为Sa的同根主路径子串。
(7)主路径匹配,若两条主要路径的Sa、Sb能使Sb的绝对值超过Sa的绝对值,则Sb主路径中从根节点至Sa的结果节点为Sa的主路径子序列,则Sa能够和Sb的数值相匹配。
1.2 缓存结构
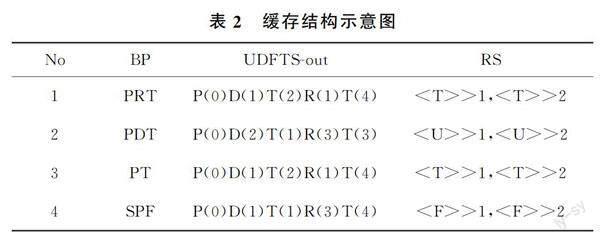
在计算机辅助翻译工具中,针对不同查询语言和查询实际的表示方法,在数据信息汇总分析时存在两种不同的缓存系统组织方式,与之对应的缓存查找算法也不同。本文根据序列的XPath查询,缓存主要结构见表2,在视图的具体分析中,No为存放缓存文件的视图编号,BP为删除父节点的查询主路径,UDFTS-out是视图查询的序列模式,RS是结果节点集合。缓存可以填充数据,选择相应的用户行为分析挖掘数据,挖掘用户频繁查询的信息和数据,进而收集实体信息和數据,保存到缓存系统中。在此过程中,为了加速对缓存文件的搜索速度,设置了索引。索引的基本结构中,Item是一个索引项,具体情况涵盖直系后代轴,不区分大小写。Position是缓存中视图的序号,即缓存系统中的No值。确定缓存和索引结构后,如果有新的查询信息,系统会对这些数据信息实施规范化的指引和UDFTS-out缓存查找,经过一系列的协调分析能够找到匹配新查询主路径的候选视图。
2 纯XML数据库语义缓存中视图的快速查找算法
2.1 U-ViewMatch缓存查找算法
缓存的查找算法由缓存的组织结构决定。XML语义缓存查找的方法由查询模式树实现的,将查询树与缓存中的视图模式树进行比较会消耗大量的时间[14],所以在计算机辅助翻译工具实施操作時,序列化XPath查询的目的是减少搜索算法的时间。结合定理1,搜索过程中要先进行主路径匹配分析,通过找到适合的匹配路径,才能有效排除不匹配的视图。
定理1 在具体的匹配分析中,如果查询Qa主路径和Qb主路径不匹配,则Qa和Qb不匹配。
证明:由主路径匹配、同根主路径子串和查询匹配的定义能够证明定理1。
算法U-ViewMatch是一种缓存查找算法。
输入:CVS:Cached View Set缓存视图集,为指向缓存区的指针;
21-out Q-BP:查询Q的去掉父结点信息的UDFTS-out序列的主路径;
输出:MVS:Matched View Set,能够匹配Q主路径的候选视线图集
Begin
IndexMatch(rootU-out Q-BP)//索引中Item信息。
if(item==null)
return null;
else{MVS=null
S=Index[item] //Position中position的个数
for(i=0,i<s;i++){
curView_BP = Index[itme] // Position[i]的主路径; curView为当前视图
if (BPM (U-out_Q_BP, curView_BP)) //判断Q主路径是否与V主路径匹配
MVS.append(Cache. curView);}
return MVS;}
End
计算机辅助翻译时,在U-ViewMatch方法中,首先检索,以检验新的Q的根结点能否用作缓存中的一个视图的根结点。在运行期间,若发生问题导致查询运算失效,则表示快取中没有相应Q的查询。此时可以利用数据库实现对数据的检索,能够加速计算机从旁协助翻译工具中数据信息的查询和应用,并尽快确认无法匹配查询的情况,完成搜索缓存的所有区域。在分析查询索引的过程中,如果信息搜索成功,则结合查询序号,将查询主路径和当前序号对应的显示主路径一一比较,显示对应的指标项。在for循环完成时,传回MVS视图。这时,MVS中有相应的Q的主路径的视图。此期间,MVS可能被认为是一个空白集合,因为Q的根和若干个执行图表中的根节点不匹配导致了此情况。
定理2 当视图V的主路径长度超出Q的主路径的长度时,V自身无法被用来建立一个可以用来求解Q值的补偿查询。
证明:结合主路径匹配、查询匹配和补偿查询的定义能够证明定理2。
结合定理2,比较视图主路径和查询主要路径的长度,若视图主路径长度大于查询主路径长度,说明视图和查询信息不匹配,此时,需要及时采取措施,尽快停止对主路径匹配查询的操作[15]。
如果查询主路径的长度大于视图主路径的长度,需要将每条视图主路径进行比较,查询它们的结点信息。根据表1中的Y条件,视图主路径的“//”结点可以与查询主路径上除“//”之外的多个连续节点匹配。
2.2 算法的改进
U-ViewMatch算法可以在缓存中搜寻并返回符合查询主路径的所有视图。在计算机操作系统的从旁协助翻译英文实用程序中,无论按照什么条件查询,当两个视图的路径都能与查询主路径匹配时,如果该视图具有更长的查询条件,则结果更接近实际的查询数值,视图建立的一次性补偿查询更具体。具体的操作步骤简单方便,在视图上请求补偿查询也更快。例如查询Q=A[D]/B/C[T],视图V1=A[D]/B/C,视图V2=A[D]/B,参照结合V1的内部结构一次性补偿查询CQ1=//C[T],参照结合V2基本结构一次性补偿查询CQ2=//B/C[T],参照结合V2基本结构一次性补偿查询,CQ1V1内部结构比CQ2更简单。
定理3 补偿查询代价判定,不考虑谓词的情况下,可以通过考虑最长视图来构造的补偿查询求解代价最小。
证明:设视图主路径的长度为m,查询主路径的长度为n,结合上文的具体描述和分析,视图主路径匹配查询。若两者为一次性补偿状态,则一次性补偿查询的主路径为当前查询文件从k个叶子节点Qk开始的子串,实际长度为(n-k+1),m越大,k值越大,反之亦然。从某种角度来说,对于可查询的XPath,查询深度越小,计算成本越小。但是,参考最长时间匹配的基本原则,结合主路径的长度最长原则,所构建的查询最优解成本是最小的。图1显示了查询、视图、补偿查询主路径的长度,参考定理3,对U-ViewMatch算法进行一些必要的改进,在具体实施操作中,可以根据主路径的长度进行排序。
3 结论
本文分析了计算机辅助翻译工具中纯XML数据库系统中的语义缓存视图查找问题。唯一的UDFTS输出序列化过程是在XPath查询上执行的,因此使用算法U-ViewMatch快速查找与要解决的查询主路径匹配的所有缓存视图,作为候选视图集来回答查询,并根据主路径长度进行排序,再根据候选视图集的特点探讨一种补偿查询方法,旨在能够有效提升数据信息的查询效率,减少网络数据传输可能出现的性能问题。
参考文献
[1]孟小峰,慈祥. 大数据管理:概念、技术与挑战[J]. 计算机研究与发展,2013,50(1):146-169.
[2]TAJIMA K, FUKUI Y. Answering Xpath queries over networks by sending minimal views[C]// 30th International Conference on Very Large Data Bases. 2004: 48-59.
[3]许沛华. 基于XML的移动数据库缓存技术研究[D]. 武汉:华中师范大学, 2009.
[4]查达永. 一种基于XML数据库查询结果集缓存方案的设计与实现[D].武汉:华中科技大学,2016.
[5]崔岩,崔婉秋,王大伟.XML查询中相关关键字匹配算法研究[J].信息通信,2016(8):21-23.
[6]CONSENS M P, RIZZOLO F. Fast answering of XPath query workloads on web collections[C]// 5th International XML Database Symposium. Vienna, 2007: 23-24.
[7]BALMIN A, ZCAN F, BEYER K S, et al. A framework for using materialized XPath views in XML Query Processing[C]// 30th VLDB Conference.Toronto, 2004:60-71.
[8]许娴. XML数据库的查询技术研究[J].江苏技术师范学院学报,2013,19(4):7-12.
[9]谷瑜青. XML数据库及其应用研究[J].电脑编程技巧与维护,2015(10):80-81.
[10] CHEN L, RUNDENSTEINER E. ACE-XQ: A CachE-aware XQuery answering system[C]// WebDB. 2002: 31-36.
[11] FENG J H, LI G L, TA N. A Semantic cache framework for secure XML queries[J]. Journal of Computer Science and Technology, 2008, 23(6): 988-997.
[12] 汪濤. 纯XML数据库结构关系查询技术[D]. 贵阳:贵州大学, 2009.
[13] 郎泓钰, 任永功. 基于Redis内存数据库的快速查找算法[J]. 计算机应用与软件, 2016, 33(5): 40-43+52.
[14] 毕玉萍, 胡世昌, 李劲华. 基于排序树的Node-Apriori改进算法[J]. 青岛大学学报(自然科学版), 2020, 33(3): 50-56.
[15] 陈俊林, 张文德. XML文档的数据库转换技术研究[J].现代图书情报技术, 2006(9): 38-42.
Algorithm Research of Auxiliary Translation Tools View in Pure XML Corpus Semantic Cache
XING Hao
(Jincheng College, Nanjing University of Aeronautics and Astronautics, Nanjing 211156, China)
Abstract: The basic knowledge of pure XML database system in detail was introduced, including XML document cache structure, basic definitions and XML document parsing methods. The serialized XPath query algorithm was emphatically analyzed. After analyzed the advantages and disadvantages of fast search algorithm for auxiliary translation tool view in pure XML database semantic cache, an improved idea of compensation query based on the longest view was proposed.
Keywords: XML database; semantic cache; computer aided translation tools; fast search algorithm
收稿日期:2022-08-20
基金项目:2021年江苏省高校“青蓝工程”优秀青年骨干教师培养项目(批准号:2021SJA2246)资助;2021年江苏省高校哲学社会科学一般项目(批编号:2021SJA2246)资助。
通信作者:邢浩,女,副教授,主要研究方向为金融翻译与翻译技术等。E-mail: honna666@foxmail.com
