
基于教育数据挖掘的学生画像构建与学情预测分析研究
2023-06-25 07:35唐茜
现代信息科技 2023年4期
关键词:关联度

摘 要:该研究通过采集学生在校的图书借阅、参加公益活动、上网等行为数据,采用随机森林算法挖掘行为特征与学业成绩之间的关联程度,提取关键特征进行加权计算合并形成新特征,通过基础模型K-means算法进行聚类分析,最终将学生划分成自律学霸型、夜猫子上网型和缺乏规划型三类学生。基于Logistics回归模型建立预测模型,分别讨论三类群学生的学习成绩预测效果,为教育工作者深入诊断学生的学习状态并给予精准的教学引导和干预提供参考。
关键词:教育数据挖掘;行为数据;学生画像;关联度;预测分析
中图分类号:TP311 文献标识码:A 文章编号:2096-4706(2023)04-0193-06
Research on Student Portrait Construction and Learning Condition Prediction
Based on Educational Data Mining
TANG Qian
(Beijing Institute of Technology, Zhuhai, Zhuhai 519088, China)
Abstract: By collecting the behavioral data of students' book borrowing, participating in public welfare activities and surfing the Internet, this paper uses the random forest algorithm to mine the correlation degree between behavior characteristics and academic performance, and the key characteristics are extracted to weight and calculate for merger to form new characteristics. Through the clustering analysis of the basic model K-means algorithm, the students are divided into three types of excellent performance in self-discipline, late sleepers with Internet access and lack of planning. This paper establishes a prediction model based on the logistic regression model, and discusses the prediction effect of the three types of students, which provides a reference for educators to deeply diagnose students' learning status and give precise teaching guidance and intervention.
Keywords: educational data mining; behavioral data; student portrait; correlation; prediction analysis
0 引 言
教育信息化2.0時代,教育进入以大数据驱动的新时代。目前,高校内积聚了学生的各类在校行为数据并逐步构建成为智慧校园。学生画像作为智慧校园中的重要组成部分,通过搜集和整理学生在各类平台中留下的碎片化“烙印”,进行聚合和抽象形成学生的专属“画像”,以反映学生的多方面属性。学生的学习成绩作为教育教学中的核心指标,是衡量学校教学质量、检验教师教学成果和评价学生知识掌握程度的重要依据,分析学生行为特征与学习成绩之间存在的内在联系和潜在规律,获得优化教学决策的信息并加以应用,已引起高校和研究者的广泛关注。本研究基于数据挖掘技术,通过采集学生的基本信息、图书借阅、上网行为、参与公益活动等各类数据,挖掘行为特征与学习成绩之间的关联性,进一步提取关键特征并构建学生画像,针对不同类群的学生建立预测模型预测其学业成绩,以达到对学生异常情况的早期预警,优化教学实施过程,以促进学校对不同类群学生的培养、引导和管理工作。
1 相关研究
教育数字化转型已成为高等教育高质量发展的重要引擎和创新路径,引发了高等教育教学模式、治理体系等方面的系统性变革。在2020年出台的《深化新时代教育评价改革总体方案》中提出,利用人工智能、大数据等现代信息技术,探索学生在学习全过程纵向评价和德智体美劳全要素横向评价。教育数据挖掘已成为教育信息化、数字化的新方法,从应用需求上来看,王宏志、熊风等将教育数据挖掘划分为三个层次,即描述分析、预测分析和规范分析[1]。其中,描述分析是依据历史数据描述并分析学生行为特征,预测分析是指预判学情的未来趋势及概率,规范分析根据学生的历史数据提出学生下一步的学习计划和引导方案。杜婧敏、方海光等认为教育数据挖掘的应用主要体现在评估、预测和干预,评估是指基本统计分析及其可视化、提取学生群体特征,预测是针对不同类型的学生构建预测模型研判学生成绩,干预是指对教师的教学方法提供改进意见[2]。李凤霞、徐玉晓提出了教育数据挖掘的三大主要趋势为教育数据的挖掘分析以优化教学策略,开发自适应学习系统以实现个性化学习,以及开展多元化的学生综合评价促进教育教学模式的创新[3]。国外相关学者也对此进行分析研判,KLA?NJA-MILI?EVI?等构建了教育大数据的理论框架,包含信息技术分析、学习分析和平台机构分析[4]。美国智库布鲁金斯研究院提出了教育大数据研究的五种范式为趋势分析、聚类分析、关系挖掘、自然语言转化以及构建现象解释模型[5]。Kirsty Kitto建立了一种新的教学数据挖掘方法“do(做)—analyse(分析)—change(改变)—reflect(反映)”,以区别传统的特定系统范围内的教学数据静态分析,形成面向学生行为跟踪的动态数据分析[6]。通过研究成果梳理分析,我们发现教育数据挖掘(Educational Data Mining,EDM)方法主要包括预测(Prediction)、聚类(Clustering)、关联挖掘(Relationship Mining)、决策支持(Distillation for human judgment)和模型发现(Discovery with models)。当前教育数据挖掘应用主要聚焦于三大热点:以解释和优化学生学习过程的学习分析,以学生个性化需求为导向的教育空间及平台分析,以学生动态性、全过程为研究对象的教育数据治理分析。
从数据来源来看,教育数据可分为学习者个人信息、学习资源信息(视频、PPT、文档等)以及学习者行为信息(行为跟踪、社会交互等)等不同来源的异构数据。通过采集和整理学生海量的行为数据,抽象出学生的行为特征并形成学生用户画像。学生画像是由用户画像概念迁移而来[7]。一般来说,学生画像由学生特征、学生标签和学生属性三个基本要素构成[8]。学生画像侧重于对学生进行不同维度的划分。目前,已形成了学生画像的一定研究,Kiu等人通过研究图书馆的学生数据,挖掘分析其阅读习惯,进而构建画像,为学生读者推荐图书的目的[9]。张治等构建学生的个体画像和群体画像,分别服务于学生生涯规划和个性发展,为学校办学改进和政府教育治理提供决策支持[10]。薛耀峰等设计了基于德、智、体、美、劳五个维度的学生画像用于呈现不同区域学生的培养发展情况[11]。因此,学生的数字画像是以学生的行为数据为客观事实和依据,通过数据挖掘等技术方法抽离出描述学生的真实特征及行为的标签集,基于具体的教学情境的形成有信度和效度的综合评价。
综合已有的研究基础,本研究基于预测、聚类和关联分析三个教育数据挖掘的主要方法,通过采集学生的多维行为数据,分析学生们在生活规律、学习习惯等方面的群体特征,计算学生行为特征与学习成绩之间的关联程度,利用聚类算法对学生进行用户画像形成立体的评价,并构建预测模型深入分析预测各类群学生的学习成绩变化特征[12,13]。
2 数据采集与预处理
本研究以广东省某高校的103名本科生为研究对象,使用学生脱敏数据进行分析,该数据集包含了学生基本信息、学籍信息等静态数据,以及两个学年的成绩信息、图书借阅记录、参与公益活动记录、上网记录等动态数据。
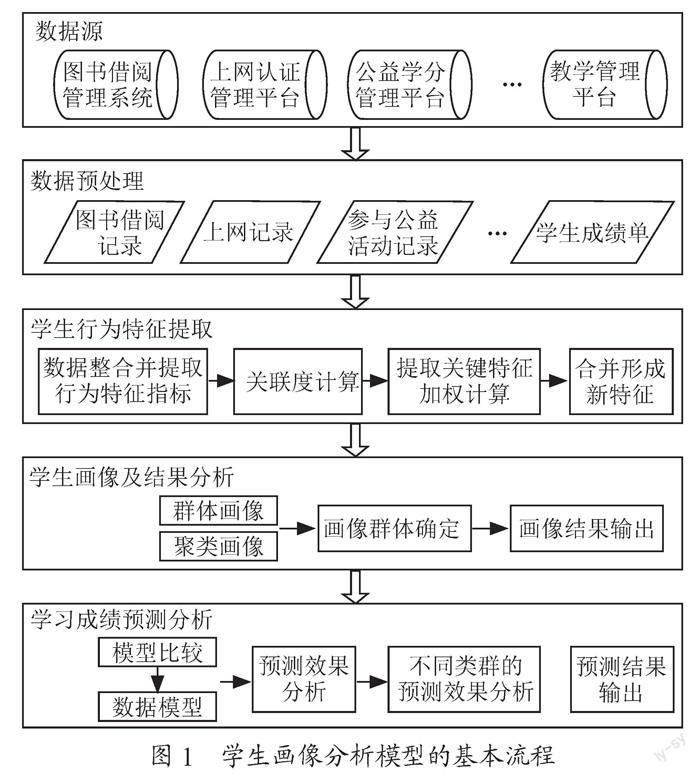
数据预处理在数据挖掘中约占整个工作量的80%,数据的质量将会直接影响模型分析的效果,因此,在建模之前,需要先对数据进行预处理。为了提升数据质量,针对部分信息记录不完全或存在缺失的样本进行清洗等预处理操作。并进一步计算各特征值与学习成绩相关性及影响度,针对关联度大的标签进行加权计算并强化学生属性,最后通过合并新特征并聚类形成学生用户画像,分析模型基本流程如图1所示。
对经过数据预处理之后的数据类型汇总,分为学生基本信息、图书借阅信息、上网行为信息、参与公益活动信息以及教学活动信息5个部分,预处理后的2018级学生特征如表1所示。
3 学生群体画像分析
为了进一步探索数据,我们将预处理后的数据利用汇总统计及可视化进行数据特征的初步分析,勾勒出学生群体画像。
3.1 学生基本情况
本次的研究对象为2018级某专业103名本科生,其中男生46人,女生57人,從性别比例上来看相差不大。学生们主要来自广东省内,占比68.75%,其余则来自湖南、湖北、浙江、陕西、吉林等11个省份。同时,我们采集了学生的语文、数学和英语三科的入学成绩,因不同省份的高考总分不一致,无法对分数进行横向比较,我们通过预处理将高考总分对标学分制5.0,进一步将学生入学的三科分数转化为学分绩点,并计算出语文、数学、英语三科的平均绩点分别为3.39、3.06、3.24。从学生获得奖学金情况来看,在统计周期内共计有68名同学获得优秀学生奖学金,人均获奖0.66次,学生生源地及性别分布情况如图2所示。
3.2 图书借阅数据
大学图书馆是高校教学科研工作的支撑,也是学生学习的第二课堂。本研究选取的图书借阅信息,包含学号、书名、书号、借阅日期、书籍所属类型等指标,探索学生图书借阅的数据特征。通过图3和图4图书借书次数的分布情况可以看出,约有84%的学生借书图书次数集中在[0,30]之间,最多的一位同学借阅图书84本,最少的一位同学借阅图书1本。其中,学生们借阅次数最多是文学类和经济类的书籍,相比较而言,男生更愿意阅读经济、数理科学及化学、工业技术方面的书籍,而女生则更倾向于阅读文学、语言文字以及政治法律方面的书籍。
3.3 上网行为数据
利用网络进行网上学习、社交和娱乐等已成为大学生在校生活的重要组成部分,基于此,通过对校园网的上网认证管理平台有关学生的登录时间、退出时间、登录日期、登录网址等字段的原始数据预处理,抽离出学生的上网次数与时长、平均上网时长、上网集中时段等指标,分析学生上网行为的典型特征。图5和图6展示了学生平均每周的上网时长,超过一半的学生平均每周上网时长控制在40小时以内,大约有30.1%学生平均每周的上网时长在20~40小时范围内(即平均每天花在网上的时间为6小时以内),按照不同时间段的上网人数来看,学生们上网的高峰期为晚上19:00—24:00时,占比为81.16%,其次为下午13:00—18:00,占比69.36%,约有30.39%学生选择在当日早晨或通宵至次日凌晨上网。
3.4 参与公益活动数据
为鼓励学生积极参与各类的公益活动陶冶心灵、服务社会,增强社会实践经验,各高校专设公益学分并通过公益活动管理平台进行监管。因此,我们设置了学生们参与公益活动次数及时长、获得公益活动认证学分等指标,了解学生参与公益活动的整体情况。通过图7展示可知,学生们参与公益活动的积极性较高,人均参与公益活动约10次,但女生明显要比男生更积极主动参加,从人均获得公益学分数来看,女生参与公益活动获得的学分超过男生的一倍。
4 特征值的关联性分析
在学生画像的聚类算法中,特征的选取直接影响聚类效果。因此,本研究将各特征值与学生成绩之间进行关联性分析,以关联度作为特征选择的度量指标,针对关联性高的标签进行加权计算合并成新特征刻画学生画像。
本研究分别通过线性回归、决策树、随机森林、K最邻近节点(K-Nearest Neighbor, KNN)以及支持向量机(Support Vector Machine, SVM)算法开展关联度计算,并针对算法性能进行比较分析,发现随机森林算法的性能指标MSE值最小,且计算结果的上限、下限差值最小,即算法模型的波动最小,效果最稳定,比较如图8所示。
采用随机森林算法计算各特征值与学生成绩之间的关联度,其中,上网时间的特征值与学习成绩之间的关联度最高达到0.388,选择在不同时间段上网的行为习惯也潜在影响学生学习成绩。而语文、数学和英语三门科目的入学成绩对学生大学阶段的学习也存在一定的影响,其中语文科目的影响度为三科中的最高,达到0.296,其次为数学科目。学生参与公益活动、借阅不同类型的书籍与其学习成绩之间也都存在内在联系,针对学生的专业学科背景,从数据上来看,借阅语言、文化类的图书对其成绩的影响高于其他类型图书,其次为经济类图书。图9展示了与学习成绩之间关联度最高的八个特征。
5 学生聚类画像分析
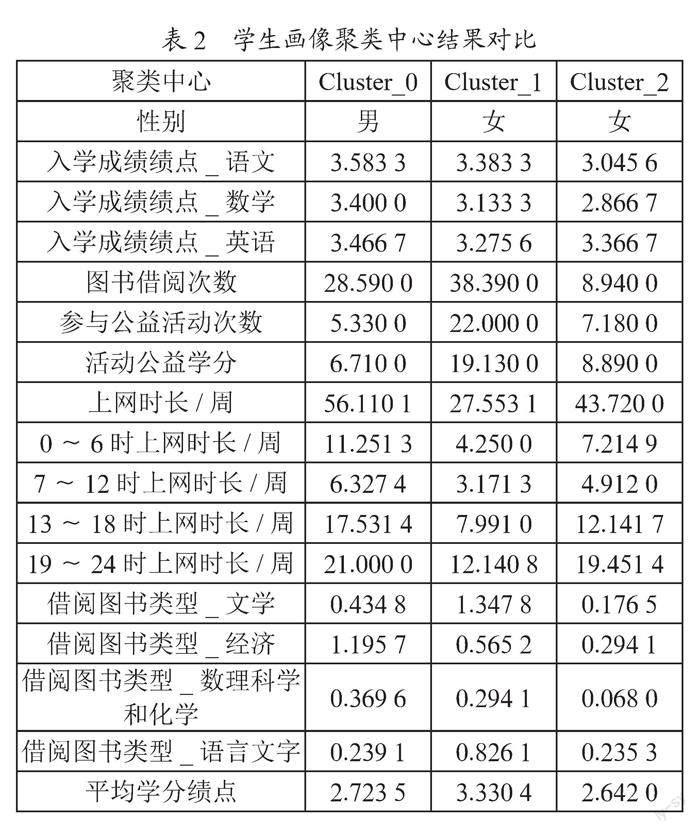
本研究依据各特征值与学习成绩之间的关联度,采用层次分析法(AHP)在保证特征多样性的基础上分析特征的重要度并确定新权重,在尽可能保留特征全的基础上增加特征之间的差异性。通过基础模型K-means聚类算法进行中心点选择的多次算法实验,最终发现当聚类算法按照K=3进行聚类,得到学生类群的特征差异最显著,Cluster_0、1、2共计3个聚簇及中心如表2所示,三维聚类图如图10所示。
学生画像实验结果分析如下:
自律学霸型学生:对应于聚簇Cluster_1,从性别上来看以女生居多,虽入学成绩并不突出,但在校期间积极主动学习并严格要求自己,阅读课外书籍的数量、参与公益活动的次数均远高于其他两类同学,并且具有较强的自律性,严格控制在宿舍里的上网时间,对应的平均学分绩点达到三类学生中的最高值3.330 4。
夜猫子上网型学生:对应于聚簇Cluster_0,此类学生以男生居多,相比较而此类学生入校时三科成绩最好,虽然也阅读一定的课外书籍,但因缺乏自律性和主动性,不愿意参与公益活动,而且花费较长的时间上网,尤其是夜间上网时长最长,生活作息不规律,导致其学习成绩在入学后产生倒退,反映出网络对缺乏自制学生的负向影响更大。若后续加强对学生的引导和监督,帮助学生建立自律的学习、生活习惯将对该类学生产生较大的影响。
缺乏规划型学生:对应于聚簇Cluster_2,此类学生中仍然是女生占比相对较高,从入学成绩上来看,该类学生的学分绩点为最低,同时,入校后不积极阅读课外书籍,也不主动参与课外活动,学业要求不高,思想上中规中矩,对人生规划缺乏思考,沉迷于网络,学习成绩也是三类群体中的最低。因此,可以将此类学生列为重点关注学生群体,针对女生出现两极分化的现象,可设置一对一帮扶小组,通过教师的关注、引导和监督,帮助该类学生做好人生规划、树立学习目标,结合其他同龄人的带领和帮扶,养成良好的学习和生活习惯,建立一定的学习自信心。
6 基于学生画像的学习成绩预测分析
本研究以学习成绩作为预测目标,分别选取朴素贝叶斯、广义线性模型、Logistics回归、决策树、随机森林、梯度增强树和支持向量机等多个算法模型对样本特征进行预测分析,并对比各模型的性能优劣。其中,Logistics回归算法的综合表现更佳,且准确率最高达到0.593,因此,选取该算法构建学习成绩预测数据模型。并分别针对不同的学生类群构建学习成绩预测数据模型,有针对性的进行学习成绩预测分析。
以学生图书借阅、上网行为、参与公益活动以及开展教学活动四类特征指标为自变量,以统计周期内学习成绩的平均学分绩点为因变量,对自律学霸类型、夜猫子上网型和缺乏规划型三类学生的数据建立logistic回归方程,分别对应表3中的模型1、模型2、模型3。各模型对应的显著性p值均小于0.05,说明模型构建均具有统计学意义,三个模型对原始学习数据的拟合通过检验。根据依次列出模型1、2、3的最大伪R2值分别为0.443、0.362、0.472,这说明模型3和模型1对原始属性变量变异的解释程度最好,模型2对原始属性变量变异的解释程度一般,可能还存在一部分信息无法解释,导致模型的拟合程度并未达到优秀。
从各类群预测结果对比上来看:
模型1在预测自律学霸型学生的学分绩点在4.0以上的正确率为82%,该模型的整体预测正确率为73.2%,说明自律学霸型的logistic模型预测效果较好。
模型2在预测学分绩点1.0以下正确率达到了100%,并且在预测夜猫子上网型学生的学分绩点分布的正确率高于模型1和模型3的预测效果。
模型3对缺乏规划型学生成绩的预测正确率高达69.8%,对学分绩点1.0以下的数据也实现了较好的预测效果,预测的正确率达到75%,这将为教学管理中的学情预警提供有效的数据支持。
7 结 论
在高校校园中,学习和生活是不可分割的兩个部分。借助学生画像在描述学生不同类群特征上的优势、学习成绩预测在实施教学引导和干预上的价值,提出了基于学生画像的学习成绩预测流程,涵盖构建标签体系和数据建模、数据采集与预处理、行为特征与学习成绩之间关联度计算、学生画像分析与输出以及实施学习成绩预测等步骤。针对学生画像输出的自律学霸型、夜猫子上网型和缺乏规划型三类群学生,深入分析并讨论了各类群的学习成绩预测效果,为高校开展相应的学情预警工作提供有效的参考信息。今后,还将继续在更多学习场景中整合学生不同类型的数据,以挖掘学生画像及学习成绩预测的应用潜力,促进个性化教育与现代信息技术的融合创新发展。
参考文献:
[1] 王宏志,熊风,邹开发,等.教育大数据分析:方法与探索 [J].中国大学教学,2017(5):53-57.
[2] 杜婧敏,方海光,李维杨,等.教育大数据研究综述 [J].中国教育信息化,2016(19):1-4.
[3] 李凤霞,徐玉晓.国际教育大数据研究综述 [J].软件导刊:教育技术,2019,18(12):83-85.
[4] KLA?NJA-MILI?EVI? A,IVANOVI? M,BUDIMAC Z. Data science in education:Big data and learning analytics [J].Computer applications in engineering education,2017,25(6):1066-1078.
[5] DARRELL M W. Big Data for education:data mining,data analytics,and web dashboards. Governance studies at brookings [R].Washington:Brookings Institution,2012:1-10.
[6] 卓文秀,杨成,李海琦.大数据与教育智能——第17届教育技术国际论坛综述 [J].终身教育研究,2019,30(3):62-67.
[7] 杨长春,徐筱,宦娟,等.基于随机森林的学生画像特征选择方法 [J].计算机工程与设计,2019,40(10):2827-2834.
[8] 郭顺利,张宇.基于VALS2的在线健康社区大学生用户群体画像构建研究 [J].现代情报,2021,41(10):47-58.
[9] KIU C. Data Mining Analysis On Students Academic Performance Through Exploration Of Students Background And Social Activities [C]//2018 Fourth International Conference on Advances in Computing,Communication & Automation (ICACCA).Subang Jaya:IEEE,2018:1-5.
[10] 张治,刘小龙,徐冰冰,等.基于数字画像的综合素质评价:框架、指标、模型与应用 [J].中国电化教育,2021(8):25-33+41.
[11] 薛耀锋,曾志通,王亚飞,等.面向区域教育治理的学校画像研究 [J].中国教育信息化,2020(7):67-70.
[12] 叶俊民,罗达雄,陈曙.基于短文本情感增强的在线学习者成绩预测方法 [J].自动化学报,2020,46(9):1927-1940.
[13] 蔣卓轩,张岩,李晓明.基于MOOC数据的学习行为分析与预测 [J].计算机研究与发展,2015,52(3):614-628.
作者简介:唐茜(1988—),女,汉族,湖北松滋人,讲师,硕士,研究方向:数据挖掘与分析、供应链信息共享。
收稿日期:2022-09-26
基金项目:广东省教育评估协会2021年度研究课题(21GJYPG10);北京理工大学珠海学院校级教学改革项目(2020009JXGG)
猜你喜欢
农业科技通讯(2023年1期)2023-02-12
选煤技术(2022年2期)2022-06-06
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
中成药(2018年1期)2018-02-02
水利科技与经济(2017年12期)2017-04-22
水利科技与经济(2016年7期)2016-04-25
电源技术(2015年11期)2015-08-22
技术经济(2014年10期)2014-02-28
河南科技(2014年16期)2014-02-27
