
基于改进YOLOv5的复杂背景下交通标志识别研究
2023-06-25 18:49李翔宇王倩影
现代信息科技 2023年10期
关键词:注意力机制
李翔宇 王倩影

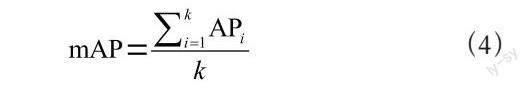
摘 要:针对复杂路况背景下交通标志检测任务存在辨识度低、漏检严重等问题,提出一种基于改进YOLOv5s的轻量级交通标志检测模型。首先,引入坐标注意力模块,增强重要特征关注度;其次,对损失函数进行改进,降低边框回归时的自由度,加速网络收敛;最后,在中国交通标志检测数据集上进行实验。结果表明,模型在保持原有YOLOv5s模型体量的情况下,mAP@0.5提高了2.7%,检测速度达到91 FPS,对各种交通场景变化具有更好的鲁棒性。
关键词:交通标志检测;YOLOv5;注意力机制;损失函数
中图分类号:TP391.4;TP18 文献标识码:A 文章编号:2096-4706(2023)10-0030-04
Abstract: Aiming at the problems of low recognition and serious leakage in traffic sign detection tasks in the context of complex road conditions, a lightweight traffic sign detection model based on improved YOLOv5s is proposed. Firstly, the coordinate attention module is introduced to enhance the attention of important features. Secondly, the loss function is improved to reduce the degree of freedom during border regression and accelerate network convergence. Finally, experiments are conducted on the Chinese traffic sign detection dataset. The results indicate that while maintaining the original YOLOv5s model volume, model's mAP@0.5 improves by 2.7%, with a detection speed of 91FPS, and it has better robustness to various traffic scene changes.
Keywords: traffic sign detection; YOLOv5; attention mechanism; loss function
0 引 言
隨着社会经济与信息技术的快速发展,无人驾驶技术也突飞猛进。交通标志作为交通系统的重要组成部分,对车辆的流量、流向起着重要的调节、疏导和控制作用,对人们出行与车辆行驶安全具有重要的保障作用。交通标志检测作为无人驾驶系统的重要一环,受到越来越多的科研工作者的关注。传统的交通标志检测方法,主要通过是颜色、边缘信息、图片形状等进行信息提取然后再结合机器学习方法进行检测,其检测精度与检测速度往往不能令人满意。随着深度学习的兴起,科研工作者开始将深度学习检测算法应用到交通标志检测任务中来。其中研究主要分为两个方向,一类是以R-CNN[1]和Fast R-CNN[2]为代表的两阶段检测算法,这类算法具有较高的精度,但检测速度慢;一类是以SSD[3]与YOLO系列[4,5]为代表的单阶段算法,这类算法的优势在于检测速度快,可以更好地胜任实时检测任务。
目前大部分研究是基于简单交通场景下标志识别,无法满足现实要求。仅有的一小部分针对复杂场景的识别算法也都是针对某种特定背景,不具有普适性。董天天等人[6]先采用小波分解技术减少特定雨雪场景对检测任务造成的干扰,然后再采用改进后的YOLOv3算法进行交通标志检测。吕禾丰等人[7]对YOLOv5中的边框回归损失函数和非极大值抑制方法进行改进,虽然检测效果有一定提升,但后处理方式较为耗时。
为了更好地解决由于天气、光照、遮挡等复杂路况背景造成的交通标志识别度低、漏检严重等问题,本文提出了一种基于改进YOLOv5s的轻量级检测算法。改进主要包括以下两个方面:1)在主干网络末端引入坐标注意力模块来应对复杂背景下的其他干扰,增加模型对重要特征的关注度。2)对边框回归损失函数进行改进,引入所需回归之间的向量角度,减少预测框在收敛过程中的自由度,加速网络收敛,提高检测效果。
1 YOLOv5概述
YOLOv5是Ultralytics公司于2020年5月份开源的一种新型单阶段目标检测器,集成了众多先进成果,本文采用的是最新的6.0版本,共包括四个模型,从小到大依次是YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x,模型越大代表参数量与计算量越大,模型越复杂,检测精度也越高。为了保持模型的轻量化,本文在YOLOv5s的基础上进行改进。YOLOv5的网络结构主中要包括输入端、主干网络(Backbone)、特征融合网络(Neck)和输出端四部分。输入端主要包括Mosaic4数据增强、K-means聚类生成锚框以及图片缩放等图像预处理操作。6.0版本与之前版本相比在Backbone部位有些许改动,首先,用一个6×6卷积层替换了之前网络第一层Focus模块进行下采样操作,两者在理论上是等价的,但是对于现有的一些GPU设备(以及相应的优化算法)使用6×6大小的卷积层比使用Focus模块更加高效。其次,用SPPF层替换了之前的SPP层,之前的SPP层由尺寸大小分别为5×5、9×9、13×13的池化层并联而成,现在的SPPF使用三个5×5的池化层进行串联,两者效果相同,但SPPF速度提升了两倍。此外主干网络还包括CBS复合模块和C3模块,CBS模块中封装了卷积层、批处理层与激活函数。Neck主要由基于FPN的PANnet特征融合网络构成,用来加强信息传播。最后输出端通过CIoU来计算边界框回归损失,并对3个不同尺度的特征图进行预测。
2 YOLOv5 改进
2.1 坐标注意力机制
注意力机制是机器学习中的一种数据处理方法,可以显著提高神经网络的特征提取能力,广泛应用在自然语言处理、计算机视觉等机器学习任务中。目前应用范围较广的注意力机制都存在一些缺陷,比如压缩-激励模块仅仅建模了通道间的关系来对每个通道加权,并没有考虑到空间结构和位置信息。混合域卷积注意力模块将通道注意力和空间注意力进行串联,尝试在降低通道数后通过卷积来提取位置注意力信息,但依靠卷积只能提取到局部信息,缺少了长程依赖。
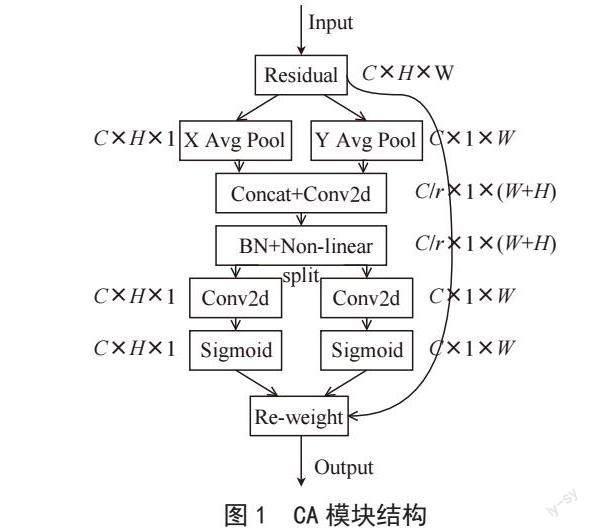
针对以上问题,Hou等人[8]提出了一种新型坐标注意力模块(Coordinate Attention, CA),如图1所示,为了缓解2D全局池化造成的位置信息丢失,CA将通道注意力分解为两个沿着不同方向聚合特征的1D特征編码过程,使得模块可以沿着其中一个空间方向捕获长程依赖,沿着另一个空间方向保留精确的位置信息。然后,将生成的特征图分别编码,形成一对方向感知和位置敏感的特征图,互补地应用到输入特征图来增强感兴趣的目标的表示。经试验证明,引入的CA模块增强了网络对目标的精确定位能力,提高了模型对重要特征关注度,明显改善了模型检测效果。
2.2 损失函数改进
目标检测任务的有效性在很大程度上取决于损失函数的定义,YOLOv5中的CIoU虽然具有较好的宽高拟合效果与偏离趋势度量能力,但没有考虑到所需真实框与预测框之间不匹配的方向。这种不足导致收敛速度较慢且效率较低,因为预测框可能在训练过程中“四处游荡”并最终产生更差的模型。为了弥补这种不足,本文使用SIoU[9]作为YOLOv5中的边框损失函数,SIoU考虑到了所需回归之间的向量角度,并且重新定义了惩罚指标。SIoU损失公式为:
其中θ表示一个超参数,控制着对形状损失的关注程度,ωw和ωh表示预测框和真值框之间的真实宽高比。
3 实验结果与分析
3.1 实验环境与参数设置
本文实验环境计算机硬件配置如下:CPU 为Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50 GHz 45 GB,GPU 为RTX 2080 Ti 11 GB,采用 Ubuntu操作系统和PyTorch 1.10深度学习框架作为实验的运行环境。
为保证对照实验结果的有效性,所有模型均采用相同的超参数,其中,输入图像尺寸为640×640、初始学习率为0.01、动量参数为0.937,最终学习率为0.1,BatchSize为32,在训练开始后进行3轮预热,后续采用余弦退火策略更新学习率,总共训练300个epoch。
3.2 数据集准备与数据增强
本文所采用的数据集为长沙理工大学制作的中国交通场景数据集[10](CCTSDB-2021),为了面向更加真实全面的交通场景图像,2022年开源的CCTSDB-2021数据集新增加了4 000张困难样本,其中不仅包括高速、城市、乡镇等多种路况,还具有雨、雪、雾、夜晚弱光、昼夜强光等多种复杂天气,大大提升了检测难度。该数据集将交通标志分为指示(mandatory)、禁止(prohibitory)、警告(warning)三大类。实验过程中,选取这4 000份困难样本按3:1的比例划分为训练集和测试集。使用的数据增强包括平移、左右翻转、色调、饱和度、曝光度以及Mosaic4六方面。前五项的使用概率分别为0.5、0.1、0.015、0.7、0.4、Mosaic4是指在训练过程中随机选取四张图进行拼接,来增强小目标的检测效果。
3.3 评价指标
为了从多个角度综合的评价模型效果,本文选取了模型参数数量Params(M)、阈值为0.5时的平均精度mAP@0.5以及检测速度(FPS)作为检测算法衡量标准。mAP(mean Average Precision)是指各类别AP的平均值,计算公式为:
其中k表示类别数,AP表示PR曲线下面积。
3.4 消融实验
为了验证本文提出算法在复杂路况背景下对交通标志的检测效果,以及各项改进的有效性,设计了4组消融实验,如表1所示。在原YOLOv5基础上引入CA模块后模型mAP@0.5提升了1.0%,且几乎不带来额外计算开销。在此基础上继续对损失函数进行改进,在引入SIoU后,模型mAP@0.5提升了1.7%,与原YOLOv5模型相比,模型mAP@0.5提升了2.7%,在大幅提升检测效果的同时,保持了模型的轻量化。图2展示了消融实验各阶段改进的检测精度对比。其中横坐标表示训练轮次,纵坐标表示IoU阈值为0.5时的平均精度。
3.5 对比实验
为了进一步验证本文改进算法的有效性与先进性,我们设计了6组对照实验,与目前主流算法在本文数据集上进行对比,如表2所示,我们分别从模型大小、检测精度以及检测速度三个维度对6个模型的检测效果进行比较,无论是在相同体量的模型中对比检测精度,还是以检测精度为基准对比模型体量与检测速度,均可以证明本文改进算法的有效性与先进性。
3.6 定性评价
为了更加直观展现算法改进前后的检测效果,在测试集中抽取了部分交通标志检测图像进行定性评价,如图3所示。左侧图像为雨夜道路伴有局部强光与反光,路况复杂、干扰严重,右侧图像为夜晚弱光道路目标识别,能见度低。在两组实验中,原YOLOv5(上面两幅图)均出现了漏检,改进后的算法(下面两幅图)不仅检测到了所有正确目标,并且预测框的置信度得分普遍高于原模型,说明改进后的算法捕获到了更加准确的位置信号与语义信息,具有更强的检测效果。
4 结 论
针对复杂路况背景下交通标志识别度低、漏检严重等问题,本文提出了一种基于YOLOv5s的改进算法。通过引入坐标注意力来应对复杂背景下的其他干扰,提高特征关注度;增加角度损失组件来减少预测框在收敛过程中的自由度,更快贴合真实目标,提高检测效果。本文所提改进算法与原YOLOv5相比mAP@0.5提高了2.7%,并且维持了原有的体量与检测速度。与目前主流模型相比,本文模型在同等体量下检测精度更高,在同等精度下体量更小、检测速度更快,对各种场景变化具有更好的鲁棒性。
参考文献:
[1] GIRSHICK R,DONAHUE J,DARRELL T,et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation [C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:580-587.
[2] GIRSHICK R. Fast R-CNN [C]//2015 IEEE International Conference on Computer vision(ICCV).Santiago:IEEE,2015:1440-1448.
[3] LIU W,ANGUELOV D,ERHAN D,et al. SSD: Single Shot MultiBox Detector [J/OL].[2022-11-18].https://arxiv.org/pdf/1512.02325.pdf.
[4] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once:Unified,Real-Time Object Detection [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas:IEEE,2016:779-788.
[5] BOCHKOVSKIY A,WANG C Y,LIAO H Y M. Yolov4: Optimalspeed and accuracy of object detection [J/OL].arXiv:2004.10934 [cs.CV].[2022-11-18].https://arxiv.org/abs/2004.10934.
[6] 董天天,曹海啸,阚希,等.复杂天气下交通场景多目标识别方法研究 [J].信息通信,2020(11):72-74.
[7] 吕禾丰,陆华才.基于YOLOv5算法的交通标志识别技术研究 [J].电子测量与仪器学报,2021,35(10):137-144.
[8] HOU Q B,ZHOU D Q,FENG J S. Coordinate Attention for Efficient Mobile Network Design [C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition,Nashville:IEEE,2021:13708-13717.
[9] GEVORGYAN Z. SIoU Loss: More Powerful Learning for Bounding Box Regression [J/OL].arXiv:2205.12740 [cs.CV].[2022-11-19].https://arxiv.org/abs/2205.12740.
[10] ZHANG J M,ZOU X,KUANG L D,et al. CCTSDB 2021: A More Comprehensive Traffic Sign Detection Benchmark [EB/OL].[2022-11-20].http://hcisj.com/articles/?HCIS202212023.
作者简介:李翔宇(1997—),男,漢族,河北石家庄人,硕士研究生在读,研究方向:机器学习与大数据分析、目标检测;王倩影(1984—),女,汉族,河北保定人,副教授,博士研究生,研究方向:深度学习。
猜你喜欢
计算机应用(2019年3期)2019-07-31
无线互联科技(2019年9期)2019-07-29
无线互联科技(2019年9期)2019-07-29
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
电子技术与软件工程(2019年5期)2019-06-20
软件导刊(2019年1期)2019-06-07
数字技术与应用(2019年2期)2019-05-14
现代电子技术(2018年8期)2018-04-13
