
单向句法依存关系指导下的跨模态检索
2023-06-25 14:40张知奇袁鑫攀曾志高
现代信息科技 2023年10期
张知奇 袁鑫攀 曾志高


摘 要:大多数现有的跨模态检索方法仅使用每个模态内的模态内关系或图像区域和文本词之间的模态间关系。文章中提出了一种基于自然语言的句法依存关系的视觉语言模型,称为Dep-ViLT。通过句法依存分析,构建句法依存树,利用单向的句法依存关系增强核心语义的特征表达,促进语言模态与视觉模态的特征交互。实验表明,Dep-ViLT对比现有的SOTA模型召回率(R@K)平均提升了1.7%,最高提升2.2%。最重要的是,Dep-ViLT在具有复杂语法结构的长难句中依然表现良好。
关键词:句法依存;跨模态检索;图卷积;Transformer
中图分类号:TP391.3 文献标识码:A 文章编号:2096-4706(2023)10-0074-06
Abstract: Most of the existing cross-modal retrieval methods only use the intra-modal relationship within each mode or the inter-modal relationship between image regions and text words. This paper proposes a visual language model based on the syntactic dependency relationship of natural language, called Dep-ViLT. Through syntactic dependency analysis, the syntactic dependency tree is constructed, and the one- directional syntactic dependency relationship is used to enhance the feature expression of core semantics and promote the feature interaction between language mode and visual mode. The experiment shows that the recall rate (R@K)of Dep-ViLT compared with the existing SOTA model has an average increase of 1.7%, with a maximum increase of 2.2%. Most importantly, the Dep-ViLT still performs well in long and difficult sentences with complex grammatical structures.
Keywords: syntactic dependency; cross-modal retrieval; figure convolution; Transformer
0 引 言
隨着互联网的蓬勃发展,数据呈现出爆发式增长,这些数据通常以多模态形式呈现,包括但不限于图片以及对应的文本描述,因此跨模态检索(例如,使用图像查询来搜索相关文本,反之亦然)已成为一个突出的研究主题。
提升跨模态图文检索准确度的关键是特征表示,为了解决不同模态信息的异构鸿沟问题,首先想到的就是对不同模特的数据进行单独的特征提取。在基于特征表示的方法中,针对单模态特征,Peng[1]等人提出了模态针对型深层结构模型(Modality-Specific Deep Structure, MSDS)。该模型通过卷积神经网络提取图像区域特征,通过WCNN提取文本表征。WCNN可以处理任意大小的文本序列并获取具有相同维度的结果特征向量[2]。随后,基于模态针对型深层结构模型,HE等人[3]提出了深度双向表示学习模型(Deep and Bidirectional Representation Learning Model, DBRLM)的方法,利用图像的图题中的结构信息和位置信息进行数据增强,利用不对称结构学习模态间的关系,拓展了双向网络模型的研究思路。
针对单标签或多标签问题,为了更好地弥合视觉语义和文本语义间的差距,Qi等人[4]使用了深度卷积激活特征描述子(Deep Convolutional Activation Feature, DeCAF),将卷积神经网络产生的预测作为ImageNet的输入视觉特征。实验表明,深度卷积激活特征描述子可以使ImageNet再次学习卷积神经中提取的图像特征,精炼图像特征,并且效果优于卷积神经网络。由于CNN预训练模型具有良好可迁移性质,针对同一问题,Song等人[5]采取微调CNN预训练模型方案,提出了深度语义匹配方法(Deep Semantic Matching, deep-SM),对不同模态的数据采取不同的损失函数,使用微调的CNN和重新训练的FN将图像和文本投影到同一纬度的向量特征空间中,如图1所示。实验表明,微调的方法可以提高模型对目标数据集的适应性,有效降低训练难度,拉近多模态数据的语义异构距离。
综上所述,目前的基于单模态特征表示的方法有两种方式来更好地提取多模态输入特征:
1)针对不同模态,采用针对性的方法提取单模态特征来增强图像和文本的表征能力。该方法对大规模的特定数据集具有良好的特征学习能力。
2)微调或者改进CNN模型。在大规模的多标签数据集上,该方法具有良好的适应性和迁移性。
但是,目前研究者在基于单模态特征表示的方法中更倾向于对视觉特征的表征方法的改良,文本数据在跨模态语义特征提取过程中并没有得到很好的研究[6]。
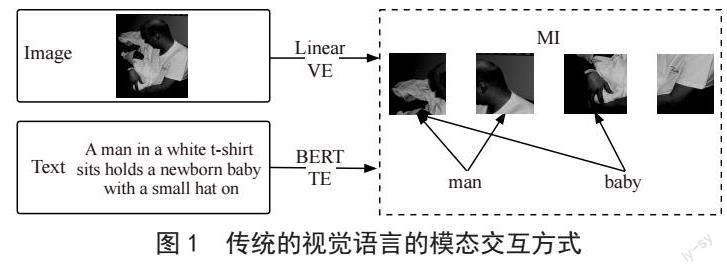
针对文本数据在跨模态语义特征提取问题,我们将目光锁定在词嵌入方法的选取上。因为针对视觉模态,ViLT已经采取了最简单的处理方式,将视觉模态的大部分计算量转移到了模态交互层。所以说能否正确理解文本语义将直接决定ViLT的模态交互效果。在融合语义理解的能力上,句法依存关系具有天然的优势。本文以ViLT模型为基础,在文本嵌入中引入句法依存树,利用句法依存树对文本重新建模,并进行依存分析,通过斯坦福NLP工具抽取文本的句法依存三元组,以词为节点,依存弧为边,构建句法依存图,并将句法依存图输入到GCN中得到句法依存关系的表征。句法依存图如图2所示。句法依存关系将句子表示为有向树,在相关单词之间具有修饰依存弧,一个依存弧单向连接两个词,分别是核心词(head)和依存词(dependent)并标注词性,弧边标注依存关系的类型。从图2中可以看出,“man”是“sits”的名词主语,属于动作的施加者。“baby”是“holds”的直接宾语,而且“sits”和“holds”这两个动作之间是依赖关系,因此“baby”属于主语“man”的动作“sitsholds”的直接承受对象。这两个依存方向共同构成了一个有效的证据,即“mansitsholdsbaby”。我们将文本嵌入的注意力从双向的上下文语义转换到单向的句法依存方向上。再从另一方面可以看出“shirt”是“man”的复合名词,它们之间的关系是关联修饰,句法依存树能直接将核心词“man”链接到“shirt”,表示“shirt”和“man”这两个词是强相关的,理应给予更多的注意力。因此引入句法信息可以有效帮助模型提高检索性能和增强语义中心可解释性。
综上所述,本文的贡献如下:
针对词嵌入无法明确主语动作行为的对象导致的歧义问题,提出基于句法依存分析和图卷积的ViLT模型。通过句法分析得到依存关系三元组,其中单向的依存弧代表依存方向。该模型能够充分学习句子中的复杂语义依赖关系和单词粒度的词性标注。
将Dep-ViLT(Dependency-Vision and Language Transformer)在MSCOCO和Filck30K这两大数据集中进行大量对比实验。实验结果表明句法依存信息对模型的训练和预测有着至关重要的指导作用。
1 Dep-ViLT
如图3所示,Dep-ViLT主要由三部分组成:
1)针对输入的文本模态使用BERT将单词装换成词向量。针对输入的图像使用简单的线性切割将图片分割成N个图像块。并标注位置信息。
2)根据文本构建它的句法依存树,标记每个单词的词性,并将其输入至图卷积神经网络(GCN)中,得到句法依存特征。
3)输入到Transformers模態交互层进行交互计算,得到全连接层的概率分布。
1.1 Word Embedding and Image Preprocessing
假设输入的文本为 ,通过词嵌入矩阵 和位置嵌入矩阵 嵌入到 。其中L表示文本长度,H表示隐藏层深度,V表示单个词向量的维度。
假设输入的图像为 被分割并展平为图像块 ,其中C表示图像通道数,H和W表示图像的长和宽,(P,P)表示图像块分辨率,N=HW/P2。接着将 线性投影到 并加上位置嵌入矩阵 得到 。
1.2 句法依存分析
句法是句子中词与词之间相互依赖的关系和关系类型的合集,包括但不限于主谓宾,定状补等句法关系,将所有词与词之间的依存关系抽取出来,以句子中的中心词为根节点,其余词语为子节点,依赖关系为边,构建句法依存树。句法依存树可以清晰地表达出句子中词与词之间的逻辑关系,不管在物理上距离多远,只要存在相互修饰关系,则在树中的距离会很相近[7]。为了分析抽取句子中的依存关系,本文利用工具得到文本的依存树表示。传统的机器学习算法通常将句法依存关系转化成向量,与文本的语义向量合并后,用于机器学习的输入,这样的学习方并没有与语义向量进行有效融合[7],所以本文通过工具得到句法依存信息,再将依存信息重构成句法依存图表示,用于图卷积神经网络中。具体步骤如下。
1.2.1 基于依存语法拆分句子
本章所讨论的句法依存树使用斯坦福公开的句法分析工具Stanford Core NLP(斯坦福句法分析器)产生。该工具是一个基于jvm的注释管道框架,它提供了从标记化到共同引用解析的大部分公共核心自然语言处理的步骤。例如:“A man in a white t-shirt sits holds a newborn baby with a small hat on”。通过斯坦福句法分析器可以快速地对句子进行依存句法分析,其分析结果如表1所示。
其中,分词方法会将中文句子进行分词操作,并且返回一个分词后的列表。词性分析方法则会将分词后的词表进行词性标注。
1.2.2 构建句法依存图
第一步获得有效的句子依存结构关系后,句子通过Dependency Parser 方法生成句子依存三元组,获得如表1中最后一行所示的依存关系元组。Dependency parse方法返回一个依存关系三元组的列表,列表中每一项的格式如下:(依存关系,关系出发索引,关系结束索引)其中,Root代表依存树的根节点,根节点的出发索引为0,结束索引为9。该索引代表了分词列表中以9为起始点的该索引所代表的词。如在表1中,索引为9所代表的词为“sits”。根据依存关系元组即可构建出如图4的句法依存图。
1.2.3 GCN解析
本文引入GCN对句法依存图展开分析。利用G={V,E}表示基于依存句法树构建的句法依存图,V表示一个句子中的所有节点,即词的集合;E表示边的集合,即所有依存关系的集合。基于依存句法树中的依存关系,在句子中,如果某一个词是某条依存关系的依存词,则在关联矩阵中元素赋值为1。若句子中的某个词是某条依存关系的被依存词,则赋值为-1;若不存在依存关系,则赋值为0。这样即得到一个稀疏的关联矩阵A。之后基于关联矩阵A表示的图G,利用GCN对图中节点si进行卷积,得到特征DEPi,具体如式(3)所示:
其中,ReLU表示激活函数;A表示联矩阵; 表示A的度矩;;Wc表示GCN的权重矩阵。
1.3 Transformers Encoder
2 实验结果与分析
2.1 数据集和评估方法
本文在两个广泛使用的数据集上对Dep-ViLT进行多模态检索任务评估,数据集的样本如图5所示(图中示例来自Filckr30K,其ImageId为69551477),数据集统计如表2所示(文本长度是来自bert-base-uncased标记的长度)。
1)MSCOCO是一个由123 287个图像组成的大型图像文本数据集,其中每个图像都用5句自然语言进行描述。我们采用MSCOCO的标注将数据集分割:5 000张图像用于测试,5 000张图像用于验证,其余113 287张图像用于训练。
2)Flickr30K总共包含31 000张图片和158 915个自然语言描述。每个图像通常用5句自然语言进行描述。在分割之后,我们使用1 000张图像进行测试,另外1 000张用于验证,其余用于训练。
本文采用在跨模态检索中广泛使用的查询问题评价指标R@k(k=1,5,10)用于性能评估,表示前k个检索结果中相关结果数与所有相关结果数的比率,衡量的是检索系统的查全率。计算方式如式(8):
对于单一查询,在系统中搜索k个最近的结果,若返回的k个结果中至少存在一个相符的搜索结果,则该次查询的score记为1,否则记为0。
2.2 实验设置
对于所有的实验,我们使用AdamW优化器,在前5个epoch中将初始学习率设置为5×10-5,然后在其余的epochs中使学习率线性衰减。
为了方便探究句法依存树是如何影响文本的特征提取过程的,我们将语言模态输入分为三种类型:原始文本、句法依存树、经过词性标注后的句法依存树。作为Dep-ViLT的语言模态的输入,上述三种类型可以自由排列组合,并在Transformers中进行交互。我们对原始文本的嵌入部分采用基于BERT-base的模型作为文本编码器,该模型总共包含12个Transformer层,其中含有768个隐藏单元和12个heads。此外,为了提高计算效率,Dep-ViLT使用ViT-B/16作为图像编码器,输入图像分辨率为384×384。
2.3 对比实验
本文分别选取以下5种模型与Dep-ViLT进行实验比较,它们分别是SCAN、CAAN、MMCA、SGRAF、COTS。其中COTS是现在的跨模态领域中的SOTA方法。
2.3.1 SCAN
SCAN[8](Stacked Cross Attention for Image-Text Matching)提出了深度视觉语义对齐的堆叠交叉注意力机制,捕捉视觉和语言之间的更深层次的语义联系,推断图像-文本相似性。并使图像-文本匹配更易于解释。
2.3.2 CAAN
CAAN[9](Context-Aware Attention Network for Image-Text Retrieval)提出了一个统一的上下文感知注意力网络,基于给定的上下文从全局的角度自适应地选择信息片段,其中包括单一模态中的上下文语义以及图像语义实体区域和文本单词之间的对齐关系。
2.3.3 MMCA
MMCA[10](Multi-Modality Cross Attention Network for Image and Sentence Matching)通過在统一的深度网络模型中联合图像区域和单词的模态内关系和模态间关系,提出了一种新的用于图像和文本匹配的多模态交叉注意网络。
2.3.4 SGRAF
SGRAF[11](Similarity Reasoning and Filtration for Image-Text Matching)在MMCA的基础上提出了相似度图推理(SGR)模块来通过图推理推断图像文本的相似度,该模块可以识别更复杂的匹配模式,并通过捕获局部和全局对齐之间的关系来实现更准确的预测。为了在相似性聚合中减少非关键词的干扰,提出了一个有效的相似性注意过滤(SAF)模块来抑制不相关的交互,以进一步提高匹配精度。
2.3.5 COTS
Lu[12]等人提出了一种新的双流VLP模型(Collaborative Two-Stream Vision-Language Pre-Training Model for Cross-Modal Retrieval, COTS)。为了提高双流模型的性能,同时保持其高效率,除了实例级对齐之外,COTS还利用了两个额外的跨模式学习目标:一是用于令牌级交互的掩蔽视觉语言建模(MVLM)学习目标。二是用于任务级交互(Task-Levelinteraction, KL)对齐学习目标。为了减轻大规模预训练数据中噪声所带来的负面影响,Lu提出了一种自适应动量滤波器(AMF)模块。AMF在实例级对齐中充分利用动量机制,并在预训练期间自适应地过滤有噪声的图像文本对。值得一提的是,目前COTS在所有的双流模型中表现出了最高的性能,并且与最新的单流模型相比,模型性能相当,但是推理速度快10 800倍。
我们在两个广泛使用的图像文本数据集Flickr30K和MSCOCO上比较了我们的Dep-ViLT和最先进的方法,结果如表3所示(I2TRetrieval为图像检索文本;T2IRetrieval为文本检索图像;#为本文提出的方法;Dep-ViLT-Base为只有句法依存树。Dep-ViLT-P(Partofspeech):包含句法依存树和词性标注;Dep-ViLT-O(Originaltext):包含句法依存树和原始文本;Dep-ViLT-OP(OriginaltextandPartofspeech):包含句法依存树和原始文本,并开启词性标注)。
表3是各类算法在Flickr30K和MSCOCO数据集下的R@K指标的实验结果,整体来说,在R@K指标上本文所提的Dep-ViLT算法都优于其他对比方法。
Dep-ViLT在R@1、R@5和R@10的检索查全率指标上大大优于SCAN、CAAN、MMCA、SGRAF这四种单流模型。具体而言,与最新的单流模型SGRAF相比,我们的Dep-ViLT-Base在均使用MSCOCO数据集的情况下在I2TRetrieval任务中取得了R@1指标的5.41%(63.21% VS 57.8%)的领先,在T2IRetrieval任务中,R@1和R@10均有5%(46.83% VS 41.9%,86.96% VS 81.3%)的提升幅度。此外,当Dep-ViLT同时引入句法依存树和原始文本并为句法依存树开启词性标注时,我们的Dep-ViLT进一步提升了性能。
Dep-ViLT与双流模型的对比同样也是可圈可点。在于最近的SOTA模型COTS的对比中,可以看到在I2TRetrieval任务下,两者的R@K性能表现不相上下,Flickr30K数据集中的R@5和MSCOCO数据集中的R@1和R@10对比COTS均有小幅度的优势。但是在T2IRetrieval任务下,我们的Dep-ViLT-OP明显优于COTS,MSCOCO数据集中的R@10指标领先了2.25%(88.35% vs 86.1%)。在实验环境相同的情况下,考虑到双流模型比单流模型的参数量要多得多,在I2TRetrieval任务中单流模型Dep-ViLT与双流模型COTS性能相同,但是模型大小更轻量。在T2IRetrieval任务中更是取得了R@K指标上的优势。另外,因为COTS模型在模态交互之前提取的模态特征,说明我们所提的Dep-ViLT模型针对句子依存关系的图卷积的依赖关系提取是具有可行性的。
3 结 论
在本文中,我们研究了如何提高跨模态检索的性能。具体而言,我们通过在图像文本检索中利用文本的句法依存关系和词性标注,提出了一种新的基于ViLT的文本句法依存关系(Dependencies)指导的视觉语言模型,称为Dep-ViLT。也就是说,我们通过分析文本的句法依存关系构建句法依存图,通过图卷积神经网络提取句法依存方向。在句法依存关系中,单向的依存方向能够促进语言模态和视觉模态间的交互。大量实验验证了我们的Dep-ViLT在图像文本检索中的有效性和高效性。它還证明了词性对句法依存关系的表征提取及其依存关系与原始文本语义对齐有至关重要的作用。
未来的研究工作可以从以下4个方面去考虑:
1)模型提取句法依存图特征采用的是图卷积神经网络,可以考虑更换成其他更优越的模型架构,可能获得更好的效果。
2)模型将句法依存关系分析重组成句法依存图,可以考虑将句法依存关系表示成其他数据结构,可能利于模型进行依存分析。
3)除了图像和已经标注好的描述文本,可以考虑是否存在其他的隐性信息。
4)本文是针对英文的图像描述文本开展句法依存关系分析工作,而且中文的句法与英文的句法存在千丝万缕的联系,因此,可以考虑对中文的图像描述文本展开同样的工作,以提高中文领域的跨模特检索性能。
参考文献:
[1] PENG Y X,QI J W,YUAN Y X. Modality-Specific Cross-Modal Similarity Measurement With Recurrent Attention Network [J].IEEE Transactions on Image Processing,2018,27(11):5585-5599.
[2] KIM Y. Convolutional Neural Networks for Sentence Classification [J/OL].arXiv:1408.5882 [cs.CL].(2014-08-25).https://arxiv.org/abs/1408.5882v2.
[3] HE Y,XIANG S,KANG C,et al. Cross-Modal Retrieval via Deep and Bidirectional Representation Learning [J].IEEE Transactions on Multimedia,2016,18(7):1363-1377.
[4] QI J W,HUANG X,PENG Y X. Cross-media Similarity Metric Learning with Unified Deep Networks [J/OL].arXiv:1704.04333 [cs.MM].(2017-04-14).https://arxiv.org/abs/1704.04333.
[5] SONG Y,SOLEYMANI M. Cross-Modal Retrieval with Implicit Concept Association [J/OL].arXiv:1804.04318 [cs.CV].(2018-04-12).https://arxiv.org/abs/1804.04318.
[6] 刘颖,郭莹莹,房杰,等.深度学习跨模态图文检索研究综述 [J].计算机科学与探索,2022,16(3):489-511.
[7] 张翠,周茂杰,杨志清.融合句法依存树注意力的关系抽取研究 [J].广东通信技术,2020,40(10):43-47+71.
[8] LEE K,CHEN X,HUA G,et al. Stacked Cross Attention for Image-Text Matching [J/OL].arXiv:1803.08024 [cs.CV].(2018-07-23).https://arxiv.org/abs/1803.08024.
[9] ZHANG Q,LEI Z,ZHANG Z,et al. Context-Aware Attention Network for Image-Text Retrieval [C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Seattle:IEEE,2020:3533-3542.
[10] WEI X,ZHANG T,LI Y,et al. Multi-Modality Cross Attention Network for Image and Sentence Matching [C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Seattle:IEEE,2020:10938-10947.
[11] DIAO H,ZHANG Y,MA L,et al. Similarity Reasoning and Filtration for Image-Text Matching [J].Proceedings of the AAAI Conference on Artificial Intelligence,2021,35(2):1218-1226.
[12] LU H Y,FEI N Y,HUO Y Q,et al. COTS:Collaborative Two-Stream Vision-Language Pre-Training Model for Cross-Modal Retrieval [C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).New Orleans:IEEE,2022:15671-15680.
作者簡介:张知奇(1996—),男,土家族,湖南常德人,硕士研究生在读,研究方向:深度学习下的图文相似性独立和跨模态检索;通讯作者:袁鑫攀(1982—),男,汉族,湖南株洲人,副教授,博士,研究方向:信息检索、自然语言处理、局部敏感哈希;曾志高(1973—),男,汉族,湖南株洲人,教授,博士,研究方向:机器学习、智能信息处理。
