
一种复杂微服务系统异常行为分析与定位算法
2023-07-01 06:49华庆一南亚会句建国
西安邮电大学学报 2023年1期
王 博,华庆一,南亚会,句建国
(1.西北大学 信息科学与技术学院,陕西 西安 710127;2.西安邮电大学 计算机学院,陕西 西安 710121;3.西安邮电大学 陕西省网络数据智能处理重点实验室,陕西 西安 710121)
当前,随着个人计算[1]向社会计算[2]的发展及工业物联网的兴起,海量的服务赋之云端。通过网络,云计算[3]可以随时随地、便捷地按需使用可配置的计算资源共享池,如服务器、存储、应用软件和服务等模式。云计算的本质就是一切皆服务[4](X as a Service,XaaS),XaaS强调下游对上游按照契约提供服务,隐藏实现细节。随着软件技术的不断发展,软件体系结构[5]从单体结构、垂直结构、面向服务的架构(Service-Oriented Architecture,SOA )到微服务架构[6-7],逐渐趋向于动态、离散和分布,如服务的离散化和集中化或微服务的分散化等。
近年来,人工智能(Artificial Intelligence,AI)技术取得了很大的进展,面向互联网技术(Internet Technology,IT)运营的人工智能[8-10]( Artificial Intelligence for IT Operations,AIOps)在复杂软件系统的运维分析中发挥着巨大的作用,而在复杂软件的智能运维中,根因分析[11-13](Root Cause Analysis,RCA)智能化运维提供了精确的数据基础和故障定位依据。
根因分析的场景大致抽象为搜索定位、指标关联、调用异常和组合分析等几大方向。在搜索定位方面,Hotspot[14]构建了多维时间序列指标的数据立方体,利用蒙特卡罗树搜索(Monte Carlo Tree Search,MCTS)方法对根元素集进行定位,是该多维指标体系中精确高效的异常定位方法。iDice方法[15]解决了关于快速识别发行问题报告中问题产生数量的突然变化的问题。在指标关联方面,Automap模型[16]使用多维时间序列度量动态生成服务关联并诊断根源,根据时间序列之间的异常关联推断出异常行为,并生成描述不同服务之间相关性的图。MicroCause框架[17]可以准确地定位导致微服务故障的根本原因的监控指标。在调用异常方面,Liu等[18]采用无监督异常检测系统,通过重构呼叫轨迹表示,并通过设计具有后向流的深层贝叶斯网络,以统一的方式准确可靠地检测轨迹异常。Cheng等[19]提出了一个基于网络的扩散框架识别和排序显著的因果异常。Brandón等[20]提出了一个基于系统架构的图形表示的根因分析框架。在组合分析方面,Liu等[21]提出了一个可广泛部署的框架FluxRank,其可以自动准确地定位根本原因主机,从而触发某些操作减轻服务故障。Hiranya[22]提出了一种面向根的可扩展体系结构,实现了系统的原型实现和性能异常检测与诊断的统计方法。Wang等[23]利用eBay的生产数据进行部署和评估,帮助运维人员将识别根本原因的时间从几小时减少到几分钟。然而,根因分析依赖于异常检测[24-26],上述方法均未解决在复杂微服务系统中的根据多元日志数据的定位根服务异常问题。
针对根因分析中的搜索定位,以往基于时间序列的异常检测方法主要采用参数估计,如高斯模型、回归模型和混合参数模型[27]。这些模型都需要事先假设数据的分布,而假设的分布往往与实际分布不同,数据的先验分布难以用现有的函数来描述,会与准确的结果有一定的偏差。并且,众多异常检测方法均基于二分类,只能给出异常的结果,不能给出异常的根本原因。文献[28-29]通过极端学生化偏差(Extreme Studentized Deviate,ESD)方法测量了异常程度,并分析了异常的根本原因,但仅解决了简单的单维数据,无法对复杂的非结构化高维数据进行异常检测。因此,针对ESD算法无法处理多元数据的问题,拟提出一种复杂微服务系统异常行为分析与定位(Multivariate Seasonal Hybrid ESD,M.S-H-ESD)算法。该算法先对多元微服务日志的数据进行清洗和标准化处理,获取每一维数据特征的贡献权值,然后加权求和归一为一元数据,采用多元周期混合ESD(Seasonal Hybrid ESD,S-H-ESD)算法度量一元数据的异常度,进而获得异常度最高的服务,通过设置置信度和异常上限,定位微服务系统异常的根因服务。
1 M.S-H-ESD算法
基于多元微服务日志的根因服务异常分析方法主要包含多元数据处理、模型训练和异常评分、模型评估以及故障修复等4个部分,具体过程示意图如图1所示。

图1 服务异常行为分析与定位过程示意图
1)多元数据处理。基于微服务系统的半结构化日志,通过正则表达式或自动抽取工具[34]抽取相关的重要信息,将半结构化的日志信息转变为结构化的数据。对结构化数据清洗和标准化后,提取多元数据的特征值和特征根,求出每一维度数据的贡献度,对多元数据进行加权归一处理。
2)模型训练和异常评分。对获取的服务数据按调用方式分组,对每组服务使用M.S-H-ESD算法计算每个服务为其他服务调用的服务评分。根据设置的阈值得到根服务的异常和定位结果,其中异常得分的上限越高,得到的异常根因服务越紧致,反之得到的异常根因服务越松弛。最后,按照得分结果进行排序,最有可能发生异常的根因服务就在其中,排序愈靠前,发生异常的可能性越大。
3)模型评价。常用的评价指标有准确率、查全率和F1值。准确性是最常见的评价指标,精确度越高,分类器越好,在对非均衡分布数据集的召回率和F1值的应用中,其是更客观地反映分类器在评价方面的指标。
4)故障修复。根据根因服务的异常分析结果进行故障修复,故障修复包括人工修复或系统自愈。
1.1 数据处理
对多元微服务日志数据某一实体属性的研究涉及p个指标,分别用x1,x2,…,xp表示,则p个指标组成的p维随机向量x=(x1,x2,…,xp)T。 设随机向量x的均值为μ,协方差矩阵为Ψ。x的线性变换可以形成一个新的合成变量y,即新的合成变量y可以用原变量线性表示为
(1)
式中,ui=(ui1,ui2…,uip)T是一个线性变换向量,i=1,2…,p。
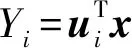
步骤1读取输入,并对输入数据采用minmax方法标准化,将初步处理后的数据记为D。
步骤2利用主成分分析[30](Principal Components Analysis,PCA)模型得到D的协方差矩阵Ψ的特征向量X、特征值θ和方差贡献率υ。
步骤3计算成分得分系数矩阵K。K由得分系数矩阵分量Kij组成,其计算表达式为
(2)
式中:Xij为第i个特征向量的第j个分量;θi为对应的特征值;i,j∈[1,2,…,h],h为属性的个数。
步骤4计算D中每个属性的权重。根据得分系数矩阵K,第i个特征分量权重为
(3)
步骤5返回每一条记录的加权归一化数据,即一元数据为
(4)
当m≤h时,取得的特征值θ从大到小排序后前m个分量满足特征提取要求。
步骤6根据原始数据调用服务和被调服务对一元数据Fi进行分组。
1.2 异常行为分析与定位
在现实世界的数据集中,离群点往往是多个而不是单个的。为了对多离群点检测,需要逐步删除数据集中偏离均值最大值或最小值。设数据集中没有异常值为原假设,记为H0,数据集中有一个异常值为备择假设,记为H1。同步更新相应的t分布临界值检验H0是否成立。利用ESD算法获取一元数据的异常点,具体步骤如下。
步骤1计算均值的数据序列应先删除上一轮最大残差样本数据,均值偏离最远残差的表达式为
(5)
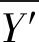
步骤2计算临界值
(6)
式中:n为数据集的样本数;α为置信度。
步骤3对比均值偏离最远残差与临界值大小,若Ri>λj,则原假设H0不成立,该样本点为异常点。
步骤4重复以上步骤k次至算法结束。
ESD算法在处理原始数据的时候,并未考虑微服务日志数据本身具有时间序列的特征,为了更好地提取特征,在原有一元数据的基础上,对数据进行去周期和趋势。
基于Loess的周期趋势分解(Seasonal-Trend Decomposition Procedure based on Loess,STL)将时间序列数据分解为趋势分量、周期分量和余项分量。将ESD算法运用于STL分解后的余项分量中,即可得到时间序列上的异常点,但在余项分量中存在着部分假异常点。为了解决这种假阳性降低准确率的问题,采用中位数(median)替换趋势分量。设原时间序列数据为T,STL分解后的周期分量ST,则残差余项分量的计算表达式为
(7)
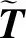
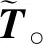
M=median(|Ti-median(T)|)
(8)
将式(8)代入式(7),得到去周期和趋势后的数据为
QT=T-ST-M
(9)
对数据进行去周期和趋势后,采用S-H-ESD算法进行异常服务分析和定位。使用S-H-ESD算法先为所有分组的调用服务和被调用服务获取异常得分矩阵S,然后通过异常得分矩阵S加权获得到每个服务i的异常度得分Gi。
设某调用服务i发生的异常数为a,被调用服务发生的异常数为b,调用服务异常得分为
式中:Si.为所有调用服务为i的异常得分;S.i为所有被调服务为i的异常得分。
由调用服务异常得分Li得到调用服务加权异常得分的表达式为
式中:Ø≥1为调用服务赋以较大权重。
对微服务的异常度得分Gi进行排序,从而获取不同参数下的根因异常服务。
M.S-H-ESD算法具体步骤如下。
步骤1读取结构化日志数据。
步骤2利用式(4)对读取数据进行加权并归一化得到一元数据。
步骤3根据调用服务和被调服务对一元数据进行分组提取。
步骤4将每条数据利用式(5)和式(6)分别计算均值偏离最远残差Rj和临界值λj。若Rj>λj,则H0原假设不为真,采样点为异常点。调整置信度α和异常得分的上限u,会得到不同服务下异常得分的值。记录该所有采样点,即分组的调用服务和被调服务的异常得分矩阵S。
步骤5根据调用服务和被调用服务矩阵的异常得分S,加权得到每个服务的异常度得分Gi。
步骤6对微服务的异常度得分G进行排序,即为获取根本原因异常服务,且异常可能性顺序递减。
2 实验结果与分析
2.1 仿真环境和数据选取
仿真实验采用的环境为64核Intel Xeon platinum 8260 MCPU、40 G内存、Python3.7、Ubuntu18.04 、Cuda 10.2 和Pytorch 1.6.0。
为了验证M.S-H-ESD方法的有效性,选取上证指数周期性明显的某股票2019—2022年的股票交易数据作为实验数据,并对异常数据进行标记。
2.2 异常检测结果评估
在模拟实验中,分别采用K-means、PCA-Q[31-32]统计方法和M.S-H-ESD方法对异常进行检测,并对检测结果的准确性、召回率和F1等指标进行评估对比,结果如图2所示。
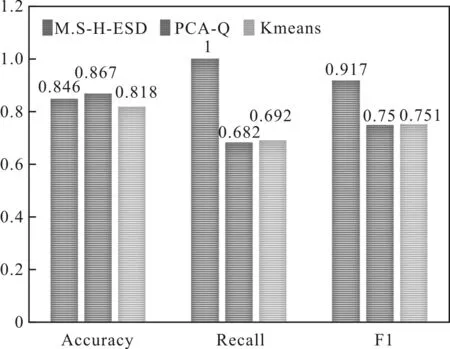
图2 不同算法异常检测评估结果
从实验结果可以看出,M.S-H-ESD方法对于多变量周期数据的异常检测结果优于其他异常检测算法,并在召回率和F1评估上有较大优势,分别高出30%和16%。这是因为,对于时间序列数据,M.S-H-ESD算法考虑了初始阶段的周期和趋势,在提取特征时,首先去除了周期和趋势,凸显了数据特征。
2.3 微服务异常行为分析和定位
2.3.1 数据说明
在复杂微服务系统中,涉及到不同时间序列的服务日志数据,每一个系统的日志数据都需要分别提取。提取日志数据并将其构造为多元数据,主要包括OSB(Oracle Service Bus)、CSF(Common Service Framework)和JDBC(Java Database Connectivity)等调用类型、开始时刻、持续时间、调用服务、被调服务以及CPU占用率、内存占用率和页面缓存等关键性能指标(Key Performance Indicator,KPI)。部分数据的格式和内容如表1所示。

表1 微服务系统中的部分结构化日志数据
2.3.2 微服务根因异常定位仿真结果
微服务调用的数据不能直接用于根服务异常定位。复杂微服务系统的调用结构如图3所示。基于调用服务和被调服务分组数据,使用M.S-H-ESD算法获得每个组服务异常得分值,为分组服务对异常调用得分进行排序,选择前5%作为微服务根因异常的选择对象。

图3 复杂微服务系统的调用结构
利用M.S-H-ESD算法对多元数据处理后,根因异常服务在不同参数的评分结果如表2所示。α和u值越小,需要定位的根因异常服务就越少,反之亦然。因此,根据情况,可以更准确地将较小的参数分配给问题服务。调整异常的置信度α和异常得分的上限u,会得到不同服务下异常得分的值。不同配置参数下根本原因异常得分的折线图如图4所示。从图4中可以看出,异常的置信度α和异常得分的上限u并没有改变异常根因服务评估结果的趋势。

表2 多元数据处理后的根因异常服务在不同参数的评分结果

图4 不同参数下微服务异常评分结果折线图
表2反映了异常根因服务得分和定位结果,其中异常得分的上限u越高,得到的异常根因服务越紧致,反之,得到的异常根因服务越松弛。按照得分结果进行排序,最有可能发生异常的根因服务就在其中,排序愈靠前,发生异常的可能性越大。通过对服务异常的评分排序,可以得到复杂微服务系统的根因异常分析结果,如表3所示。
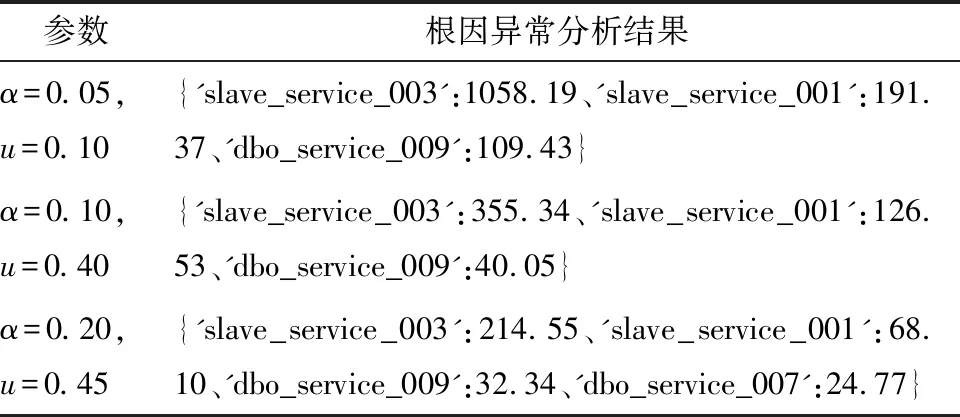
表3 根因异常分析的结果
3 结语
对云平台的微服务运维数据进行提取,利用M.S-H-ESD算法对多元运维数据和测试数据的异常进行得分,得到了微服务系统异常根因服务。实验结果表明,M.S-H-ESD算法对时间序列多维数据的异常行为检测具有较高的精确度、召回率和F1值,能够准确定位微服务系统中的异常服务。
猜你喜欢
中国药学药品知识仓库(2022年9期)2022-05-23
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
商品与质量(2019年34期)2019-11-29
测控技术(2018年5期)2018-12-09
电子技术与软件工程(2017年18期)2018-01-28
小学生(看图说画)(2017年6期)2017-11-06
中国卫生产业(2017年16期)2017-07-20
信息安全研究(2016年4期)2016-12-01
西南军医(2016年5期)2016-01-23
