
基于双向特征金字塔的数据融合目标检测网络
2023-07-01 06:36张浩钧郭建峰张锦忠柴博松侯诗梦张学成
西安邮电大学学报 2023年1期
张浩钧,郭建峰,张锦忠,柴博松,侯诗梦,张学成
(1.上海无线电设备研究所,上海 201109;2.西安邮电大学 经济与管理学院,陕西 西安 710061;3.西北工业大学 软件学院,陕西 西安 710072;4.陆军装备部驻上海地区第三军事代表室,上海 200032)
自动驾驶技术依靠环境感知、人工智能、视觉计算、雷达监控等相关设备自动驾驶车辆。目前,自动驾驶的感知技术利用多传感器,如相机、激光雷达和红外雷达等获取环境信息。在检测任务中,传感器所获取的信息也被称为模态数据,不同的模态数据具备不同的特性。如何准确检测立体场景中的三维目标逐渐成为目标检测任务的研究热点。随着激光雷达的广泛应用,点云数据能够包含检测对象的三维信息,可以得到更为准确的物体空间信息,并且点云数据不受光照影响,立体目标检测任务可以使用激光雷达的点云数据进行检测。
在自动驾驶领域,进行目标检测的算法主要有以下3种思路。
第一,利用图像数据进行检测。例如,采用快速的基于区域的卷积神经网络(Fast Region-based Convolutional Network,Fast RCNN)、更快速的基于区域的卷积神经网络(Faster Region-based Convolutional Network,Faster RCNN)、统一实时目标检测(You Only Look Once,YOLO)、单次多边框检测(Single Shot MultiBox Detector,SSD)等目标检测算法[1-4]对图像数据进行检测。目前,该类方法目标检测的精度和速度均不断提高,但是,由于相机图像数据为二维数据,当应用于自动驾驶领域的检测时,难以获得三维目标的空间定位。一种解决办法是在3D单目(Monocular 3D,Mono3D)[5]网络中依赖图像数据生成深度信息,以补足二维图像数据缺乏的维度信息,然后,凭借补足后的图像数据和深度信息完成检测任务。
第二,利用激光雷达数据进行检测。由于激光雷达数据具有丰富的三维信息,可以根据这点来进行三维目标检测。端到端的点云目标检测网络VoxelNe网络[6]的提出将点云数据进行体素化,根据体素中是否包含目标,将每个体素赋值为1或0,然后,将三维卷积神经网络应用于体素网格。应用于3D分类和分割的点集深度学习(Deep Learning on Point Sets for 3D Classification and Segmentation,PointNet)网络、度量空间中点集的深度分层特征学习(Deep Hierarchical Feature Learning on Point Sets in a Metric Space,PointNet++)网络、点云的3D目标生成与检测(3D Object Proposal Generation and Detection from Point Cloud, Point RCNN)网络[7-9]等算法直接对点云进行处理,并进行点云分类。但是,这种方法更多适用于室内环境等小场景,当应用于自动驾驶的复杂场景中时,检测效果不够理想。基于激光雷达点云的端到端实时三维物体边界检测YOLO 3D模型[10]借鉴二维目标检测思想,将激光雷达数据投影为点云俯视图(Bird’s Eyes View,BEV),在俯视图上进行特征提取,然后,通过三维检测框的方式进行目标分类和位置回归,这种方法较VoxelNet检测速度较快,但是,存在数据利用不充分的缺点。
第三,利用激光雷达数据和图像数据进行融合检测。自动驾驶多模态的3D目标检测(Multi-view 3D Object Detection Network for Autonomous Driving,MV3D)网络[11]首先将激光雷达数据投影为俯视图与前视图;其次,在BEV上生成候选区域,再将候选区域分别映射为3通道红绿蓝(Red Green Blue,RGB) 彩色图像以及BEV与前视图上,进行感兴趣区域的特征提取和特征融合;最后,利用检测网络进行位置回归和目标分类。基于视图聚合的三维建议联合生成和对象检测(Joint 3D Proposal Generation and Object Detection from View Aggregation,AVOD)网络[12]首先利用深度卷积网络分别对三维点云数据的俯视图与二维图像进行特征提取,然后,进行目标分类和位置回归。在多传感器三维目标检测的深度连续融合(Deep Continuous Fusion for Multi-Sensor 3D Object Detection,ContFuse)网络[13]中,将三维点云数据的BEV与图像数据通过连续卷积方式进行融合,形成密集的鸟瞰图数据。相较于MV3D方法,俯视图包含更多信息,然后,针对密集俯视图进行位置回归和目标分类。文献[14]提出点云网络(Frustum Pointnets Network,F-PointNet),采用决策层融合进行检测。F-PointNet网络利用二维目标检测算法对图像数据进行检测,并根据图像的二维检测结果来确定视锥,进而确定目标在点云中的空间位置,回归计算出目标的位置及尺寸。
PointNet算法与PointNet++算法均对原始点云数据进行检测任务,需要占用庞大的硬件计算资源和存储资源,整体网络的计算速度较慢。VoxelNet网络对点云数据进行体素编码处理,检测速度明显优于PointNet算法,然而,在计算过程中需要对空体素块推算,计算速度相对YOLO3D算法较慢。
该文针对单点云数据的三维目标检测算法存在的特征缺失,当存在遮挡目标时,容易出现漏检或误检的情况,以及多尺度目标环境下小目标检测精度低等问题展开研究,拟提出一种基于多源数据融合的多尺度目标检测算法,对YOLO3D的主干网络进行改进,引入压缩-解压网络(Squeeze-and-Excitation Networks,SeNet)方法[15],对图像和BEV特征进行提取并融合,构建双向特征金字塔处理(Feature Pyramid Network,FPN)融合带来偏差的问题,从而达到对立体场景中的车辆等物体进行有效检测的目标。
1 YOLO 3D目标检测网络
作为三维目标检测网络,YOLO 3D网络学习二维目标检测YOLOv2网络,利用二维点云俯视图进行三维目标检测。由于点云数据在空间中不会受到景深的影响,因此,YOLO 3D网络将点云数据投影映射为俯视图,并根据YOLOv2算法的特征提取网络结构,对俯视图特征进行提取,然后,根据三维立体检测框对俯视图特征进行类别确定及位置回归计算。BEV三维特征图及合成图示意如图1所示。

图1 BEV三维特征图及合成图示意
YOLO 3D网络结构示意图如图2所示,从左至右依次为数据输入单元模块、特征提取网络模块、检测向量模块和目标回归计算模块。在特征提取网络模块中,包含特征提取单元卷积层、批量正则化和激活函数(Conv,Batch Normalization,Leaky Relu,CBL)结构块由卷积层Conv,标准化层(Batch Normalization,BN)和激活函数层(Rectified Linear Unit,ReLU)组成。YOLO 3D网络首先计算出点云俯视图的高度特征与密度特征,形成608×608×2的特征图,并将特征图输入DarkNet特征提取网络中,然后,将经特征提取之后的参数转换为38×38×33的检测向量,最后在计算检测向量的过程中,分别求取不同类别目标的检测框及概率。
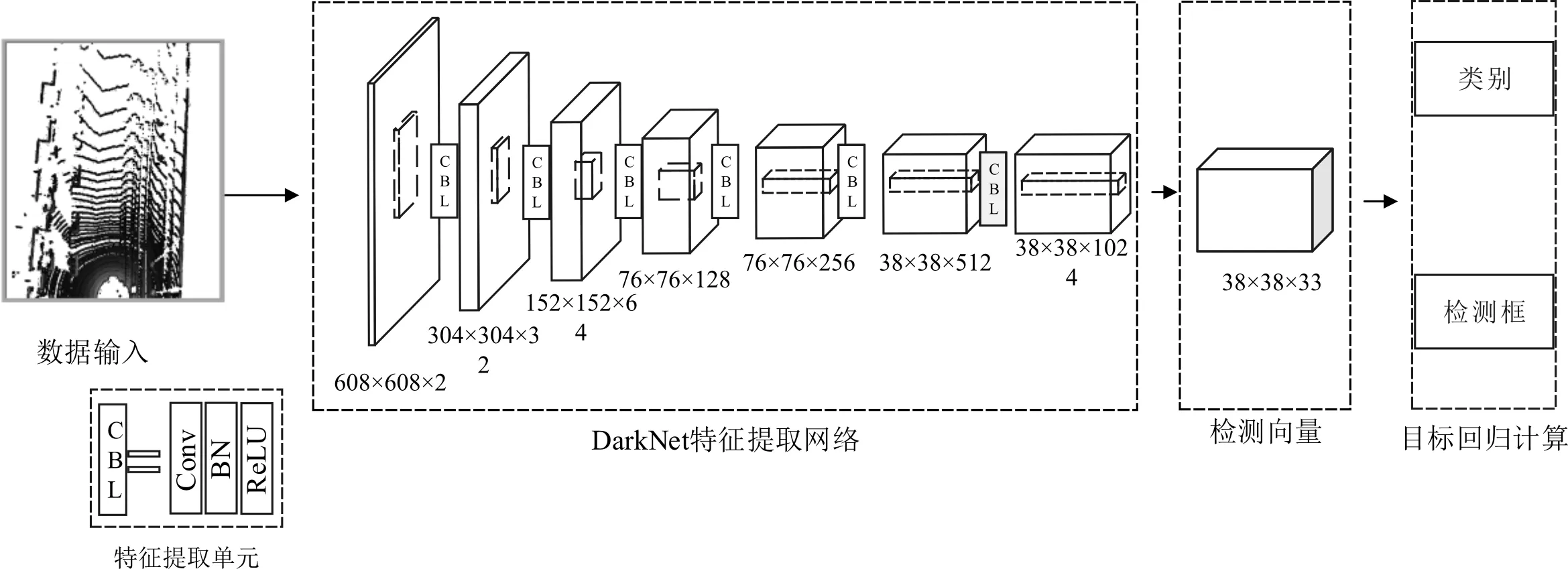
图2 3D目标检测网络结构示意图
2 改进的数据融合目标检测网络
由于雷达点云数据对目标的纹理判断不准确,在遇到遮挡目标时不能够准确检测目标。针对此问题,对于YOLO 3D的单点云检测算法进行改进,构建出一种基于激光点云与图像数据融合,具有注意力残差结构的目标检测网络(ContFuse-SE-ResNet-YOLO 3D,CFSR-YOLO 3D)。
CFSR-YOLO 3D网络利用残差网络结构ResNet[16],使得神经网络在进行特征提取的过程中能够逼近于特征提取前的参数,以避免由于多层次卷积结构所导致的数据丢失和过多参数导致的过拟合情况。采用的ResNet的网络结构示意图如图3所示。对于输入的x,经过两层卷积层处理之后所得到的输出结果为F(x),通过残差结构之后的输出结果为F(x)+x。经过残差短接之后,下层的残差网络结构输入受上层的影响,能够接收原始数据的增益,整体网络在最终计算时,能够综合前向的数据传递,不会因为经激活函数之后的参数过量造成过拟合情况的发生,导致出现无法收敛的情况。

图3 ResNet网络结构示意图
使用残差网络结构对原数据进行提取,能够得到特征处理前的参数回馈,从而改善网络中对于数据的处理变换所造成丢失的情况,使得在神经网络在进行特征提取的过程中,更加贴切所需要提取的数据,以避免多层次的特征提取之后,丧失了对于原数据的特征表达。
2.1 通道注意力残差网络
在YOLO网络中,采用卷积神经网络来进行特征提取,在YOLOv2中采用DarkNet19来进行检测。在VGG16[17]、ResNet101和ResNet152方法中,多采用堆叠网络深度来提高检测效果,在YOLOv3中同样采用了增加网络深度的方式来提高检测。为了提高检测效果,同时,避免带来庞大的计算资源消耗,采用SeNet网络来替代YOLO 3D中卷积神经网络进行特征提取。SeNet是一种具有注意力机制的网络。SeNet网络结构示意图如图4所示。图中,x表示输入,c表示网络的通道数,h表示网络的高度,w表示网络的宽度。对于输入x,首先通过池化层(pooling);其次,经过两层全连接层(Full Connection);再次,通过一个S型(Sigmoid)激活函数获得0~1之间的归一化权重;最后,通过Scale操作将归一化后的权重加权到每个通道的特征上。

图4 SeNet网络结构示意图
对于卷积神经网络,卷积操作的计算核心为卷积算子,是利用卷积核从输入特征图中学习新特征图的过程。从本质上讲,卷积是对一个局部区域进行特征融合,包括从空间上(高度维度h和宽度维度w)以及通道上(通道数c维度)的特征融合。在网络训练学习过程中,若未针对性地对特征进行检测,将会花费大量无效的时间。在训练学习,采用注意力机制能够提高计算中对于相关资源的倾向性[18]。使用空间注意力机制和通道注意力机制[19-20],能够提高神经网络对于有效特征的提取。
空间注意力机制典型网络以空间变形器网络(Spatial Transformer Networks,STN)[21]和动态容量网络(Dynamic Capacity Networks,DCN)[22]代表。以STN为例,在经典卷积神经网络中,显式学习空间中的平移具有不变性,但是,对于大尺度图像而言,并不具备空间平移不变性。而在STN网络中,通过给图片特征施加仿射变换等方式,使得图像特征能够建立起平移不变性、旋转不变性及缩放不变性。在SeNet网络中,通过分配给每个卷积通道之间不同的资源,能够提高有效资源的获取效率。SeNet网络显式地建模特征通道之间的相互依赖关系,通过训练学习的方式来自动获取每个特征通道的重要程度,然后,依照重要程度去增强有用的特征并抑制对当前任务用处不大的特征,从而能够减少整体网络训练学习的错误率,并且提高检测的准确性。
2.2 激活函数的优化
由于ReLU函数的简单性和直接性,目前的卷积神经网络中多采用ReLU函数作为激活函数来使用。当堆叠深层网络时,神经元需要传递的参数较多,ReLU的门限函数使得当前神经元的值为负数时,梯度不再进行传递,出现神经元“死亡”的情况。而Swish函数具有无上界、有下界、平滑、非单调的特性,并且在深层次的网络中不会出现ReLU函数的神经元“死亡”情况。
针对ReLU激活函数在神经网络中易导致神经元“死亡”的问题,使用Swish激活函数对通道注意力残差网络SE-ResNet中的ReLU函数进行替换。尽管会因此加深网络结构深度,但是,在深层神经网络中使用Swish激活函数并不会发生神经元“死亡”的情况。Swish函数中的超参数β可以通过网络训练进行自适应学习,能够更加泛化地模拟神经网络的非线性情况,以提高网络鲁棒性。改进激活函数后的通道注意力残差网络Swish-SE-ResNet网络结构示意图如图5所示。对于输入的x经过卷积操作(Conv)和标准化处理(Batch Normalization,BN)后分层处理,然后把处理后的结果进行融合操作。

图5 Swish-SE-ResNet网络结构示意图
3 基于数据融合的目标检测网络
为了适应在三维目标检测任务中多样化的场景和多尺度目标,进一步对改进的YOLO 3D端到端目标检测网络进行调整,搭建CFSR-Bi-YOLO 3D多尺度数据融合目标检测网络。根据不同大小和尺度目标的检测要求,将多源数据的融合过程进行多层次增强,并调整对不同尺度目标的检测框,通过分层检测的方式检测不同大小的目标。
3.1 构建双向特征金字塔
根据FPN的分层理念,检测网络对不同的目标采用不同尺度的检测,并综合高维度与低维度的特征,将高维度的特征经过上采样之后融入低维度特征中,让低维度特征在进行检测的同时接收到高纬度的语义信息,最终完成检测任务。但是,FPN结构仅采用了一次高维度向低维度的扩张,并且在进行不同维度特征间融合时,使用均值的方式进行融合,这对不同特征而言,融合之后会带来一定的偏差。
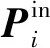
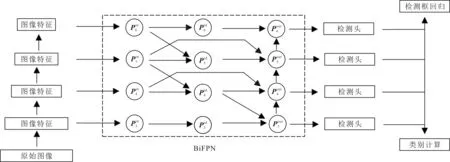
图6 BiFPN网络结构示意图
为应对FPN的均值融合存在的问题,将不同维度特征在融合过程中施加不同的偏置,从而使得融合之后特征能够根据检测任务的重点,学习对不同融合特征的倾向,以实现更高级的特征融合。以第5层特征图为例,第5层特征金字塔中的特征融合结果和输出特征图的计算表示式分别为
(1)
(2)
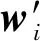


(3)

(4)
3.2 数据预处理
提出的目标检测网络所使用数据集为KITTI数据集[23-24]。该点云数据集通过激光照射到物体表面获取对目标的距离信息的坐标以及反射强度值。对于数据进行如下处理。
首先,将投影点云离散成一个分辨率为0.1 m/pixel的网格。对于每个单元格而言,高度特征被计算为该单元格点的最大高度,强度特征为每个单元中具有最大高度的点的反射率值,密度特征为每个单元中点的数量。然后,将高度特征、强度特征与密度特征合成为BEV图像,高度特征、强度特征与密度特征分别为BEV图像的不同通道,处理后的图像示意图如图1所示。其中,高度特征为每个单元格中点云的最大高度值;强度特征是在每个单元格位置取得点云反射强度的最大值,并归一化到0~255之间。
对密度特征而言,由于点云分布特点是近多远少,导致在近处单元格中点云数量分布较多,远处的单元格点云数量分布较少,需要采用归一化处理,归一化后的密度值为
(5)
式中,N为单元格中点云的数量。
3.3 多源数据多层次融合
在原YOLO 3D三维目标检测方法中,将点云数据投影为俯视图。该处理方法对于数据的利用不够充分,为了使得激光雷达数据与图像数据有效融合,采用连续卷积融合方案,输出信息数据更加丰富的俯视图特征。
多源数据融合根据融合过程发生在不同的阶段可分为特征层融合、决策层融合和混和阶段融合等3种情况。由于激光雷达数据与图像数据具有一定相关性,文中采用的融合策略为特征层融合。根据连续卷积融合方案,首先,构建两个学习流,采用SeNet网络分别从图像和BEV中提取特征;其次,通过深度参数连续卷积[25]将不同分辨率的图像和BEV特征图进行融合;最后,利用改进之后的YOLO网络对融合后的特征进行三维目标检测。整体网络结构及处理示意图如图7所示。
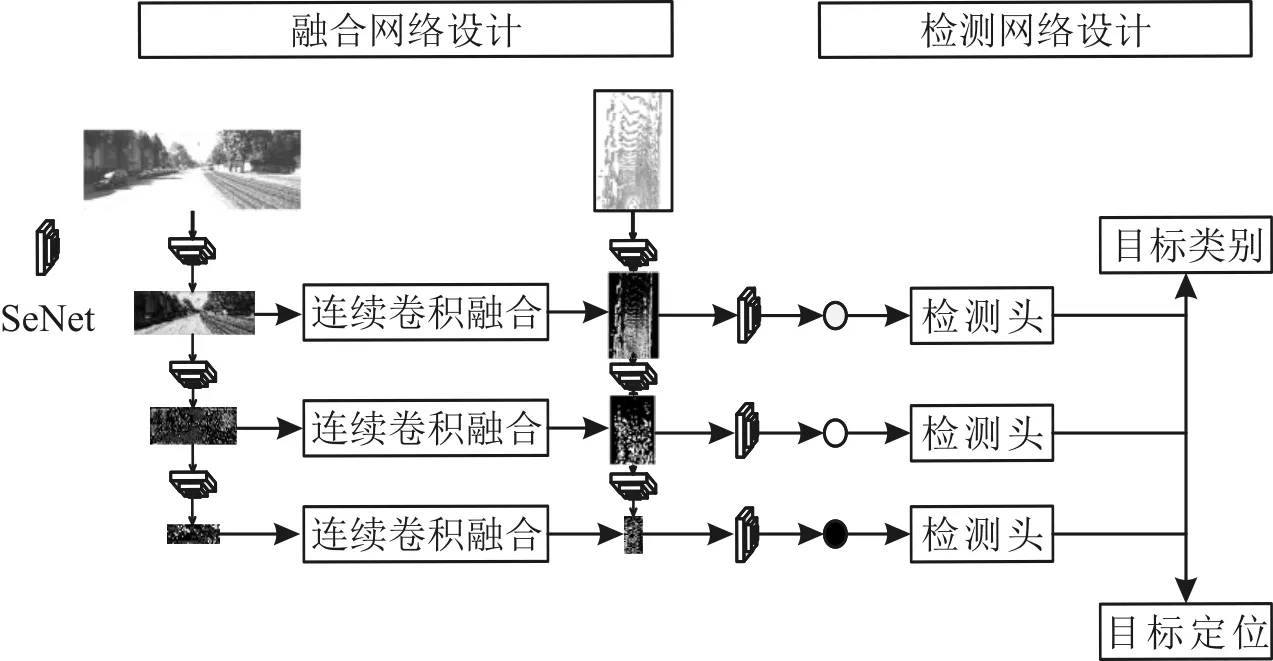
图7 整体网络结构及处理示意图
参数连续卷积是一种可以处理非网格结构数据的深度学习网络。参数连续卷积将标准的网格结构的卷积扩展到非网格结构的数据,同时保持高容量和低复杂度。其关键思想是利用多层感知器(Multi-Layer Perception,MPL)作为参数化核函数进行连续卷积。该参数化核函数跨越了整个连续域。此外,利用有限数量的相邻点上的加权求和来近似原本计算上禁止的连续卷积。
每个邻居根据其关于目标点的相对几何偏移量进行不同的加权。具体而言,假设点j在点i的邻居上建立索引,则点i处的连续卷积特征可以表示为
(6)
式中:MPL(·)表示多层感知器操作,其计算点i每个邻点处的卷积权值,对每个邻点处的卷积权值进行求和;xi表示点i的坐标信息;xj表示点i相关联的的邻居点j的连续坐标信息;fj表示点j的输入图像特征。
参数连续卷积的优点是,利用标准卷积的概念从邻近观测中捕获局部信息,而不需要可能导致几何信息丢失的栅格化阶段。对每个点云的点而言,MLP的输入包含两部分:一部分是通过将源激光雷达点投影到图像平面上,提取出相应的图像特征,然后利用双线性插值法得到了连续坐标下的图像特征;另一部分是激光雷达点和目标像素之间的三维相邻偏移。总体而言,对于每个目标像素,MLP操作通过对其所有相邻像素的MLP操作的输出进行求加来输出一个多维输出特征。MLP的输出特征通过元素方面的总和与前一层的BEV特征相结合,以融合多传感器信息。可以将点i处的多维输出特征可以表示为
(7)
式中,xi-xj为点j与目标点i的三维偏移。
参数连续卷积融合计算过程示意图如图8所示。

图8 参数连续卷积融合计算过程示意图
图8中,参数连续卷积融合计算的计算步骤如下。
步骤1针对BEV图像的目标像素,提取K个最近的雷达点。
步骤2将BEV图像的目标像素和K个近邻点映射在三维空间中。
步骤3将三维空间的BEV图像目标像素与K个紧邻点,投影在图像坐标系下。
步骤4找到BEV图像的目标像素对应的图像特征及三维偏移。
步骤5将图像特征与连续几何偏移输入MPL中,生成目标像素特征。生成稀疏俯视图和密集俯视图对比如图9所示。可以看出,密集俯视图提取到更多细节目标信息,目标特征更加明显。

图9 稀疏俯视图和密集俯视图对比
利用通道注意力残差提取单元SeNet对图像特征和点云俯视图特征进行分流特征提取,提取后的特征向量为76×76×256维度、38×38×512维度和19×19×1 024维度等3种维度。将多源数据特征进行多层次融合的步骤如下。
步骤1读取KITTI数据集所提供的配准文件中的坐标系转换矩阵与偏移矩阵。
步骤2计算投影矩阵。投影矩阵计算公式为
Pvelo_to_im g=Prect_02Rrect_00(R|T)velo_to cam
(8)
式中:Prect 02为3×4矩阵,表示投影矩阵,从矫正后的0号相机坐标系投影到2号坐标系的图像平面;Rrect 00为3×3矩阵,表示矫正0号相机的偏移矩阵;(R|T)velo to cam为3×3矩阵,表示从雷达点云坐标系向0号相机坐标系的转化矩阵。
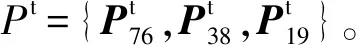

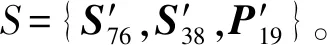
(9)
式中,Pvelo_to_img表示3×3的点云投影图像矩阵。
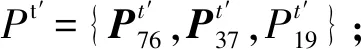
(10)
式中:n表示特征层层级数;MLP操作表示多层感知器操作,即连续卷积网络中的全连接的核函数计算过程,MLP操作将空间点所对应图像的特征相结合。
4 实验与分析
4.1 实验对象与条件
实验对为KITTI目标检测数据集。KITTI数据为激光雷达点云数据和图像数据,其中,点云数据集是由Velodyne 64线激光雷达获取的点云数据集,共包含7 481个训练集数据和7 518个测试集数据。训练集中用作训练及评估的比例为80∶20,其中的20%用作训练过程中的评估验证。根据KITTI数据集中对于交并比(Intersection over Union,IoU)的规范,设定所属目标中汽车的IoU为0.7,行人和骑行者IoU为0.5。点云文件被裁减到以激光雷达为原点,横纵坐标分别为[-40,-40]×[0,70] m的范围内。在三维目标检测任务中,KITTI数据集为每个场景中的每个可识别目标提供了三维目标检测框的标注。
实验使用Ubuntu 16.04系统,采用Pytorch 1.3.0 深度学习框架,CPU为 Intel(R) Xeon(R) Silver 4110,GPU为Quadro P5000,开发工具为Pycharm+Anaconda,Python版本为3.6。训练阶段初始学习率调整为0.01,训练迭代次数epoch设定为200次。
同场景下二维、三维及点云目标检测示意图如图10所示。其中,图10(a)为检测目标在图像中的二维检测框位置;图10(b)为检测目标在图像中三维检测框的位置;图10(c)为检测目标在点云数据下的三维检测框信息,图10(c)中方框为根据标注信息所绘制。可以看出,点云目标的空间信息更为准确,且不易受透视遮挡的影响。
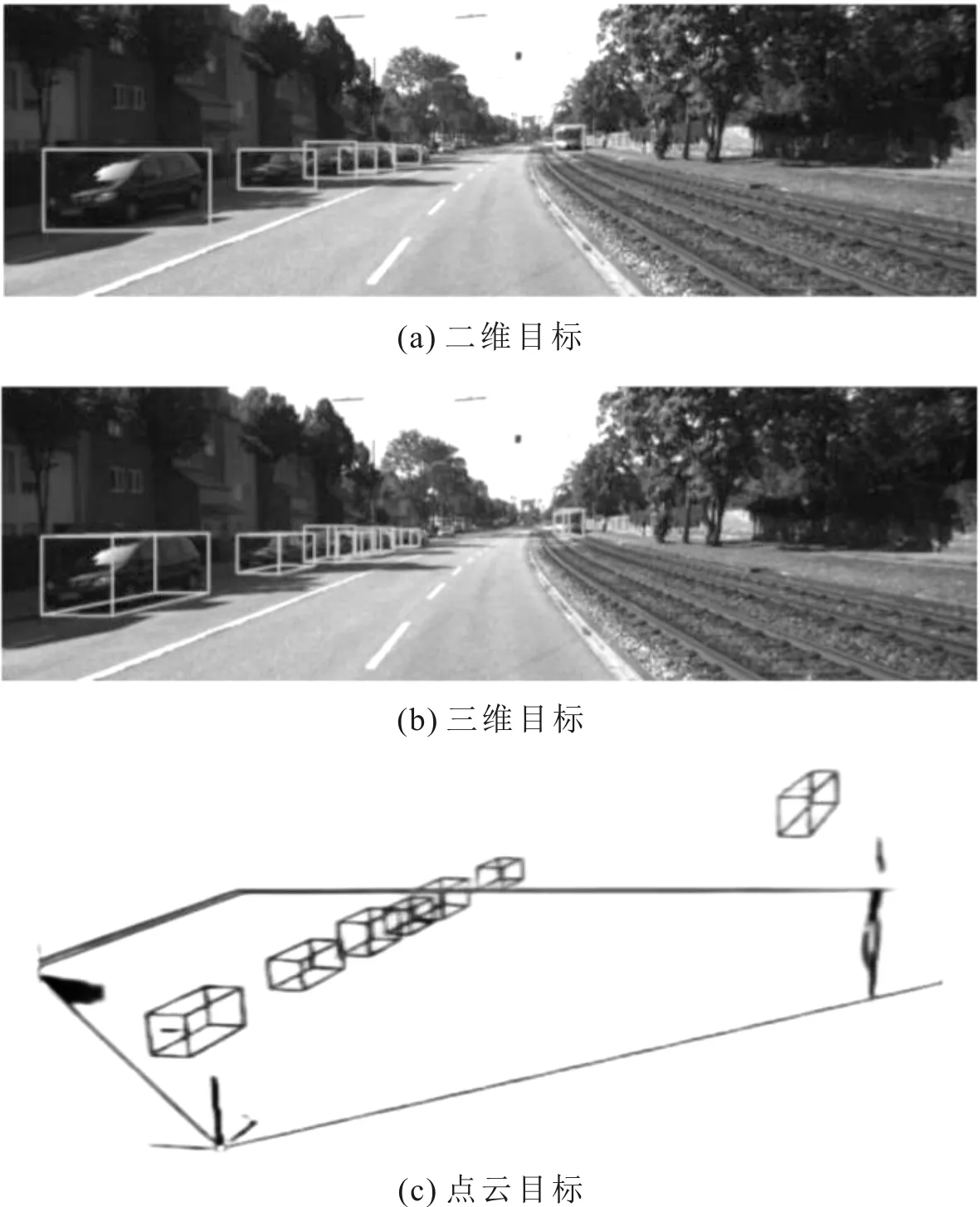
图10 同场景下二维、三维及点云目标检测示意图
4.2 评价指标
目标检测的评价指标为目标三维检测精度和目标俯视图检测精度。评估检测结果的指标为平均精度(Average Precision,AP),AP值的计算方式为检测网络输出的检测准确率与召回率曲线(Precision Recall,P-R)曲线与坐标轴所构成的积分值。准确率的计算与样本中所有检测准确的数量有关。召回率Recall与所有真实检测物体的数量有关。准确率PA和召回率PC的计算公式分别为
(11)
(12)
式中:PT表示检测为正确,真实为正确的案例;PF表示检测为正确,真实为错误的案例;NF表示检测为错误,真实为正确的案例;NT表示检测为错误,真实为错误的案例。
4.3 消融实验
在将端到端的目标检测网络延伸至三维目标中,针对三维目标检测中不同尺度间目标维度差别过大,小目标难以检测的问题,在网络结构中利用残差网络结构与双向特征金字塔结构。将经典的特征金字塔结构网络的单向数据流动方式改为双向数据流动方式,构建了CFSR-Bi-YOLO 3D网络。为了验证所提网络CFSR-Bi-YOLO 3D数据融合目标检测网络中每个模块的有效性,分别进行消融实验对比,通过消融实验验证每一个模块对于所提方法的贡献。
记录检测网络对汽车(Car)、骑行者(Cyclists) 和行人 (Pedestrians)等3类目标不同模块的3D平均精度和俯视图平均检测精度(不同模块的三维目标和俯视图目标的检测平均精度,是指各类别精度的平均值),并统计检测速率。不同模块三维目标检测平均精度对比结果及不同模块俯视图目标检测平均精度对比结果分别如表1与表2所示。其中:“+Res”表示引入残差结构;“+SE”表示引入通道注意力;“+BiFPN”表示引入BiFPN结构;“+Swish”表示引入Swish激活函数;FPS表示每秒内算法所能够检测帧的数量。
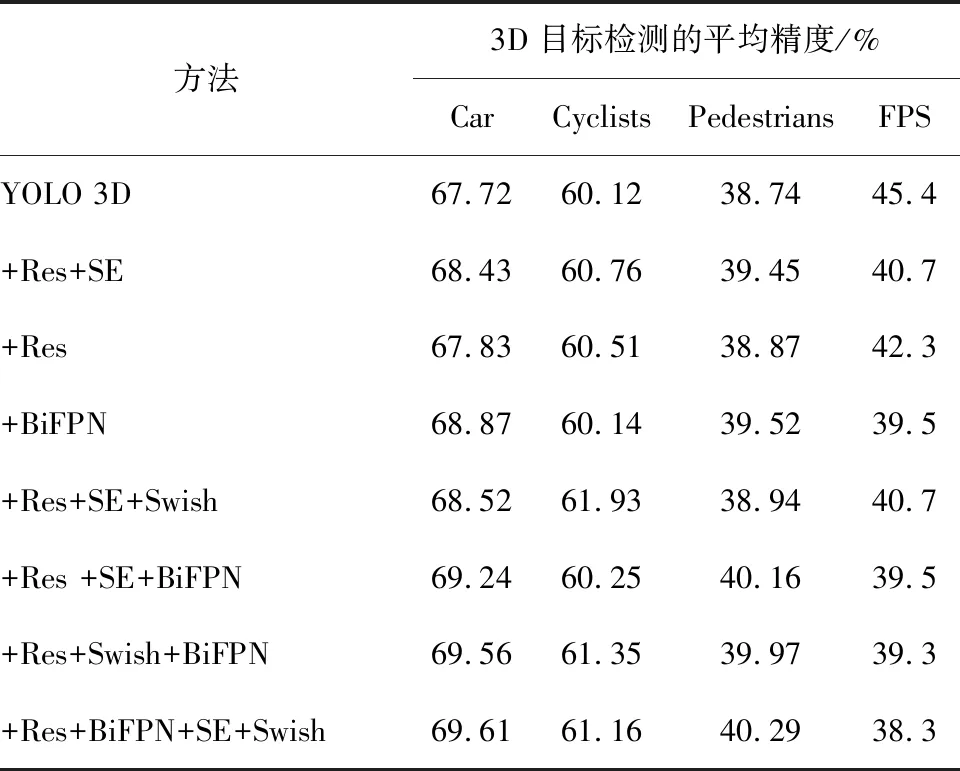
表1 不同模块三维目标检测平均精度对比结果
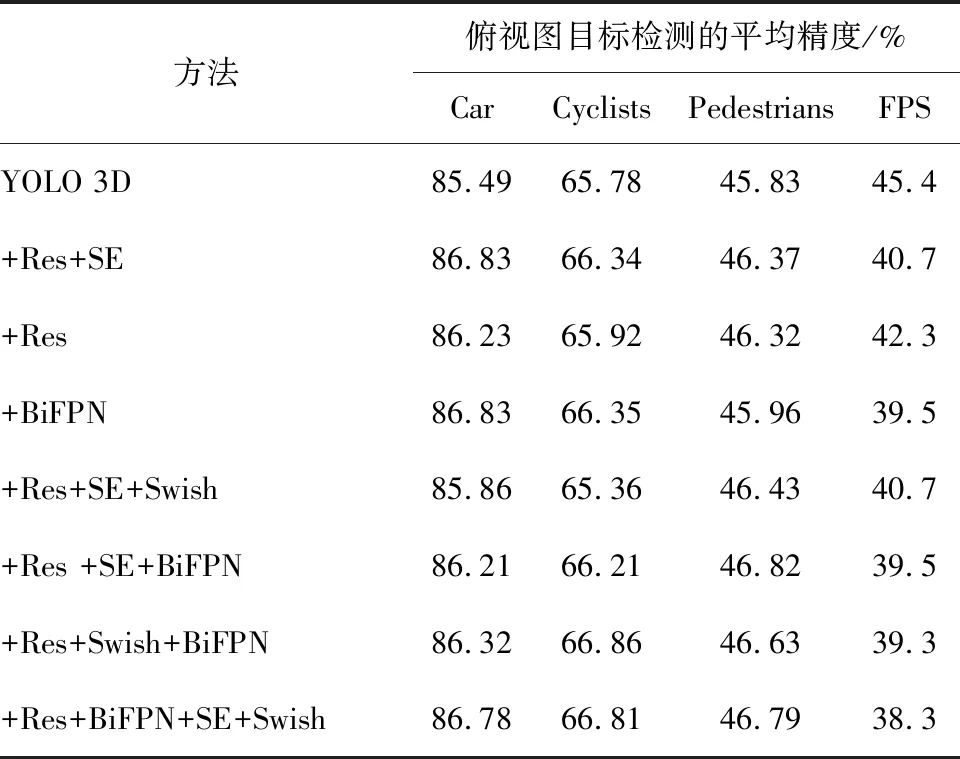
表2 不同模块俯视图目标检测平均精度对比结果
从表1和表2可以看出,使用残差结构与BiFPN结构可以提高三维目标检测网络中小目标检测准确率,三维目标检测的小目标准确率提升2%,俯视图目标检测的小目标准确率提升1%。这是因为,采用该方法可以将图像特征与点云特征进行分流提取和分层融合,利用双向特征金字塔结构增强融合不同维度特征,并划分不同单元对多尺度目标进行检测。BiFPN结构在不同维度下的特征相互传递过程中,将高维度特征的语义信息通过上采样向低维度特征传递,将低维度的定位信息利用下采样的方式传递给高维度特征,能够在原单一维度特征基础上,综合来自不同维度的特征,让图像不同维度特征获得更加丰富的表达。
4.4 不同检测方法对比
在消融实验之后,采用不同方法对数据集中的二维目标、三维目标及点云目标等3类目标的立体检测精度和俯视图中目标的检测精度分别进行试验对比。不同模块的三维目标和俯视图目标对比实验结果分别如表3和表4所示。

表3 不同方法三维目标检测平均精度对比结果

表4 不同方法俯视图目标检测平均精度对比结果
由表3和表4可以看出,所构建的CFSR-Bi-YOLO 3D数据融合目标检测网络,较YOLO 3D网络的三维目标检测所有类别平均精度提升1.46%,俯视图目标检测所有类别平均精度提升1.01%;较单图像源Pseudo-LiDar检测算法的三维目标检测所有类别平均精度提升13.9%,俯视图目标检测所有类别平均精度提升18.29%。有效地改善了YOLO 3D网络对遮挡目标检测困难的问题,这是因为,多源数据较单一源数据对目标的表征更加丰富且准确。
另外,采用MV3D、AVOD、VoxelNet、YOLO 3D和所提出的CFSR-Bi-YOLO 3D等5种不同方法对密集遮挡场景中的小目标场景进行检测,其中,MV3D算法将点云数据与图像数据进行区域融合;AVOD算法对点云数据与图像数据所形成不同特征流下的特征结果进行融合;VoxelNet算法采用点云体素化端到端的检测方式。不同方法对密集场景目标检测结果如图11所示。

图11 不同方法对密集场景目标检测结果
在图11(a)、图11(b)、图11(c)、图11(d)和图11(e)中,左图为点云场景的检测结果,右图为对应的真实场景。图11中的左图矩形框表示根据目标特征或分类信息,自动判断该区域存在目标。由图11可以看出,所提出的CFSR-Bi-YOLO 3D算法可以检测到更密集的目标,能够准确检测出密集小目标。与融合算法AVOD网络及点云检测网络VoxelNet算法相比,设计的融合检测算法,能够更加准确地检测出密集小目标;与经典YOLO3D网络相比,所提方法利用多源信息融合多尺度实施检测。能够更好地检测受遮挡小目标。
5 结语
提出一种CFSR-Bi-YOLO 3D数据融合目标检测网络方法。该方法通过将激光雷达点云与图像相结合,以减少单一数据源对目标检测准确率造成的影响。在对不同尺度目标检测中,将图像特征与点云特征进行分流特征提取,形成多层次融合结构,以提高系统的可靠性。通过引入通道注意力,以及SeNet残差网络,以提高网络的特征提取能力。另外,通过设计了一种基于双向金字塔结构的多尺度的数据融合方式,根据分层结构调整网络的先验框,以满足不同尺度目标的检测要求,相比于FPN结构仅采用了一次高维度向低维度扩张的方式,减少了不同特征融合之后带的偏差。
实验结果表明,所提出多尺度目标检测算法,与MV3D算法、AVOD算法、VoxelNet,以及单点云检测网络YOLO 3D等检测方法相比,对于三维目标和俯视图目标的平均检测准确率均有所提高,说明提出的基于双向特征金字塔的多尺度数据融合目标检测网络能够有效提升中小目标的检测准确率。研究的结果可以为自动驾驶的目标检测任务提供借鉴。
但是,随着卷积层数的增加,所提方法的计算量变大,导致模型的速度降低,不利于自动驾驶过程中对道路目标的实时检测。为此,在后续的过程中,还需要进一步加强对更轻量级网络的研究,以满足自动驾驶目标检测对于准确性和实时性的要求。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
中华诗词(2019年7期)2019-11-25
电子制作(2019年11期)2019-07-04
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2017年11期)2017-04-04
灯与照明(2016年4期)2016-06-05
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01
噪声与振动控制(2015年4期)2015-01-01
电视技术(2014年19期)2014-03-11
