
基于全息图平稳分布因子的离群点检测算法
2023-07-03 14:11张忠平张玉停张睿博
计算机应用 2023年6期
张忠平,郭 鑫,张玉停,张睿博
(1.燕山大学 信息科学与工程学院,河北 秦皇岛 066004;2.河北省计算机虚拟技术与系统集成重点实验室(燕山大学),河北 秦皇岛 066004;3.河北省软件工程重点实验室(燕山大学),河北 秦皇岛 066004;4.武汉理工大学 国际教育学院,武汉 430070)
0 引言
离群点检测旨在从数据集中发现异常数据,是数据挖掘技术领域研究的热点问题之一。离群点的定义是指与其他数据点明显不同的数据点或不符合预期行为的数据点[1]。离群点检测在很多方面都有着重要的研究意义,如信用卡欺诈检测[2]、网络入侵检测[3]、故障诊断[4]、图像处理[5]等。目前,离群点检测方法主要分为以下几个大类:基于统计的方法[6-8]、基于距离的方法[9-11]、基于密度的方法[12-14]和基于图的方法[15-17]。
基于统计的方法的基本思想是在识别离群点时取决于数据的分布模型。该方法分为两大类:一类是参数方法,这是一种假设有底层分布模型的方法,常用的两种检测模型是高斯混合模型和回归模型;另一类是非参数方法,这是一种使用核密度估计(Kernel Density Estimation,KDE)[18]的方法。
基于距离的方法的基本思想侧重于数据之间的距离计算,若一个点距离其邻居点很远,则被视作为离群点。Knorr等[19]最早对基于距离的方法进行了研究并定义了基于距离的离群点,此方法适用于中到高维的大数据集,与基于统计的方法相比,此方法具有更强的健壮性、灵活性和更高的检测效率。
基于密度的方法的基本思想是在低密度区域找到离群点,在密集邻域内找到内部点。此方法将数据点的局部密度与其邻域密度进行比较,刻画数据点的离群程度,进而检测离群点。最为经典的基于密度的方法是Breunig 等[20]提出的局部离群因子(Local Outlier Factor,LOF)算法。该算法利用k近邻,在每个点的k近邻域中,利用局部可达密度与其k近邻域内的平均可达密度进行比较得出离群点。
基于图的方法的基本思想是使用图技术有效地捕获数据点间的相互依赖性,从而识别离群点。基于图的方法能够对各种类型的数据提供一个健壮的表示,同时还能够有效地捕获数据隐含的内部连接模式,因此此类方法吸引了很多学者的关注。该方法的检测过程可以概括为两个步骤:首先将每个数据点都看作图中的一个节点,并将整个数据集以图的形式表示;然后从图中提取转移概率矩阵进行马尔可夫随机游走,利用生成的平稳分布检测离群点。Moonesinghe 等[21]提出OutRank,这是一种基于图的离群点检测算法,此算法用两种方式构建数据的图形表示,分别是基于数据点的相似性和基于数据点共享邻居的数量;然后在构建的图上进行马尔可夫随机游走,通过最终的平稳分布检测离群点。此算法只考虑了数据对象的全局信息,没有考虑数据对象的局部信息,导致它在一些数据集上检测效果不佳。Wang等[22]考虑到大多数基于图的方法忽略了每个数据点周围的局部信息,提出了一种新的离群点检测模型,将图形表示和每个数据点周围的局部信息相结合,构建局部信息图,并通过在图上进行随机游走计算离群分数,但会出现随机游走提前结束的情况,文献中针对这种情况提出了两种不同类型的重启向量来解决“悬空链接”问题,不仅避免了随机游走提前结束,还提高了算法的检测性能。
基于图的离群点检测方法通常将重点放在构造转移概率矩阵上,一个好的转移概率矩阵不仅能刻画每个数据点的全局信息,也能捕捉数据点的局部信息。传统的基于图的方法在构造转移概率矩阵时使用数据的整体分布特征,由于忽略了数据的局部信息,导致检测精度不高;使用数据的局部信息时,又可能出现“悬空链接”问题。针对上述问题,本文提出了基于全息图平稳分布因子的离群点检测算法(Outlier Detection algorithm based on Hologram Stationary Distribution Factor,HSDFOD)。算法首先使用相似度矩阵自适应地获取每个数据点的邻居集合,进而构造局部信息图;然后引入最小生成树构造一个全局信息图,使用全局信息图不仅能够考虑数据点的全局信息,同时能有效避免“悬空链接”的问题;最后综合利用局部信息图和全局信息图融合为全息图构造转移概率矩阵进行马尔可夫随机游走,通过生成的平稳分布检测出离群点。
1 相关定义
马尔可夫链上的随机游走是基于图的离群点检测方法常用的概率学模型。
定义1 马尔可夫链。给定一个随机变量的序列X={x0,x1,…,xt,…},其中xt表示t时刻的随机变量且每个xt的取值集合相同。当t>1 时,如果xt只依赖于xt-1,不依赖过去的其他随机变量{x0,x1,…,xt-2},即满足条件概率分布:p(xt|xt-1,xt-2,…,x0)=p(xt|xt-1),该性质被称为马尔可夫性。存在马尔可夫性的随机变量的序列称为马尔可夫链或马尔可夫过程。
定义2 转移概率矩阵P。设pi,j表示马尔可夫链中从节点i转移到节点j的概率,则对于一个包含n个数据点的马尔可夫链,其转移概率矩阵表示为P,定义如式(1)所示:
定义3 平稳分布。马尔可夫随机游走最终会趋于一个稳定的状态,即访问每个数据点的概率不再发生变化,这个概率向量分布称为平稳分布π=[π(1),π(2),…,π(n)],π为一个n维的向量,每个分量表示对应节点被访问的概率,且=1。通过不断的迭代,最终会生成一个平稳分布,迭代过程如式(2)所示:
为更加清晰地描述马尔可夫随机游走过程,下面给出一个在有向图上进行马尔可夫随机游走过程的具体实例。
如图1所示,给定一个由3个节点组成的转移概率图,可见每个节点不仅有转移到其他节点的边,还有从其他节点转移到该节点的边。有向图的边上的权重表示从一个节点转移到另一个节点的概率,因此一个节点上所有出度边上的权重和为1。

图1 3个节点之间的状态转移Fig.1 State transfer among three nodes
根据图1 生成对应的转移概率矩阵P的具体定义如式(3)。利用矩阵P,进行如式(2)的迭代。其中,初始分布为π0=[0.21,0.68,0.11],在迭代十几次后,平稳分布最终会收敛,得到最终的平稳分布π=[0.286,0.489,0.225]。实际上,根据马尔可夫链的特性,初始分布的概率分布不会影响最终生成的平稳分布。
2 本文算法
基于马尔可夫随机游走进行离群点检测算法的核心是构造转移概率矩阵。一个好的转移概率矩阵能较为准确地刻画数据的分布特征。经典的构造转移概率矩阵的方法是构造一个全局连通图,但由于忽略了数据点的局部信息,导致检测精度不高。之后改进的方法通过构造虚拟节点或重启向量获取数据点的局部信息,但检测结果容易受到k值的影响。针对上述问题,本文提出基于全息图平稳分布因子的离群点检测算法(HSDFOD),综合考虑数据点的局部和全局信息,并使用一种自适应k值的方法避免输入参数,提高算法的检测精度和增强健壮性。
2.1 HSDFOD思想
HSDFOD 首先通过一种自适应k值的方法获取每个数据点的局部邻域信息,使内部点的邻居个数多于离群点的邻居个数,根据数据点的邻域信息构造局部信息图;然后为获取数据点的全局信息,利用最小生成树生成一个全局信息图,最小生成树中每条边对应全局信息图中两个有向边,且两个有向边的转移概率相同,该全局信息图不仅能获取数据的全局分布信息,而且还能避免“悬空链接”问题;最后融合局部信息图和全局信息图为全息图构造转移概率矩阵,利用该转移概率矩阵进行马尔可夫随机游走,通过不断迭代,将生成的平稳分布中各个分量视为数据点的平稳分布因子,进而刻画数据点的离群程度。
2.2 HSDFOD定义
定义4 相似度函数。给定数据集X={x1,x2,…,xi,…,xn},i=1,2,…,n,xi∈Rd,对于xi,xj∈X,它们的相似度函数计算如式(4):
其中‖xi-xj‖为xi和xj之间的欧氏距离。式(4)使用的是高斯核密度公式计算两个数据点的之间的相似性,δ为核函数的带宽,计算方法如式(5):
其中 |V|是数据集包含的数据点数。
定义5 相似矩阵S。使用式(4)计算数据集中每两个点之间的相似度,进而得到整个数据集的相似矩阵ST=S,定义为式(6):
定义6 局部邻居集合。数据点xi的局部邻居LN(xi)的定义如式(7)所示。由式(7)可知将相似度大于阈值εi的点视为该数据点的邻居点。
其中εi为数据点xi的自适应阈值,定义如式(8):
其 中:μi为集合{sim(xi,x1),sim(xi,x2),…,sim(xi,xn)}的期望;σi为该集合的标准差。
从式(7)(8)可见数据点的局部邻居集合和k近邻集合类似,都是获取与数据点最相似点的集合,但与k近邻集合相比,局部邻居集合有以下两个优势。
1)局部邻居集合通过自适应k值的方式生成数据点的邻居集合,无需输入参数,从而提高算法在面对不同数据集的健壮性和稳定性。
2)每个数据点的邻居个数不同,但总体上内部点能获取更多的邻居点,而离群点获取较少的邻居点。
如图2 所示,P1点位于稀疏区域,可将该点视为离群点,P2~P9点位于稠密区域,可将这些点视为内部点。使用局部邻居的概念计算P1点的邻居集合为LN(P1)={P2,P9},P3点的邻居集合为LN(P3)={P2,P4,P5,P6,P7}。可以看出P1点和P3点的邻居个数不同,而且内部点P3有更多的邻居点。离群点P1仅有两个边缘点作为邻居点。因此,使用局部邻居集合不仅可以避免外部输入参数确定邻居个数的问题,而且能让稠密区域的点拥有比稀疏区域更多的邻居个数。
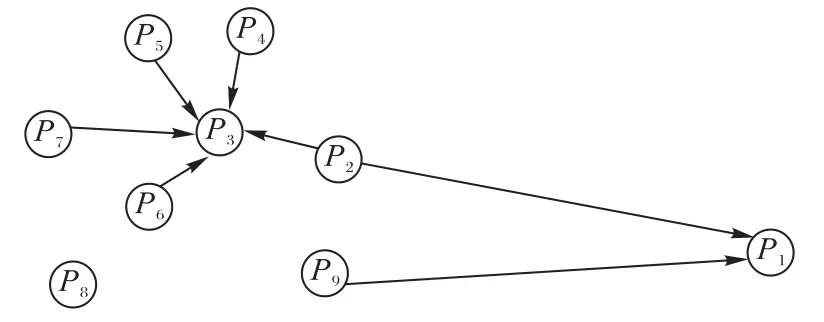
图2 局部邻居集合示例Fig.2 Example of a local neighbor set
定义7 局部信息图WLIG。局部信息图刻画数据点的局部信息,定义如式(9):
其中:S是定义5 中的相似矩阵;运算符∘为哈达玛积,即矩阵对应元素直接相乘;N是0-1 矩阵,即矩阵元素只有0 和1。N定义如式(10):
对于数据点xi,只有其局部邻居集合中的点在局部信息图中才有相应的权重。由于局部邻居集合的特性,局部信息图中内部点之间连接的紧密程度远高于离群点和内部点的连接,表现在局部信息图上为内部点对应行有更少的0 分量,因此,利用局部信息图可以准确地刻画数据的局部信息。
但仅使用局部信息图对应的转移概率矩阵进行马尔可夫随机游走会出现“悬空链接”问题,下面简要介绍“悬空链接”问题产生的原因。如图3 所示,B、C和D点为内部点,A点为离群点。
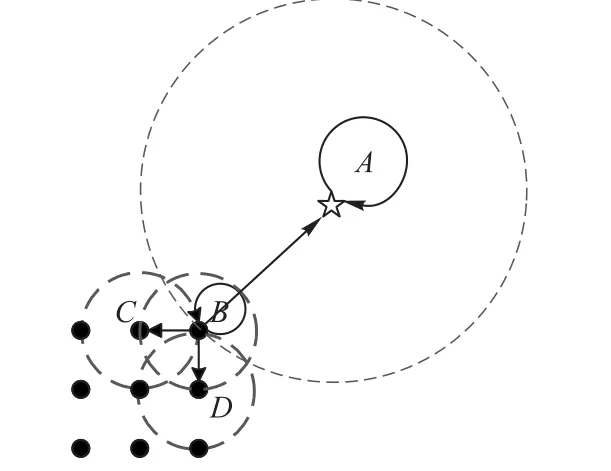
图3 悬空链接问题Fig.3 Suspended link problem
内部点B有分别指向B、C、D和A的有向边,而离群点A只有指向自己的有向边。当在该图以B点为起点进行马尔可夫随机游走时,下一步可以转移到B、C、D和A中任意一个。当转移到A点后,由于A点是离群点,没有其他点把A点视为邻居点,导致A点只有指向自身的一条边。因此,在后续的随机游走中,只会不停地在A点循环,导致A点被访问的概率急剧增加。最后,马尔可夫随机游走会提前结束,A点的访问概率接近为1,其他点的访问概率接近为0。同时,如果转移概率矩阵分为几个子图且子图之间不连通,会同样导致马尔随机游走难以有效地检测离群点。
为此,本文提出利用最小生成树构建的全局信息图解决“悬空链接”问题,下面将对全局信息图进行阐述。
定义8 矩阵R。该矩阵表示在全局连通图上的权重矩阵,主要用于生成最小生成树,其定义为式(11):
定义9 最小生成树T。在数据集X上建立一个全连接的有向完全图,其边上的权重矩阵为R,则使用Kruskal 算法或Prim 算法生成最小生成树T=(V,E)。
其中:顶点集V={x1,x2,…,xn},边集E={e1,e2,…,en-1}。从矩阵R的定义可以看出,生成的树结构不仅将整个数据集中的节点连接起来,同时任意一条边上的两个节点都是其邻域内相似性最大的节点,因此利用最小生成树能精准地刻画数据的全局信息。
定义10 最小连通矩阵(Minimum Connected Matrix,MCM)。MCM 描述了最小生成树中数据点的连通信息,定义如式(12)所示:
其中E是最小生成树的边集。由式(12)可以看出,最小生成树的每条边对应最小连通矩阵两个分量,即MMC(i,j)=MMC(j,i)。
定义11 全局信息图WGIG。全局信息图刻画了通过最小生成树获取的数据点的全局信息,定义如式(13):
其中:S为相似度矩阵;MMC为最小连通矩阵,通过哈达玛积运算得到全局信息图。全局信息图不仅通过最小生成树将整个数据点连接起来,同时利用相似矩阵精确刻画了数据点的全局分布信息。
定义12 全息图WHG。全息图将局部信息和全局信息进行融合,更全面地刻画了数据信息,定义如式(14):
定义13 转移概率矩阵PHG。转移概率矩阵综合考虑了数据点的全局和局部的数据分布,定义如式(15):
其中:D为对角矩阵,对角线上的元素为局部信息图和全局信息图对应分量之和,作用是在于保证转移概率矩阵中每一行的概率和为1。因此,本文构造的转移概率矩阵能全面地考虑数据的全局和局部分布特征,即全息图特征;同时还能避免“悬空链接”问题,确保顺利进行马尔可夫随机游走过程。
最后,在构造好的转移概率矩阵上进行马尔可夫随机游走,其迭代过程如式(17)所示:
其中π为n维的平稳分布。
定义14 平稳分布因子(Stationary Distribution Factor,SDF)。SDF 描述的数据点离群程度,定义如式(18):
由式(18)可以看出,数据点xi的SDF为马尔可夫随机游走产生的平稳分布对应分量。由于内部点之间的连接紧密程度高于离群点和内部点之间的连接紧密程度,因此平稳分布中内部点的对应的分量较大,则其SDF较大,数据点离群程度低;平稳分布中离群点对应的分量较小,则其SDF较小,数据点离群程度高。
2.3 HSDFOD描述
本节主要描述基于全息图平稳分布因子的离群点检测算法HSDFOD 的执行过程。HSDFOD 需要输入数据集D,算法输出top-n离群点。本文算法首先构建数据点的局部邻居集合,利用一种自适应k值的方式确定数据点的邻居个数,使得内部点的邻居点个数多于离群点的邻居个数;然后利用局部邻居集合构建局部信息图,使用最小生成树构造出的全局信息图解决“悬空链接”问题;最后融合局部信息图和全局信息图为全息图,构造转移概率矩阵,再利用转移概率矩阵进行马尔可夫随机游走,利用SDF 衡量数据点的离群程度进而检测出离群点。
根据上述算法思想及相关定义,HSDFOD 描述如下。
算法1 HSDFOD。
HSDFOD的时间复杂度主要来源于以下两个部分:1)为构建局部信息图,需要获取每个数据点的邻域信息所需的时间复杂度为O(n2),n为数据集中数据点的个数;2)为构建全局信息图,需要使用Kruskal算法或Prim算法生成最小生成树,时间复杂度为O(n2)。因此HSDFOD的总体时间复杂度为O(n2)。
3 实验与结果分析
为评估HSDFOD 的性能,使用SOD(Outlier Detection in axis-parallel Subspaces of high dimensional data)[23]、SUOD(accelerating large-Scale Unsupervised heterogeneous Outlier Detection)[24]、IForest(Isolation Forest)[25]和HBOS(Histogram-Based Outlier Score)[26]算法在人工数据集和真实数据集上进行实验验证,比较分析本文算法的性能。以上算法都是基于top-n思想检测离群点。实验环境配置如表1所示,主要分为软件配置和硬件配置。

表1 实验环境Tab.1 Experimental environment
3.1 实验评估指标
为了全面、有效地检测本文所提算法的性能,本节将使用精确率Pr、曲线下面积(Area Under Curve,AUC)和离群点发现曲线作为离群点检测算法性能的评价指标。精确率Pr是传统离群点检测算法常用的指标,定义如式(19)所示:
其中:TP表示算法正确检测出的数据集中真实离群点的数量;FN表示算法错误地把真实离群点识别为内部点的数量;FP表示算法错误地把内部点识别为离群点的数量。AUC 是受试者工作特征曲线(Receiver Operating characteristic Curve,ROC)下方的面积,取值范围为[0,1]。AUC 值大的离群点检测算法意味着有更大的概率将离群点排在内部点之前,因此,AUC 值越大,算法表现越好。
离群点发现曲线是一种新的展现离群点检测算法性能的指标,计算过程为:在离群点检测算法为数据集中每个数据点计算离群得分后,将数据点的离群分数倒序排列,然后分段统计离群点检测算法检测出真实离群点的总数,最后以增量的形式进行展示。离群点发现曲线上升越快,表明算法能更加准确有效地检测出离群点。离群点发现曲线最优表现为一条斜率为0.5 的线段。
3.2 人工数据集实验
本文使用图4 所示的4 种人工数据集。

图4 4种人工数据集分布Fig.4 Distribution of four synthetic datasets
表2 是人工数据集A1~A4 的详细数据特征。根据图4 和表2可以看出,选用的人工数据集A1~A4分布较为复杂,离群点个数占比合理。因此,使用A1~A4 的数据集能较为全面地验证本文算法在各种复杂数据分布下离群点的检测效果。

表2 人工数据集的数据特征Tab.2 Data characteristics of synthetic datasets
图5 展示了HSDFOD 和对比算法在4 个人工数据集下精确率对比。从图5 可见,HSDFOD 在每个人工数据集下的检测精度都是最高的,尤其在A3数据集中精确率达到100%,最差的检测精度也有70%以上。人工数据集A4 的数据分布构成较为复杂,可以看出相比其他数据集,该数据集下的各算法的精确率都存在不同程度的下降,SUOD 算法在A4 数据集中甚至未能检测出离群点,但HSDFOD 依然能达到超70%的精确率。综合上述分析,可以看出,HSDFOD 在各个人工数据集中的检测精度最高且算法较为稳定。因此,验证了HSDFOD能高效地检测离群点。

图5 人工数据集上不同算法的精确率对比Fig.5 Comparison of precision for different algorithms on synthetic datasets
图6 为HSDFOD 和对比算法在4 个人工数据集下AUC值的对比。从图6 可以清晰地看出HSDFOD 在A1~A3 数据集上的AUC 值都是最高的。由于实验时选取top-n数据点计算AUC 值,因此在A3 数据集中HSDFOD 的AUC 值和精确率一样都是1。人工数据集A3 和A4 下的各算法AUC 值都较为接近,但HSDFOD 的AUC 值排名靠前。综合上述的分析可以看出,HSDFOD 在4 个人工数据集下AUC 值表现依然很出色,虽然在A4 数据集下AUC 值稍低于SOD 算法,但整体来看HSDFOD 的AUC 值表现是优秀的,从而进一步验证了HSDFOD 能准确有效地检测离群点。

图6 人工数据集上不同算法的AUC对比Fig.6 Comparison of AUC for different algorithms on synthetic datasets
图7 为HSDFOD 和对比算法在4 个人工数据集下的离群点发现曲线。从图7 可以看出,HSDFOD 的离群点发现曲线均在对比算法的离群点发现曲线之上,表明HSDFOD 在指定查询数据点的前提下比其他对比算法更能有效检测出潜在的离群点。尤其在A3 数据集上,HSDFOD 的离群点发现曲线是一条斜率为0.5 的直线,表明HSDFOD 检测出的前40 个数据点均为离群点。综合上述的分析可以看出,在4 种复杂分布的人工数据集下,HSDFOD 的离群点发现曲线表现都为最优,验证了HSDFOD 使用局部信息图和全局信息图能有效提高算法的离群点检测性能。算法能很好地适用各种有复杂分布的数据集,并且有较好的检测精度和稳定性。
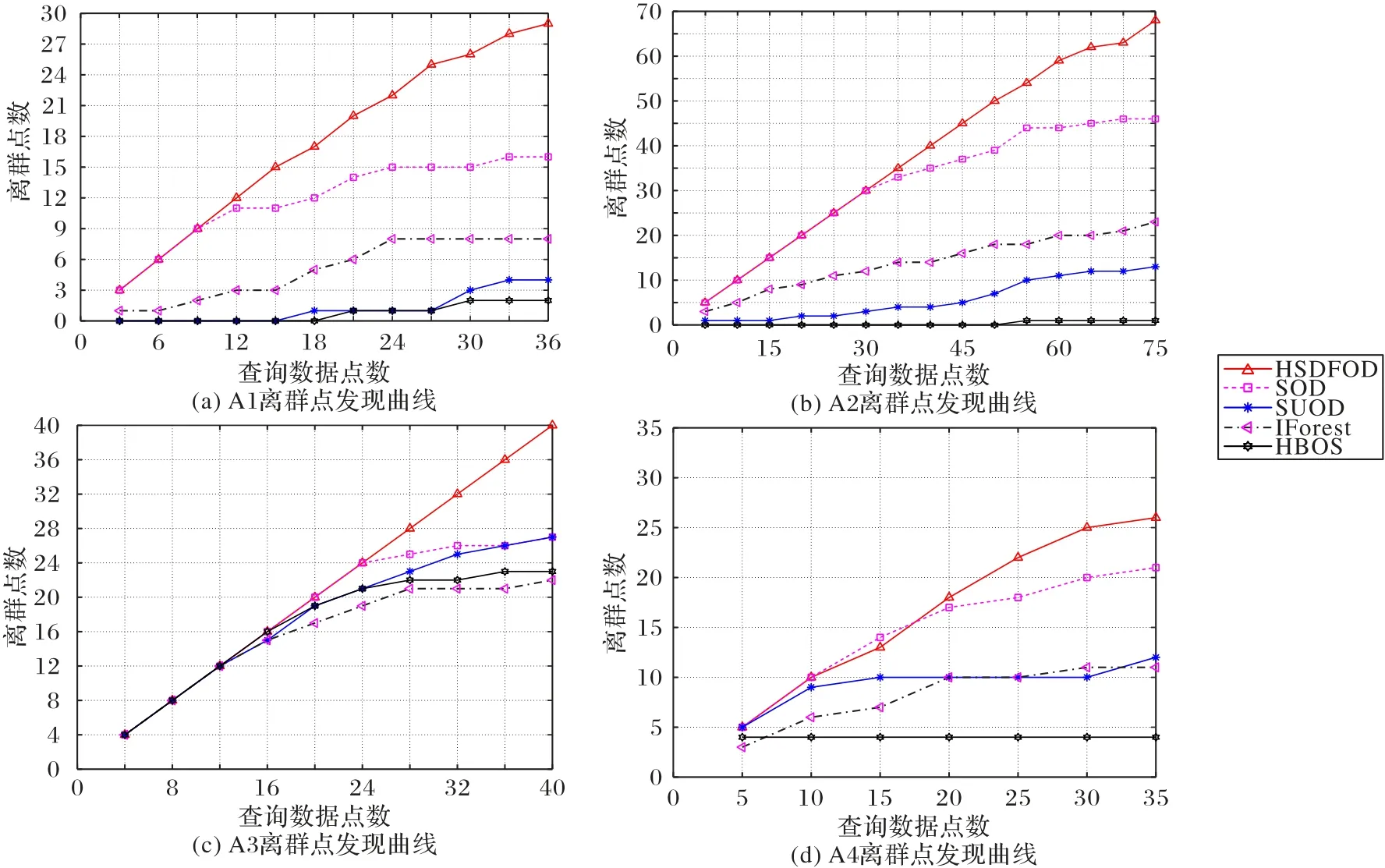
图7 人工数据集上不同算法的离群点发现曲线对比Fig.7 Comparison of outlier discovery curve for different algorithms on synthetic datasets
图8 是HSDFOD 和对比算法在人工数据集上运行时间的对比。通过图8 可见,HSDFOD 在人工数据集A1、A2 和A4 上的运行时间都是最少的,在A3数据集上比SOD算法运行时间长,与IForest 算法和HBOS 算法运行时间相近。综合上述的分析可以看出,HSDFOD 在4 个人工数据集上运行时间整体上少于其他4 个对比算法。因此可以得出HSDFOD 虽然时间复杂度为O(n2),但在人工数据集上的运行效率整体较好。
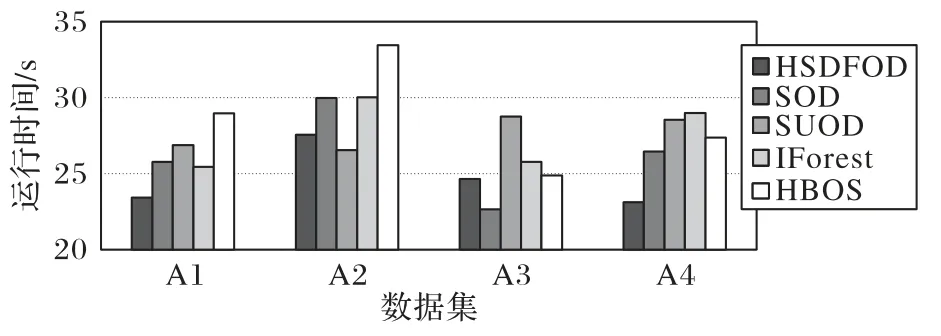
图8 人工数据集上不同算法的效率对比Fig.8 Comparison of efficiency for different algorithms on synthetic datasets
3.3 真实数据集实验
本文选用的4 个真实数据集均来自UCI 数据集,数据集的维度在7~32,离群点占比在4.0%~35.8%。表3 展示了真实数据集的数据特征,由表3 可见,本文选用的真实数据集拥有较广泛离群点比例和数据点维度,使用这些数据集能更加全面且真实地展示各种离群点检测算法的实际检测能力。
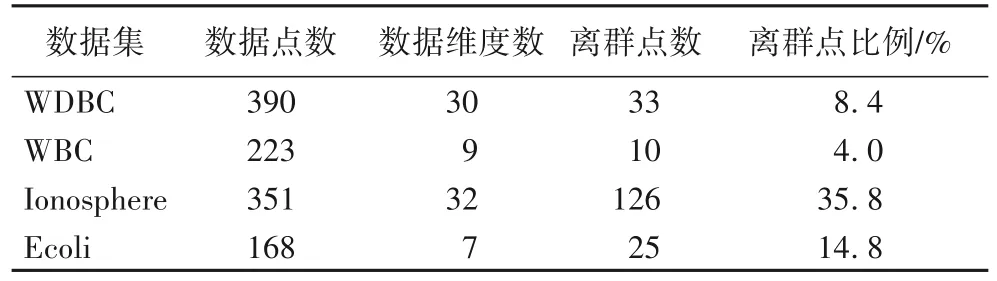
表3 真实数据集的数据特征Tab.3 Data characteristics of real datasets
图9 给出了HSDFOD 和对比算法在真实数据集下精确率的比较。从图9 可见,在WDBC 数据集上HSDFOD 的精确率达到了90%以上,而对比算法的精确率均在50%左右,HSDFOD 在该数据集的精确率远超对比算法的精确率。HSDFOD 在Ionosphere 数据集上的精确率为84.1%,精确率优于对比算法。在Ecoli 数据集上,HSDFOD、SUOD 算法和IForest 算法的精确率均为80%。HSDFOD 在WBC 数据集上的精确率略低于SUOD 算法,但仍然有80%的精确率。综上分析,可以看出HSDFOD 在4 个真实数据集上整体精确率的表现优于对比算法,而且算法性能较为稳定,精确率均能保持在80%以上。因此,通过精确率的比较分析,验证了HSDFOD通过利用全息图能正确有效地检测离群点,精确率较高。
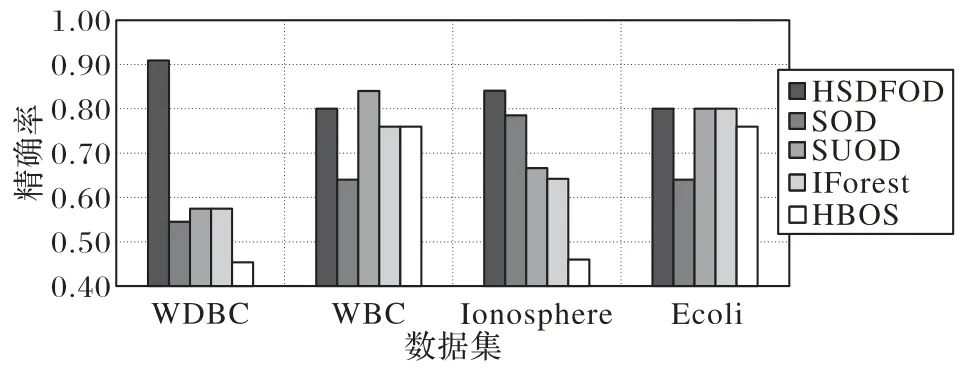
图9 真实数据集上不同算法的精确率对比Fig.9 Comparison of precision for different algorithms on real datasets
图10是HSDFOD 和对比算法在真实数据集下的AUC值。由图10 可以看出,HSDFOD 在4 个数据集上的AUC 值均超过0.9,并且AUC 值均优于对比算法。因此,通过对4 个真实数据集上的AUC 值的比较,发现HSDFOD 具有较高的稳定性,验证了HSDFOD能正确检测离群点,有较好的检测性能。
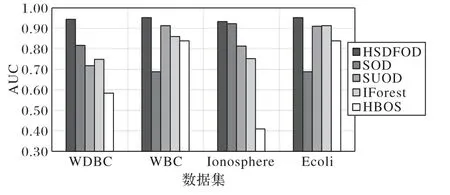
图10 真实数据集上不同算法的AUC对比Fig.10 Comparison of AUC for different algorithms on real datasets
图11 是HSDFOD 和对比算法在真实数据集下离群点发现曲线的比较。通过图11 可看出HSDFOD 在WDBC 数据集和Ionosphere 数据集的离群点发现曲线明显处于对比算法的离群点发现曲线上方。在WBC 数据集上,HSDFOD 在查询数据点数为6~12 时,查询出的离群点数比SUOD 算法、IForest 算法和HBOS 算法少,但当查询数据点数达到14 时,检测出和对比算法同样多的离群点。HSDFOD 在Ecoli 数据集上和对比算法的表现类似,但整体好于SOD 算法的离群点发现曲线。综上所述可以发现,HSDFOD 的离群点发现曲线虽然不是在4 个真实数据集中都优于对比算法,但整体的离群点发现曲线远优于对比算法,而且HSDFOD 的稳定性好于对比算法。因此,通过在离群点发现曲线指标上的比较,验证了HSDFOD 在真实数据集上不仅能正确检测离群点,并且算法有较好稳定性。
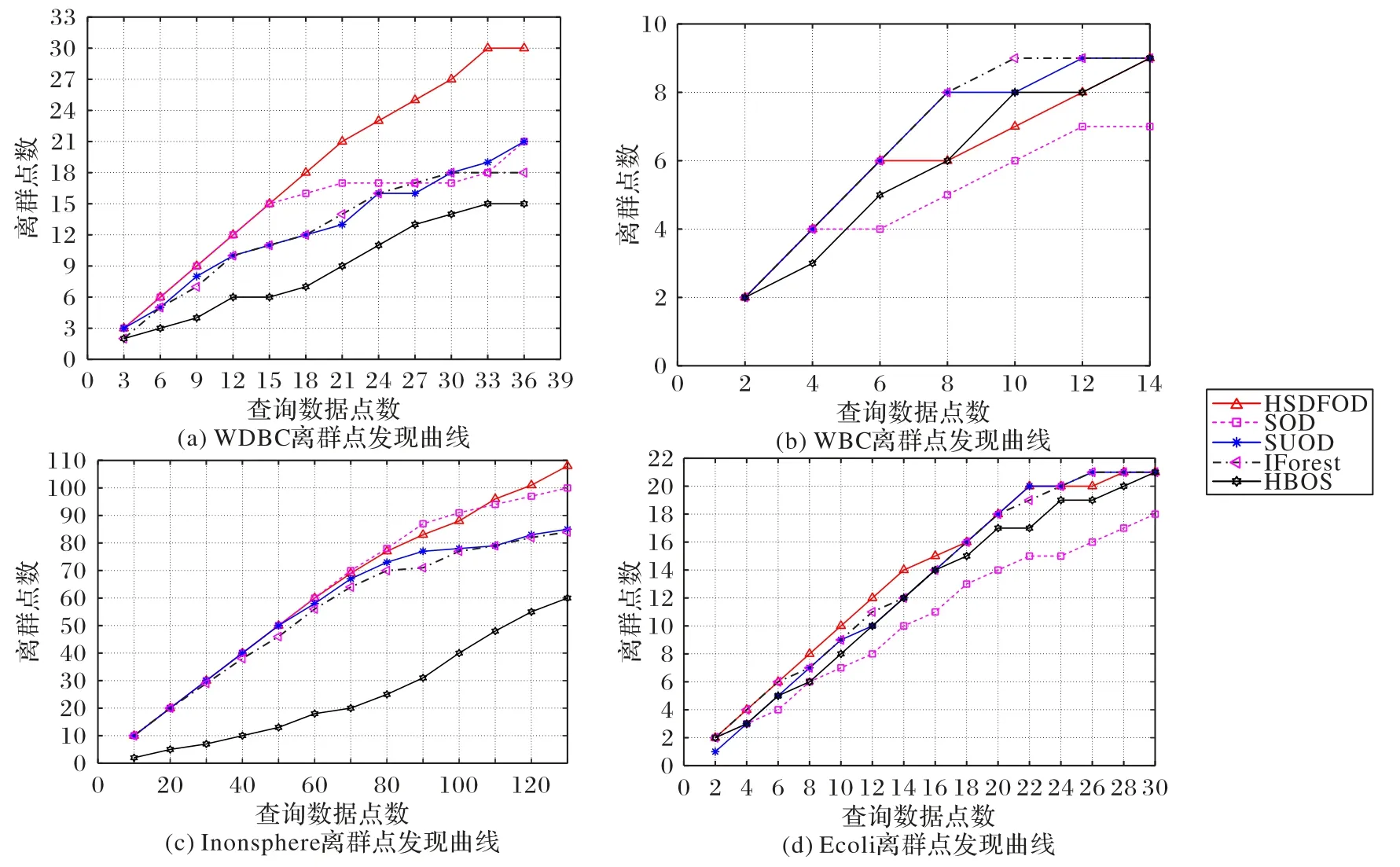
图11 真实数据集上不同算法的离群点发现曲线对比Fig.11 Comparison of outlier discovery curve for different algorithms on real datasets
图12是HSDFOD和对比算法在真实数据集上运行时间的对比。

图12 真实数据集上不同算法的效率对比Fig.12 Comparison of efficiency for different algorithms on real datasets
通过图12 可以看出,HSDFOD 在真实数据集WBC、Ecoli上的运行时间都是最少的。在真实数据集WDBC、Ionosphere上,HSDFOD和SOD算法的运行时间均少于SUOD算法、Iforest算法和HBOS算法,HSDFOD的运行时间仅多于SOD算法。综上可以看出,HSDFOD在4个真实数据集上运行时间整体上少于其他4 个对比算法。因此可以得出HSDFOD 在真实数据集上的运行效率整体上是好于对比算法的。
综上,由于本文算法既考虑了基于图的离群点检测方法中仅使用数据的全局分布信息会导致忽略局部离群点的问题,也考虑了只使用数据的局部信息会造成“悬空链接”问题,因此本文提出的基于全息图平稳分布因子的离群点检测算法能更有效全面地检测离群点。
4 结语
本文提出了基于全息图平稳分布因子的离群点检测算法。首先为获取数据点的局部信息,提出了一种自适应k值的生成方法获取数据点的局部邻居;然后通过获取的局部邻域信息,生成局部信息图,再通过最小生成树和相似矩阵生成全局信息图;最后综合局部信息图和全局信息图为全息图生成转移概率矩阵,利用该转移概率矩阵进行马尔可夫随机游走以完成离群点的检测。实验结果表明,通过同时考虑局部信息图和全局信息图的全息图能很好地提高离群点的检测精度。由于本文在构建局部信息图和全局信息图时都需要较高的时间复杂度,因此未来的工作方向是在保证准确率的条件下降低时间的复杂度。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
数学物理学报(2017年5期)2017-11-23
数学理论与应用(2016年3期)2016-05-17
中国房地产业(2016年9期)2016-03-01
核科学与工程(2015年3期)2015-09-26
哈尔滨师范大学自然科学学报(2015年1期)2015-04-19
西安交通大学学报(2014年8期)2014-04-16
电视技术(2014年19期)2014-03-11
上海电机学院学报(2014年3期)2014-02-28
