
基于改进型DeepLab的图像语义分割研究
2023-07-17 14:50郑永奇
计算机应用文摘·触控 2023年13期

摘要:深度学习在图像语义分割方面有着广泛的应用,能够提高计算机对图像的理解和识别能力,同时在自动驾驶、医学影像等领域具有重要作用。然而,其现有算法还存在一些缺陷,如预测结果不连续、精度不高等。因此,文章基于深度学习技术以DccpLab V3+框架为研究对象,探究其基本原理和核心架构.并基于Xccption提出一种改进型DccpLab V3+框架,以解决预测结果不连续、下采样导致特征图信息丢失等问题,从而提高分割的精度。该研究使用Cityscapcs数据集进行实验验证.并将改进的框架与初始的DccpLab V3+框架进行了比较。实验结果表明,该方法在平均交并比方面表现更优,提高了2.82%的分割精度。
关键词:DccpLab;Xccption;语义分割;Cityscapcs
中图法分类号:TP391 文献标识码:A
1 概述
随着海量图像数据的不断涌现,计算机视觉成为当前计算机专业研究的热门方向。目前,计算机视觉研究的主要研究领域包括图像分类[1] 、目标检测与识别[2] 以及语义分割[3] 等。其中,语义分割是指对原图像中每个像素点所属的类别概率进行预测,并将不同类别的像素点用不同颜色进行标识。语义分割在自动驾驶领域中可以实现对道路场景的自动识别,在医学影像中可以辅助医生的决策和诊断,在农机自动化中能够实现农业设备的路径识别导航等。
2014 年,谷歌团队提出了DeepLab 系列模型,在此之前,深度卷积神经网络已被广泛应用于目标检测和图像分类等研究领域。但是,深度卷积神经网络在图像语义分割领域有着难以克服的缺陷。比如,卷积神经网络中的池化层在进行下采样时会导致图像的分辨率降低、使图像中的空间位置信息偏差较大等。
为解决这些问题,本文研究了基于DeepLab V3+框架的图像语义分割算法并提出了改进型框架。首先,本文探究了DeepLab V3+框架的基本原理和模型结构,然后,将Xception 作为DeepLab V3+框架的图像特征提取网络,最后使用Cityscapes 街景数据集进行了模型验证。实验结果表明,改进后的DeepLab V3+框架比原算法在分割精度MIoU 方面提高了2.82%。
2 基于DeepLab 模型的图像语义分割方法
2.1 DeepLabV3+模型结构
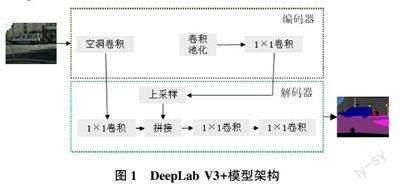
DeepLab V3+模型是在DeepLab V3 模型的基础上进行优化而来的,该模型结合了编码?解码型算法多方面的优势。DeepLab V3+模型中的编码器和解码器2 个模块使它能够更好地平衡精度和时间。
DeepLab V3+模型架构如图1 所示。
在编码器中,图像首先通过主干网络进行特征提取,提取的结果包括浅层特征和经过整个骨干网络训练后得出的特征图。这些特征图通过金字塔型的池化层提取特征,再由不同倍率的空洞卷积进行融合。
这些操作使经过处理得到的特征图融合了深层次特征。在解码过程中,将编码过程中产生的浅层特征与深层次特征进行融合,并进行一次3×3 卷积。最后,模型进行一次上采样并得出模型结果,使输出结果与原始图像大小相同。DeepLab V3+模型的层次主要包括卷积层、池化層和激活函数。在基于深度学习的图像语义分割方法中,卷积神经网络是最普遍的算法。
经过卷积和池化操作,输出特征图用于图像语义分割。为降低模型参数量和防止过拟合,通常在卷积层后添加池化层,以降低图像特征的大小。激活函数是神经网络中的关键组成部分,DeepLab V3+模型采用的是ReLU 激活函数,具有计算速度快、收敛速度快等优点,表达式为:ReLu =max(0,x) (1)
2.2基于改进型DeepLab V3 +模型的图像分割
研究表明,DeepLab V3+模型存在未充分利用不同层次特征信息等问题,会导致所分割的目标边界不清晰、细节不明显,影响后续图像解释。针对这些问题,本文对该方法提出了进一步的优化。改进型框架在利用传统DeepLab V3+的编码-解码架构的基础上,将具有65 层卷积操作的Xception65 引入编码器,并将其作为主干网络来提取特征。这种网络结构能够充分利用低层次特征中的空间位置信息,有助于还原分割后图像的细节构造。改进的DeepLab V3+框架仍使用编码-解码总体架构,如图2 所示。
输入图像经过Xception 特征提取网络的65 层卷积和深度可分离卷积操作后,被分开输出到下一级。
第一个数据流通过带空洞卷积的池化层得到5 种特征图,经过融合后再进行1×1 卷积。另一个数据流通过1×1 卷积降低通道数后,与空间金字塔型池化层得到的特征图进行融合,得到编码器处理的高层次特征图。高层次特征图经过4 倍上采样后输送到解码阶段。解码器接收了编码处理后的数据,包括经过池化层处理的深层次特征图和通过空间注意力机制进行加权处理的特征图,以及将特征提取网络中不同层级的低层次特征作为输入并与空间注意力机制进行特征融合得到的特征图。在解码阶段,编码阶段上采样后的高层次特征图与解码阶段前期的特征图进行融合,并通过3×3 卷积进行特征图的最后一次细化处理,最后通过4 倍上采样来恢复特征图大小完成图像语义分割。
3 实验设计
3.1 数据集
本研究将Cityscapes 数据集作为实验数据,该数据集包含50 余个城市的街景图像,涵盖汽车、行人、地面等19 个物体类别,在无人驾驶和道路场景语义分割的研究中得到广泛应用。
3.2 实验配置
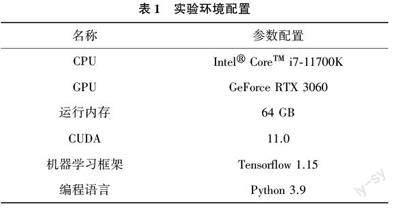
本实验平台搭建在Windows 11 的计算机上,具体实验环境配置详见表1。
3.3 实验结果
本研究在Cityscapes 数据集上进行了图像语义分割的实验,对输入图像进行了裁剪处理,使其大小统一为513×513×3。实验中选取了5 000 张精细标注的图像信息,其中包括3 000 张训练集图像、1 000 张验证集图像和1 000 张测试集图像,涵盖19 个类别的物体,如树、车、马路、路灯、人等。本文采用了DeepLabV3+算法和提出的改进算法对Cityscapes 数据集进行了图像分割操作。对比实验结果显示,相较于传统DeepLab V3+算法,本文提出的改进算法能比较清晰地分割出建筑、汽车等,图3(c)相较于图3(b)就更加清晰地分割出黄色圆圈中的路灯、汽车等物体,通过与图3(a)相比可以明显看出,改进型DeepLab V3+算法更加接近物体在原始图像中的空间位置特征,减少了图像信息损失。多次实验结果表明,改进算法在MIoU 值和MPA 值上分别提高了2.82%和1.37%,显著提高了图像分割性能。其中,一幅图像的分割效果对比如图3 所示。改进型Deep Lab V3+与原算法的对比效果如表2 所列。
4 结束语
本文旨在探究基于深度学习的图像语义分割技术,着重关注DeepLab V3+框架的算法改进和应用。
语义分割是计算机视觉中的一项重要任务,它可以将图像中的每个像素分配到其所属的语义类别,为计算机智能视觉领域提供了强有力的支持。因此,研究基于深度学习的图像语义分割技术具有重要的意义。
为验证所提出的改进算法的有效性和适用性,本研究在Cityscapes 数据集上进行了一系列实验。实验中,使用平均交并比等指标来评估所提出的图像语义分割方法的性能。通过对实验结果的分析发现,本文所优化的DeepLab V3+框架在MIoU 分割精度方面提高了2.82%,达到了较好的效果。
未来,我们将继续探索实时语义分割的效率和提高弱监督图像语义分割精度等方面的研究。在实时语义分割方面,我们将探究更加高效的网络结构和算法,以提高分割速度。在弱监督图像语义分割方面,我们将探究更加有效的监督策略和数据增强方法,以提高分割精度。我们相信,以上工作将会进一步提高图像语义分割技术的性能,并为实际应用提供更加可靠的支持。
参考文献:
[1] 罗建豪,吴建鑫.基于深度卷积特征的细粒度图像分类研究综述[J].自动化学报,2017,43(8):1306?1318.
[2] 王彦情,马雷,田原.光学遥感图像舰船目标检测与识别综述[J].自动化学报,2011,37(9):1029?1039.
[3] 田萱,王亮,丁琪.基于深度学习的图像语义分割方法综述[J].软件学报,2019,30(2):440?468.
作者简介:郑永奇(1984—),硕士,讲师,研究方向:信息安全、信息管理。
