
NLP“消失”之后
2023-07-18 15:46吴洋洋
第一财经 2023年7期
吴洋洋

ChatGPT的发布改变了很多人的工作,首先就是那些处理自然语言的工程师。
正在清华大学电子信息专业读研二的蔡紫宴3年前决定换掉自己的专业,从经济学转到人工智能相关专业—“自然语言处理”(Natural L anguageProcessing,NLP)。
这是一个当时听起来十分时髦的研究领域。非计算机专业的人对这个领域或许陌生,但只要你曾与苹果的Siri等聊天机器人互动过,或是使用过Google翻译、输入法中的关键词联想功能,那么你就或多或少地接触过NLP。
然而研究生入学一年多后,蔡紫宴就发现,他在课堂和比赛中学到的自然语言处理技术,正在快速迭代。
易变的前沿
“我们看到NLP领域很多研究都被ChatGPT‘消灭了。”四川大学神经网络方向副研究员郭泉说,如果说此前学校里的学生、研究员们还在试图通过不同的模型使机器更准确地完成分词、提取人名等传统N L P任务,那么ChatGPT已经可以跳过这些中间环节,直接生成结果,而且做得很好。
NLP是个古老的领域,但技术迭代周期在以翻倍的速度缩短。早在1940年代,工程师们就尝试用提前设定好的规则(比如语法),训练机器理解语言。1990年代,基于统计的技术开始应用到NLP中。2010年之后,深度学习成为主流。然后就来到了2020年,当年3月,OpenAI发布了其第3代大语言模型(LargeLanguage Model,LLM)GPT-3(基于Transformer)。
从时间跨度来看,NLP领域的技术迭代时间从最早的30年、20年减少到了10年—差不多是一位在这一领域求学的学生从大学入学到博士毕业的时长。
蔡紫宴担心,再过两年,他在学校和实践中所学的技术都会被淘汰,“你对一些自然语言的理解可能被完全颠覆,在考试、实习时你当作定理来背的很多东西都没意义了。”蔡紫宴说,他3年前开始学习自然语言处理的相关知识,当时主要与预训练语言模型相关,双向编码的BERT模型更被看好,而如今GPT模型表现出了更好的潜力。
“这就像一棵进化树,在一个分支十分辉煌后突然走向尽头,另一个分支逐渐登上舞台。”蔡紫宴说,如果早些年N L P 的研究类似于纯手工的作坊,在2 017年G oogle提出Transformer和后来预训练语言模型一统天下后,NLP领域的研究就像拥有了自动缝纫机的纺织工—现在,则进一步转向全自动化底座的流水线。
学术期刊和会议对收录论文的要求也一夕之间发生改变。蔡紫宴发现,但凡论文涉及模型效果,只要论文没有理论性创新,就必须考虑“大模型”。不然,审稿人基本都会问“你的研究结果与ChatGP T相比表现如 何”。
进入“大模型时代”以来,技术的演进速度并没有慢下来,而是更快了。从本科开始就在做自然语言处理研究的李然告訴《第一财经》杂志,2 019年到2021年,基于Transformer的语言处理模型主要还集中在BERT、GPT-2这类规模较小的模型上,但从2022年年末开始,GPT-3、GPT-4这类更大规模的预训练处理模型能够生成更长文本序列、具有更高的语义理解和生成能力。很快,李然就发现,实验室里几乎所有人都开始讨论大模型。
2022年下半年,语言处理技术全面从传统NL P转入大模型的时候,李然结束了他的本科学习,进入研究生阶段。
“那时就感觉地球要结束了。”李然说,之前的研究到底要不要继续做下去、已有的技术积累是不是应该被推翻了、如果坚持的话坚持的意义是什么、之前研究的东西在未来还有没有深入应用的价值……李然每天都在思考这些问题,但没有答案。
不停奔跑,才能留在原地
蔡紫宴、李然所在的实验室都开始尝试转型,从传统NLP转向“大模型”。不过这种转向并非简单改变研究兴趣就能实现,而是涉及从芯片资源到数据资源的整体硬件改造。
李然称,他所在的实验室只能做一些参数量在10亿到100亿之间的模型训练。而像拥有1750亿个参数的GPT-3就“绝对做不了”。有消息称,GP T-4的参数量已经达到1万亿。
蔡紫宴有相同的担忧。在没有GPT-3、GPT-4这些“大模型”的时候,单个实验室甚至单个学生利用实验室的普通服务器都可以做自然语言处理的研究,但只要想研究“大语言模型”(Large Language Models,L LMs),就需要联合不同实验室,甚至要带着老师、实验室的资源与校外公司合作,依靠对方提供的数据来做研究。即使是在清华,能做这种“庞大工程”的实验室都不多,首先在算力上就有很高的门槛。
自然语言处理技术发展历程
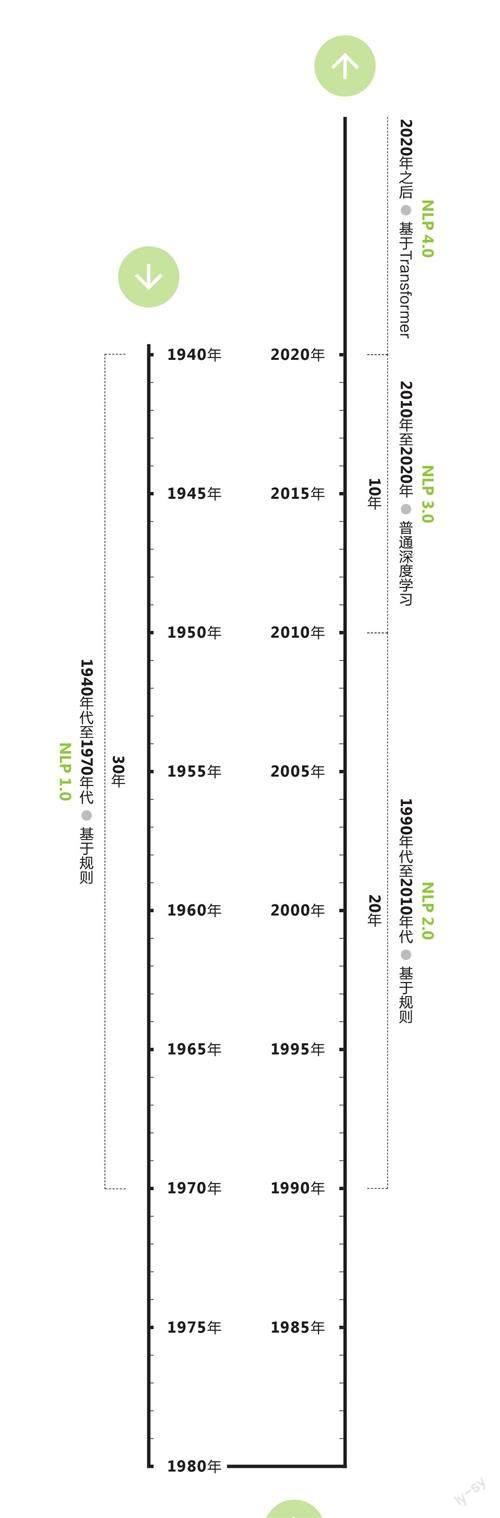
数据来源:根据公开资料整理注:GPT-3在2020年3月发布
大模型热潮下,NLP领域变得更“卷”了。李然发现,自己好几次冥思苦想找到的点子还没付诸实践,就已经被挂在了ArXiv(arxiv.org)上—该网站的论文通常是未经同行评审的预印本,但先发布就意味着先占坑。前几天,李然做了半年的研究正要收尾,检索ArXiv了解最新的研究进展和趋势时,发现又有人做过了。
蔡紫宴相对“幸运”一些。他感兴趣的是大语言模型如何与人类的价值观对齐,使大模型输出的内容更加安全并符合人类偏好。刚开始做研究时,这还是一个关注度不是很高的方向,毕竟当时的模型离“电子鹦鹉”相去甚远,更谈不上关注大模型的伦理与治理问题,业内一个月或者一个季度才会更新几篇有重要贡献的论文。但现在,ArXiv上不到两天就会有一篇新的相关论文。
“论文更新的速度,普通研究者完全跟不上,大家都疯狂往这个领域卷,羊驼、原驼……各种动物的名字都被用来命名大模型,从3月到现在新论文已经数不胜数。”蔡紫宴说。
被改变的职业路径
技术大转身,毕业后的去向成为NLP研究生们需要重新思考的问题。
蔡紫宴发现,身边一些原本“很厉害”的同学都已经放弃读博。他们一方面想要赶一赶“行业风口”,抓紧投身于这个急需算法工程师的行业,以快速积累经验—以及财富。另一方面,蔡紫宴发现他们也担心“如果四五年后读完博士,可能技术通过迭代又发生了革命性的改变”。
“最糟糕的情况是你已经在NLP读博一或者博二,研究目的是提高算法效率,但研究内容与大模型无关,那可能就要调整研究方向了。”蔡紫宴说。
本来想读博的李然也开始迷茫。他发现,随着技术前沿的剧烈变化,开展前沿研究的门槛越来越高,成本也越来越高,因此前沿研究更倾向于去工业界和企业做,而不是在高校实验室里,高校学生想在算法研究领域发表论文越来越难,“我也不是天才”。李然说,他打算在前沿研究领域就此打住,去行业里面做一些落地的工程化应用。
蔡紫宴也看到了算法工程化—而非基础研究方面—的学术和就业机会。
“大模型应用肯定会在近几年彻底革命各类应用和系统,到时候所有的应用都可能被替换,这需要大量的工程师来维护,解决各种优化迭代、运营维护,或者是信息安全等问题。很多公司也有定制化模型的需求。”蔡紫宴说,比如,如果在移动设备端编译运行大语言模型,工程师就可以通过编译优化和压缩模型权重,用低精度的方式来减少算力需求。
重新思考教育
2018年,国内共有35所高校获得人工智能专业建设资格,其中多数为985、211院校。某种程度上,人工智能专业的设置体现了高校的前瞻性,但其学习和研究速度仍然远远赶不上技术迭代的速度。如果这群处在技术前沿专业的学生,在面临技术拐点时都如此脆弱,那教育的价值到底是什么?
郭泉不需要像李然和蔡紫宴那样焦虑自己的职业前景,他已经是四川大学神经网络方向的副研究员。在ChatGPT发布之后,他进一步思考教育到底应该教什么这个问题。
他仍然赞同本科生和研究生要有不同的教学模式这种传统。比如对于本科生,就要教他们打好学科基础,高等代数、线性代数、概率论、机器学习、神经网络等课程需要长期留在教学方案中。
“不需要跟着行业走,看行业里出现了自动驾驶、语音识别,课程就跟着调整,而是要看学生的思维构成需要哪些知识,要培养他们在一个领域思考的能力,前沿的行业应用只作为扩展和了解内容。”他对《第一财经》杂志说。
但是到了研究生阶段,就要强调“提出问题的思维能力和解决问题的思维能力以及科研过程中的的动手能力”。
“我们不能把计算机当成理学来教,这必须是一个工程实践相关的科学,所以我们要培养学生‘提出问题并解决它的能力。”郭泉说。这一点可以类比化学实验,一个实验需要某种特殊形状的试管,但市面上没有卖,如果学生有很好的实践能力,就可以用酒精喷灯把实验室里的试管烧成实验需要的形状。烧试管这件事情不会被发成论文,但烧试管后做出的实验有可能產生重要的科研成果。
作为研究者,郭泉也反思了他对“问题”的定义。ChatGPT发布以前,他一直觉得“涌现”是伪科学,但现在,ChatGPT的出现让他开始认为“涌现”是一个可以被提出、需要被思考的问题(注:ChatGPT发布后,很多人将神经网络大到一定程度、喂养足够规模的数据后出现的智能跃升现象,称作“涌现”)。他对这个问题还没有答案,但已将其列入自己的下一个研究课题。
猜你喜欢
考试与评价·七年级版(2021年2期)2021-08-14
考试与评价·七年级版(2020年4期)2020-10-23
娃娃乐园·综合智能(2017年16期)2017-02-24
浙江大学学报(工学版)(2015年11期)2015-03-01
浙江大学学报(工学版)(2015年5期)2015-03-01
浙江大学学报(工学版)(2015年1期)2015-03-01
吐鲁番(2014年2期)2014-02-28
