
融合多维特征与兴趣漂移的虚拟学术社区群推荐模型
2023-07-20 10:25魏玲权晨雪
现代情报 2023年7期
魏玲 权晨雪

关键词:虚拟学术社区;核心用户;偏好融合;兴趣漂移;群推荐
DOI:10.3969/j.issn.1008 -0821.2023.07.006
[中图分类号]TP391.3 [文献标识码]A [文章编号]1008-0821(2023)07-0048-16
知识经济时代,学科间的交流与互动越来越频繁,不同实体通过知识媒介在分解、共享、转移、整合的过程中极大地促进了知识间的交叉协同与融合发展。虚拟社区是为用户提供在线交流与互动的平台,其中知识的流动与共享决定了虚拟社区的竞争力、生命力与创新力,问答社区、在线健康社区、虚拟学术社区中社交网络与知识网络相互交织,共同推动个人、学术机构或商业组织前进。虚拟学术社区作为一种新兴学术交流平台,将具有相似兴趣的科研人员聚集在一起,拓宽了学术交流的渠道,丰富了学术交流的形式与内容。随着用户逐渐成为虚拟社区的核心,有研究表明在虚拟学术社区中用户呈现差异化及中心化的特征,表现为社区中存在不同群体的区分,并且用户群体出现逐渐中心化的动态演变,这种动态演变能够促进交互行为的增加,其中核心用户群体在知识交流中担任信息级联传播的角色,实现对核心用户的信息推荐服务有助于推动知识传播速率。除此之外,虚拟学术社区中存在个体信息匮乏、用户网络稀疏以及缺乏资源整合等缺陷,在个性化推荐时难免会出现因用户信息较少以及数据稀疏导致推荐工作量大且效率不佳的问题,又由于虚拟学术社区内信息分散并且知识质量良莠不齐,极大地影响用户间的知识交流,从而激发了知识服务方式的创新和高效知识发现策略的需求。提高社区知识利用率最直接的方式就是对用户信息及生成的内容进行合理聚合,将其聚合为各个群组,既可以在推荐时实现知识资源的整合,又能尽可能地满足群组中用户对推荐内容专业性的精准度要求,同时科研人员面对海量的学术资源需求亦有一定差异,因此本文结合用户信息得到不同兴趣群组,研究群组中成员动态兴趣变化,及时跟踪群组兴趣变化过程以提高群组推荐效率,帮助社区管理者探索不同偏好群组中知识扩散与流动的相关规律,从而促進不同偏好用户需求的有效匹配。
现有针对虚拟学术社区的知识推荐多为个体服务,且忽略核心用户群组在社群中对推动知识流转带来的影响,因此本文提出了一种融合多维特征与兴趣漂移的虚拟学术社区群推荐模型,该模型基于社会网络分析和引入属性因子的PageRank法,运用改进的信息熵度量公式融合多维特征数据综合识别核心用户并聚类得到用户群组,同时引入时间因素探究群组中用户兴趣漂移规律,挖掘连续时间窗下的群组动态偏好变化,通过考虑兴趣漂移的群组协同过滤算法评估模型性能,有效提高群组推荐的准确性。
1相关研究
目前,国内外学者围绕虚拟学术社区的研究主要集中在知识流转与共享、用户交互特征、网络结构分析方面。知识流动可以发生在任何交互的环境中,Zhang J等认为,社交媒体使得虚拟社区成为知识交流的重要平台,知识共享的数量和质量对社区满意度和忠诚度有显著的正向影响。严炜炜等指出,学术社交网络常被视为复杂异构网络,其用户行为依赖于由社交网络与知识网络交织而成的多维关系网络。部分学者对用户的识别与分析展开研究,许睿等依据用户间的关注关系结合社会网络分析,选取入度、中心性等指标识别社区中的意见领袖。陈彩蓉等利用图结构建模用户间的信任关系,通过改进的PageRank法计算各用户节点的权重来体现用户影响力水平。王晰巍等从社交网络中受认可度、情感联系度和网络传播度3个方面构建意见领袖节点影响力指数法。刘玉文等提取用户多维特征构建多特征遗传的意见领袖识别方法。吴江等融合个人属性、网络特征、行为特征和文本特征构建意见领袖识别的综合指标体系。王晓梅从用户辐射度、权威性、参与积极性、历史影响力、话题动态特征5个维度构建基于话题动态特征的微博意见领袖预测指标。以上关于意见领袖的挖掘在网络社区的研究中也常被称为核心用户识别,李玉媛等进一步利用SNA和Topsis算法将用户划分为核心用户与一般用户。一般地,网络社区中的核心用户活跃度高、与其他用户联系紧密,并且表现出专业度高的特点,对信息传播速度和广度有着积极影响并起到重要的中介或过滤作用,对核心用户进行研究将有助于社区的建设和可持续发展。
在社会化推荐系统的研究中较少考虑到由不同用户组成群组的活动形式,随着研究范围的扩大,需要将大量具有共享性质的项目推荐给某一用户群组,并且当为个体推荐较困难时,还需构建虚拟群组进行推荐。学者们关于用户群组的构建主要通过相似度计算和聚类算法实现。席茜等提出了一种基于Hellinger距离的社会信任关系提取方法,将计算出的用户相似度与分组信息相结合来识别群组。董伟等借助ATM模型,通过文本聚类识别用户兴趣偏好,引入用户一文档映射和海林格距离算法得到用户兴趣群组。进行群组推荐的首要步骤为偏好融合,通常有两种实现方案:一是先对每个成员进行推荐,再利用融合策略聚合群组成员的推荐结果,即推荐融合,但在面对大规模群组时推荐效率低下且聚合结果工作量大;二是根据群组成员的偏好,通过融合策略直接生成群组的偏好模型,再进行推荐,即模型融合,如WangH等采用自注意力机制,从群组成员和项目之间的交互中自动学习每个群组成员的动态权重,同时聚合群组成员的偏好生成群组偏好。柯赟等利用LDA主题模型表征每个用户的兴趣偏好,聚合用户偏好特征得到群组偏好。夏立新等通过获取用户情境信息提取单个用户行为的偏好,实现群组聚类后融人情境信息挖掘群组行为特征,构建群组行为偏好特征向量。在群组推荐系统中,核心问题为如何更好地融合群组偏好,而偏好融合的本质则是用户兴趣偏好建模,对此的研究逐渐由静态向动态发展。用户兴趣往往根据环境、时间、自身情况等因素的变化而不断变化,并且这些变化隐藏在用户行为信息中,这种现象被称为兴趣漂移。当前关于兴趣漂移的研究主要从两个角度出发,第一种认为用户的兴趣处于不断变化的过程中,需要时刻更新用户兴趣模型,部分学者引入时间因子利用主题模型提取虚拟学术社区中用户动态兴趣演化过程,胡伟健等将时间惩罚函数引入到欧氏距离对用户兴趣的变化进行描述,提出一种结合用户兴趣变化的协同过滤推荐算法;第二种则需要准确定位至用户发生兴趣漂移的节点,由此进行用户兴趣建模,更加准确地捕捉兴趣变化,如吴树芳等在社交网络用户兴趣挖掘的基础上考虑兴趣主题稳定度,计算不同时间窗口下的兴趣波动幅度实现对用户兴趣的挖掘。钱聪等融合兴趣遗忘特征、出版物兴趣重合度以及文本语义相似度等用户不同时间段的偏好,以捕捉用户在每个时间段的多重偏好变化提高知识推荐的准确性。蒋武轩等为探究用户当前的兴趣关注与稳定偏好,基于社交网络结合遗忘曲线挖掘用户不同时间窗口下的长短期兴趣,依据滑动时间窗提高用户兴趣发现的准确性并进行推荐。
综上所述,目前针对虚拟学术社区中核心用户群体识别的研究较少,而现实中核心用户的权威性及活跃性对知识信息的传播会产生积极的影响作用。此外,在提升知识推荐服务水平方面和在信息资源不断扩充与更新的背景下,对于核心用户群组相邻时间窗下动态兴趣的推荐研究较为匮乏,这不利于精准挖掘其兴趣变化,且在一定程度上影响推荐精度。为解决上述问题,本文从识别虚拟学术社区核心用户群组的视角出发,由于群组偏好与个人偏好具有相似性,将群组融合后的偏好视作一个伪用户跟踪其兴趣变化,进一步研究群组动态兴趣漂移为促进虚拟学术社区内知识流动提供新视角。
2融合多维特征与兴趣漂移的群推荐模型
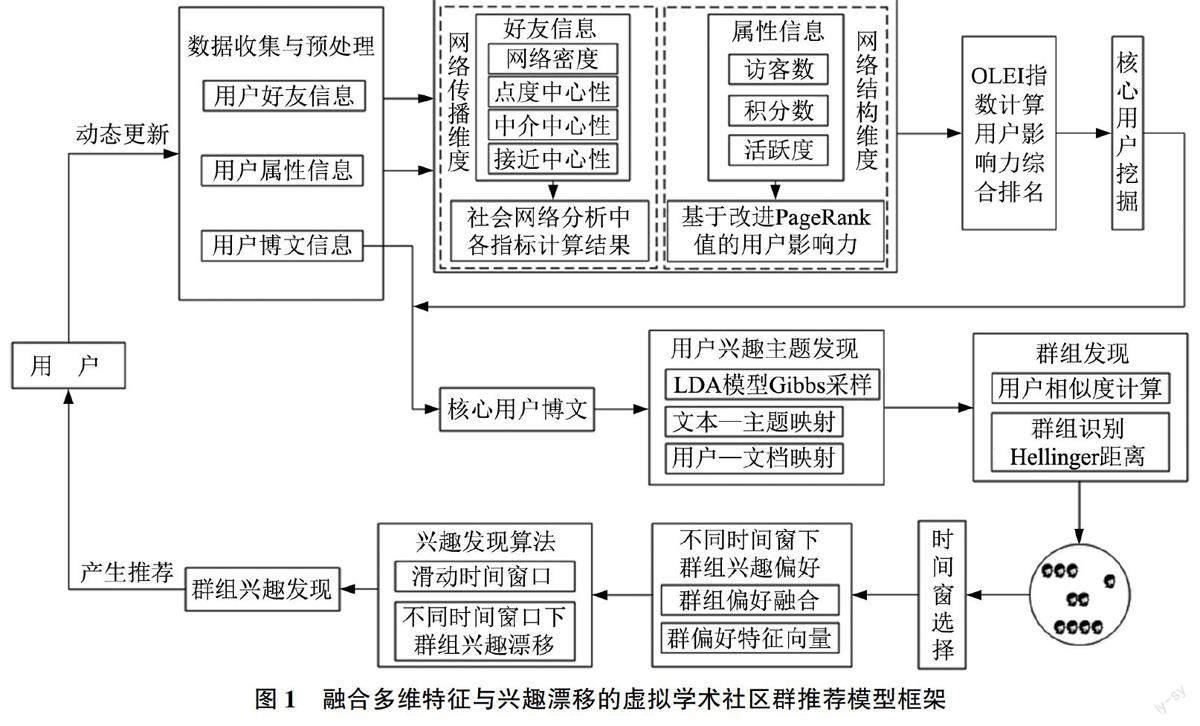
2.1研究框架
本文以虚拟学术社区为研究对象构建融合多维特征与兴趣漂移的群推荐模型,总体框架如图1所示。首先采集用户信息数据集作为后续研究的基础;其次基于网络传播维度和网络结构维度分别得到用户影响力排名,进而综合识别核心用户;第三结合用户博文信息提取文本主题实现用户一主题映射,并计算用户的主题偏好相似度聚类得到群组,实现用户偏好的识别和分类;第四通过模型融合将用户偏好融合为群组兴趣偏好,利用非线性遗忘曲线和连续滑动时间窗口发现群组兴趣漂移过程:最后利用考虑群组动态兴趣漂移的协同过滤群组推荐算法将感兴趣的内容推荐给目标群组用户。
2.2融合多维特征的核心用户识别
本文提出的核心用户识别方法从网络传播和网络结构两个维度构建,网络传播维度主要考虑社交关系,基于社会网络分析法得到整体网络图谱与用户节点的中心性和重要程度,包括点度中心性、中介中心性和接近中心性3个指标;网络结构维度综合考虑用户自身属性以及成员间的交互行为,构建用户属性指标体系并将属性因子引入PageRank算法中,得到基于网络结构的用户影响力计算结果,并参考前人将信息论应用于量化节点影响力的研究,借鉴OLEI指数构建本文融合多维特征的核心用户挖掘方法。
2.2.1网络传播维度的社会网络分析法
社会网络分析法(Social Network Analysis,SNA)是一种综合应用数学、图论、计算机等多学科交叉的计量方法,对网络中的个体关系模式进行测量、评估及可视化。虚拟学术社区中知识交流和共享行为内嵌于社会关系网络中,网络结构可以反映成员间关系的紧密程度和整体网络密度。一般地,将其定义为一个三元组,G={V,E,W|v∈V,eij∈E},其中V表示节点集合,E表示节点间的连边,W表示节点间边的权重,在社会网络中常用关系图和关系矩阵表示,将用户看作节点,用户间的关注、访问、点赞等视作节点的连边,从网络拓扑信息结构的角度衡量网络中节点的重要性,整体反映节点在网络中的位置。节点中心度常被用来描述节点在无向网络中的重要性,即人员在社会网络关系图中的地位,社会网络分析中常用的指标有点度中心性、中介中心性和接近中心性,如表1所示。
2.2.2网络结构维度的改进PageRank法
本文使用访客数、积分数以及活跃度3个指标构建用户属性特征指标体系,访客数即为所有到访过该博客主页的用户数,这可以在一定程度上反映用户影响力,访客数越多,其自身影响力可能越大;用户积分数为总发帖数、精华帖数以及兑换的金币数之和;用户活跃度则通过用户登录频次、回复数、搜索数和文字评论数等行为累计得到,即用户在该社区中产生的行为越多、积分越高,越易吸引其他用户参与知识资源的讨论与传播。
本文采用熵权法计算上述3个属性指标的权重,首先对原始数据进行标准化处理,使所有数据映射在[0,1]范围内,通过式(1)进行变换。
3实证研究
3.1数据收集与预处理
本文选取“科学网”为研究对象,科学网面向广大科研工作者提供快捷权威的科学新闻报道、科学信息服务,现已成为国内颇具影响力的科研知识交流网络社区平台。为有效获取数据,选取“管理综合”下的“管理科学与工程”“工商管理”“管理学”“宏观管理与政策”“图书馆、情报与文献学”5个领域的用户数据作为数据源,借助OCTO-PUS采集器获取近5年內的所有数据,包括用户的基本信息、好友列表、博文数及博文内容等,在剔除隐私用户和好友信息不可见的数据项后,最终得到688条有效信息和14295条博文信息。其中部分用户基本信息如表2所示。
3.2核心用户识别
3.2.1社会网络分析法
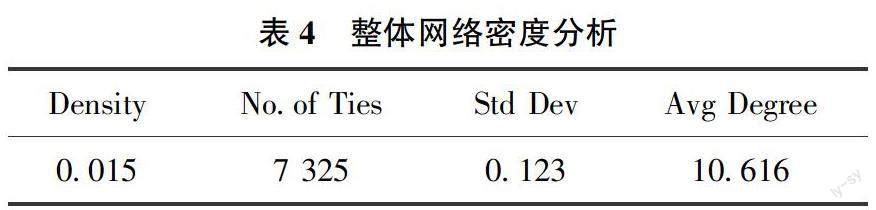
为得到整体网络图谱,需要将采集到的数据进一步处理,构建用户社交信息邻接矩阵,由于科学网中的好友仅存在双向链接关系,因此若二者相互关注,则在矩阵中填充1,否则为0,得到基于好友关系的邻接矩阵,如表3所示。然后将构建的邻接矩阵和用户对应的好友数作为属性值一并导入至UCINET软件中,得到整体知识共享网络分析结果,结果如表4所示。
网络密度反映社区中成员间的联系紧密程度和群体的结构形态,网络结构使每个实体均占据一定的位置并具有其独有特征。由表4可得整体网络密度为0. 015,即说明在科学网学术社区中,整体网络较为稀疏,并且由于该社区具有很强的专业性,各领域间跨度大,因此成员间的交互程度一般;网络平均度数为10.616,可以看出该网络呈现多中心化的特点,存在一部分连线较多且充当中介作用的节点,即网络中出现多个核心用户且他们之间的知识共享较为频繁,而边缘用户多出现分布分散、交互程度较低的特点,此结论与黄微等对虚拟学术社区研究的结果表现一致。本文进一步借助Netdraw软件进行可视化分析,绘制得到好友关系网络图谱如图2所示。
从整体图谱来说,共计688个节点和7325条边,其中蕴含交错复杂的关系。节点的大小代表用户在网络中的整体中心度,即节点越大对应的连边越多;连边代表了用户之间的关系纽带,可以在一定程度上反映用户是否处于整个网络中的核心地位。由图2可以看出,ID为1557、117288、842903、541012等用户节点大,是网络中的活跃分子,且与其他用户连边较为繁杂,在社区中享有较高的关注度,即中心度较高。在此基础上,本文进一步从定量的角度度量网络中的节点,各中心性指标计算结果如表5所示。
3.2.2改进的PageRank值计算
本文使用访客数、积分数以及活跃度3个属性指标对社区内现有用户做影响力评估,由于各指标具有不同的意義,需要在计算前利用式(1)进行标准化处理,结果如表6所示。然后利用熵权法依据式(4)得到各指标权重,如表7所示。
分析可得在评价用户影响力的属性指标中,用户访客数带来的影响最大,权重为0.65,其次为积分数,权重为0.25,这是由于积分数由总发帖数、精华帖数以及兑换的金币数综合计算得到,结合访客数及积分数可以看到用户的博文质量是决定用户影响力的关键因素,博文质量的提高带来精华帖及发帖数的增加,同时吸引好友或新用户拜访主页,而活跃度权重仅为0.1,究其原因为该类社区内用户行为多为浏览、登录带来的活跃度累计,同时,社区内部分成员间信任度较低,这共同导致了成员间的交互程度不高。因此,社区运营者可以通过有效的激励机制,如鼓励用户发布博文、积极参与学术相关交流以增强虚拟学术社区知识共享的意愿和行为,同时完善社区的推荐功能,提升社区内用户交互的积极性,增强用户粘性。
在得到各指标权重后依据式(5)得到用户影响力值Ii,即用户属性权重wj,同时依据式(3)通过Java程序编写计算这688名用户的PageRank特征值,如表8所示。
3.2.3用户综合影响力排名
本节对3.2.1及3.2.2中得到的指标数据Min-Max标准化处理后,通过节点影响力指数OLEI式(7)得到用户综合排名,如表9所示,并根据结果选取排名前12%的87名用户作为虚拟学术社区内的核心用户。
3.3核心用户兴趣群组识别
对识别出的87名核心用户近5年内的5 233条博文进行处理,科学网作为一个专业的科研知识交流社区,其中用户行为统称为知识共享行为,所涉及的内容多与其研究领域或当前关注信息相关,该社区内的用户博文同样隐含用户的潜在兴趣与未来关注方向。对此进行分析将有助于发掘相同兴趣爱好的用户群组,以便更好地提供知识推荐服务。部分核心用户博文数据如表10所示。
本研究使用Python中的PANDAS库,结合停用词表与词典,对博文进行分词。得到基于用户博文的分词结果,利用SKLEARN库进行LDA主题挖掘训练,由式(8)和式(9)计算困惑度得到最优主题数。训练过程中发现,当主题数K=5时,困惑度较低,由此得到最终的5个主题,如表11所示。可以看到在“科学网一管理科学”领域中,用户所关注的主题大致可以分为5个方面:学者交流、科技管理、数据挖掘、学术论文以及图书情报,并且主题分类得到的结果更为专业且聚焦,科技管理主题一特征词包含企业、政策、市场和数字化等,紧跟当前数字企业的最新动态方向,数据挖掘主题一特征词包含机器学习、算法、人工智能、算法优化等,聚焦于当前算法的改进与优化等方面,均与当前该领域的关注点息息相关。
进一步分析用户对不同主题的偏好程度,遍历所有用户与相应文本,建立用户一文档映射表,其中部分映射关系如表12所示。用户编号即用户ID,文档编号则是对所有用户博文的排列顺序。
基于用户一文档编码以及主题一特征分布,利用式(10)通过Gibbs采样构建用户—主题概率映射表,如表13所示,可以直观得到在主题确定的情况下,不同用户对各主题的偏好概率值,能够大致得到用户所属的主题。
为准确识别核心用户所属的兴趣群组,本研究采用Hellinger距离算法,通过式(11)和式(12)计算不同用户间的文本语义相似度,分析用户所属的群组及所属的偏好程度,得到群组划分,结果如表14所示。可以发现,ID为583、3075、39723的用户偏好程度分别与科技管理、数据挖掘和图书情报的主题更为接近,与用户583兴趣相似的有用户42818、38036、53483等。
3.4群组兴趣漂移模型构建
基于核心用户群组识别的结果,为探究群组兴趣漂移特征,本文结合滑动时间窗口法进行研究,以180天为固定时间窗口处理数据。随机选取Croup3作为样本进行分析,将兴趣数定为5个,通过主题提取得到2021年8月-2022年7月这4个时间窗口下的群组兴趣,表15展示了Group3在不同时间窗口下各主题—特征词分布。
经过训练得到用户归属各个偏好主题的概率,通过式(13)对群组内用户偏好进行概率融合,得到群组兴趣特征表示。以Tl时间窗口下Group3用户偏好融合为群组偏好的过程为例,结果如表16所示,最终得到Croup3分别在4个连续时间窗口下融合后的兴趣偏好特征向量,如表17所示。
根据前文构建的兴趣漂移发现算法,对选取的Croup3实证数据进行分析,通过式(14)计算得到T1时间窗下的5个初始兴趣值及它们在连续时间窗口下的兴趣衰减结果Wt,g,u如表18所示,可以看到随着时间窗口的移动,对应的兴趣度在逐渐降低,这一结果符合人们的遗忘规律。同时,根据实证数据的特征,将判断兴趣是否发生漂移的阈值Rt,g,u设为0.2,即如果计算得出的兴趣衰减结果小于0.2,则该兴趣值在当前时间窗口下处于较低状态,将被新的兴趣所替代。
依据表14中T2时间窗下的兴趣特征通过式(15)和式(16)计算Group3对5个初始兴趣在T2时间窗口下的兴趣衰减情况,如表19所示。从中可以看出,初始状态下的兴趣值Rt,g,u均出现衰减,但“智能控制科学”和“应急管理”的兴趣值仍处于一定水平,其余3个的衰减结果均低于本文设置的阈值0.2,将被替代。为了补充当前时刻下产生的新兴趣,分别计算T2窗口下的兴趣与Tl窗口下5个兴趣的相似度之和的均值,选择结果最大的前3个兴趣予以保留,作为T2时间窗下的兴趣漂移结果,即“智能控制科学”“应急管理”“数字化服务系统”“图像神经网络”“系统仿真建模”。在后续时间窗口下,对用户的兴趣漂移发现示意图如图3所示,其最终结果如表20所示。
3.5融合多维特征与兴趣漂移的群组推荐
本文选取2022年8月—10月Group3群组中的用户博文数据作为测试集,用以判断群组兴趣漂移过程模型的优劣。通过兴趣漂移模型可以得到在下一个时间窗口的漂移结果为:智能控制科学、数字化服务系统、图像神经网络、系统仿真建模和人工智能决策,将其与下一时间窗中真实数据集的各个主题作对比,分别为平行智能与元宇宙、网络合作机制、视频文本主题分析、深度学习模型以及人工智能决策模型,计算语义相似度作为判断依据,可以使其预测准确率达到80%,且大多围绕人工智能、深度学习、神经网络等领域,与实际情况相符,由此可以得出本文提出的群组兴趣漂移模型较为合理,且预测准确率较高。
同时对2017—2022年近5年的核心用户博文数据随机划分为80%的训练集与20%的测试集,采取准确率(Precision)和均方根误差(RMSE)用以评价群组推荐的效果。准确率是评价模型优劣的重要指标,表示预测出的兴趣主题与实际的兴趣主题有多少是相符的,准确率的计算式(18)如下:
式中,Precision指推荐结果的准确率,R(g)是根据群组在训练集中的行为为群组推荐的列表,而T(g)是群组在测试集上的行为列表。
均方根误差(RMSE)是计算预测内容与真实内容之间的偏差,该值越低,说明预测准确度越高,反之则说明推荐效果不佳,计算式(19)如下:
实验1:群组数对推荐效果的影响
群组推荐算法的推荐基本单位是用户群组,群组偏好源于组内每名成员,因此群组规模数将对群组偏好的融合结果产生关键性的影响,为探究群组数量对推荐算法准确度的影响,实验对比了本文提出的融合多维特征与兴趣漂移的群组推荐模型在不同的群组数目下的推荐准确度,如图4所示。
从中观察群组数量对推荐效果的影响,可以看到随着群组数量的增多,即群组规模的减少,算法准确度在不断提高,当组内用户数量不断减少时,对群组的推荐可以视为对个体用户进行推荐,组内差异较小,融合后的群组偏好更接近组内用户真实偏好,故推荐效果好。但进行群组推荐时,组数划分也不宜过小,不仅会失去划分群组的意义,还会影响整体群组推荐效果;另外,选取合适的群组数目,将有助于推荐算法准确性的提高。
实验2:不同推荐算法的对比实验
为了进一步分析所融合的各因素对本文模型的影响,在数据集上进行消融对比实验,将消融模型分为5组,第一组模型为传统的协同过滤群推荐算法模型(CFGRA),第二组模型为仅考虑多维特征对核心用户进行协同过滤群组推荐算法(CFGRA-MCU),第三组模型为仅考虑群组兴趣偏好的协同过滤群组推荐算法(CFCRA-UIP),第四组模型为融合多维特征与考虑群组兴趣偏好的协同过滤群推荐算法(CFGRA-MCU-UIP),第五组表示本文所提出的模型(CFGRA-MCU-UID)。实验选择群组数K=20,近邻群组数在4-16之间,分别对这5种消融模型在Precision和RMSE下进行对比实验,结果如图5与图6所示。
在逐步融合各因素的推荐算法对比实验中可以看出随着近邻数K的增加,二者的值均逐渐降低并趋于稳定,并且随着算法中加入因素的增多,消融模型的整体推荐效能不断提高且均优于不考虑融合任何因素的传统群组推荐模型(CFGRA)。在只考虑单一因素的模型算法中,推荐性能得到一定的提升但仍有待提高。由此在所有指标测试中,本文提出的模型效果最好,说明该算法模型可以提高推荐性能,很好地预估群组中用户的兴趣变化,产生更好的推荐结果。
4结语
本文首先从网络传播维度和网络结构维度出发,基于信息熵相关理论结合点度中心性、接近中心性、中介中心性和引入属性特征的PageRank值4个指标,借鉴OLEI指数融合多维特征数据综合识别核心用户;其次利用LDA模型、Gibbs采样和Hellinger距离对核心用户潜在群组聚类,得到群组划分;最后挖掘连续时间窗口下群组动态兴趣漂移规律,将群组兴趣变化引入协同过滤群组推荐算法中进行推荐。通过采集“科学网”社区内部分用户信息并使用Python、Java程序进行模拟,以Precision和RMSE作為检验标准,发现该模型可以准确识别核心用户,并且能够较好地反映群组用户兴趣漂移过程,同时,对比传统的群组协同过滤法及仅考虑单一因素的推荐算法,本文提出的算法准确率更高,且推荐准确度与群组数量呈正相关,为后续研究确定最优群组数提供依据。综上所述,融合多维特征与兴趣漂移的虚拟学术社区群推荐模型可以有效解决虚拟学术社区中知识推荐效率不佳的问题,进而带来服务方式的创新,还可以促进高效的知识资源整合,进一步提升对核心用户的知识服务质量,同时弥补群组协同过滤算法中忽略群组兴趣漂移带来的缺陷,促进社区内知识共享与流转效率,实现社区的高质量发展。
