
基于深度Q网络的近距空战智能机动决策研究
2023-07-20 01:25张婷玉孙明玮王永帅陈增强
航空兵器 2023年3期
关键词:空战
张婷玉 孙明玮 王永帅 陈增强

摘要:针对近距空战对抗中无人机机动决策问题, 本文基于深度Q网络(DQN)算法的框架, 对强化学习奖励函数设计以及超参数的选择问题进行了研究。 对于强化学习中的稀疏奖励问题, 采用综合角度、 距离、 高度和速度等空战因素的辅助奖励, 能够精确描述空战任务, 正确引导智能体的学习方向。 同时, 针对应用强化学习超参数选择问题, 探究了学习率、 网络节点数和网络层数对决策系统的影响, 并给出较好的参数选择范围, 为后续研究参数选择提供参考。 空战场景的仿真结果表明, 通过训练智能体能够在不同空战态势下学习到较优的机动策略, 但对强化学习超参数较敏感。
关键词:空战; 自主机动决策; 深度强化学习; DQN; 奖励函数; 智能机动; 参数选择
中图分类号: TJ76; V212.13文献标识码:A文章编号: 1673-5048(2023)03-0041-08
DOI: 10.12132/ISSN.1673-5048.2022.0251
0引言
伴随着现代战争的信息化和智能化, 空战战场上使用無人机的趋势日益明显, 无人作战飞机(Unmanned Combat Aerial Vehicle, UCAV)逐渐成为未来空战的主力武器[1-2]。 目前UCAV大多采用地面人员遥控的作战模式, 很难适用于复杂多变的空战环境。 因此, 提升UCAV的智能化水平是打赢未来空战的军事需求[3]。 飞行器自主机动决策技术是提高空战自主能力与智能化水平的关键技术, 能够准确感知空战环境并生成合理机动决策的自主机动决策方法是各国军事技术的研究重点[4]。
现有的空战决策方法分为两类: 一类是非学习策略, 另外一类是自学习策略。 非学习策略的求解过程主要采用优化理论, 包括专家系统[5-6]、 微分对策[7-8]、 矩阵博弈[9-10]等方法。 而自学习空战决策方法的核心是用智能算法对空战决策过程建模, 并根据训练产生的经验对决策模型参数进行优化。 典型的自学习策略算法包括遗传算法[11]、 动态规划算法[12]和强化学习算法等。 丁林静等人采用动态模糊Q学习模型, 提出了基于强化学习的无人机空战机动决策方法[13], 但由于空战问题的复杂性, 使传统强化学习算法无法解决连续状态空间问题, 会存在维度限制问题。
近年来, 深度强化学习在多种决策问题中均有一定突破, 为解决空战对抗中飞行器机动决策问题提供了新思路。 目前, 深度强化学习在空战对抗中的运用主要有基于值函数的Q学习方法和基于策略搜索的Actor-Critic方法。 张强等人提出一种基于Q-network强化学习的超视距空战机动决策方法[14]。 Zhang等应用DQN(Deep Q-Network)算法研究了二维平面的空战机动决策问题, 针对DQN算法初始随机探索效率低的缺点, 提出利用专家知识提高探索效率, 加快训练时间[15]。 Yang等基于DDPG(Deep Deterministic Policy Gradient)算法构建空战决策系统, 针对DDPG算法缺少空战先验知识、 导致数据利用率低的问题, 提出向经验池加入已有机动决策系统的样本数据, 加快算法收敛速度[16]。 吴宜珈等通过改进PPO(Proximal Policy Optimization)算法, 优化策略选择过程, 提高决策效率[17]。 上述文献主要关注对深度强化学习算法的改进, 对于适用于一对一空战的奖励函数以及强化学习超参数选择问题没有过多研究。 在深度强化学习方法应用过程中, 超参数的整定以及超参数的调整是否会带来性能的影响, 是一个值得研究的问题。
本文针对三维空间中无人机一对一近距对抗问题开展研究, 采用强化学习框架对空战问题进行建模; 针对强化学习的稀疏奖励问题, 考虑加入能够准确描述空战任务的辅助奖励, 设计一对一空战的机动决策奖励, 提出了基于DQN算法的自主机动决策方法; 针对深度强化学习超参数选取问题, 探究超参数对决策系统的影响, 并设置空战场景进行仿真, 验证机动决策方法的有效性。
1空战机动决策问题描述及建模
1.1近距空战问题描述
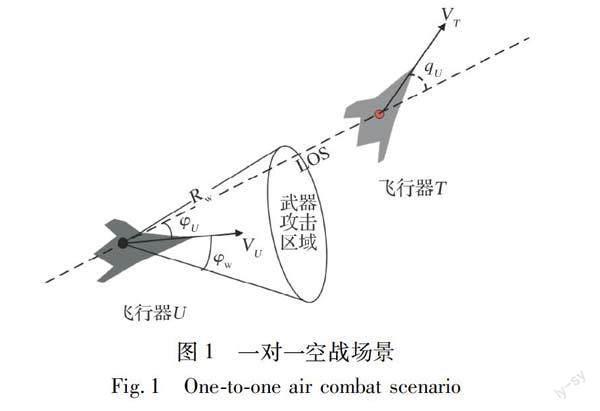
空战问题可用OODA环描述, 即完成空战的观察(Observe)、 判断(Orient)、 决策(Decide)和执行(Action)回路(简称OODA回路)。 结合OODA回路描述, 自主空战被定义为在瞬息万变的复杂战场环境中感知并认知战场态势和目标意图, 对武器和机动动作快速做出最优的决策策略, 并控制飞机精确执行机动指令。 空战决策是自主空战的核心。 本文所研究的空战场景为近距一对一空战, 如图1所示。
一对一空战机动决策的目的是在双方交战过程中, 使我方尽量处于空战态势的优势地位, 即尽可能让敌方进入我方的武器攻击区域, 同时避免自身落入敌方的武器攻击区域。 典型的武器攻击区域是攻击机的前方一定距离和角度的锥形范围。
1.2UCAV运动学模型
飞行器的运动学模型是空战机动决策模型的基础, 本文研究的重点是机动策略, 不考虑姿态等, 故将飞行器看作三维空间中的一个质点, 采用三自由度质点模型。
基于动力学基本定理, 飞行器在惯性坐标系下的三自由度质点运动模型为[18]
式中: v为飞行器的速度; x, y, z为飞行器质心在惯性坐标系中的坐标值; γ, ψ, μ为飞行器的俯仰角、 航向角和滚转角; nx为切向过载, 表示飞行器在速度方向上受到的推力与自身重力的比值; nz为法向过载, 提供飞行器所需的升力[18]。 本文所选取飞行器机动模型的控制量为nx, nz, μ。
2基于DQN的机动决策方法
2.1系统框架
深度Q网络(Deep Q-Network, DQN)是將传统强化学习方法Q-learning与深度神经网络相结合的一种算法。 DQN用深度神经网络代替Q表, 解决了Q表存储限制问题; 引入目标网络来计算目标Q值, 采用暂时参数冻结的方法切断Q网络更新时的相关性, 有效避免了Q估计值不收敛的问题。 DQN算法的框架如图2所示。
空战格斗的机动决策是一个序贯决策过程, 强化学习正是一种求解序贯决策问题的优化方法,故将机动决策问题建模为连续状态空间和离散动作空间的强化学习问题。 强化学习算法为无人机进行动作选择, 我机与目标机的状态形成空战环境的描述, 当前空战态势的评估结果返回强化学习算法中。 决策系统的框架如图3所示。
2.2UCAV的强化学习环境构建
2.2.1状态空间
本文选择空战态势信息作为状态变量, 它将为无人作战飞机机动决策提供必要的信息支撑。 空战态势信息的几何关系如图4所示。
状态变量包括我机与目标机距离R、 我机与目标机的距离变化率R·、 我机方位角φU、 我机进入角qU、 两机的速度方向的夹角χ、 两机的飞行高度差Δh以及两机的飞行速度差Δv。 除态势信息外, 还引入我机的当前飞行高度zU和飞行速度vU作为状态变量。 因此, 本文设计的系统状态空间向量为
2.2.2动作空间
飞行器的机动过程可视作一些基本机动动作的组合[19], 因此本文选择由美国NASA提出的“基本机动动作库”作为动作空间[20], 其包括7个基本操纵方式: 定常飞行、 加速、 减速、 左转、 右转、 向上拉起和向下俯冲。 飞行器可通过连续多步的基本动作选择,从而组合出不同战术动作。
飞行器机动动作的控制量为切向过载nx、 法向过载nz和滚转角μ, 考虑飞行器结构特性对过载的限制, 本文切向过载的取值范围为nx∈[-2,2], 法向过载的取值范围为nz∈[-4,4], 滚转角的取值范围为μ∈[-π/3, π/3][21]。 实际每次执行机动动作过程中均采用最大过载, 机动动作所对应的控制指令如表1所示[21]。
2.2.3奖励函数
忽略武器攻击误差等因素, 设定当两机距离R小于武器攻击范围Rw, 方位角小于武器最大攻击角度φw且进入角小于qw时达到目标状态, 可获得最终奖励rfinal:
为了避免飞行器在飞行过程中失速、 飞行过低或过高、 远离目标或与目标发生碰撞, 本文设置来自于环境的惩罚函数re:
综合建立的强化学习环境、 神经网络结构及探索策略, 本文提出基于深度Q学习的机动决策算法, 算法1描述了基于深度Q学习的机动决策算法过程。
算法1: 基于深度Q学习的飞行器机动决策过程。
输入: 状态空间S, 动作空间A, 初始神经网络, 训练参数。
输出: Q网络参数。
1: 初始化经验回放缓冲区D, 容量为N。
2: 初始化在线Q网络及随机权重θ。
3: 初始化目标Q网络, θ-=θ。
4: 初始化ε=1。
5: for episode = 1, 2, do:
6: 初始化状态双方飞行器的状态, 获取当前态势。
7: if episode为N的倍数then。
8: 进行评估, 评估时ε=0。
9: endif
10: for step = 1, 2, …, T do。
11: 以ε的概率从7个基本动作中随机选择一个动作, 否则, 选
择动作at=argmaxaQ(st, a, θ)。
12: 执行动作at, 得到奖励rt, 进入下一状态st+1。
13: 将[st, at, rt, st+1]存储到D中; 判断该空战回合是否结
束。
14: end for
15: 从D中随机抽取一批样本[sj, aj, rj, sj+1]。
16: 定义amax=argmaxa′Q(sj+1, a′, θ)。
17: 令yj=rj, 达到目标状态rj+γQ(sj+1, aj, θ-), 未达目标状态
18: 根据目标函数(yj-Q(sj, aj, θ-))2, 使用梯度下降法更新
权重θ。
19: 每隔C轮, 更新目标Q网络, θ-←θ。
20: 逐步减小ε的值, 直至εmin。
21: end for
3仿真与分析
3.1强化学习超参数探究
在目标飞行器进行匀速直线运动且双方初始相向飞行的场景下, 探究强化学习超参数对机动决策的影响。
3.1.1学习率
学习率决定目标函数能否收敛以及何时收敛。 本文在网络结构不变且三个隐藏层均为64个节点的情况下, 探究学习率对机动决策系统的影响。 由于计算机性能限制, 训练耗费时间较长, 仅选择三组对照, 所设置的三个实验组的学习率分别是0.01、 0.001以及0.000 1。
各学习率学习曲线如图7所示, 横坐标为训练次数, 纵坐标为用30回合计算平均值进行平滑后的累计奖励值。 结果表明, 学习曲线整体均呈上升趋势, 学习率影响收敛速度。 当α=0.01时, 在训练次数大于700次后奖励值下降成为负值; 当α=0.000 1时, 未出现收敛趋势, 且奖
励值为负值, 说明智能体尚未探索出较好的机动策略; 当α=0.001时, 奖励值随训练次数增加逐步提高, 且有收敛趋势。 可见, 学习率过低会延长训练时间, 学习率过高可能会达到局部最优结果或发散。 因此, 针对飞行器机动决策问题, 学习率设置为0.001较为合理。
3.1.2神经網络节点
在深度神经网络输入层及输出层结构不变且均为3个隐藏层的情况下, 探究节点数对决策系统性能的影响。
一般情况, 神经网络节点数设置为2的N次方, 另外在深度学习中, 设置倍数关系的节点数才会有区别。 因此, 三个实验组的隐藏层节点数分别是[32, 64, 32]、 [64, 128, 64]和[128, 256, 128]。
三个实验组的学习曲线如图8所示。 实验结果表明, 节点数将会影响收敛速度或者是否收敛, 同时神经网络宽度越大也会耗费更长的训练时间。 学习曲线均有收敛趋势, 第二组收敛速度更快。 强化学习的训练数据比监督学习稳定性低, 无法划分出训练集与测试集来避免过拟合, 因此深度强化学习无需用过宽的网络, 避免参数过度冗余导致过拟合。 用深度强化学习解决空战中飞行器的机动决策问题时, 节点数可选择64或128。
3.1.3神经网络层数
在深度神经网络的输入层及输出层结构不变且每个隐藏层均为64个节点的情况下, 探究神经网络层数对机动决策系统的影响。 设计三个实验组的隐藏层数分别是3层、 4层和5层。 三个实验组的学习曲线如图9所示。
由图9可知, 3层隐藏层的神经网络有收敛趋势, 4层和5层的神经网络则没有明显的收敛趋势, 可能出现过拟合情况。 由仿真可知, 隐藏层数对决策系统收敛性影响较大。 因此, 解决空战机动决策问题时, 可使用有3层隐藏层的深度神经网络。
3.2仿真结果与讨论
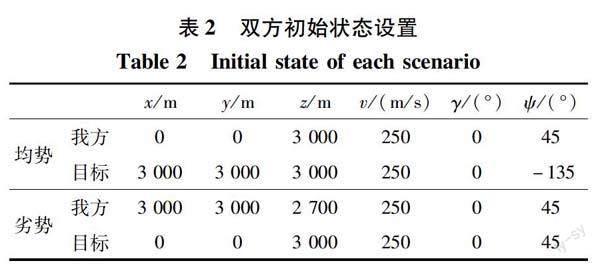
目标机进行匀速直线运动的场景下, 设置目标飞行器一直采取定常飞行的机动动作, 对我方无人机进行强化学习训练。 我机分别以均势和劣势的初始状态进行机动。 均势初始状态指双方相互朝向对方, 劣势初始状态指目标机从后方追赶我机。 初始状态设置如表2所示。
首先设置双方相对飞行, 初始态势为均势。 记录每个回合对战训练的飞行数据, 通过Matlab绘图可视化交战双方的飞行轨迹, 可更加直观地展示机动决策结果。
经过训练, 智能体能够探索出针对当前初始态势较好的机动策略, 轨迹如图10所示。 初始时双方为相向飞行, 我方飞行器在目标向我方靠近时采取拉升高度的机动动作, 主动脱离目标机的武器攻击区域; 而后通过筋斗动作调转方向, 朝向目标机飞行; 降低高度接近目标机, 调整机头方向, 进入优势攻击位置。
在初始态势为劣势的情况下, 智能体经过训练后选择的飞行策略如图11所示。 初始时, 目标机位于我机后方, 我方无人机初始处于劣势, 且飞行高度低于目标机, 我方通过机动决策首先拉升高度以脱离目标机武器攻击范围的同时, 获得重力势能优势; 而后进行“筋斗”翻转绕至目标后方, 从而转变了空战态势, 使我机处于优势攻击角度; 再降低高度接近目标, 使得目标机进入我方的武器攻击范围, 成功锁定目标机, 该机动决策符合空战中真实的无人机格斗战略。
在目标机进行盘旋机动的场景下, 设置目标机始终采取向右水平盘旋机动动作, 双方的初始状态与直线飞行均势初始场景的设置相同。
图12展示了部分回合的双方飞行轨迹。 在训练前期, 智能体处于随机探索阶段, 可能会飞出限定高度或者失速等, 环境会给予较大的惩罚, 通过与环境的不断交互, 智能体能够逐渐探索出获得奖励值较高的决策策略。 图12(a)中智能体一直采取定常飞行的策略, 获得累计回报较低, 在后续训练中智能体尝试抬升高度并调转机头方向等动作, 如图12(b)~(d)所示, 有逐步向目标方向飞行的趋势, 能够探索出较为合理的飞行策略, 但效果尚不理想。
以上3个情景的仿真表明: 无人机的动作选择策略在经训练后能够依据态势输出较为合理的连续动作控制量, 对不同的情景及初始态势决策效果有所不同, 但均具有适应性, 具备一定空战能力。 由表1和仿真结果可知, 采用确定的控制指令对飞行器进行训练能保证基本任务完成, 而难以在复杂场景中取得明显优势。 为提升复杂飞行场景下该算法的优越性, 后续将考虑采用连续动作空间, 丰富机动动作的控制指令。
同时, 通过采取同一实验场景的超参数取值, 对不同场景进行测试, 由图10~12可以看出, 该超参数取值的训练结果在目标机匀速直线飞行的场景中更具飞行优势。 结果表明, 强化学习超参数选择较为合理且具有一定的适应能力, 能适用于多种飞行场景, 一定程度上能够解决超参数整定繁冗问题。 此外, 超参数对不同场景的适应能力问题, 仍值得进一步探索。
4结论
本文针对三维空间中的一对一空战机动决策问题进行了研究, 将机动决策问题建模为连续状态空间以及离散动作空间的强化学习问题, 设计奖励函数并提出了基于深度Q网络的机动决策方法。 仿真结果表明, 该方法能够在简单场景下探索出较合理的机动策略, 但对学习率等强化学习超参数较敏感。
未来工作及改进方向有: (1)构建目标机的机动决策系统, 使其也具备自主决策能力, 更加符合真实空战场景; (2)机动决策系统的动作空间可采用更加符合真实飞行员操纵动作的连续动作空间。
参考文献:
[1] 姜进晶, 汪民乐, 姜斌. 无人机作战运用研究[J]. 飞航导弹, 2019(1): 41-44.
Jiang Jinjing, Wang Minle, Jiang Bin. Research on UAV Combat Application [J]. Aerodynamic Missile Journal, 2019(1): 41-44.(in Chinese)
[2] 范晋祥, 陈晶华. 未来空战新概念及其实现挑战[J]. 航空兵器, 2020, 27(2): 15-24.
Fan Jinxiang, Chen Jinghua. New Concepts of Future Air Warfare and the Challenges for Its Realization[J]. Aero Weaponry, 2020, 27(2): 15-24.(in Chinese)
[3] 鲜勇, 李扬. 人工智能技术对未来空战武器的变革与展望[J]. 航空兵器, 2019, 26(5): 26-31.
Xian Yong, Li Yang. Revolution and Prospect of Artificial Intelligence Technology for Air Combat Weapons in the Future[J]. Aero Weaponry, 2019, 26(5): 26-31.(in Chinese)
[4] 孙智孝, 杨晟琦, 朴海音, 等. 未来智能空战发展综述[J]. 航空学报, 2021, 42(8): 525799.
Sun Zhixiao, Yang Shengqi, Piao Haiyin, et al. A Survey of Air Combat Artificial Intelligence[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42(8): 525799.(in Chinese)
[5] Goldsmith T E, Schvaneveldt R W. Representing and Training Expertise in Air Combat Maneuvering[R]. Las Cruces: New Mexico State University, 1987:1-55.
[6] Burgin G H, Sidor L B. Rule-Based Air Combat Simulation[R]. Washington D C: NASA, 1988.
[7] Othling W L. Application of Differential Game Theory to Pursuit-Evasion Problems of Two Aircraft: DS/MC/67-1[R]. Ohio: Air Force Institute, 1970.
[8] Miles S, Williamson-Noble D. Toward a Differential Game Solution to a Practical Two Aircraft Pursuit-Evasion Problem in Three-Dimensional Space: GA/MC/71-5[R]. Ohio: Air Force Institute, 1970.
[9] Austin F, Carbone G, Falco M, et al. Game Theory for Automated Maneuvering during Air-to-Air Combat[J]. Journal of Guidance, Control, and Dynamics, 1990, 13(6): 1143-1149.
[10] 邓可, 彭宣淇, 周德云. 基于矩阵对策与遗传算法的无人机空战决策[J]. 火力与指挥控制, 2019, 44(12): 61-66.
Deng Ke, Peng Xuanqi, Zhou Deyun. Study on Air Combat Decision Method of UAV Based on Matrix Game and Genetic Algorithm[J]. Fire Control & Command Control, 2019, 44(12): 61-66.(in Chinese)
[11] Kaneshige J, Krishnakumar K. Artificial Immune System Approach for Air Combat Maneuvering[C]∥ Intelligent Computing: Theory and Applications V, 2007, 6560: 68-79.
[12] McGrew J S, How J P, Williams B, et al. Air-Combat Strategy Using Approximate Dynamic Programming[J]. Journal of Gui ̄dance, Control, and Dynamics, 2010, 33(5): 1641-1654.
[13] 丁林靜, 杨啟明. 基于强化学习的无人机空战机动决策[J]. 航空电子技术, 2018, 49(2): 29-35.
Ding Linjing, Yang Qiming. Research on Air Combat Maneuver Decision of UAVs Based on Reinforcement Learning[J]. Avionics Technology, 2018, 49(2): 29-35.(in Chinese)
[14] 张强, 杨任农, 俞利新, 等. 基于Q-Network强化学习的超视距空战机动决策[J]. 空军工程大学学报: 自然科学版, 2018, 19(6): 8-14.
Zhang Qiang, Yang Rennong, Yu Lixin, et al. BVR Air Combat Maneuvering Decision by Using Q-Network Reinforcement Learning[J]. Journal of Air Force Engineering University: Natural Science Edition, 2018, 19(6): 8-14.(in Chinese)
[15] Zhang X B, Liu G Q, Yang C J, et al. Research on Air Combat Maneuver Decision-Making Method Based on Reinforcement Learning[J]. Electronics, 2018, 7(11): 279.
[16] Yang Q M, Zhu Y, Zhang J D, et al. UAV Air Combat Autonomous Maneuver Decision Based on DDPG Algorithm[C]∥ IEEE 15th International Conference on Control and Automation, 2019: 37-42.
[17] 吴宜珈, 赖俊, 陈希亮, 等. 强化学习算法在超视距空战辅助决策上的应用研究[J]. 航空兵器, 2021, 28(2): 55-61.
Wu Yijia, Lai Jun, Chen Xiliang, et al. Research on the Application of Reinforcement Learning Algorithm in Decision Support of Beyond-Visual-Range Air Combat[J]. Aero Weaponry, 2021, 28(2): 55-61.(in Chinese)
[18] 吴昭欣. 基于深度强化学习的飞行器自主机动决策方法研究[D]. 成都: 四川大学, 2021.
Wu Zhaoxin. Research on Autonomous Maneuvering Decision Method for Aircraft Based on Deep Reinforcement Learning[D]. Chengdu: Sichuan University, 2021. (in Chinese)
[19] Yang Q M, Zhang J D, Shi G Q, et al. Maneuver Decision of UAV in Short-Range Air Combat Based on Deep Reinforcement Learning[J]. IEEE Access, 2019,8: 363-378.
[20] Austin F, Carbone G, Falco M, et al. Automated Maneuvering Decisions for Air-to-Air Combat[C]∥ Guidance, Navigation and Control Conference, AIAA, 1987: 2393.
[21] 董肖杰, 余敏建, 宋帅. 空战机动动作库及控制算法设计研究[C]∥第五届中国指挥控制大会论文集, 2017: 188-193.
Dong Xiaojie, Yu Minjian, Song Shuai. Research on the Design of Air Combat Maneuver Library and Control Arithmetic of Movements[C]∥ Proceedings of the 5th China Command and Control Conference, 2017: 188-193.(in Chinese)
[22] 李永丰, 史静平, 章卫国, 等. 深度强化学习的无人作战飞机空战机动决策[J]. 哈尔滨工业大学学报, 2021, 53(12): 33-41.
Li Yongfeng, Shi Jingping, Zhang Weiguo, et al. Maneuver Decision of UCAV in Air Combat Based on Deep Reinforcement Learning[J]. Journal of Harbin Institute of Technology, 2021, 53(12): 33-41.(in Chinese)
Research on Intelligent Maneuvering Decision-Making in Close Air Combat Based on Deep Q Network
Zhang Tingyu1, Sun Mingwei2, Wang Yongshuai1, Chen Zengqiang1
(1. College of Artificial Intelligence, Nankai University, Tianjin 300350, China; 2. Key Laboratory of Intelligent Robotics of Tianjin, Tianjin 300350, China)
Abstract: Aiming at the problem of UCAV maneuvering decision-making in close air combat, the design of reinforcement learning reward function and the selection of hyper-parameters are studied based on the framework of deep Q network algorithm. For the sparse reward problem in reinforcement learning, an auxiliary reward function that considers angle, range, altitude and speed factors is used to describe the air combat mission accurately and guide the learning direction of the agent correctly. Meanwhile, aiming at the problem of applying reinforcement learning hyper-parameter selection, the influence of learning rate, the number of network nodes and network layers on the decision-making system is explored, and a good range of parameter selection is given, which provides a reference for the following research on parameter selection. The simulation results show that the trained agent can learn the optimal maneuver strategy in different air combat situations, but it is sensitive to reinforcement learning hyper-parameters.
Key words: air combat; autonomous maneuvering decision-making; deep reinforcement learning; DQN; reward function; intelligent maneuver; parameter selection
收稿日期: 2022-11-22
基金項目: 国家自然科学基金项目(62073177; 61973175)
作者简介: 张婷玉(2000-), 女, 河北衡水人, 硕士研究生。
*通信作者: 孙明玮(1972-), 男, 北京人, 教授。
猜你喜欢
小哥白尼(军事科学)(2022年1期)2022-04-26
小哥白尼(军事科学)(2021年9期)2022-01-17
小哥白尼(军事科学)(2020年11期)2021-01-18
小哥白尼(军事科学)(2020年9期)2021-01-18
小哥白尼(军事科学)(2019年3期)2019-06-26
小哥白尼(军事科学)(2018年2期)2018-05-25
军营文化天地(2017年6期)2017-06-28
百科探秘·航空航天(2015年10期)2015-11-07
百科探秘·航空航天(2015年2期)2015-11-07
军事历史(2000年3期)2000-08-16
