
基于宽度学习系统的仓储粮情风险点预测模型
2023-07-20 00:12廉飞宇付麦霞
河南工业大学学报(自然科学版) 2023年3期
廉飞宇,秦 瑶,付麦霞
河南工业大学 信息科学与工程学院,粮食信息处理与控制教育部重点实验室,河南 郑州 450001
粮食储备是保证我国粮食安全的重要举措。为了保证储粮安全,除了要实时监测储粮状态(简称粮情),还需要及时地预测仓储粮情的变化趋势。仓储粮情风险点预测,就是要预测一个时间点,储粮到了这个时间点,极有可能发生霉变和品质劣变而导致不可食用,必须进行人工处理。仓储粮情风险点的预测准确度与多种因素有关。相关研究表明,仓储粮情预测是一个十分复杂的问题[1],也是目前粮食储藏领域迫切需要解决的关键科技问题。
对于预测问题,传统机器学习的方法有线性回归(LR)、支持向量回归(SVR)[2]、随机森林[3]、ARIMA[4]、灰色预测模型[5]、BPNN[6]等,已经在很多领域得到了广泛应用。然而,粮情数据是十分复杂的,既有静态数据,又有动态数据,数据量庞大,数据的属性多样、特征多样,基于传统机器学习方法的预测模型很难对多源的大量粮情数据做出有效处理,从而导致这类预测模型通常只能采用部分数据对仓储粮情进行片面的预测,难以满足对“仓储粮情风险点”预测的实际需要。目前,深度学习算法得到了很大的发展和广泛的应用,其突出的优势在于可以自主地学习样本中隐含的深层次抽样特征,能够大大提高模型预测性能,从而成为构建仓储粮情风险点预测模型的一个不错的选择[7-8]。
深度神经网络的发展得益于高性能图形处理单元(GPU)的应用,但GPU是较昂贵的计算资源,在面临大数据训练时,深度神经网络需要学习的权重参数非常多,且由于其较多的中间层,使得深度神经网络在应用BP算法进行训练时不仅十分耗时,而且也易于碰到梯度消失或梯度爆炸的问题。粮情数据属于大数据,数据不仅维数高、规模大,而且大多呈动态增长态势,这无疑给利用粮情大数据训练基于深度学习的粮情风险点预测模型带来了巨大的困难。因此,构建一种简洁的、易于训练的神经网络模型,使其能够在保证模型精度的前提下,适应大规模动态粮情数据的建模和训练是十分必要的。
宽度学习[9-11]的提出从理论上为神经网络的出现提供了可能。采用宽度学习方式的神经网络称为宽度学习系统(broad learning system, BLS),它是在原有浅层神经网络的基础上,把网络向宽度方向拓展,并且把隐藏层拓展为由特征节点和增强节点组成的级联结构。宽度学习系统的训练通过对隐藏层到输出层的权重求伪逆完成,大大快于梯度下降法的求解速度,同时,宽度学习系统还可采用增量学习的方法快速更新模型[12]。由于宽度学习系统的这些优势,使其一经提出就受到重视,并已被成功应用于图像分类[13-14]、模式识别[15]、电力预测[16]、智能交通[17]等领域。作者基于现有的宽度学习基本理论,采用基于宽度学习的特征提取与融合方法,以及基于增量学习的训练方法,结合粮情数据的多模态特征,提出了基于宽度学习系统的粮情风险预测模型,有效地改善了深度学习方法模型复杂、训练速度慢、所需数据集规模大等不足,可作为粮情风险预测的一个可行的替代方案。
1 宽度学习系统
1.1 宽度学习系统基本网络结构
宽度学习系统(BLS)是在RVFLNN (随机向量函数链式神经网络)[18]的基础上产生的,其网络结构如图1所示。BLS的网络结构仍沿袭了传统的浅层神经网络的3层结构,不同的是BLS对其隐藏层进行了宽度方向的拓展,即隐藏层由多组特征节点和增强节点组成。需要说明的是,输入数据X不是直接与特征节点相连,而是经过某种映射后作为特征节点的值。
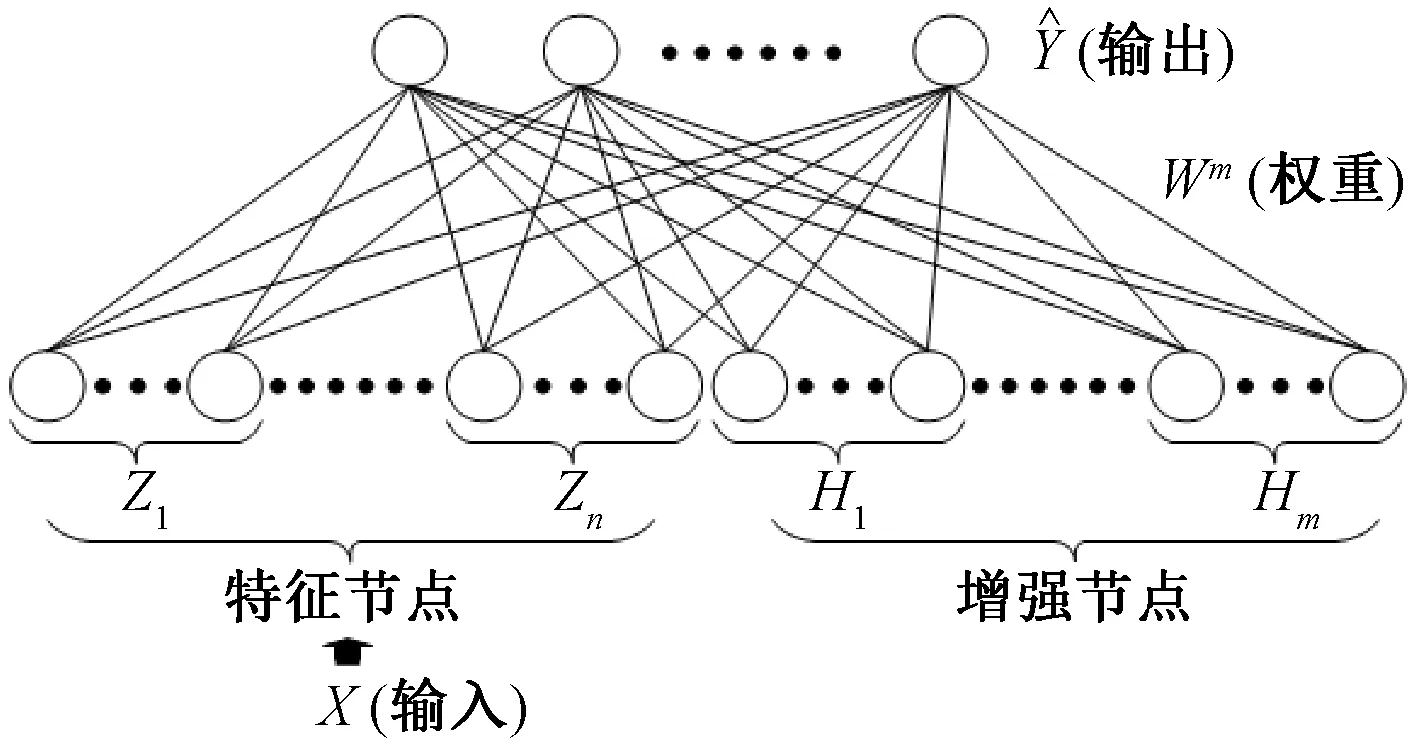
图1 宽度学习系统的基本网络结构
1.2 输入层
在BLS 输入层,神经元个数等于输入数据的属性数。如输入数据有M个属性,则第i个输入数据可表示为向量xi=(xi1,xi2,…,xiM)。如果一共有N条这样的输入数据,则有N个M维的输入向量,可用矩阵表示为X=(x1,x2,…,xi,…,xN)T。BLS对输入数据X进行批量处理,送入特征节点进行变换。由于输入数据的各属性具有不同的类型,为了方便处理,输入的原始数据一般都要经过归一化处理。
1.3 隐藏层
1.3.1 特征节点
由图1可知,BLS的隐藏层是一个由特征节点层和增强节点层构成的级联结构。设其特征节点层由n组节点Z1,Z2,…,Zn组成,且第Zi组节点又由q个神经元组成,则输入数据X经过Zi的特征映射后可表示:
Zi=φi(XWei+βei),i=1,2,…,n,
(1)
式中:φi是激活函数,可以选用常见的Sigmoid函数、ReLU函数等,各组映射的激活函数可以不同;Wei∈RM×q是网络的权重矩阵,初始值可随机产生;βei∈RN×q是偏置矩阵,初始值也是随机的,并且这两个矩阵可通过稀疏自编码器微调以提取输入数据中更为稀疏的特征。
1.3.2 增强节点
BLS的增强节点层可表示为H1,H2,…,Hm,假设其中的第j组增强节点Hj包含了r个神经元,则有来自特征节点层的矩阵Zn,经增强节点层后可得:
Hj=ξj(ZnWhj+βhj),j=1,2,…,m,
(2)
式中:ξj为激活函数,可以选用Sigmoid函数、ReLU函数等;Whj∈RNq×r为权重矩阵;βhj∈RN×r为偏置矩阵,其初始值均为随机值。
1.4 输出层
BLS的输出层既可以处理回归问题也可以处理分类问题。对于分类问题,BLS可采用独热码进行标签编码。如输入样本xi的标签为yi=(yi1,yi2,…,yiQ),Q为类别数,则独热码[0,0,1,…,0]表示输入样本是第3类。所有的标签可表示:
Y=(y1,y2,…,yi,…,yN)T,
(3)
式中:Y为标签矩阵。
输入样本X经过BLS后,得到输出概率矩阵:
(4)
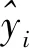
1.5 BLS的建模和求解
在BLS中,只有权重矩阵Wm需要训练,减少了BLS的训练量。BLS的训练基于以下目标函数:
(5)
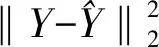
2 BLS的改进——增量学习
增量学习是指当有新增样本时,模型必须重新进行训练,而只需针对新增数据做增量的训练或局部的更新,这种训练方式可以使模型的更新更快捷,模型更新的代价也更小。文献[19]提出了动态更新的神经网络训练算法,该算法通过求取伪拟矩阵[20],给出了在有新增输入数据时,连接权重的快速更新方法。此后,增量学习也应用到了随机森林[21]、SVM[22]等机器学习算法中,逐渐成为机器学习领域中的一种重要的学习方法。将增强节点增量算法(EIBLS)和输入数据增量算法(IIBLS)用于改进传统宽度学习系统,以提高BLS模型分类精度。
2.1 EIBLS算法
EIBLS算法是保持网络中特征节点数量不变,增加增强节点的数量,以达到提升模型特征提取能力的学习算法,算法示意如图2所示。
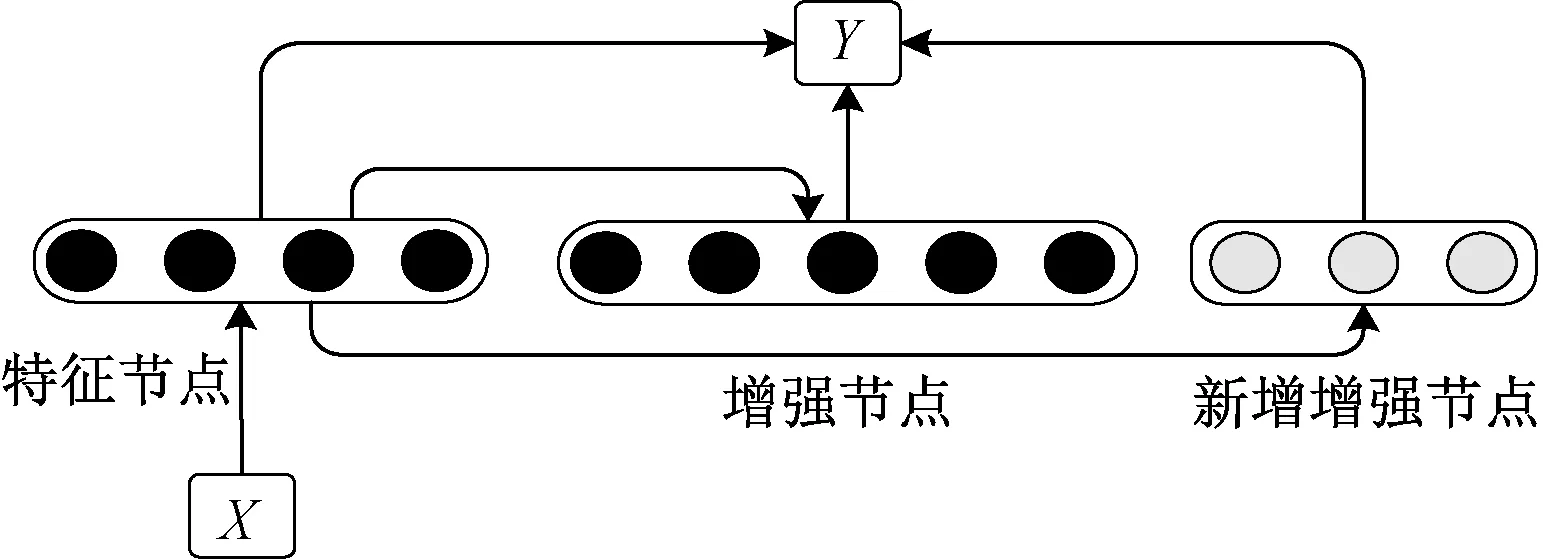
图2 BLS的增强节点增量算法
当模型增加了若干个增强节点,模型的隐藏层矩阵将由A=[Zn|Hm]扩展为Am+1=[A|ξ(ZnWm+1+βm+1)],其中Wm+1和βm+1是新增的权重矩阵和偏置矩阵,ξ是激活函数,符号“∣”表示两矩阵并置。由伪拟运算得到隐藏层矩阵的伪拟矩阵:
(6)
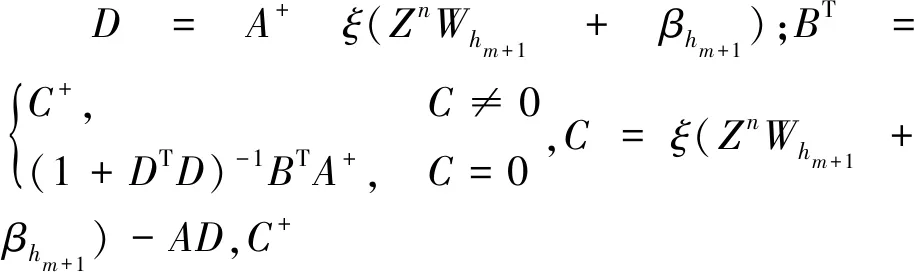
根据式(5)、(6),将隐藏层与输出层的连接权重Wm+1更新:
(7)
2.2 IIBLS算法
传统深度学习模型在输入数据增加时一般需要重新训练模型,费时费力;宽度学习模型在处理这一问题上表现了特殊的优势,可以采用IIBLS算法快速更新模型。
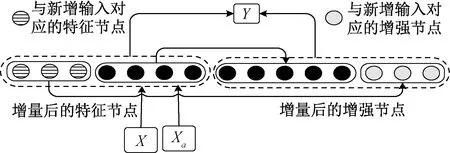
图3 BLS的输入数据增量算法
Ax=[φ(XaWe1+βe1),…,φ(XaWen+βen)|
(8)

(9)
对应的伪逆矩阵:
(10)


(11)
3 基于BLS的粮情风险预测模型
基于BLS的粮情风险预测模型框架如图4所示。仓储粮情数据是以温度、湿度、气体组成、虫情等多种模态形式存在的。通过融合多种模态的信息进行机器学习是模型构建的必要步骤。但现有宽度学习系统及其改进算法在进行模式分类或预测时还都是只针对单模态的数据。结合粮情数据的多模态特征,在宽度学习系统现有框架的基础上,提出基于宽度学习系统的粮情风险预测模型,模型如图4所示。该模型旨在通过学习和融合多种模态的数据以提高预测精度。
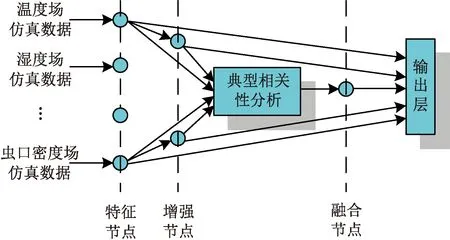
图4 仓储粮情风险预测模型框架
由图4可知,粮情风险预测模型在宽度学习系统的基础上增加了典型相关性分析(CCA)模块和特征融合节点。首先对多种模态的粮情数据进行初步的特征提取,然后输入到相关性分析模块进行相关性学习,再经过特征融合节点进行特征的融合,最后经输出层实现模式分类。该模型的优势在于相比于单一模态的分类模型,可以通过充分利用多模态的融合特征得到更高的分类性能。
CCA可以对两个数据集进行融合降维,把两个不同模态的数据集按照某一关联规则映射到同一个数据空间,如果是多个模态的数据集,可以采用级联的方式进行融合和映射。CCA的数学定义如下:
假设两个n维的数据集X={x1,x2,…,xn},Y={y1,y2,…,yn},通过映射基向量u和v的变换后,分别得到新的坐标空间,定义数据集X和Y的相关性参数:
(12)
式中:∑xy和∑xx、∑yy分别为类间和类内协方差矩阵,即
(13)
式(13)的相关计算实际上是一个优化问题,可以转化为特征值的求解问题。
假定模型的输入样本数为N,其特征节点和增强节点个数分别为N1和N2,则一种模态数据的特征表达式:X1=[Z1|H1],它由一个宽度学习单元生成,其特征节点和增强节点分别可表示:Z1={zi|zi∈RN1,i=1,…,N}和H1={hj|hj∈RN1,j=1,…,N};同理,另一种模态数据的特征表达式、特征节点和增强节点可以表示:X2=[Z2|H2],Z2={zi|zi∈RN2,i=1,…,N}和H2={hj|hj∈RN2,j=1,…,N},由另一个宽度学习单元生成。为了更好地学习两种模态数据的共同特征,需要先将它们混合再输入融合节点层。考虑到处理的方便性,仅简单地将两种模态的数据并联起来,作为最后提取的总特征和融合节点的净输入,即
FN×2(N1+N2)=[X1N×(N1+N2)|X2N×(N1+N2)]。
(14)
显然,F就是融合节点层的新输入。为了更好地融合不同模态的数据,引入融合节点映射层,借鉴传统神经网络的非线性拟合将不同模态特征抽象融合,最后利用输出矩阵进行特征学习,以提高模型分类性能。假定融合层节点的个数为N3,则融合节点层输出:
(15)
式中:φ(·)是一个S型非线性激活函数;Wt为融合节点层的权重;bt表示融合节点的偏置(偏移量);t对应前面T均表示输出。
4 试验结果与分析
4.1 数据获取与处理
试验数据来源于岳阳市某国家级储备库2019—2020年粮情测控数据。该粮库安装了全套的综合粮情测控系统,可测储粮温度、湿度、虫情和仓内气体成分,测控软件能以可视化的方式动态显示仓内温湿度云图、走势图等。试验共获取温湿度数据735条(每条数据包括仓内平均温度1项、粮堆各层平均温度、最高最低温度12项、仓内湿度1项、仓外温湿度各1项),粮情报表105个,温湿度云图图像76个,虫情报表20个,虫口密度图24个,气体成分报告10个。部分数据样本如图5所示。
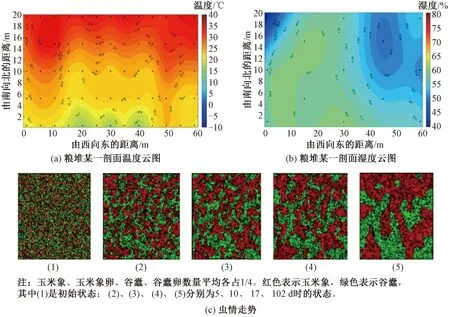
图5 粮情多模态数据部分样本
显然,获取的数据有两种类型(文本数据和图像数据)和多个模态(每个模态对应一种数据来源),其中图像数据由文本数据可视化生成。对文本数据进行预处理,将数据导出,剔除病态数据,形成温度、湿度、虫害、气体成分4种无格式纯文本文件,共计23 275个数据,将其中70%的数据作为训练集并标签化。图像数据100个,采用SamplePairing扩增至600个,采用Labelimg工具加标签。本文研究目的在于预测粮情风险等级,在预测前,将粮情风险划分为4个等级:正常、低风险、中风险和高风险。各风险等级定义如表1所示。

表1 粮情风险等级划分
需要说明的是,利用表1给出的粮情风险等级有其局限性,如夏季刚入仓的粮食温度可能高于正常指标。试验是通过人工的分析判断,形成了数据集各样本标签。数据集中各样本是以天为单位,1 d的粮情数据为1个样本。
将数据分为2组,文本数据和图像数据各一组,均由多种模态数据组成。将多模态的数据作为宽度学习系统网络模型的输入,通过图4所示的基于典型相关性分析模块,以提取到更深层次的粮情风险特征,从而提高模型的精准性。
由于粮情风险预测数据集是典型的不平衡数据集,正常数据占了大多数。为了提高以上各种风险数据占的比重,保证各类型数据的平衡,采用了COMSOL Multiphysics软件,对粮仓生态环境进行了仿真,并通过改变初始条件和人为设置参数,分别对低风险、中风险和高风险粮情进行了推演,取得了大量少数类型数据,并添加到训练数据集中,保证了数据集中数据类型的平衡性。最后,把数据按照8∶2分成训练集和测试集。
4.2 评价指标
准确率作为分类器评价指标对于非平衡数据有失公平,为了客观评价分类算法性能好坏,根据混淆矩阵评估算法性能。根据表2的混淆矩阵,引入查全率R(Recall)、查准率P(Precision)、F1-value值(F1)、G-mean值等定义。

表2 混淆矩阵
各指标定义如下:
式中:F1是查全率与查准率加权调和平均值;G-mean是正类准确率与负类准确率的综合指标。
4.3 试验设置
为了验证本文算法在小样本数据集上的性能,试验的初始训练数据仅为1 000个,然后样本每次增加1 000个,评估宽度学习的增量学习算法对模型的准确率的影响。试验的目的在于检验本文的宽度学习模型在保证预测准确率的前提下是否可以作为深度学习的替代方案。因此,本文与一些深度学习的方法进行了对比,主要在识别率、训练和测试时间以及参数的敏感性等方面做了评估。
试验中对比了基本BLS、级联特征映射的宽度学习(CFBLS)[13]、有限连接的级联特征映射宽度学习(LCFBLS)[13]方法。CFBLS改进了宽度学习模型的特征节点连接方式,采用了一种级联方式的连接结构。LCFBLS与CFBLS结构相似,但最后一组特征节点用来生成增强节点。同时,本文的增量式宽度学习方法还与长短期记忆网络(BiLSTM)模型、Transformer网络模型、SSD模型和YOLOv3等4种深度学习方法进行了对比。宽度学习算法BLS的初始参数设置为10×10个特征节点和100个增强节点,增强节点更新5次,每次增加100个增强节点。
损失函数采用直接分类损失,该损失是约束模型训练的最基础的损失,通过交叉熵损失衡量由全连接层实现的分类器的输出,其计算方法见式(16),其中,qi在i与真实标签y对应时取1,否则取0。
(16)
为了避免特征提取网络对当前任务产生过拟合而不适应新的检测任务或受到标记不准确的标签影响,在计算上述交叉熵损失时,引入了标签平滑策略,将待预测样本属于另一类的可能性也纳入衡量范围内,对交叉熵损失中的qi进行修改。
(17)
4.4 试验结果与分析
4.4.1 第1组数据试验结果与分析
为了证明提出的增量式宽度学习模型预测的有效性,利用文本数据对粮情风险预测模型进行建模,并比较采用EIBLS增量学习算法和IIBLS增量学习算法模型的预测精度。结果如表3和表4所示。

表3 EIBLS增量学习算法的结果

表4 IIBLS增量学习算法的结果
由表3和表4可知,随着在宽度学习中引入增量学习,模型的预测精度(F1)逐渐提高。由于IIBLS增量学习算法能为预测模型提供新的信息,在增强节点相同的条件下,比仅增加增强节点的EIBLS算法具有更好的预测精度。如在增强节点都是600的条件下,输入数据为6 000时的IIBLS模型预测精度比输入数据为1 000时的EIBLS提高了10%左右。但同时,输入数据的增加,带来了数据处理的开销增加,使得IIBLS模型的训练时间长于相同增强节点下的EIBLS的训练时间。
比较引入了增量学习的宽度学习模型与基本宽度学习模型、其他改进宽度学习模型和两种深度模型(BiLSTM和Transformer)在预测准确率、模型训练时间上的结果,BiLSTM参数设置如下:学习率0.001,卷积核窗口为(1,2,3,4),其中的每个LSTM 大小为128,采用Adam 优化器;Transformer的层数设为4,自注意力头的个数为8。使用相对位置编码长度为8,batch size数量为32,训练期间使用初始学习率为0.000 4的Ranger优化器,每迭代8个epoch学习率衰减为原来的4/5,训练过程中最大迭代次数设为30。在解码过程中使用Beam Search,集束大小设为3。训练数据量从1 000增加到6 000,对比结果如表5所示。

表5 本文模型与对比模型在第1组数据上的预测效果对比
由表5可知,综合了预测的精确率和训练时间,本文提出的方法,优于基本宽度学习模型和两种改进宽度学习模型,特别是本文模型在训练时间上,由于采用了增量学习的算法,训练时间大大减少。与两种常见的深度学习算法进行比较,IIBLS的预测精度和对比的两种深度学习方法非常接近,EIBLS方法也只有很小的差距,但本文的两种宽度学习模型训练时间大大少于两种深度学习模型。由此可以看出,本文的宽度学习模型在粮情风险预测上完全可以作为深度模型的替代模型。
4.4.2 第2组数据试验结果与分析
利用图像数据对粮情风险预测模型进行建模,并比较采用EIBLS增量学习算法和IIBLS增量学习算法模型的预测精度。所有图像被调整为224×224的分辨率,宽度学习网络基本模型感知域为4×4,特征图和池大小均为3。对比结果如表6和表7所示。

表6 EIBLS增量学习算法的结果

表7 IIBLS增量学习算法的结果
由表6和表7可知,对于图像数据,随着增量学习的引入,模型的预测精度提高得更快,且在增强节点相同的条件下,IIBLS增量学习算法比EIBLS增量学习算法有更高的预测准确率。但由于图像处理比较费时,模型的训练时间稍长于文本输入数据下的训练时间。
为了证明增量学习式BLS预测模型对图像数据的有效性,将EIBLS和IIBLS两种预测模型与基本BLS、CFBLS、LCFBLS以及两种深度神经网络图像检测模型SSD、YOLOv3在预测性能上进行对比,结果如表8所示。各对比模型参数设置如下:IIBLS的初始结构设置为4×4感知域、100个增强节点和10×10特征节点、特征映射和池大小为3;将BLS、CFBLS、LCFBLS的初始结构设置为1 000个增强节点和100×10特征节点。
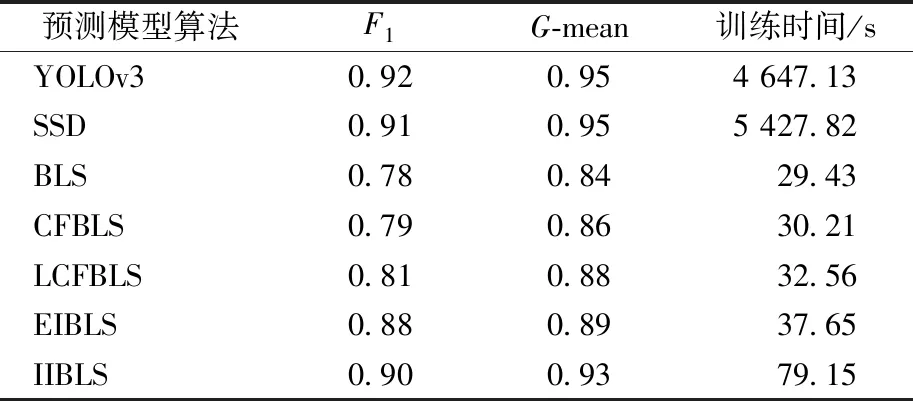
表8 本文模型与对比模型在第2组数据上的预测效果对比
由表8可知,本文提出的BLS,对于图像数据,在预测的精确率和训练时间上,整体都优于基本宽度学习模型和两种改进宽度学习模型。与两种常见的一阶段目标检测深度学习网络模型相比,IIBLS和EIBLS方法只有很小的差距,但训练时间大大少于两种典型深度学习模型。由此可以看出,本文的宽度学习模型在粮情风险预测上,无论是针对文本数据还是图像数据,完全可以作为深度模型的替代。
5 结论
基于近年来出现的宽度学习基本理论,通过引入增量学习方法和相关性分析方法,建立了一个基于改进宽度学习网络的仓储粮情风险点预测模型。该模型针对深度学习模型构建时存在的训练时间长、资源需求大等问题,在保证预测精度不降低的前提下,大大降低了模型的训练难度和资源消耗,使得精准的仓储粮情风险预测模型在资源配置较低的储粮企业也可以得到实现,可为企业减少大量的信息化投资,降低储粮的成本。目前,本文的宽度学习模型在预测精度上作为一种深度学习的替代方法,仍需要进一步提高预测精度。下一步的工作将集中在如何提高不同模态粮情数据的融合效果,以及如何在宽度学习中引入注意力机制,以进一步提高宽度学习模型的预测精度和应用范围。
猜你喜欢
当代陕西(2022年6期)2022-04-19
中学生数理化·中考版(2019年9期)2019-11-25
牡丹江师范学院学报(自然科学版)(2019年4期)2019-09-10
中国粮食经济(2018年4期)2018-12-27
粮食与饲料工业(2017年3期)2017-03-08
农业与技术(2016年5期)2016-10-21
电信科学(2016年9期)2016-06-15
医学研究杂志(2015年5期)2015-06-10
人生十六七(2015年5期)2015-02-28
电子设计工程(2015年16期)2015-02-27
