
基于CEEMDAN-GRU 的主泵电机绕组温度预测
2023-08-05 07:22朱一虎夏虹杨波朱少民张汲宇王志超
应用科技 2023年4期
朱一虎,夏虹,杨波,朱少民,张汲宇,王志超
1. 哈尔滨工程大学 核安全与先进核能技术工业和信息化部重点实验室,黑龙江 哈尔滨 150001
2. 哈尔滨工程大学 核安全与仿真技术重点学科实验室,黑龙江 哈尔滨 150001
核主泵是反应堆一回路压力边界的重要组成部分之一,是反应堆及一回路系统中最关键的旋转设备,其主要功能是将一回路中的冷却剂进行升压,克服冷却剂在设备和管道中的流动阻力,促使其将堆芯中产生的热量传递到蒸汽发生器,保证堆芯的正常冷却,因此保证主泵电机长期、安全、稳定、可靠地运行至关重要。而在夏季时,由于环境温度升高,主泵电机定子绕组运行温度会接近其跳泵限值[1],对机组构成了潜在威胁,需要对其定子绕组温度进行预测,以便工作人员判断其运行趋势并且采取相应的安全保护措施。
对于设备运行参数,传统的预测方法主要有3 类:回归分析法,此方法的计算原理和结构形式都比较简单,预测速度快,但对复杂多变的数据预测精度较低;整合移动平均自回归(autoregressive integrated moving average, ARIMA)模型,利用差分对原始序列进行平稳化,根据序列特性求得相关参数来进行预测,此模型较为简单,只需要原始序列产生的变量而不需要其他外生变量,但其要求原始序列或原始序列差分后的序列是稳定的,并且无法捕捉非线性关系;机器学习模型,此类方法主要以当前时间点的数据特征进行建模预测,未考虑数据的时序性,在对基于时间序列的数据进行预测时误差较大[2]。
近年来,众多的国内外学者开始将深度学习用于时间序列的预测中。王鑫等[3]利用长短期记忆(long short-term memory, LSTM)神经网络对复杂系统的历史故障数据进行时间序列预测,王祥雪等[4]通过对LSTM 网络逐层构建和精细化调参来预测短时交通流,并且可以根据预测精度进行参数的自适应更新。牛哲文等[5]在传统门控循环单元(gated recurrent unit, GRU)神经网络的基础上融合了卷积神经网络(convolutional neural networks,CNN)来预测风电场的短期风功率,并引入随机失活(dropout)技术减少模型的过拟合现象。针对时间序列数据固有的不平稳导致预测精度较低的问题,很多研究人员引入模态分解方法,去除一部分噪声,再对不同尺度下的分量分别预测[6−12]。相较于上述应用场景,时间序列预测方法在核电站中的应用较少,武云云等[13]将ARIMA模型应用于环境放射性水平的预测,结果表明预测值与实际值基本一致。张思原等[2]提出了基于LSTM 的多特征融合多步状态预测模型,对蒸汽发生器的蒸汽压力进行预测,验证了该方法的有效性。朱少民等[14]结合ARIMA 和LSTM 的优势,利用组合模型对核电厂主泵的运行状态进行预测,结果表明该方法具有更加稳健的预测性能。
本文采用自适应噪声完备集合经验模态分解(complete ensemble empirical mode decomposition with adaptive noise,CEEMDAN)与门控循环单元结合的模型来对时间序列进行预测。相比于集合经 验 模 态 分 解 (ensemble empirical mode decomposition, EEMD),该方法在分解过程中添加的是白噪声经过经验模态分解(empirical mode decomposition, EMD)得到的各阶本征模态函数(intrinsic mode functions, IMF),最后重构信号中的噪声残余更小,降低了筛选次数,同时也避免了各模态分量结果差异造成的集合平均难以对齐的问题。利用GRU 神经网络对分解重构得到的各分量分别建立相应的预测模型,对各预测结果进行叠加从而得到最终的预测结果。
1 CEEMDAN 的基本原理
EMD 是一种基于信号局部特征自适应的信号分解方法,它根据信号的局部特征尺度,按频率由高到低将复杂的非线性、非平稳信号分解为有限个本征模态函数之和。然而大量的实践证明,EMD 分解方法存在的模态混叠现象限制了其应用。随后Wu 等[15]提出了对此问题的改进措施——EEMD,即给原始信号添加均匀分布的白噪声,使得不同尺度的信号会自动映射到合适的参考尺度上。虽然EEMD 抑制了模态混叠,但是对原序列添加的白噪声仍有可能残存于分解后的模态分量中,影响了后续信号的进一步分析。在此基础上,Torres 等[16]提出在分解时添加自适应白噪声,有效降低了EEMD 重构时的误差。其具体步骤为:
1)对原始序列f(t)添加白噪声序列,得到含有噪声的信号序列fi(t),对此序列进行N次EMD 分解后取算术平均值得到第1 个模态分量FIMF1(t):式中: ε0为噪声系数,ωi(t)为第i次分解加入的服从标准正态分布的白噪声序列。
2)计算第一残余分量:
3)定义Ej(·)为对序列进行EMD 分解后的第j个模态分量,则对r1(t)+ε1E1(ωi(t))分解得到:
4)重复步骤2)、3)得到其余的模态分量和残余分量,直到所得到的残余分量极值点个数小于等于2,则停止分解,此时得到固有模态分量FIMFK
和最终残余分量R(t)。最终残余分量可表示为
CEEMDAN 分解通过添加自适应白噪声对序列进行了干扰脉冲的平滑处理,进一步降低了重构时的误差,提高了完整度。
2 GRU 的基本原理
循环神经网络(recurrent neural network,RNN)是深度学习领域中一类特殊的内部存在自连接的神经网络,它通过隐藏层上的回路连接使得前一时刻的网络状态能够传递给当前时刻,当前时刻的状态也可以传递给下个时刻。LSTM 神经网络是在RNN 中梯度错误累积过多而导致梯度消失或梯度爆炸的基础上所提出的,其将门控的机制引入到循环单元中,可以有选择性地添加和删除数据信息,起到了控制信息数据流通的作用。GRU 是一种LSTM 的变体,它将LSTM 的输入门和遗忘门耦合为更新门,用于控制隐藏状态的更新,减少了矩阵乘法的运算,有效加速了网络的收敛。GRU 的结构如图1 所示。
GRU 的前向传播计算过程可表示为
式中:xt为神经元的输入,ht−1为前一时刻隐藏层的状态,Wr、Wz和Wh分别为重置门rt、更新门zt和隐藏层的权重矩阵。重置门由该时刻的输入和上一时刻的隐藏状态控制,其决定了是否将隐藏状态的信息遗忘,从而发掘数据间的短期联系;更新门则控制上一时刻的信息在当前时刻的保留量。
3 CEEMDAN-GRU 预测模型
利用CEEMDAN 将原始序列分解为若干个频率不同的固定模态分量和1 个残余分量,同时为了降低预测建模的复杂度和避免模型过拟合,对各分量进行重新组合得到高频分量、低频分量和趋势项,运用GRU 网络分别对重组后的分量进行预测,最后将预测结果叠加集成得到最终的预测结果。图2 给出了此方法的预测流程,具体步骤如下:
1)利用CEEMDAN 将绕组温度序列分解为K个模态分量FIMFi(t)(i=1,2,···,K)和1 个残余分量R(t);
2)分别对FIMFi(t)做显著性水平α=0.05下均值为0 的单样本t检验;
3)若FIMFm(t)为第1 个Pvalue<0.05的模态分量,则将FIMF1(t)+FIMF2(t)+···+FIMFm−1(t)的结果作为高频分量,将FIMFm(t)+FIMFm+1(t)+···+FIMFK(t)的结果作为低频分量,最后将残余分量作为趋势项;
4)针对重组得到的3 个分量,分别构建相应的GRU 预测模型,得到各分量的预测值;
5)通过叠加处理得到最终绕组温度的预测结果。
4 实验验证及分析
4.1 数据来源
主泵电机是核电站的关键设备,通常采用的是易于安装、使用和维护的异步电动机,而同步电机与异步电机的不同之处在于转子的结构,其定子绕组都是相同的。本文采用来自德国Universität Paderborn 永磁同步电机(permanent magnet synchronous motor, PMSM)的实验数据[17]进行预测方法的验证,数据集共有12 个特征,包括温度传感器测量的环境温度、冷却液温度、永磁表面温度、定子轭温度、定子齿温度、定子绕组温度以及电压d轴分量、电压q轴分量、电机转速、电流引起的扭矩、电流d轴分量和电流q轴分量。仿真实验的目标特征为定子绕组温度。数据集共包含52 个测量阶段,基本涵盖了电机温度变化的全过程,每个测量阶段通过相对应的标签加以区分,所有测量序列均以2 Hz 的采样频率在测试台上完成。为降低计算成本,本文选取某个测量阶段中时间间隔为150 min 的数据作为原始序列,标准化后的绕组温度如图3 所示。在图3 所示的时间区间内,绕组温度先后大致经历了振荡、上升、下降以及再振荡的阶段,构成了相对完整的温度变化周期,使得本文建立的预测模型对绕组温度变化的特征提取更加充分,增强了研究结论的说服力。

图3 原始绕组温度序列
4.2 CEEMDAN 分解与重组
对图3 所示的序列进行CEEMDAN 分解,得到11 个固有模态分量和1 个残余分量,分解结果如图4 所示。

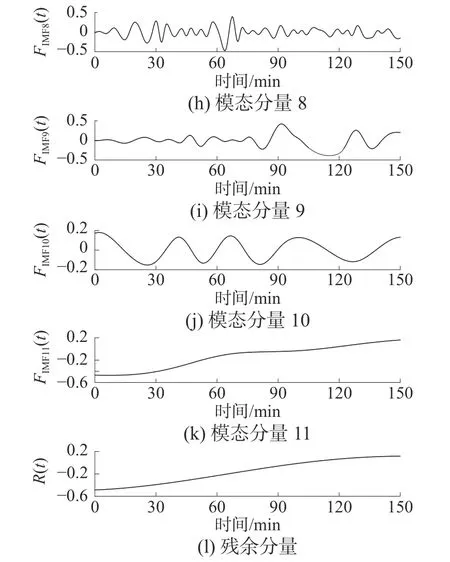
图4 CEEMDAN 分解结果
按顺序依次对各分量进行显著性水平α=0.05下均值为0 的单样本t检验,各模态分量的t检验结果如表1 所示。
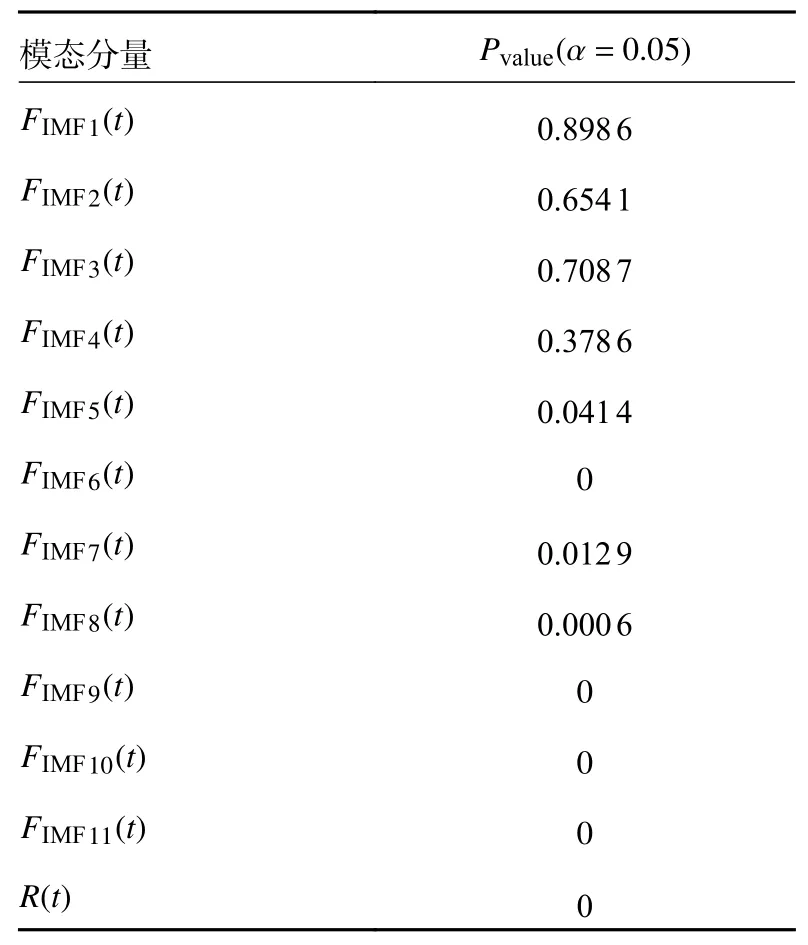
表1 各分量的t 检验结果
由表1 可知,FIMF1(t)∼FIMF4(t)的Pvalue均大于0.05,而FIMF5(t)∼FIMF11(t)的Pvalue均小于0.05,即在当前显著性水平下第1 个均值显著偏离0 的模态分量为FIMF5(t)。因此可将FIMF1(t)∼FIMF4(t)叠加得到高频分量Fhigh(t),表示序列的短期波动项;将FIMF5(t)∼FIMF11(t)叠加得到低频分量Flow(t),表示序列的中期重要因素影响项;残余分量R(t)不变,作为序列的长期趋势项。重组后的结果如图5所示。

图5 分量重组结果
4.3 GRU 神经网络的建模
对于重组后的分量,采用滚动时间窗的方式对子序列进行预测,选择前80%的数据作为训练集,后20%的数据作为测试集。采用双层GRU神经网络,输入序列长度为30,即选取前30 个样本对序列进行预测,输出序列长度为1,同时设置失活率为0.2 的Dropout 层以抑制网络的过拟合。具体的GRU 神经网络超参数如表2 所示。为了消除数据间量纲的差异,加速网络的收敛,在将数据输入网络之前采用MinMaxScaler 估计器对数据进行归一化,使数据处于[0,1],其计算公式为
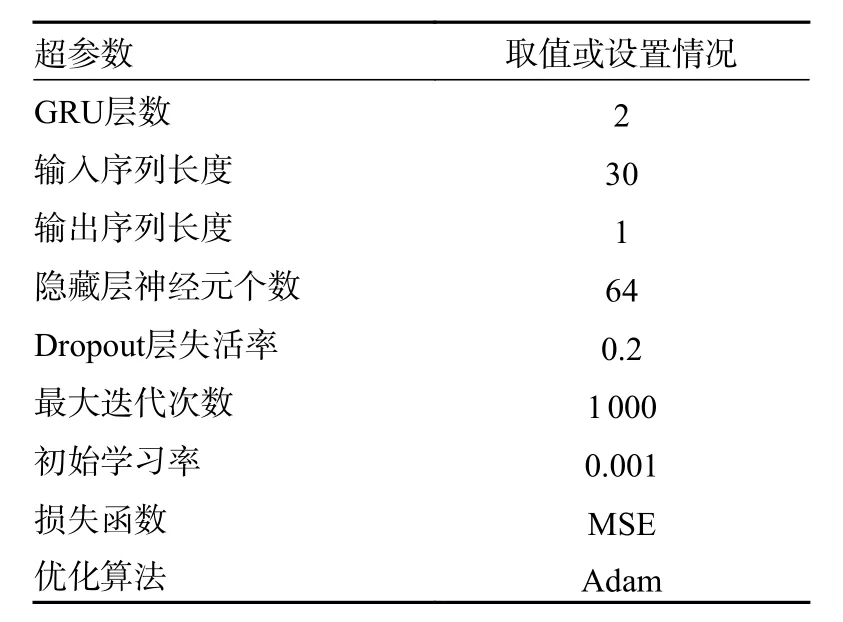
表2 GRU 神经网络的超参数
4.4 预测评价指标的选择
预测评价指标有很多种,为了对选用的方法进行全面的分析和评价,本文选用平均绝对误差(mean absolute error, MAE)EMA、均方根误差(root mean square error, RMSE)ERMS、对称平均绝对百分比误差(symmetric mean absolute percentage error,SMAPE)ESMAP以及校正决定系数(adjustedR-square)来评估预测模型的优劣,相应的计算公式为
4.5 预测结果与对比分析
经过网络的训练和测试,高、低频分量和趋势项预测结果如图6~图8 所示,对应的预测评价指标如表3 所示。

表3 重组分量的评价指标

图6 高频分量预测结果

图7 低频分量预测结果

图8 趋势项预测结果
从预测曲线图6~图 8 中可以看出,经过分解、重组得到的3 个分量在测试集上的预测结果均与原分量序列基本重合,即预测模型对数据具有较强的解释能力。
将这3 个分量的预测结果进行集成重构得到绕组温度在测试集上的预测结果,同时与传统RNN、LSTM 和GRU 模型进行对照实验,如图9 所示。

图9 不同模型的预测结果
为了便于在具体的部分区域上比较不同模型之间的差异,对测试集中第128~130 min 的变化趋势进行局部放大,如图10 所示。从图10 中可以看出,传统神经网络模型虽然在整体趋势上与实际趋势保持一致,但在某些极值区域的预测输出与实际值有不小的差距;而本文提出的预测模型不仅成功预测出了绕组温度的变化趋势,而且在局部极值处与真实值的误差最小,在波动频繁的区域也能捕捉到原始序列的细节特征,具有更强的预测能力。

图10 不同模型局部区间的预测结果
同时表4 也给出了各预测模型的评价指标结果。数据表明,相比于其他模型,本文所提出的CEEMDAN-GRU 预测模型的MAE、RMSE、SMAPE值均最小,而Adjusted-R2值最大,即认为在所给出的评价指标上优于其他模型。同时,将本文的模型与使用GRU 直接预测相比较,当分解重构的方法融入预测模型后,预测效果均取得了较大改善,验证了CEEMDAN 分解可以更好地提取数据的内在特征,提高预测精度。
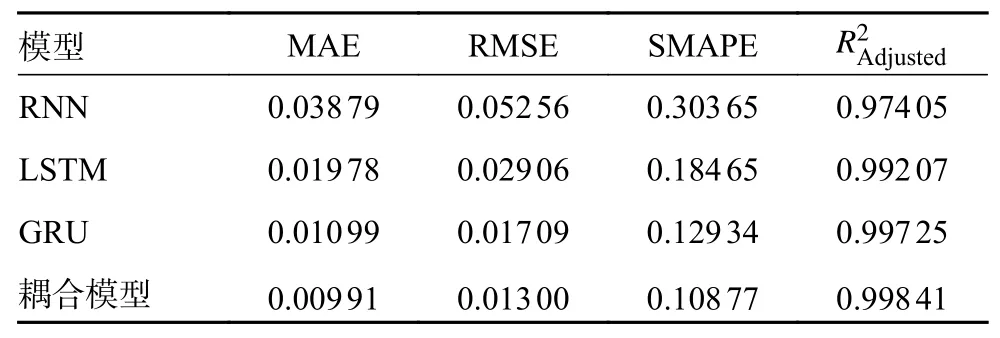
表4 不同模型的评价指标对比
5 结论
为了提高核电站中主泵电机的预警能力,适当优化其维护策略,本文提出了一种基于CEEMDAN-GRU 的主泵电机绕组温度预测算法,主要包括:
1) CEEMDAN 分解善于提取复杂时间序列的波动模式,GRU 神经网络在提取数据间的长期依赖关系方面具有优势,将二者有效结合,建立了新的时间序列预测耦合模型;
2) 通过计算分解后各模态分量的Pvalue进行分量的重组,以此作为网络的输入,降低了预测模型的复杂度,避免了模型的过拟合;
3) 相较于其他对比模型,CEEMDAN-GRU 的耦合模型在多元评价指标中均有明显的优势,具有更好的预测性能。
在后续工作中,将对GRU 的参数优化方法等展开进一步的研究。
猜你喜欢
基层中医药(2021年12期)2021-06-05
英美文学研究论丛(2018年1期)2018-08-16
纺织科学研究(2017年6期)2017-07-03
电子制作(2017年1期)2017-05-17
照明工程学报(2016年3期)2016-06-01
电测与仪表(2016年2期)2016-04-12
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
云南电力技术(2015年2期)2015-08-23
上海电机学院学报(2015年4期)2015-02-28
电测与仪表(2014年23期)2014-04-04
