
刍议基于人工智能的图像处理技术
2023-08-09 06:39周媛媛
计算机应用文摘·触控 2023年15期
摘 要:文章对基于人工智能的图像处理技术中多任务卷积神经网络的实现原理、应用场景进行了介绍,旨在为从业者提供一定的参考,以及为行业外感兴趣之人提供一定的科普知识。
关键词:人工智能:图像处理:多任务卷积神经网络
中图法分类号:TP391文献标识码:A
基于人工智能的图像处理主要进行“数字图像处理”,即通过编制计算机程序控制算法,在原始数字图像中定向执行某些功能作业。在图像处理的过程中,可以从数字图像中完成基本信息的提取。在现代生活中,大众已经习以为常的“相机美颜” 功能、电影《流浪地球2》中令刘德华、吴京等人饰演的角色“年轻化”的方法均应用了人工智能图像技术。总体而言,对此技术的实现原理及应用展开分析具有重要意义。
1 基于人工智能的图像视觉处理技术原理
当前应用较为广泛的图像处理技术以多任务卷积神经网络(Multi?Task Convolutional Neural Network,MTCNN)为代表[1] 。此项技术的核心原理是,能够将“人脸区域检测” 以及“人脸关键点检测” 融合于一体,形成类似cascade 的主题框架[2] 。MTCNN 网络一般分成P,R,O 三层?NET 网络结构。在上述三个级联网络形成图像检测跟踪模型之后,进一步添加“候选框+分类器”处理机制,能够自动捕捉人脸图像并进行检测。上述三个级联网络各自具有的功能是:P?NET 具有“快速生成候选窗口”功能;R?NET 具有“基于高精度候选窗口过滤选择”的功能;O?NET 具有“生成最终边界框与人脸关键点”的功能[3] 。
2 基于人工智能的图像视觉处理技术的应用历程
MTCNN 网络模型在人脸识别领域的应用范围最广,处理人脸图像信息的过程如下。
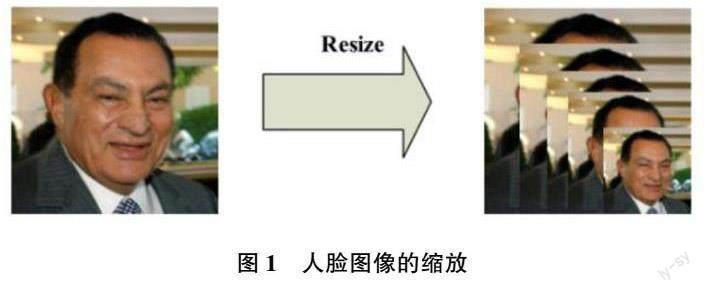
(1)图像金字塔的构建。首先,在处理一张人脸图像之前,需要对图片进行缩放,但缩放的程度并不固定[4] 。如图1 所示,右侧的效果便是“图像金字塔”。这一过程在计算机图像处理软件中的实现方法为设定缩放系数factor。经过对不同人脸图像的反复试验,研究人员得出一个结论,将factor 取值设定为0.709,取得的缩放效果最佳。于是“factor= 0.709”被编入控制程序中。图1 右侧的“金字塔”型人脸图像的“金字塔具体分层” 取决于人脸图像的原始大小———“factor= 0.709”实际上是缩小比例,将原始图像的长度、宽度均乘以这一系数,一直到长度、宽度低于某个特定值(不同处理软件有不同的标准,同样可以自行设定) 便停止。经过几轮的“缩放”,图像的“金字塔层级”便是多少。基于上述原理对某人脸图片进行处理,核心处理程序如下。
def calculateScales(img):
copy_img = img.copy()
pr_scale = 1.0
h,w,_ = copy_img.shape
if min(w,h)>500:
pr_scale = 500.0/ min(h,w)
w = int(w?pr_scale)
h = int(h?pr_scale)
elif max(w,h)<500:
pr_scale = 500.0/ max(h,w)
w = int(w?pr_scale)
h = int(h?pr_scale)
scales = []
factor = 0.709
factor_count = 0
minl = min(h,w)
while minl >= 12:
scales. append(pr_scale?pow(factor,
factor_count))
minl ?= factor
factor_count += 1
return scales
按照上述程序对图片进行比例缩放,其中存在2个数据,分别是“500”和“12”。前者指利用处理软件处理图片前,可通过人工方式对图片的长度、宽度进行调整,使其高于500,否则软件处理的图片过小,信息提取容易失真[5] 。后者指经过多轮次自动缩放,当图片的长度、宽度达到12 时,缩放即可停止。
(2)基于P?NET(Proposal Network)的网络层。经过步骤(1)的缩放处理,在“人脸金字塔”图像中形成一个“全卷积网络”。这一过程的主要作用是通过全卷积网络,对图片中的重要区域———人脸所在位置进行“边框标定”,之后初步提取人脸特征,完成上述作业,还可进行窗口调整及大部分窗口过滤作业。需要注意,在该阶段,P?NET 存在2 个“输出”,应用层的核心控制程序是:
classifier = Conv2D ( 2, ( 1, 1), activation = 'softmax', name='conv4?1')(x)
设置classifier 指令的作用是,对网格点上框的可信度进行判断。在该条控制程序之下,还需编制:
bbox_ regress = Conv2D (4, (1, 1), name = 'conv4?2')(x)
对这一条程序的深度理解是:虽然bbox_regress能够表示相框的位置,但这一位置是经过缩放后的图像中的人脸所在位置,并非原始真实位置。
(3)将bbox_regress 映射到真實图像上,然后完成一次解码作业。在编制控制程序时,上述“映射+解码”过程的实现需要调用函数库中的detct_face_12net函数[6] 。具体的程序是:
def detect _ face _12net ( cls _ prob, roi, out _ side,
scale,width,height,threshold):
# 0,1 表示维度的翻转
cls_prob = np.swapaxes(cls_prob, 0, 1)
roi = np.swapaxes(roi, 0, 2)
stride = 0
# stride 略等于2,图片压缩比例(经过p?net导致的),(x,y)是有人脸概率大于threshold 的点
if out_side ! = 1:
stride = float(2?out_side?1) / (out_side?1)
(x,y) = np.where(cls_prob>=threshold)
boundingbox = np.array([x,y]).T上述程序对应的解析内容是:针对经过缩放及P?NET 处理后的图片,找到其对应原图的位置,反向复盘“P?NET 比例+图像黄金比例”,最后完成映射。完成函数调用及编制程序控制语句后,需要解决的问题如下。
①bbox_regress 映射到真实图像后,图片中会出现多个网格点。这些网格点的置信程度有高有低,需要从中筛选出具有高置信度的网格点[7] 。具体的筛选原理是:围绕“置信程度” 设定一个“ 临界值”,超出该临界值,意味着该网格点内存在“人脸信息”;低于该临界值,表明该网格点内不存在人脸信息。为便于理解,笔者举一个更简单、更容易验证的例子。对很多图像处理初学者而言,Photoshop 一般是所接触的第一个图片处理软件。在Photoshop软件中打开一张图片后,很多人都尝试过“前推鼠标滑轮,放大图片”的操作。之后看到的景象是,图片仿佛被切割成多个“小方格”。这些小方格的本质是“像素”———如果一张背景是白色的人脸图像,那么在一定深度色彩的像素区间内便“有图像内容信息”;依然保持白色的像素区间便“没有图像内容信息”。这里还需注意一个问题,即当前阶段的AI 人工智能(可理解为具有多种处理功能的软件工具)依然停留在“类人化”的阶段,而非“完全具备人类大脑的思维能力”。之所以提出该问题,是因为软件控制程序的“思考判定逻辑”具有极强的“直观性”,并不懂得“转弯”。比如,在人工处理一张人脸图片时,如果背景是白色,图像中人的脖颈处出现了部分白色衬衫,那么其会将该“白色衬衫”所在的像素区域认定为“人脸的一部分”,在手动抠图时会将该区域与人脸区域作为一个整体提取。图像处理软件则不具备上述功能,在相关控制程序启动后,所有“白色像素区域”都会被认定为“该区域不存在人脸信息”,故会将该区域筛除[8] 。基于此,所设定的“置信程度临界值”不能引起歧义,否则会导致人脸识别效果大幅度降低。
②对网格点所在的位置进行记录,即记录框架内的x,y 轴信息。
③继续利用函数,完成图像中框的左上角基点、右下角基点之间的“像素差”。完成堆叠处理后,可以得到boundingbox。在此基础上, 可以利用bbox _regress 完成对解码结果的计算,对应的程序为:boundingbox = boundingbox + offset12.0scale
(4)R?NET 层(Refine Network)处理。这一层同样需要构造一个“卷积神经网络”[9] 。与P?NET 层相比,该层多出一个“圈层连接”功能。这样设置的目的是,以更加严格的标准,对图像相关信息及输入数据进行筛选。具体来说,当图片进入P?NET 层时,很多用于“预测”的窗口会被留下。通过编制控制算法,将这些预测窗口送入R?NET 层,接受深度筛选。由于卷积神经网络的存在,大量效果较差的候选框会在该环节被筛除,最后剩下的候选框均具有较为清晰的效果,之后会被送入Bounding?Box Regression,以完成深度优化预测。总体而言,R?NET 层在使用最后一个卷积层后,还会对规模达到128 的全连接层进行充分利用,以实现“保留更多图像特征”的目标。基于此,R?NET 处理层的性能、对图像信息处理的精确度均优于P?NET 层。
(5)O?NET 层(Output Network)处理。该层的基本结构是一个复杂程度更高的卷积神经网络,比R?NET 层多一个卷积层[10] 。从某种程度上来看,相较于R?NET 层,O?NET 层的主要功能更接近“辅助回归”功能———可对图像中的人脸面部区域进行更具侧重性的识别,之后对图像中能够体现出人脸面部特征的点位进行“回归处理”。完成相关作业之后,在图片中,筛选出一定数量的人脸面部信息对应的多个面部特征点(可进行设置,按照特征代表性由高到低分布),之后完成输出。完成上述处理后,还需对NMS结果进行验证处理,最终生成人脸识别信息。一张图片中存在多个人,依次完成人脸信息的缩放、筛选、提取,可自动完成识别检测,效率极高。
3 结束语
人工智能的本质是“程序控制”,是指人类编制出具有“定向控制、定向作业”功能的程序算法,在“跑程序”的过程中,将其对特定对象信息进行识别、捕捉、分析、处理,最终给出人们希望看到的结果。相关“处理”流程最初由人工完成,但随着计算机计算能力的提升,人类大脑的计算速度已经远远低于计算机,人工处理过程还容易受到诸多因素的干扰,最终处理效果远远无法达到人们的要求。在这种情况下,人工智能技术应运而生,极大地提高了运算处理效率。总之,相信在不久的未来,更多令人惊叹的人工智能图像处理技术会在各行各业得到应用,从而使人类世界更加“多姿多彩”。
参考文献:
[1] 李峰泉.人工智能的皮革自适应视觉图像处理切割技术研究[J].中国皮革,2022,51(9):44?48.
[2] 曾光华,肖洋.人工智能算法在图像处理中的应用见解[J].电子元器件与信息技术,2022,6(7):97?100.
[3] 宋朝晖.人工智能算法在图像处理中的应用探讨[C] / /2022 年第五届智慧教育与人工智能发展国际学术会议论文集,2022:278?279.
[4] 何映彤.人工智能技术下图像处理教学的应用研究[J].科学咨询(教育科研),2022(6):124?126.
[5] 刘云川,韩梦瑶,王浩全,等.人工智能算法在图像处理中的应用分析[J].电子世界,2021(16):67?68.
[6] 刘磊,袁林德,王紫宁,等.基于人工智能算法的敦煌舞图像处理技术[J].软件,2021,42(8):39?41.
[7] 邓晨曦,蒋一锄.人工智能算法在图像处理中的应用探讨[J].中国新通信,2020,22(18):98?99.
[8] 张超.人工智能图像处理的边缘计算硬件优化[D].哈尔滨:哈尔滨工业大学,2020.
[9] 梁斌.试论人工智能算法在图像处理中的应用[J].数码世界,2018(9):220.
[10] 張薇.人工智能算法在图像处理中的应用[J].通讯世界,2018(4):63?64.
作者简介:
周媛媛(1988—),硕士,实验师,研究方向:教育信息化、图像识别技术、数据可视化。
猜你喜欢
西安航空学院学报(2022年2期)2022-07-04
商界(2019年12期)2019-01-03
制造技术与机床(2018年12期)2018-12-23
电子制作(2018年18期)2018-11-14
IT经理世界(2018年20期)2018-10-24
电子测试(2018年6期)2018-05-09
电子测试(2017年11期)2017-12-15
小康(2017年16期)2017-06-07
南风窗(2016年19期)2016-09-21
南风窗(2016年19期)2016-09-21
