
随机森林算法对流域面积监测的适用性研究
2023-08-21 09:44刘晓宇
现代信息科技 2023年12期

摘 要:基于R语言进行统计分析、回归建模,结合变量重要性排序、相关性分析等多种方法,分析了武汉市市内流域(长江、汉江)面积变化的影响因素,建立了流域面积监测随机森林回归模型。与多元线性回归模型、支持向量回归模型的对比结果表明,随机森林回归模型拟合优度更高,平均绝对误差更低,这说明随机森林算法在流域面积监测研究中具有较高的适用性。
关键词:随机森林;流域监测;多元线性回归;支持向量机
中图分类号:TP181 文献标识码:A 文章编号:2096-4706(2023)12-0074-04
Research on the Applicability of Random Forest Algorithm to Watershed Area Monitoring
LIU Xiaoyu1,2
(1.Three Gorges Smart Water Technology Co., Ltd., Shanghai 200335, China;
2.Shanghai Investigation, Design & Research Institute Co., Ltd., Shanghai 200335, China)
Abstract: Statistical analysis and regression modeling is carried out based on R language, combined with variable importance ranking, correlation analysis and other methods, this paper analyzes the influencing factors of the area change of the urban watershed (Yangtze River, Hanjiang River) in Wuhan, and establishes a random forest regression model for watershed area monitoring. The comparison results with multiple linear regression model and support vector regression model show that the random forest regression model has higher Goodness of fit and lower average absolute error, which indicates that random forest algorithm has higher applicability in watershed area monitoring research.
Keywords: Random Forest; watershed monitoring; multiple linear regression; Support Vector Machine
0 引 言
近年來,随着3S技术的快速发展,3S动态监测流域变化为流域土地利用监测工作提供了新的思路,国内一些学者也进行了相关的研究工作。郑义、王发良等通过对不同分辨率的遥感影像依次抽样,分别计算各样本的河流面积调整系数,探索不同月份河流覆盖面积之间的关系,从而提出将不同时相影像中提取出的河流面积修正成统一时点的方法[1]。李石华、周峻松等以抚仙湖流域为例,通过遥感影像提取流域土地利用信息,结合社会经济数据,采用多元回归和主成分分析等方法探索流域土地利用时空变化的驱动机制[2]。胡义涛、朱颖等以天目湖流域遥感、土地利用及DEM数据为基础,对天目湖流域林地的动态变化进行了定量分析[3]。
随机森林算法是一种近些年逐渐被诸多学者关注的机器学习算法,因其准确率较高,对误差值有一定的包容性,在高光谱遥感训练学习方面表现优异,所以常被研究人员应用到地学相关领域的研究中。崔东文以万元GDP用水量及万元工业增加值用水量为自变量,建立了基于随机内插构造样本的随机森林回归年污水排放量预测模型[4]。梁慧玲、林玉蕊等以大兴安岭塔河地区森林火灾发生数据为基础,采用二项逻辑斯蒂回归模型和随机森林算法分析了塔河地区森林火灾与气象因子之间的关系,证明了随机森林算法在林火预测中具有更高的预测精度[5]。这说明,随机森林算法对变量共线性不敏感和预测精度高等优势让它逐渐成为机器学习算法中的一种热门算法。
总体而言,有关流域面积变化驱动因素的研究比较少,随机森林算法在同类研究中的适用性值得探讨。因此,本研究对于流域大尺度监测及机器学习算法在流域影响因素分析研究中的可行性判定具有一定的价值。
1 研究方法
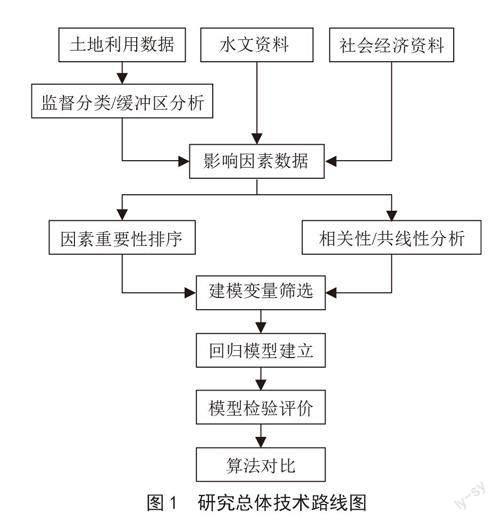
本研究以随机森林算法为核心,以武汉市15年各项水文及经济数据为基础,通过相关性分析、随机森林特征重要性检测等方法探究武汉市内长江、汉江流域面积年际变化的影响因素,结合对各项因素的定量分析,建立具有普适性的随机森林回归流域面积预测模型,并通过与多元线性回归模型和支持向量回归模型的误差比较,探究随机森林算法在流域预测工作中的可行性,具体的技术路线如图1所示。首先,通过监督分类、缓冲区分析等方法获取影响因素数据;其次,对影响因素数据进行正态性检验、相关分析、重要性排序和多重共线性检查,从而确定回归模型的输入变量;最后,使用随机森林算法建立预测模型,并与其他算法模型做以对比和验证,比较各算法的优劣。
2 研究过程
2.1 数据收集
2.1.1 流域面积数据
选取武汉市2002—2016年Landsat系列遥感影像(非汛期数据),通过矢量化方法从中提取长江、汉江流域范围,计算两江为期15年的流域面积数据。
2.1.2 影响因素数据
影响流域变化的因素大致可以分为自然因素和人为因素两类:自然因素是指地理、气候等导致流域面积变化的因素;人为因素是指人类各项活动间接导致流域面积变化的因素,包括社会经济、土地利用和水资源利用等。
本研究从《武汉水资源公报》以及《武汉市统计年鉴》中获取武汉市15年来年降水量数据,作为气候影响因素参考;采用监督分类和缓冲区分析两种方法提取流域土地利用數据,作为土地利用因素参考;选取绿地、居民用地、水域以及其他用地四类样本,对影像数据进行监督分类,以长江、汉江流域为中心建立7级缓冲区,统计每一级缓冲区范围内各类用地的面积总和;从社会经济、人口增长、社会生产等多方面考虑,选取产值、人口、年末耕地面积等多种统计年鉴指标作文影响经济的基础数据;选取年地表水资源量、总水资源量、总用水量、人均用水量、万元GDP用水量五个指标来反映武汉市水资源总量和利用保护情况。
2.2 流域面积预测模型构建
2.2.1 流域面积影响因素分析
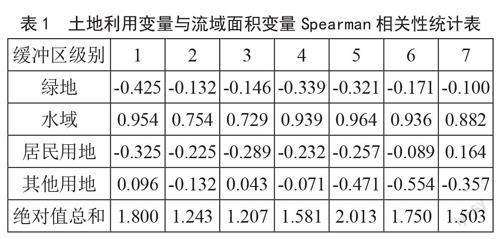
首先,探讨土地利用因素对流域面积的影响,计算各缓冲区级别土地利用面积变量和流域面积之间的相关性,如表1所示,从表1中可知水域面积与流域面积的相关性较强,其中5级缓冲区水域面积与流域面积的相关性最大。从各类用地相关性的绝对值总和来看,同样也是5级缓冲区(20 km)的绝对值总和最大,其次是1级、6级、7级缓冲区。
其次,分别使用随机森林算法、多元线性回归算法和支持向量机算法对数据进行拟合,通过自变量对因变量的解释度或模型的拟合优度来筛选适宜的缓冲区数据级别,如表2所示。对于随机森林回归模型,5级缓冲区(25 km)范围土地利用变量对因变量的解释程度最高(72.11%);对于另外两种模型,7级缓冲区(全区)土地利用变量的拟合优度均为最高,分别为91.82%和92.01%。因此,使用5级缓冲区数据作为随机森林回归的建模数据,使用7级缓冲区土地利用数据作为多元线性回归和支持向量回归的建模数据。
再次,探讨16个与社会经济和水资源利用相关的因素对流域面积的影响,采用Pearson相关系数分别计算各变量(土地利用变量除外)与流域面积的相关性,结果如表3所示。选取Pearson相关系数排名前七的变量作为回归模型待选自变量(不含未通过正态性检验的变量)。而总用水量、水产品产量、粮食产量和人均用水量四个变量与流域面积的相关性较小,在回归模型构建中可以不予考虑。
此外,随机森林算法有其独特的度量变量重要性的方法,参数“误差增加比例/ %”越大说明变量重要性越大,为0说明没有影响,为负说明可能对因变量有误导;参数“节点纯度增长值”越大说明变量重要性越大,为0说明对因变量没有影响。对所有变量进行多次拟合并计算出两种参数的平均值,部分数值如表4所示。除排名前四位的变量以外,年降水量和人均生产总值的排名也比较靠前,其他变量排序差异较大,可能是由重要性计算结果相近导致的,说明它们对模型的贡献度相当但是不高,在后续建模中可不予考虑。
综合以上分析,初步得出水域面积、其他用地面积、总水资源量、年地表水资源量、年降水量和人均生产总值为影响流域面积变化的主要因素,在随机森林回归分析时作为输入变量参与建模。
2.2.2 随机森林回归流域预测模型建立
随机森林回归模型的建立主要包括变量确定、参数确定、模型建立和模型检验评价几个部分。
随机森林是由多棵决策树组合而成的,通过每棵树生成的结果投票表决得到最后结果。首先确定构建决策树时向下分支随机抽样的变量数目,通常选为建模输入变量数目的1/3[6]。上文共选择6个变量,则该参数为2。用前文选择的输入变量建立随机森林回归模型,得到模型误差和决策树数目的关系,发现当决策树数目大于600之后,模型的误差开始趋于稳定,因此将决策树数目参数确定为600。
再次检测变量重要性,发现变量重要性排序基本保持在稳定状态,此时得到的随机森林回归模型对因变量的解释度约为62.94%,模型的拟合优度为91.32%。为了进一步优化模型,去掉贡献度最小的变量即人均生产总值重新建模,发现余下5个变量对因变量的解释度为70.41%,模型拟合优度为94.38%。考虑到随机森林算法对于变量和数据量的基本要求,不再对模型做进一步的变量删除。
2.3 对比验证
2.3.1 多元线性回归流域面积预测模型构建
在多元线性回归模型中,具有共线性的变量会影响模型的预测结果,需要对用于建模的自变量进行共线性诊断。计算变量方差膨胀因子(VIF值)发现,年地表水资源量和总水资源量均存在严重的多重共线性。因此后期在进行回归分析前必须先降低变量之间的共线性。
使用逐步回归的方法对自变量进行筛选,经过多轮的逐步回归及共线性检查,发现在仅保留其他用地面积和水域面积两个变量时,模型和自变量的显著性最佳,且不再存在多重共线性,如表5所示,模型在0.05的置信水平上具有显著性,变量在0.05的置信水平上都通过了显著性检验,且拟合优度达到了91.53%。
2.3.2 支持向量回归流域面积预测模型构建
在进行支持向量回归分析之前,须采用多次建模计算拟合优度的方法来选择回归模型类别和核函数组合,发现当参数组合为“nu-regression”和“linear”时,拟合优度最高。
综上,水域面积、总水资源量、年地表水资源量、年降水量和其他用地面积是排名最靠前的5个自变量。建模时,逐渐去掉相关性最小的自变量,计算不同变量数目下模型的拟合优度,结果如表6所示,从表7中可知使用水域面积、年地表水资源量和总水资源量建立回归模型[7]时,模型的误差和拟合优度达到最优,约为90.49%。
2.3.3 模型对比分析
本研究使用全部数据来训练和验证模型,使模型最大限度地获取数据变化信息,从而使模型拥有更高的精度和适应性。为比较三种算法的优劣,将三种模型的样本拟合值与样本观测值(影像流域面积数值)进行比较,如图2、图3所示。
在折线图中,散点为样本观测值,拟合线上的点为模型预测值,三个模型的拟合度相当,拟合效果不好的点在数目和距离上相差不大。
在散点图中,横坐标为样本观测值,纵坐标为模型预测值,添加45度倾斜参考线比较,发现支持向量回归模型偏离参考线的点在距离和数目上最大,其他两种模型相差不大,说明支持向量回归模型的拟合效果最差,其他两种模型的拟合效果相近。
使用四个指标参数MAE(平均绝对误差)、RMSE(均方根误差)、RSE(相对平方误差)和R2(拟合优度)来评价回归模型的预测能力。MAE、RSE、RMSE三个参数的值越小说明模型的预测误差越小,R2越大说明模型拟合效果越好,计算结果如表7所示。
比较四个参数的大小可知,随机森林回归模型相比于多元线性回归模型和支持向量回归模型误差更小,预测精度和拟合优度更高。
综合来看,三种回归模型在流域面积预测问题上表现出来的适用性都不错,但随机森林回归模型略占优势,更适用于流域面积预测及相关研究。
3 结 论
本文对影响武汉市主要流域(长江、汉江)覆盖面积的各项因素进行了分析讨论,选取了年地表水资源量、总水资源量、年降水量、水域面积等5个变量,作为随机森林回归模型的输入变量,建立了最优随机森林回归流域面积预测模型。主要结论为:
1)土地利用类型变化一定程度上影响了流域面积变化,其中水域面积和其他用地(耕地、未利用地等)面积变化对流域面积的影响最大;此外,与水资源密切相关的因素(年降水量、年地表水资源量、总水资源量等)对流域面积的影响较大。
2)使用随机森林算法擬合输入变量时,可以得到准确度较高的流域面积预测模型,说明随机森林算法在流域面积预测研究中具有可行性。
3)通过与多元线性回归模型和支持向量回归模型的比较分析,发现随机森林回归模型表现突出,误差率最小,拟合度最高,说明随机森林算法相比于线性回归算法和SVM算法更适用于流域面积预测。
上述结论充分说明随机森林算法在一定程度上适用于地学问题,但仍存在局限性,值得我们做进一步的研究和探讨。其一,机器学习算法普遍需要大量数据来学习建模才能体现其最优拟合效果,但本研究中数据量有限,即使已使用一些手段来降低误差,但模型稳定度仍待提升;其二,流域面积变化与河流汛期密切相关,但遥感影像的采集时段并不统一,导致模型可信度有限。
参考文献:
[1] 郑义,王发良,李广泳,等.面向地理国情监测的河流面积调整系数研究 [J].遥感信息,2014,29(4):26-30+36.
[2] 李石华,周峻松,王金亮.1974—2014年抚仙湖流域土地利用/覆盖时空变化与驱动力分析 [J].国土资源遥感,2017,29(4):132-139.
[3] 胡义涛,朱颖,赵越,等.基于DEM高程的天目湖流域林地动态变化研究 [J].苏州科技大学学报:工程技术版,2017,30(4):57-61.
[4] 崔东文.随机森林回归模型及其在污水排放量预测中的应用 [J].供水技术,2014,8(1):31-36.
[5] 梁慧玲,林玉蕊,杨光,等.基于气象因子的随机森林算法在塔河地区林火预测中的应用 [J].林业科学,2016,52(1):89-98.
[6] 李欣海.随机森林模型在分类与回归分析中的应用 [J].应用昆虫学报,2013,50(4):1190-1197.
[7] 赵北庚.基于R语言randomForest包的随机森林建模研究 [J].计算机光盘软件与应用,2015,18(2):152-153.
作者简介:刘晓宇(1996.05—),女,汉族,湖北天门人,助理工程师,工学硕士,研究方向:智慧水务GIS应用。
猜你喜欢
安徽农学通报(2017年1期)2017-02-15
软件(2016年7期)2017-02-07
南水北调与水利科技(2016年6期)2017-01-06
合作经济与科技(2017年1期)2017-01-03
中国科技纵横(2016年15期)2016-12-29
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
时代金融(2016年29期)2016-12-05
中国远程教育(2016年9期)2016-11-19
价值工程(2016年29期)2016-11-14
