
基于SW-GBDT的在线农产品销量预测模型
2023-08-24 08:02李鹏飞冉茂然毋建宏
西安邮电大学学报 2023年2期
李鹏飞,冉茂然,毋建宏
(1.西安邮电大学 经济与管理学院,陕西 西安 710061;2.西安邮电大学 现代邮政学院,陕西 西安 710061)
随着电子商务(电商)的快速发展,农产品通过线上销售的比例越来越高。根据中国农业农村部和中央网络安全和信息化委员会发布的《数字农业农村发展规划(2019—2025年)》,农产品网络零售额占农产品总交易额比重将由2018年的9.8%提升至2025年的15%。可以预见,未来在线农产品销售将会取得较大的发展。
随着在线农产品销售的迅速发展,也会带来一些问题,例如,由于相当一部分农产品具有生鲜和易腐烂等特点,若销售不及时,存在库存积压现象,则可能会由于农产品腐烂而导致经济损失。准确地进行销量预测可以帮助农户实现及时销售,有效降低经济损失。
时间序列分析、支持向量机(Support Vector Machine,SVM)、神经网络以及深度学习等方法均为销量预测的常见方法[1]。时间序列分析通过对有限长度的时间序列进行观察、研究,寻找其变化发展规律,对未来做出预测[2]。例如,文献[3]提出一种改进的考虑品牌情感的自回归模型,结合用户情感值对汽车销量进行预测。SVM方法是一种以统计学习理论为基础的机器学习分类器,常被用于解决分类或回归问题[4]。文献[5]将支持向量机应用到卷烟销量的预测中,提出基于SVM的卷烟销量预测模型。近年来,随着人工神经网络的快速发展,其在预测领域得到广泛应用。例如,文献[6]提出融合口碑评论与搜索数据的消费者关注度量化方法,构建基于消费者关注度的模型,实现了汽车销量预测。深度学习是一种利用模拟人脑多层感知结构来认识数据模式的算法[7]。文献[8]针对线上农产品销量存在信息不对称的问题,提出一种结合深度学习算法优势和涉农电商销售数据特征点的皇冠模型。
时间序列分析、SVM、神经网络以及深度学习等方法均被应用于不同领域的销售预测,并取得了一定的预测效果,但是,这些方法应用于在线农产品的销量预测时,仍存在一些问题,主要包括:第一,由于农产品自身特点,其数据样本存在多样化的情况;第二,影响在线农产品的因素较多,预测模型无法全部涉及;第三,在线农产品的有效销售数据为农产品按自然生长周期成熟后销售的数据,此数据集往往规模较小,而深度学习在处理小规模数据集时预测效果较差。因此,如何在小规模数据中获取尽可能多的特征,提高在线农产品销量预测精度成为亟待解决的问题。
梯度提升决策树(Gradient Boosting Decision Tree,GBDT)算法具有灵活处理各种类型的数据、对异常值的鲁棒性强及训练时间短的特点[9],被广泛应用于预测领域的研究中。例如,文献[10]使用GBDT方法构建了航班延误预测模型,其结果表明,相比于SVM算法、随机森林(Random Forest,RF)算法和传统决策树算法,具有更高的准确度。文献[11]提出基于集成树-梯度提升决策树的PM2.5预测模型,针对PM2.5浓度的非线性与不确定性进行预测,效果较好。但是,仅仅使用GBDT算法预测在线农产品销量时,会产生特征选择不够全面的问题。
为了更加全面地选择特征,通常需要对数据进行特征扩展。滑动窗口(Sliding Window,SW)方法作为特征扩展的常用方法之一,广泛地应用于预测研究中[12-13]。例如,文献[14]提出采用基于滑动窗口的影像对象获取方法,将多尺度分割后的预测结果与滑动窗口分割后的预测结果进行对比验证,结果表明,滑动窗口提取结果的总体分类精度比多尺度分割高出0.94%。
整理归纳已有的预测文献,发现针对销量预测领域的应用研究较少,特别是对在线农产品的销量预测的研究还有待进一步深入。考虑到在线农产品销量存在外部影响因素较多以及销量数据集较小的问题,为了提升在线农产品销量预测的准确性,拟提出一种基于SW-GBDT的在线农产品销量预测模型。使用滑动窗口方法进行特征扩展,并对新增的特征进行多重共线性检验,使用主成分分析将高度相关的特征用主成分表示,降低特征之间的共线性对模型的影响,将数据集中的标称数据利用独热(one-hot)编码转变为数值数据,最后,利用梯度提升决策树对在线农产品进行销量预测。
1 研究方法
1.1 梯度提升决策树原理
GBDT算法[15]是一种以分类回归树(Classification and Regression Tree,CART)为基模型的集成学习算法[16]。GBDT集成算法的训练过程示意图如图1所示,样本通过多轮迭代,每轮产生一个弱学习器,最终将所有弱学习器加权求和后得到集成模型。

图1 GBDT集成算法训练过程示意图
假设在GBDT算法中输入的数据集为T={(x1,y1),(x2,y2),…,(xN,yN)},其中,xi∈X,yi∈Y(i=1,2,…,N),N为样本总数。GBDT算法的目标是找到一个估计函数F(x),对于任意xi,存在有F(xi),使得|F(xi)-yi|→0。一般采用损失函数的负梯度拟合损失。GBDT算法通常采用如下具体步骤。
步骤1初始化弱学习器。令样本中损失函数最小化的近似常数值为
(1)
式中:x=x1,x2,…,xN为输入样本;yi表示样本i的真实值;常量c为y1,y2,…,yN的平均值;L(yi,c)表示损失函数,用于计算真实值与预测值之间的误差。
步骤2建立M棵分类回归树m=1,2,…,M。
步骤3计算样本i的损失函数的负梯度在第m-1棵回归树的值,将其作为残差估计值rm,i,计算表达式为
(2)
式中:f(xi)表示将输入样本xi带入第m-1轮得到的学习器中得到的预测值;L(yi,f(xi))表示样本i在第m-1棵回归树的损失函数值;Fm-1表示第m-1轮得到的学习器。
步骤4将步骤3得到的残差值作为样本新的真实值,并将(xi,rm,i)作为第m棵回归树的训练数据,得到第m棵回归树,其对应的叶子节点区域为Rm,j,其中,j=1,2,…,Jm,且Jm为第m棵回归树叶子节点的个数。
步骤5计算出第m棵回归树的叶子节点区域j=1,2,…,Jm的最佳拟合值。该最佳拟合值采用损失函数的最小值表示。令Fm-1(xi)表示使用第m-1轮的学习器对输入样本xi的预测值,L(yi,Fm-1(xi)+c)表示第m棵回归树中第i个叶子节点的损失函数,则第m棵回归树的叶子节点损失函数的最小值的计算表示式为
(3)
步骤6更新学习器Fm(x),其更新方式为
(4)
式中,I表示第m棵回归树中的每个叶子节点区域的权重。若样本落在了Rm,j节点上,则令权重I=1;否则,令权重I=0。
步骤7对得到的全部学习器进行累加,得到最终回归树FM(x)的表达式为
(5)
1.2 滑动窗口法
滑动窗口法根据指定的窗口大小框住时间序列,从而计算框内的统计指标[17],实现扩展机器学习中样本特征并消除数据噪音[18]。对于时间序列s1,s2,…,sn,以周为滑动窗口的大小,在原始时间序列上按时间逆序进行滑动窗口操作,输入特征为s1,s2,…,s7,输出特征为v1,vt-9,vt-8,vt-7,…,滑动窗口方法原理示意图如图2所示。
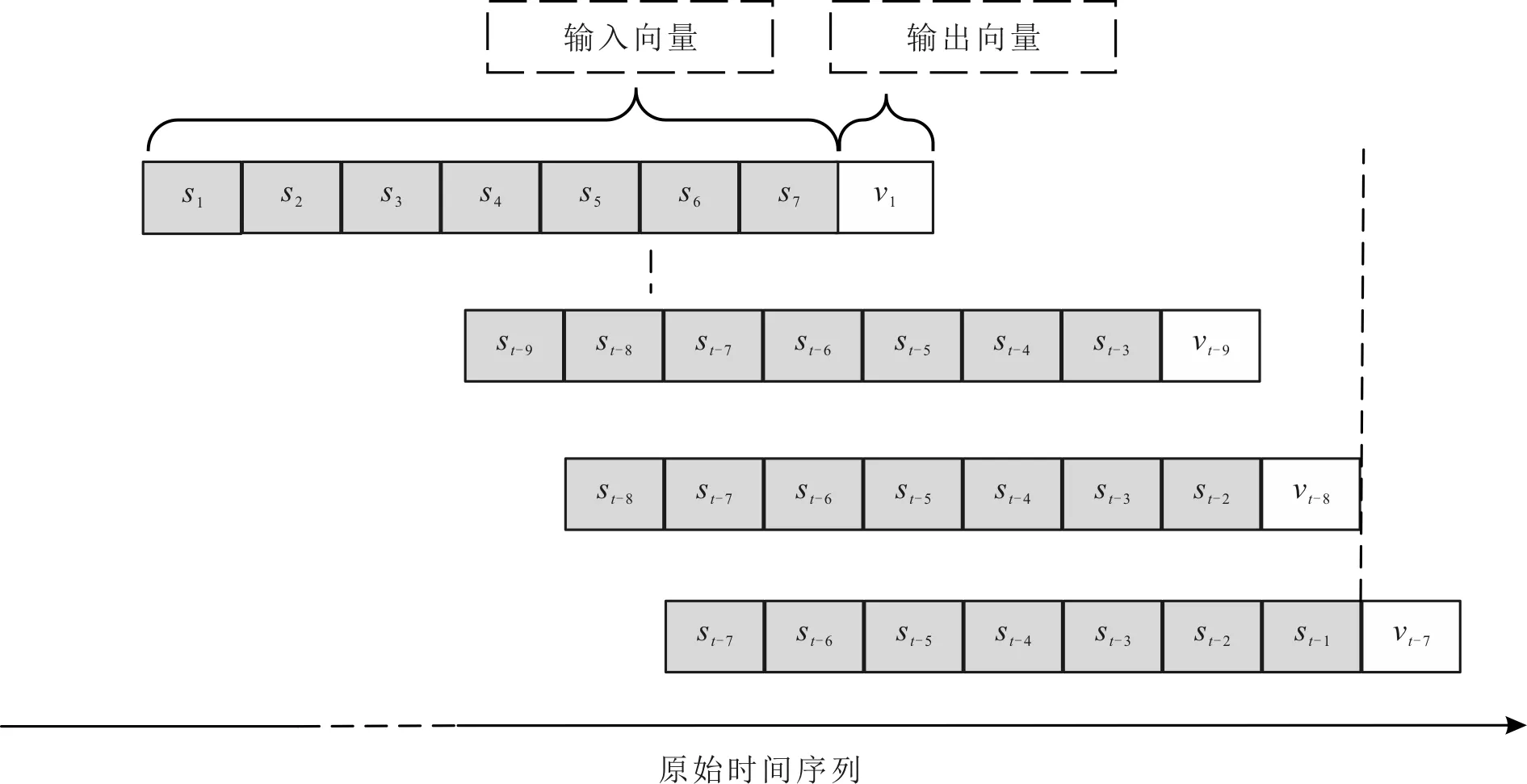
图2 滑动窗口方法原理示意图
2 SW-GBDT预测模型
SW-GBDT预测模型结构示意图如图3所示。从图中可以看出,SW-GBDT预测模型的基本思路为,利用爬虫程序获得数据,去除重复数据,使用one-hot编码处理数据集中的标称数据,得到初始数据集,使用滑动窗口法将在线农产品销量7天内的销量统计数据作为新的特征,对原数据集进行特征扩展,检验特征变量的共线性,对共线性高的特征变量进行主成分分析,并使用主成分对其替代,得到最终的输入特征,输入到GBDT模型中,利用超参数优化算法对模型参数进行优化,选出最佳参数构建预测模型,进而得出模型的预测结果。
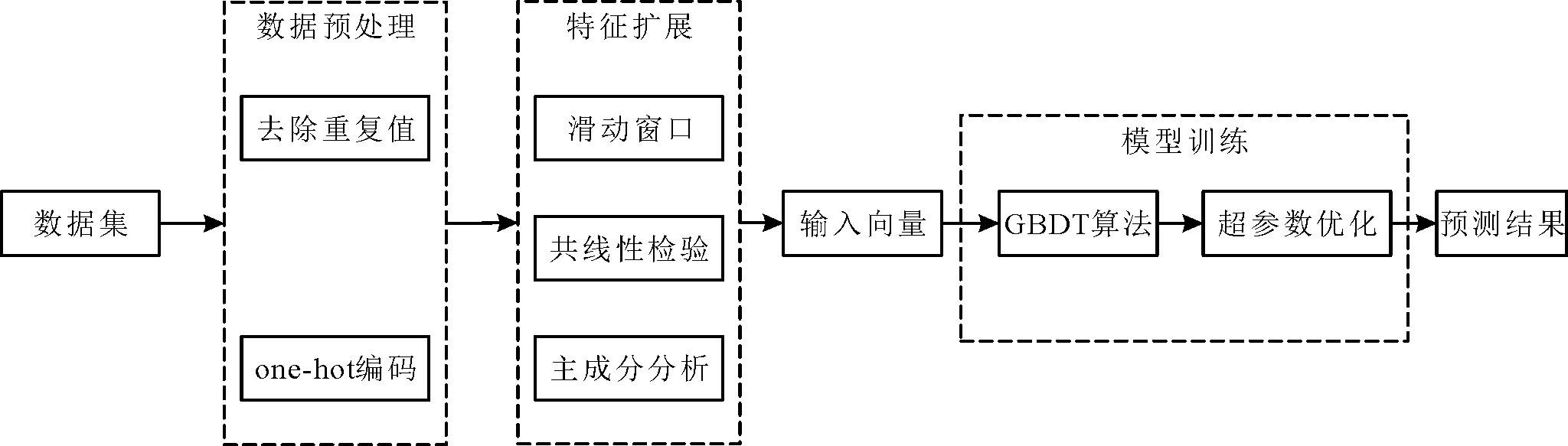
图3 SW-GBDT预测模型结构示意图
2.1 指标筛选
影响在线农产品销量的因素包括多个方面,例如,文献[19]认为,店铺评论、店铺服务以及产品特征对产品销量均会产生不同程度的影响。文献[20]研究发现,农产品的质量、安全、新鲜度及店铺信誉、送货效率和服务质量对网购生鲜农产品意愿具有显著正向影响,农产品价格对网购意愿具有显著负向影响。综合已有相关研究成果,同时考虑到数据的可获取性,选择从店铺特征、产品特征和口碑特征等3个方面来确定在线农产品销量的影响因素。
1)店铺特征。文献[21]运用探索性因子分析法和验证性因子分析法对农产品网络购买意愿影响因素研究模型进行优化和验证,发现良好的店铺信誉及店铺服务有利于提升消费者对店铺的好感,从而提升消费者的购买意愿。根据相关研究成果,形成描述店铺服务的变量列表如表1所示。

表1 描述店铺服务的变量列表
2)产品特征。通常而言,消费者对于产品特征的关注包含产品价格、产品包装、产品质量、产品安全性及新鲜程度等相关因素[20]。根据相关研究成果,最终确定描述产品特征的变量列表如表2所示。

表2 描述产品特征的变量列表
3)口碑特征。口碑是消费者之间的一种非正式沟通方式,是消费者购买商品或服务后发表的态度。相较于传播范围受限的线下传统口碑,网络口碑是以网络为媒介进行传播,具有传播范围广、时效性长及内容丰富等特征,对消费者购买决策的影响更加显著[22]。同时,不同品牌的产品在消费者中的口碑存在较大差异[23]。选取品牌名称和每日的评论数描述口碑特征,描述口碑特征的变量列表如表3所示。
4)时间特征。由于存在其他可能的外部因素对在线农产品销量产生影响,采用滑动窗口法进行特征扩展,以周为窗口单位,将该窗口前1天、2天、3天和7天产品销量的统计性数据作为时间特征加入到数据集中。最终形成描述在线农产品销售时间特征的变量列表如表4所示。
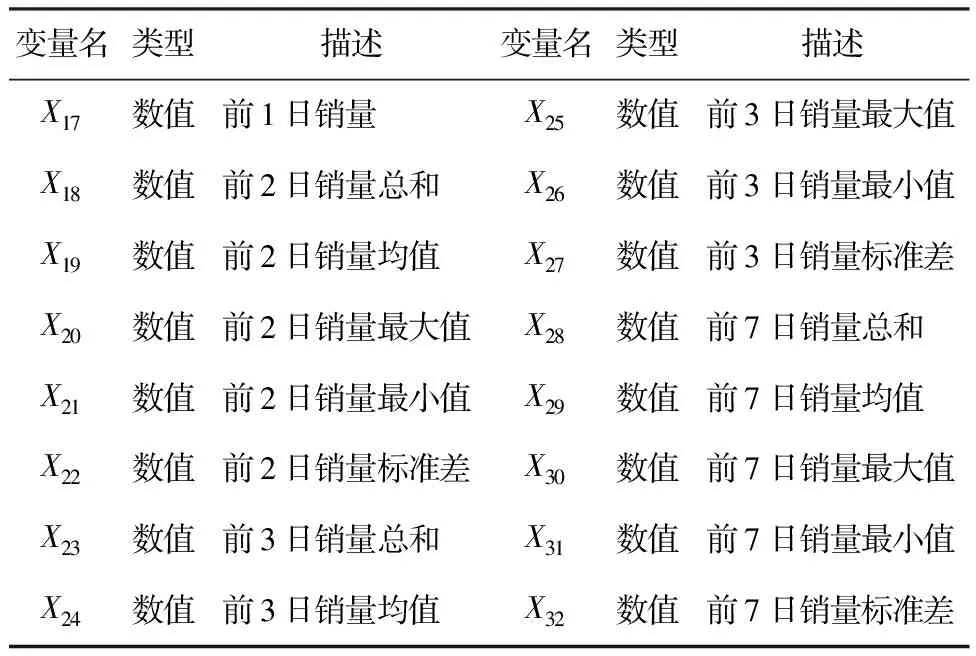
表4 描述时间特征的变量列表
基于以上对在线农产品销量预测影响因素的分析和选择,共提取出32项特征变量作为预测模型的输入变量。
2.2 模型参数
梯度提升决策树的结果由多棵决策树的输出累加得到,而每棵决策树的最大深度(max_depth)影响模型的泛化能力,最终影响模型的预测效果。模型中的学习率(learning_rate)代表每个弱分类器的权重,最大迭代次数(n_estimators)代表弱分类器的最大个数,即最多训练多少棵决策树。模型学习率和最大迭代次数两个值决定模型的拟合效果及模型的复杂程度[10]。
所提的SW-GBDT预测模型利用网格搜索法确定最优参数。网格搜索法[24]是指定参数值的一种穷举搜索方法,通过交叉验证的方法优化模型参数得到最优的学习算法。对各个参数的可能取值进行组合,列出所有可能的组合结果生成“网格”,使用交叉验证对参数表现进行评估,在遍历所有参数组合后,返回最佳参数模型。
由于Huber函数同时具备均方误差(Mean-Square Error,MSE)和平均绝对误差(Mean Absolute Error,MAE)这两种损失函数的优点,对异常值的鲁棒性更强,且梯度会随着损失值接近其最小值逐渐较少,从而使得模型结果更加准确[9],因此,选择Huber函数作为梯度提升决策树算法中的损失函数。
3 实证分析
为了验证所提SW-GBDT算法的有效性,对某电商网站的猕猴桃销量数据进行预测,并与经典GBDT算法[9]、SVR算法[6]及BP神经网络算法[25]进行对比。
实验过程中的软件环境为操作系统采用Windows 10 x64,开发平台为Python 3.9,Microsoft Office Excel 2019,调用的第三方库有Python的 oneHotEncoder,numpy,matplotlib, pandas,sklearn。硬件环境为处理器采用Intel(R) Core(TM) i5-6300H CPU@2.30 Hz ,主机内存为16 GB。
3.1 数据来源
考虑到不同农产品之间的产品差异性较大,成熟期不同以及数据的可获得性,以某电商平台不同生鲜店铺的猕猴桃销量为实验对象,仅选取产地为陕西与四川的生鲜店铺的猕猴桃销量进行数据抓取,使用Python语言编写网络爬虫程序。
将某电商平台产品搜索的关键字作为入口,搜索猕猴桃关键字,添加产地为陕西或四川的筛选条件,选取前7家店铺,依次爬取从2021年12月1日到2022年3月10日的猕猴桃订单数据,共取得700条有效数据,并得到7家店铺的销量走势图,如图4所示。从图4可以看出,由于不同店铺之间的店铺特征、产品特征存在较大的区别,导致销量的波动情况在不同店铺之间存在较大差异。此外,消费需求会随着地点、时间和偶发的特殊事件等各种因素的影响而改变。例如,有时一个热点就会导致商品销量的激增或暴跌,从而产生高度非平稳的销量时间序列。
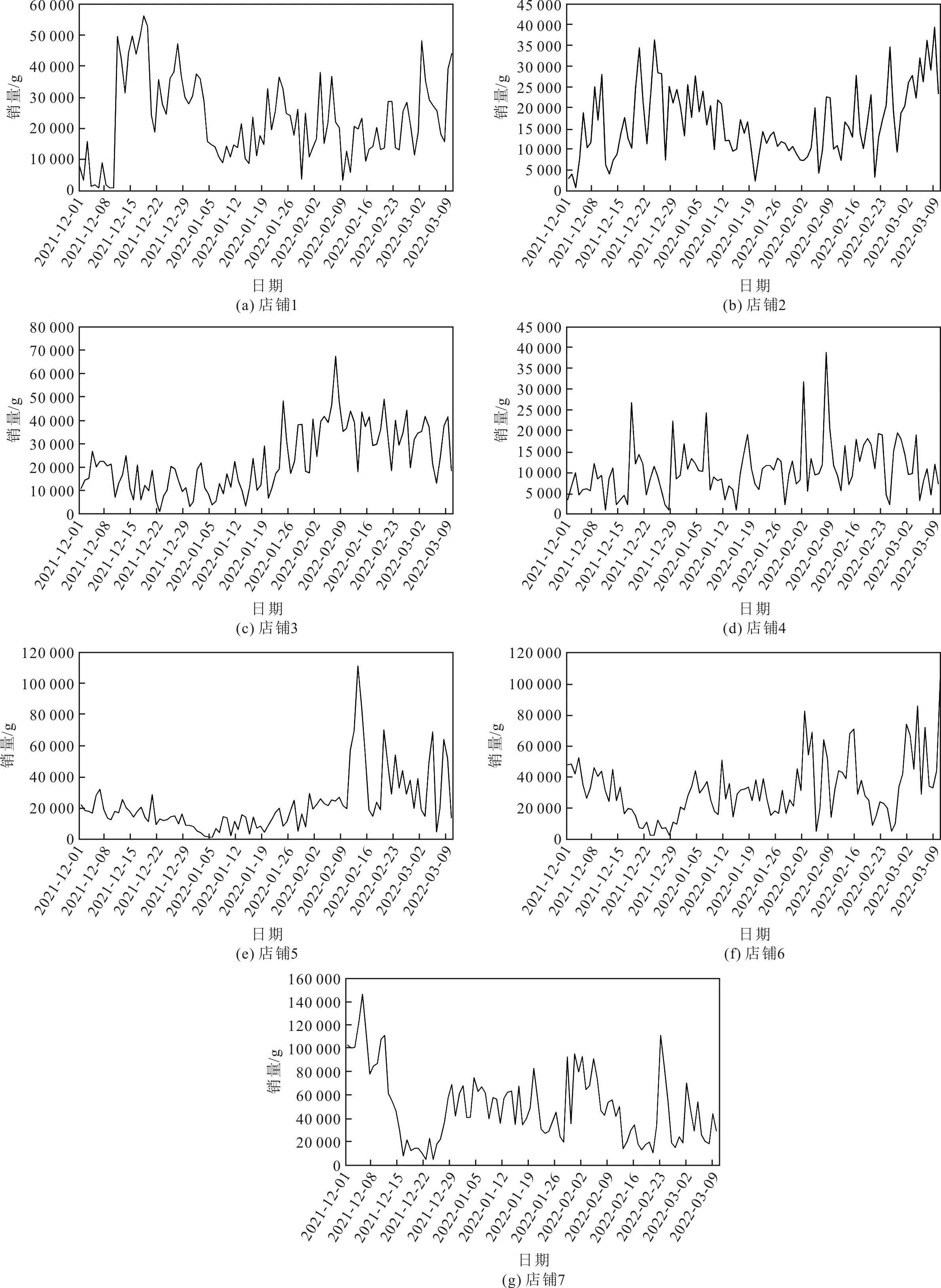
图4 7家店铺销量走势
3.2 数据预处理
3.2.1 重复值处理
由于实验数据在获取过程中会存在重复数据。为保证数据的完整性及准确性,利用订单数据中的唯一订单号对数据进行去重复操作。
3.2.2 离散值处理
模型的特征变量中存在标称数据类型,将标称数据直接引入预测模型会降低其预测效果。为此,采用独热(one-hot)编码对标称数据进行预处理。one-hot编码主要采用N位状态寄存器对N个状态值进行编码[26]。假设在线农产品的产品特征含有N个标称数据hi(i=1,…,N),则将该特征使用N个0或1的数据e1,e2,…,eN进行编码表示,对特征数据hi表示方法为,令ei=1,其余均为0。对数据集中的标称数据进行one-hot编码,得到品牌名称编码、厂址编码、包装方式编码、套餐份量编码及特产品类编码,分别如表5、表6、表7、表8和表9所示。

表5 品牌名称编码

表6 厂址编码

表7 包装方式编码

表8 套餐份量编码

表9 特产品类编码
在实际的在线农产品销售场景中,部分标称数据的类别可能过多,使用one-hot编码进行处理时会产生高维稀疏特征,最终导致GBDT模型训练效果过拟合。为此,在处理类别特征时,对于取值数量小于10的类别特征直接使用one-hot编码进行处理,当取值数量大于10时,使用catBoostEncoder编码器[27]进行处理,当存在几百、上千的类别取值时,可以将one-hot编码的结果输入神经网络embedding层中,完成从高维稀疏特征向量到低维稠密特征向量的转换[28]。
3.2.3 共线性处理
由于滑动窗口法基于时间序列进行推移进行特征扩展,会造成特征共线性问题,从而影响模型的预测效果[1]。因此,需要对模型的特征变量进行共线性检验。经过检验,检验结果中方差膨胀因子(Variance Inflation Factor,VIF)大于10的变量如表10所示,共有16个变量,表明这16个变量之间存在较强的共线性。

表10 VIF大于10的变量
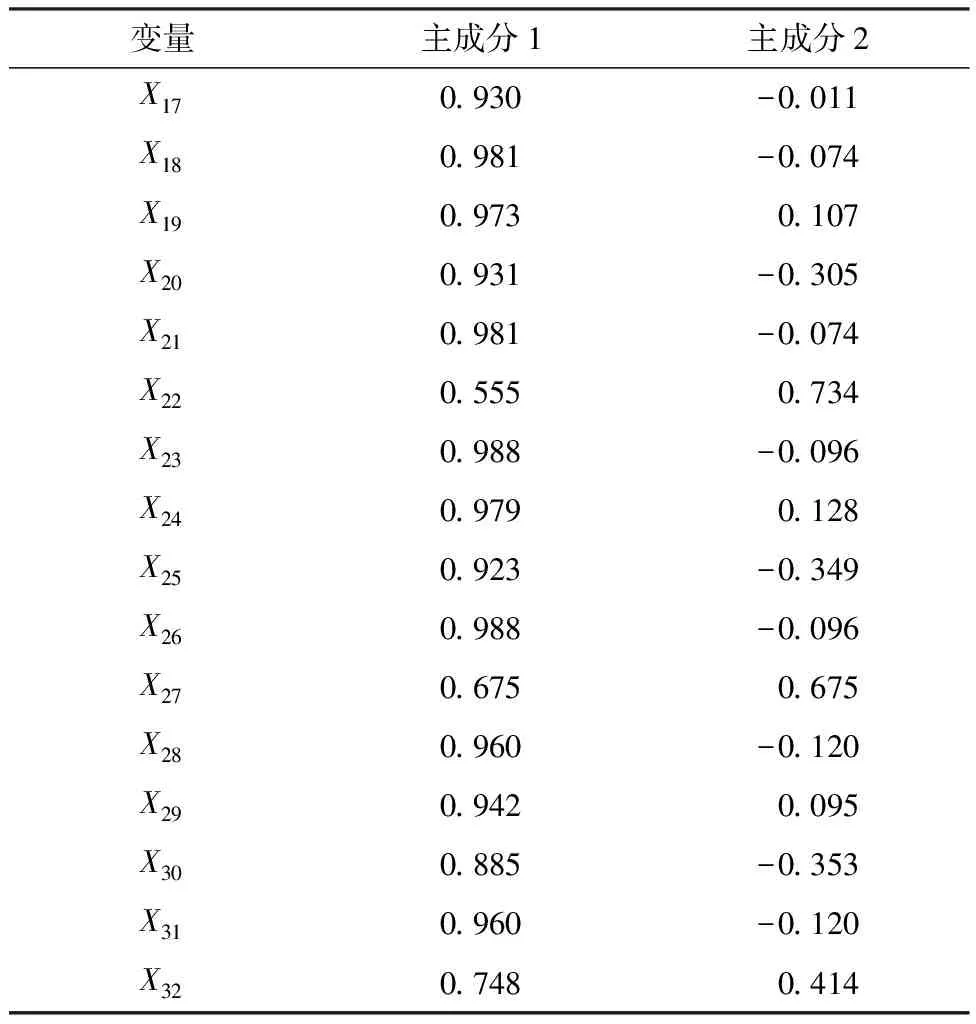
表11 共线性较强特征变量的主成分分析结果
为了降低特征的共线性风险,对表10中的16个特征变量进行主成分分析,得到共线性较强特征变量的主成分分析结果如表12所示。

表12 模型参数优化训练结果
根据主成份分析结果,可以将16个共线性较强的特征变量用两个主成分表示。两个主成分与相关特征变量之间的关系方程分别为
Z1=0.930X17+0.981X18+0.973X19+
0.931X20+0.981X21+0.555X22+0.988X23+
0.979X24+0.923X25+0.988X26+0.675X27+
0.960X28+0.942X29+0.885X30+
0.960X31+0.748X32
Z2=-0.011X17-0.074X18+0.107X19-
0.305X20-0.074X21+0.734X22-0.096X23+
0.128X24-0.349X25-0.096X26+0.675X27+
0.120X28+0.095X29-0.353X30-
0.120X31+0.414X32
将Z1和Z2两个主成分与特征变量X1至X16进行组合,构成一个18维的向量作为输入,输入到模型中进行预测。
3.3 评价指标
为准确评价模型有效性及可行性,模型预测效果的评价指标采用决定平方系数[29](R-squared,R2)、均方根误差(Root Mean Squared Error,RMSE)和平方绝对误差[30](Mean Absolute Error,MAE)等3个指标。R2的值越接近1,RMSE和MAE的值越小,模型预测的准确率越高。
3.4 预测结果
利用Python3的pandas数据处理包和Scikit-learn机器学习方法进行数据分析建模。调用train_test_split库对某平台猕猴桃销量按降序排名前七的店铺从2021年12月1日到2022年3月10日的猕猴桃订单数据进行随机划分,其中,20%作为测试集和80%作为训练集。采用GridSearchCV工具进行优化时,设定参数回归树数量(n_estimators)取值范围为[10,200],增幅设为10;设置树的最大深度(max_depth)的取值范围为[0,50],增幅为1;采用遗传算法(Genetic Algorithm,GA)优化时,设置种群数为30,n_estimators的取值范围为[10,200],max_depth的取值范围为[0,50],其余参数均采用默认值;采用差分进化(Differential Evolution,DE)算法优化时,设置种群数设为30,最大迭代次数为200,n_estimators的取值范围为[0,200],max_depth的取值范围为[0,50],其余参数均采用默认值;采用贝叶斯优化算法(Bayesian Algorithm,BO)优化时,设置初始节点为30,最大迭代次数为200,n_estimators的取值范围为[0,50],max_depth的取值范围为[0,50],算法中的其他参数均设为默认值。
经过各优化算法得出SW-GBDT最优参数,其中,模型参数优化训练结果如表12所示。从表中可以看出,将不同优化算法的模型预测效果进行对比,从整体来看,GS优化算法得到的最优参数的模型预测结果中R2值最大,表明模型的预测效果最好,但是,花费的时间也最长,这是因为,GS算法在参数寻优的过程中,会遍历所有的网格点进行模型训练,从而找出最优模型;BO优化算法的模型预测结果的R2值最低,表明预测结果与真实值之间误差较大,其搜索过程会利用过去的评估结果推断最优参数,从而能够在更短的时间内找到更优的参数;GA算法及DE优化算法的模型表现基本一致,各项模型评价参数基本相同。
4种不同优化算法的最佳预测结果如图5所示。可以看出,4种优化算法模型的预测效果和真实值之间的拟合情况。其中,GS优化算法中模型的预测值与真实值比较接近,从模型的预测效果而言,GS优化算法得到的模型参数是最优的,因此,选择GS优化算法对SW-GBDT模型进行超参数寻优。

图5 4种不同优化算法的最佳预测结果

(续)图5 4种不同优化算法的最佳预测结果
特征变量的权重大小表示变量在对模型预测结果的影响程度。特征变量的权重是其在所有决策树中权重的均值,而特征变量在单棵决策树的权重是其在每一节点裂变后的平方损失减少值。通过最佳预测模型得到特征变量的权重排序图,如图6所示。

图6 特征变量的权重排序
由图6可以看出,在所有特征变量中,每日评论数(X16)对销量的影响最大,作为历史信息反映消费者对店铺服务及农产品质量感知最直接的获取渠道,评论数越多表明消费者对于店铺的服务及产品质量能够获取的信息越多,消费者对店铺的信任度越高,从而激发消费者的购买欲望。由滑动窗口法生成的特征构成的主成分Z1、Z2对销量的影响较大,店铺在不同时间段的销量出现明显波动变化,这是因为:一方面,可能是其店铺进行促销活动,促进销量在短时间内上升;另一方面,可能是在农产品在成熟后刚进入市场,造成在该时间段内销量变化明显,说明店铺未来的销量受到近期销量特征的影响较大。
此外,包装方式(X9)、店铺服务评分(X2)及店铺描述评分(X3)对销量也有较大程度的影响,包装方式作为保证产品质量与新鲜度的主要手段,细致的保鲜包装可以提升消费者对产品的安全感,专业的售前咨询服务、完善的售后服务以及真实的产品描述信息可以提升消费者对卖家的信任度。
为更好地验证所提SW-GBDT模型的有效性,将其与经典GBDT算法、SVR算法及BP神经网络算法的预测结果进行对比,不同算法预测结果如表13所示。

表13 不同算法预测结果
由表13可以看出,与经典GBDT算法相比,经过特征扩展后的SW-GBDT预测模型的决定平方系数由0.706 8提升为0.902 3。另外,经典 GBDT算法在3种基础的机器学习算法中的预测准确率最低,而经过特征扩展后的GBDT算法相比于SVR算法的提升幅度为15.9%,与BP神经网络相比,预测准确度的提升幅度为7.9%。说明在数据量较小的情况下,传统机器学习算法能从数据中学习到的信息是有限的,而利用滑动窗口在原数据的基础上扩展特征,算法可以学习到更多的信息,从而有效地提升模型的预测精度。
4 结语
根据在线农产品的特点,在综合分析在线农产品销量影响因素的基础上,将梯度提升决策树应用于对在线农产品销量的预测,引入滑动窗口法,保留数据的时序特征以及影响销量的其他外部因素,在数据预处理过程中使用one-hot编码技术对标称数据进行特征提取,选择梯度提升决策树算法进行训练,通过网格搜索法优化模型参数进行预测。
为验证组合模型的预测准确性及有效性,同时将模型预测的评价指标与经典GBDT算法、SVR、BP神经网络方法进行对比。实证结果表明,与单一的梯度提升决策树相比,使用滑动窗口对数据集进行特征扩展后,有效地提升了模型的预测精度,相比于 SVR和BP神经网络方法,所提出的SW-GBDT模型的预测误差较低、精度较高。模型的预测结果可以帮助农户在线上渠道销售农产品时降低运营风险,提高运营效率。另外,由模型预测的权重排序结果可以看出,店铺的评论数对店铺销量的影响最大,因此,店铺在后续销售过程中可以通过营销活动激发用户的评论意愿,从而提升店铺的销量。
但是,提出的预测模型对于销量波动较大的时间点预测结果偏差较大,在后续工作中,考虑将电商活动和突发事件等影响因素作为特征引入到模型中,以进一步提升模型的预测效果。
猜你喜欢
海外文摘·文学版(2022年4期)2022-04-14
当代水产(2021年7期)2021-11-04
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
文苑(2020年5期)2020-06-16
电子制作(2019年22期)2020-01-14
汽车观察(2019年2期)2019-03-15
疯狂英语·新读写(2018年3期)2018-11-29
汽车与驾驶维修(汽车版)(2017年2期)2017-03-18
家用汽车(2016年4期)2016-02-28
