
基于多模态融合的事件分类和分拨联合模型
2023-08-26 08:37佘祥荣
电脑知识与技术 2023年20期
佘祥荣


关键词: 事件分类; 事件分拨; 图卷积网络; RoBERTa; 多模态融合
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2023)20-0028-03
0 引言
政务服务热线是指各地市人民政府设立的由电话12345、市长信箱、手机短信、手机客户端、微博、微信等方式组成的专门受理热线事项的公共服务平台,是政府联通公众的重要渠道。通过政务服务热线,政府可以及时了解民生问题,为民排忧解难,从而有效化解社会矛盾[1]。政务服务热线的事件分拨过程主要还依赖于人工处理,但热线话务员常常无法深入了解每个部门的权力与职责,同时每天数以万计的政务热线事件需要被分配,人工处理的方式难以快速高效地完成事件分拨。因此,研究一种能够准确确定事件类型并对事件进行相应责任部门的自动分拨方法具有非常重要的意义。
利用自然语言处理技术理解政务热线事件得到事件的表征信息是完成事件分类和分拨的核心,传统的word2vec[2]、GloVe[3]等词表形式的词嵌入方法,仅能考虑文本自身的信息,难以处理文本在不同环境下存在一词多义的情况。CNN[4]或RNN[5]等模型由于其自身结构原因对文本信息的提取存在局限性,而基于大规模文本数据训练的语言模型(BERT[6], XLNet[7], Ro?BERTa[8]等)可以有效解决这类问题。但语言模型对文本的输入长度有一定的限制,在处理长文本事件时会截断事件文本,从而导致丢失文本信息的问题,而构建整个文本的图结构并应用GCN[9]来提取文本的图结构信息的方式可以有效解决文本过长的问题。注意力(Attention)机制[10]可以有效地对齐不同模态的事件信息,以提升事件分类的准确性。此外,将结合“三定”职责“( 三定”包含了机构规格、主要职责、内设机构及其具体职责、人员编制和领导职数等方面内容)的事件多模态信息进行融合,可以为事件分拨提供先验知识,以提高事件分拨的准确性。基于此,本文提出了一种基于多模态融合的事件分拨和分类联合模型方法,可以通过图计算和语言模型有效解决事件文本长短不一、要素不清的问题,并采用多模态融合的方式完成事件文本分类和事件分拨任务。
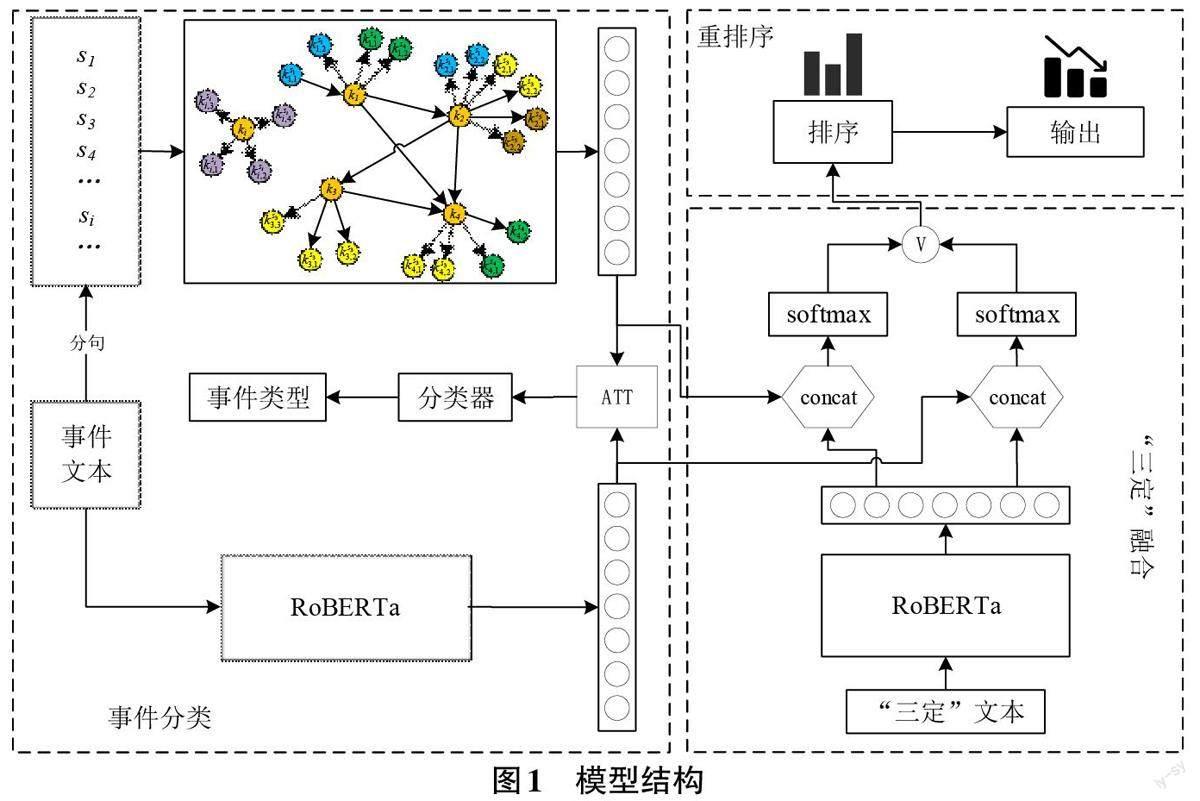
1 模型结构
本文提出了一种针对政府热线的事件分类与分拨的联合学习模型,该模型包括三个部分:基于GCN 和RoBERTa的事件分类模块、基于软投票的“三定”融合预测模块和重排序模块,模型整体结构如图1所示。
1.1 事件分类
基于图结构特征和文本特征融合的事件分类主要包括图构建、基于GCN 的图特征提取、基于Ro?BERTa的上下文特征提取和基于特征融合的事件分类四个部分。
1.1.1 图构建
由于事件文本存在长短不一的问题,并且事件文本中的某些句子与事件本身的主题不相關。因此,本文采用事件文本的命名实体和关键词作为事件的主题。由于命名实体识别和关键词提取不是本文的重点,所以本文采用现有工具包来进行命名实体识别和关键词提取。具体图构建过程如下:
1) 对于给定的事件文本D,首先进行分句处理并对事件文本进行分词和命名实体识别,同时应用Tex?tRank等关键词提取算法获得额外的关键词,以得到每个句子的节点词集合{A};
2) 对于事件的节点词集合{A}中的元素i 和j,如果i、j 出现在同一个句子中,则它们之间存在关系,在它们之间添加一条边;反之,元素i 和j 之间则不存在关系;
3) 将节点词集合{A}中的相同词进行合并,以完成事件文本的关系图构建。
1.4 重排序模块
对于一个给定的热线事件,将所有的“三定”均与该事件进行匹配并送入模型中,最终得到一个预测概率列表。由于一个部门包含多个“三定”职责,因此需要根据预测概率列表对分拨部门的匹配概率结果进行重新排序,以获取最优的分拨部门。具体过程为:
1) 对每个部门对应的“三定”职责预测概率进行累加,并计算各部门概率均值作为该部门的预测概率。
2) 根据概率结果对所有部门进行排序,选取Top-1部门作为最终分拨部门。
2 实验
2.1 数据集
本文数据集是基于芜湖市政务服务热线的真实事件分配案例构建得到,包括“事件-部门”和“事件- 三定”两部分。“事件-部门”是基于政务热线真实事件分拨处理结果构建,包含30个市级部门对应的3万条事件数据。“事件-三定”是由政务工作人员根据“事件-部门”数据中30 000条数据的实际处理结果标注所得,包括30 000条正样本(匹配)和采用随机抽取的方式构建的60 000条负样本(不匹配)。数据集描述如表1所示。
2.2 实验设置
本文使用版本为1.7.1的PyTorch构建网络模型,实验环境的操作系统为Ubuntu 18.04 LTS,显卡为NVIDIA GeForce GTX 3090。本文使用RoBERTa模型作为预训练语言模型对事件文本和“三定”文本进行语义提取,RoBERTa的嵌入维数为768,词汇量为30000,输入序列长度为512;GCN嵌入大小设置为768;采用学习率为10e-5的Adam优化器作为模型的优化方法;采用批大小为16的分批对模型进行训练。
2.3 事件分类实验结果
本文将所提出的模型与多种先进的文本分类基线模型进行对比,包括:HAN, TextGCN, XLNet, Bert?GCN。同时,采用传统文本分类指标Micro-F1 和Weighted-F1作为本文的评价指标。
表2是不同事件文本分类方法的实验结果。结果表明,相比于其他基线模型,本文的联合学习模型在事件分类任务上达到了最优性能。HAN 模型采用BiLSTM网络结合注意力机制提取文本上下文特征信息,但是对文本的局部特征提取较差,因此模型效果较差;而使用GCN网络的TextGCN模型可以根据文本结构图有效提文本的图结构信息,可以有效缓解长文本带来的网络记忆丢失的问题,但GCN对文本本身的上下文语义信息提取能力较差;XLNet语言模型可以有效编码文本上下文信息,但也对输入文本长度存在限制,因此模型效果不如采用语言模型和GCN结合的BertGCN模型;本文使用RoBERTa语言模型结合GCN 的结构,同时采用基于注意力机制的融合模型,以实现有效多模态特征信息的对齐,从而使模型具有最优的分类效果。
2.4 事件分拨实验结果
为了评估分拨任务,本文将所提出的方法与以下先进的事件分类任务基线方法进行了比较,包括:Siamese-BiLSTM-based, ABCNN-based, BERT-BiGRU-based,ELECTRA-BiGRU-based。本文采用P@5、MAP、MRR、Precision、Recall和F1指标来评价事件分拨的性能。
事件分拨对比实验结果如表3所示,由表3可知,本文方法在每个指标的效果上,均优于其他基线方法。相比于Siamese-BiLSTM-based 模型和ABCNNbased模型使用BiLSTM网络以及CNN网络作为特征提取的基础网络,采用语言模型作为特征提取网络的模型可以有效地提取文本上下文语义信息,因此效果优于Siamese-BiLSTM-based 和ABCNN-based 模型;BERT-BiGRU-based 模型和ELECTRA-BiGRU-based 模型采用不同的语言模型结合BiGRU网络进行事件分拨,因此模型效果较为相近,主要是由于语言模型对下游任务微调上存在的差距;而本文模型使用RoBERTa 语言模型和GCN网络分别提取事件文本的上下文语义信息和文本的图结构信息,可以有效提取文本本身的语义信息并缓解事件文本长短不一的问题;同时,本文还使用了基于后期融合的方式对事件的图结构特征以及事件的上下文文本特征的预测结果进行融合,从而可以有效提升模型的准确性。因此,相较于其他基线模型,本文模型取得了最优的分拨效果。
3 结论
本文提出了一种基于多模态融合的事件分类和事件分拨联合学习模型,该模型使用图计算和语言模型有效解决事件文本长短不一、要素不清等问题。模型首先通过构建事件文本的文本结构图并使用GCN 获取图结构特征;其次,使用RoBERTa语言模型提取事件文本的上下文语义特征;然后,使用注意力机制对融合事件文本图结构和上下文语义的多模态信息,并采用文本分类模型进行事件分类;最后,采用后期融合的方式对事件的分拨部门进行预测,并利用重排序模块对部门预测结果进行排序,输出事件的最优分配部门。事件分类和事件分拨的实验结果表明,相较于其他基线模型,本文提出模型在两个任务上均具有更优的性能。
