
用于地球静止轨道目标的光学检测算法*
2023-08-28 15:43韩冰王晨希翟智刘乃金
空间碎片研究 2023年1期
韩冰,王晨希,翟智*,刘乃金
(1. 西安交通大学未来技术学院,西安710049;2. 西安交通大学机械工程学院,西安710049; 3. 西安交通大学空间智能制造研究中心,西安710049;4. 中国空间技术研究院,北京100081)
1 引言
自1957年苏联发射了第一颗人造卫星“斯普特尼克”-1 以来,随着各国航天事业的蓬勃发展,卫星、火箭、空间碎片等常驻空间物体(Resident space objects,RSOs)的数目激增,这不仅压缩了有限且不可再生的地球卫星轨道资源,同时也带来了轨道资源拥挤和空间碰撞等问题,给各国空间活动造成了越来越大的现实威胁[1]。因此通过空间态势感知(Spatial situational awareness,SSA)系统跟踪、监测、编目和侦察空间目标,对于减轻碰撞造成的空间资产破坏风险至关重要[2]。SSA 作为开展各类空间活动的基础能力,已经引起各国高度关注和大力投入[3]。
地球静止轨道(GEO)是高价值太空资产最集中、轨道资源最宝贵的区域。地球静止轨道周期与地球自转周期接近,分布在该轨道上的卫星与地球表面相对静止,可以为地面用户提供连续、长期的服务,因此成为各个国家开展空间态势感知和太空安全防护与竞争的热点区域[4]。空间态势感知主要通过地基雷达、地基望远镜以及天基光学、天基红外和天基雷达等方式,实现对已知和未知的空间目标进行监测。
本文专注于地基探测地球静止轨道的常驻空间物体,地球静止轨道高度为大约36000 km。因此,通过地基观测收集到的图像中恒星成像为条纹,而地球静止轨道物体与地球自转同步,它们相对于观测器的位置大致静止,所以成像为斑点。
如图1 所示,地球静止轨道物体并非完全可见。由于大气失真和较长的曝光时间,接收到的轨道物体光子被分散成像在几个像素上,这使得观察到的空间物体变暗;云层覆盖、大气/天气影响、光污染、传感器噪声/缺陷、背景恒星遮挡(如图1(a)第二帧所示)以及在极少数情况下,活跃的地球静止轨道卫星在捕获期间进行的轨道机动等各项因素也降低了空间目标的可见性(如图1(a)第四帧所示,肉眼几乎不可见)。除此之外,如图1(b)所示,由于传感器噪声和缺陷引起的斑点状伪像和亮像素与轨道目标像点十分相似,增加了检测问题的难度。因此,本文将该问题转化为在杂乱的图像背景中定位类似暗斑点的一种远距离小目标检测问题。

图1 地基观测图像示例,源自SpotGEO数据集[5]Fig. 1 Examples of ground-based observation images from the SpotGEO dataset[5]
小目标检测长期以来是计算机视觉中的一个难点和研究热点,其旨在精准检测出图像中可视化特征极少的小目标[6]。对于轨道点状目标检测问题,目前已经提出了许多方法。一种常见的方法是图像叠加方法[7-10],该种方法通过连续捕获一个图像序列的多个图像并堆叠在一起,利用GEO轨道物体相对于背景恒星以不同模式移动的先验知识来识别轨道目标。然而,由于微弱物体的信噪比(Signal to Noise Ratio,SNR)过低,这一系列方法的检测效率在幅度上通常受到硬件传感器的可观测幅度的限制,导致其难以检测微弱物体[11]。针对此问题,一种被称为先跟踪后检测(Track-Before-Detect,TBD)[12,13]的方法被提出,该方法在一段足够长的观察周期中,收集并累积不同时间的信号测量值,以此来提高微弱目标的SNR,直到达到能够检测到的水平。但该技术的缺点是需要较大的时间成本才能实现图像序列中弱目标足够的积累,并且要求精确的轨道初始化。此类传统的目标检测方法通过手工设置参数来提取特征,泛化性差、定位精度不足、冗余计算量大,只能在特定的场景满足需求。
与传统方法相比,基于深度学习的算法克服了特征提取鲁棒性差的缺点,检测效果显著提高。然而,现有算法的设计往往更为关注大/中尺度目标的检测性能,针对类似GEO轨道物体的点状小目标检测的优化并不多。加之小目标可利用特征少、定位精度要求高、占比少等自身特性所带来的难度,导致大多数算法在小目标检测上普遍表现不佳。
Liu 等[14]提出一种多尺度目标检测算法(Single shot multibox detector,SSD),利用较浅层的特征图来检测较小的目标,提高了小目标的检测效果。利用Liu等提出的技术,文献[15]通过修改第一卷积层的步长,发现了第一个卷积层中的下采样操作对小物体的检测精度有巨大影响。Kong等[16]提出了一种多尺度融合网络,通过综合浅层的高分辨率特征和深层的语义特征以及中间层特征的信息显著提高了召回率,进而提高了小目标检测的性能。为节省特征融合的计算资源并获得更好的特征融合效果,Lin等[17]结合单一特征映射、金字塔特征层次和综合特征的优点提出了特征金字塔(Feature Pyramid network,FPN)结构,引入了一种自底向上、自顶向下的网络结构,通过将相邻层的特征融合以达到特征增强的目的。近些年来,也出现了一些适用于小目标的数据增强方法,Kisantal等[18]针对小目标覆盖的面积小、出现位置缺乏多样性、检测框与真值框之间的交并比远小于期望的阈值等问题,提出了一种Copy-Paste增强的方法,通过在图像中多次复制粘贴小目标的方式来增加小目标的训练样本数,从而提升了小目标的检测性能。在Kisantal等的基础上,Chen等[19]提出了一种自适应重采样策略进行数据增强,这种策略基于预训练的语义分割网络对目标图像进行考虑上下文信息的复制,以解决简单复制过程中可能出现的背景不匹配和尺度不匹配问题,从而达到较好的数据增强效果。Zoph等[20]超越了目标特性限制,提出了一种通过自适应学习方法,例如强化学习选择最佳的数据增强策略,在小目标检测上获得了一定的性能提升。除此之外,一种摆脱锚框机制(FreeAnchor)的检测方法被提出[21-23],其核心思想是将目标检测任务转换为关键点的估计,这在架构上更简单、检测小目标效果更好。
受到以上工作的启发,本文方法基于目前流行的RetinaNet[24]网络框架,针对GEO空间目标检测任务中目标特征薄弱、尺度小和定位精度要求高的问题,提出SFF-RetinaNet算法,设计了用于空间目标检测的NDResNet-50骨干网络,避免对原始图像的下采样,提高算法对目标浅层特征的提取能力。针对观测图像中目标像素占比极小、定位精度要求高的问题,引入FreeAnchor 模块,将锚框匹配策略转化为极大似然估计问题进行优化,使高质量的检测边界框具有更高的精度来满足小目标检测和定位的要求,提高检测精度。针对观测图像中目标样本数量匮乏、分辨率低及分布不均匀的问题,采用Copy-Paste 和多分辨率采样的数据增强方式,扩充同一张图像中的目标数量,丰富小目标的特征,提高了模型的学习能力。实验结果表明,本文提出的策略在GEO轨道目标检测任务中具有较好的检测效果。
2 RetinaNet目标检测算法概述
RetinaNet算法是一种基于锚框的一阶段通用目标检测算法。如图2所示,网络结构由Backbone(主干网络)、Neck(特征融合网络)和Head(分类子网络与边框回归子网络)三部分组成。RetinaNet采用ResNet-50作为Backbone,对图像进行特征提取,同时在Neck部分构建FPN进行特征融合。在Head部分,RetinaNet块使用classsubnet和boxsubnet分别处理目标分类任务和边界框回归任务,并且使用FocalLoss根据置信度动态调整交叉熵损失来解决样本不平衡问题。
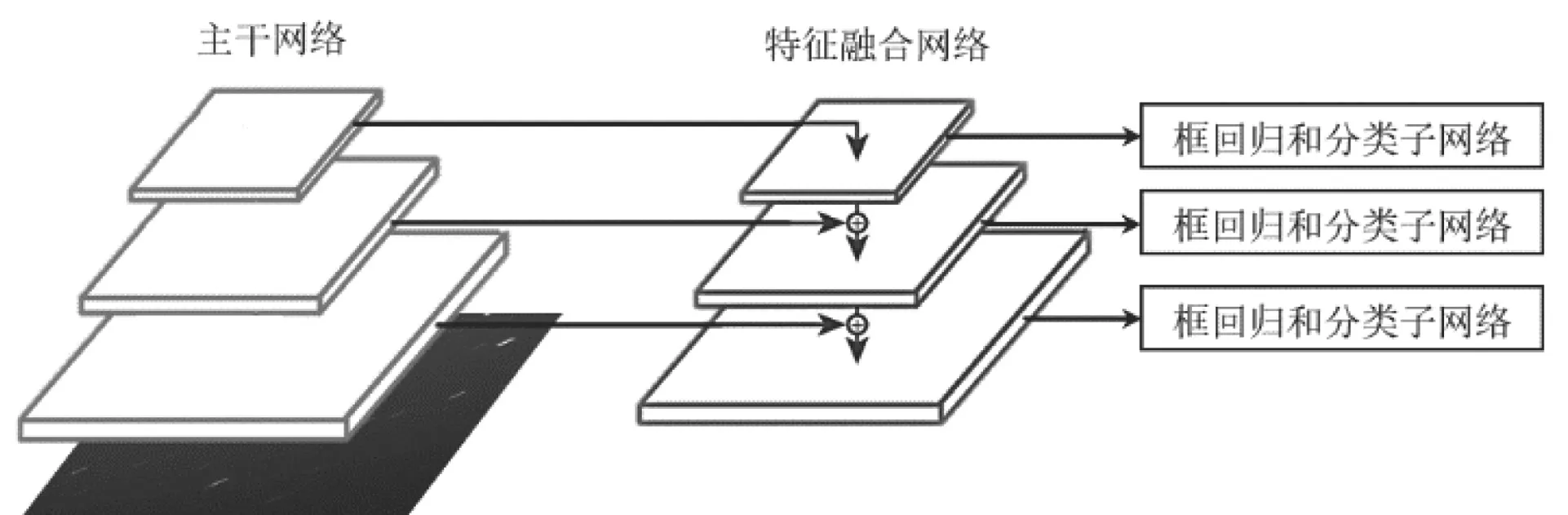
图2 RetinaNet网络结构图Fig. 2 RetinaNet network structure diagram
3 SFF-RetinaNet
本文针对GEO空间目标特征薄弱、尺度小和定位精度要求高的问题,提出SFF-RetinaNet 算法,保留RetinaNet解决正负样本不平衡问题的能力,并进一步提高。同时,提出了浅层聚焦残差网络(Shallow focus residual network,SFResnet)主干网络结构,引入FreeAnchor 检测器和多分辨率融合的Copy-Paste数据增强,SFF-RetinaNet算法整体结构如图3所示。
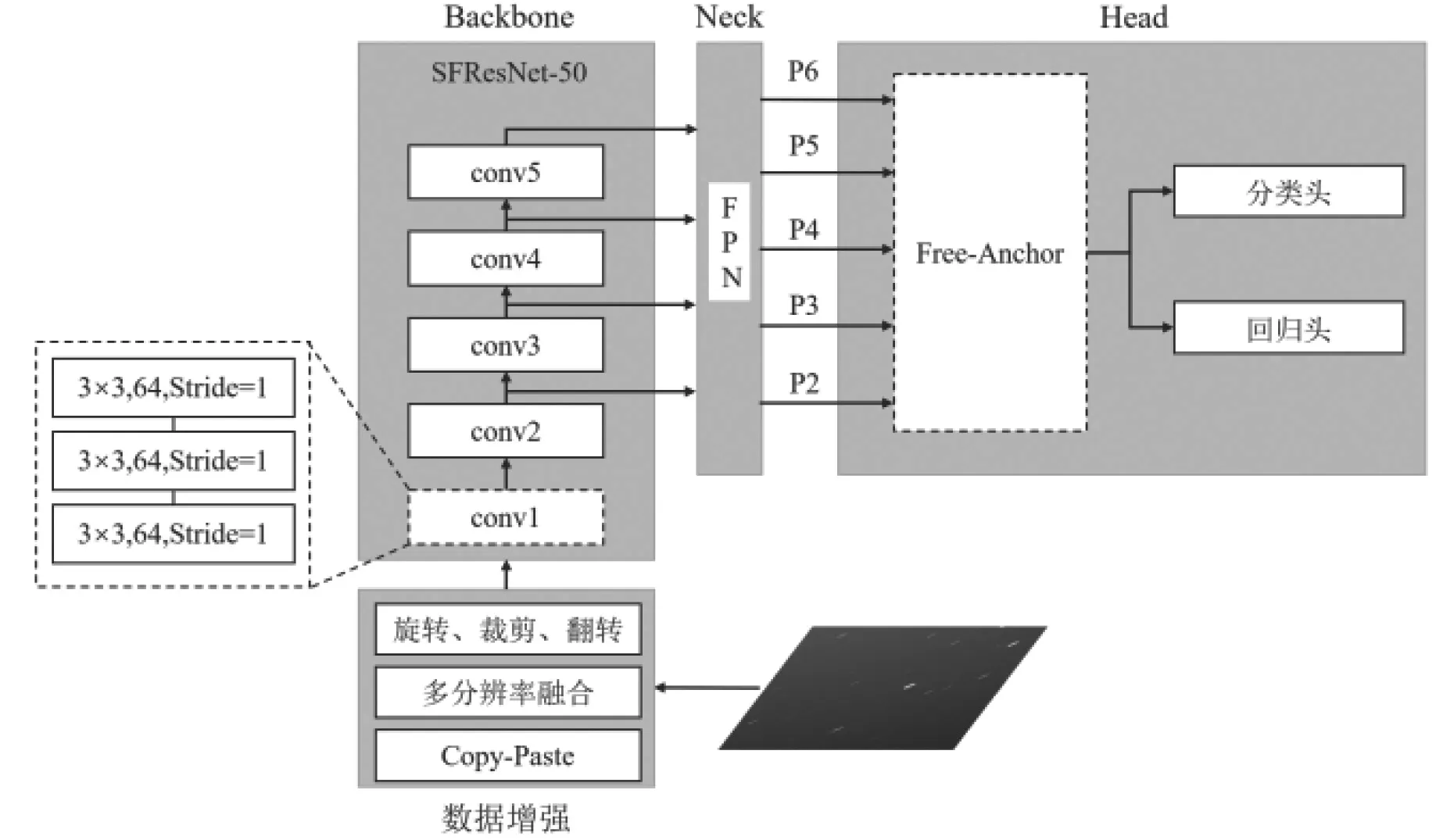
图3 SFF-RetinaNet网络结构图Fig. 3 SFF-RetinaNet network structure diagram
3.1 SFResNet-50
地面与GEO轨道距离为大约36000 km,观察到的空间物体在图像中只有不超过10个像素,大部分的空间物体只存在于浅层特征层中。深层的ResNet-50特征提取网络很容易忽略这些浅层特征,从而不能有效地提取和学习弱小目标的特征。这是由于ResNet-50的第一卷积层步长为2的下采样操作引起的,此操作会显著影响小物体的检测精度。因此,为了更有效地提取浅层特征,使主干网络更多地关注浅层纹理信息,同时继承其强大的分类能力,本文设计了SFResNet-50主干网络架构。
如图4所示,删除了ResNet-50第一个卷积层中的下采样操作,并用连续三个3×3卷积核替换7×7 卷积核。通过以上改进,SFResNet-50 能够从图像中利用更多的局部信息,从而为小物体检测提取强大的特征。
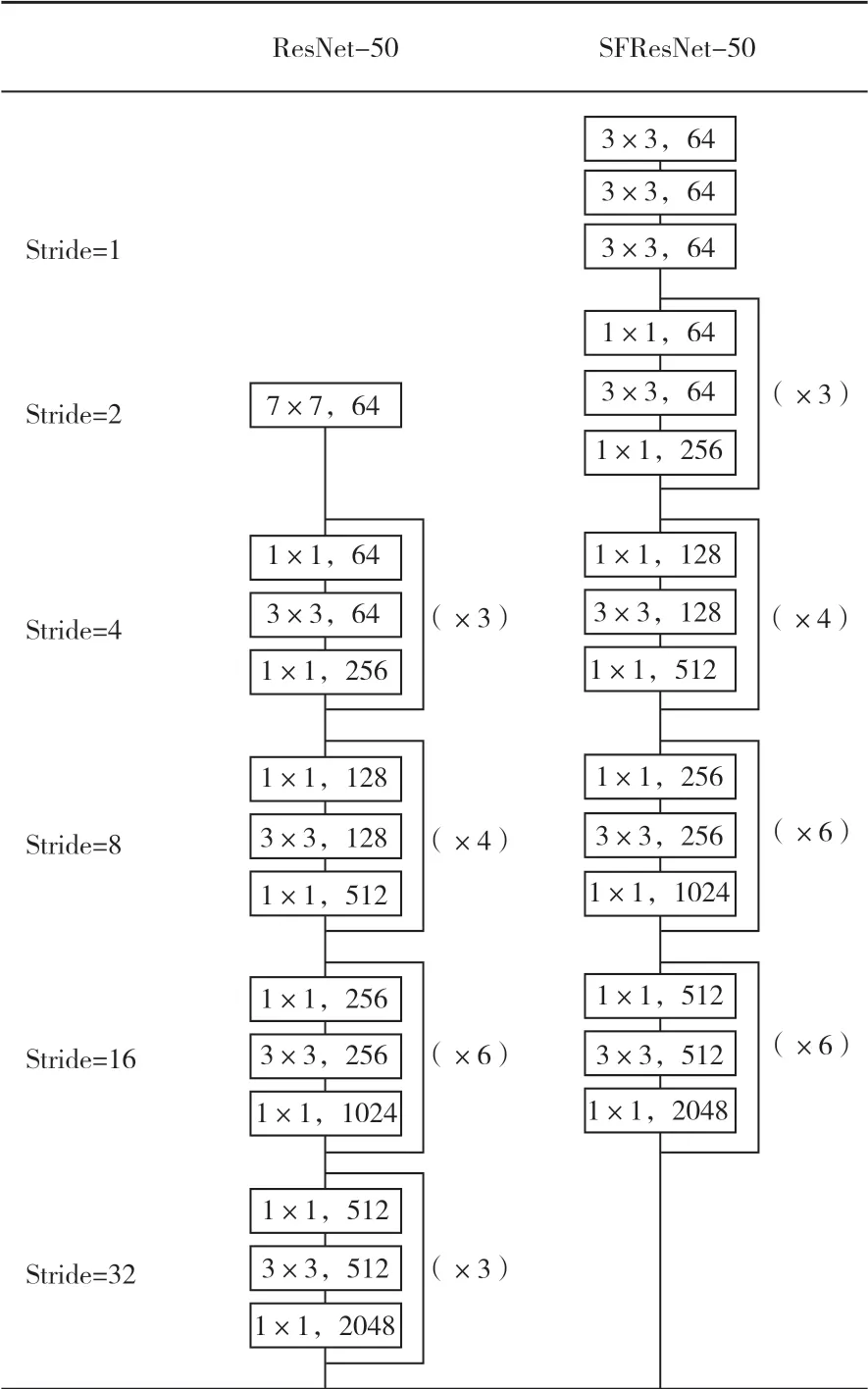
图4 网络结构更改对比Fig. 4 Comparison of network structure changes
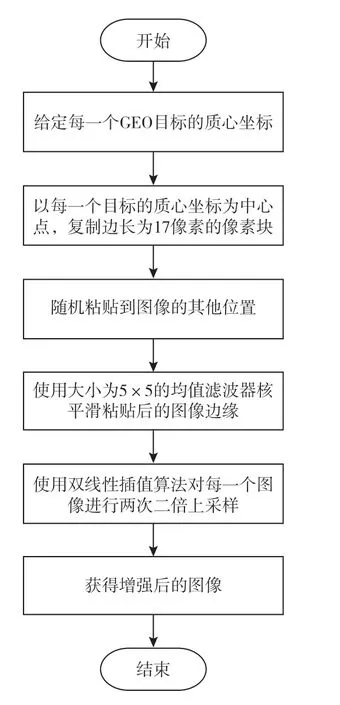
图 5 数据增强流程Fig. 5 Data enhancement process

图 6 数据增强整体效果Fig. 6 Data enhancement overall performance
3.2 FreeAnchor
锚框机制在目标检测中扮演着重要的角色,许多先进的目标检测方法都是基于锚框机制而设计的,但是锚框这一设计对于GEO 空间物体这类小目标的检测极不友好。由于空间目标在图像中覆盖面积小,且定位精度要求高,在预测过程中,即便预测边界框只偏移一个像素点,也会对定位效果产生很大的影响。此外,锚框的使用引入了大量的超参,比如锚框的数量、宽高比和大小等,使得网络难以训练,不易提升小目标的检测性能。FreeAnchor 从极大似然估计的角度优化锚框与对象的匹配,能够自动学习目标的空间信息和局部语义特征,生成适合目标的锚框,在一定程度上提升了小目标检测的精度。FreeAnchor 从三个方面优化对目标和锚框的匹配。
(1)优化召回率,如式1 所示,定义了召回率最大似然函数。其中Precall(θ)为所有目标的锚框分类置信度和定位置信度的最大乘积,为分类置信度,为定位置信度,Ai为锚框集合。通过该极大似然函数,寻找最大的目标锚框分类置信度和定位置信度乘积。
(2)提高检测精度,如式(2)所示,定义了精度最大似然函数。
式中:P{aj∈Ai}=1-P{aj→bi}max表示aj属于背景类的概率,P{aj→bi}表示锚框aj正确预测目标bi的概率,表示不属于背景类的置信度。该函数目的是将定位较差的类归为背景。
(3)为了兼容非极大值抑制算法(Nonmaximum Suppression,NMS),定义了饱和线性函数(Saturated Linear,SL)用来表示P{aj→bi},如式(3)所示。
FreeAnchor 通过引入自定义的似然函数,实现了通过学习的方法优化目标与锚框的匹配。在保证能与NMS算法兼容的同时,也优化了召回率和提高了检测精度。因此本文引入FreeAnchor,以提高检测器对锚框分配的效果。
4 数据增强设计
在本文使用的SpotGEO 数据集中,图像分辨率为640×480,空间目标的尺度很小,并且在同一张训练集图像中目标出现的个数均值为1.74,物体像素所覆盖的区域在整个图像上占比不超过0.1%,在位置特征上也缺乏多样性。传统的旋转、裁剪、翻转等数据增强方法不能有效地提高小目标的准确性。因此本文通过提高图像分辨率和图像中目标数量的方式增强数据,用来增加小目标特征的丰富度。
如图5 所示,首先使用Copy-Paste 的方式,对图像中每一个目标进行复制后再粘贴到图中任意位置的方式进行样本扩充,操作简单且效果良好。在复制目标区域时,采用的面积比目标框的真实面积略大,保留了目标周围一定的上下文特征。除此之外,使用大小为5×5 的均值滤波器平滑粘贴后的目标图像边缘,在不干扰目标像素特征的基础上,使新粘贴图像的背景更加自然。之后通过双线性插值算法分别生成图像2 倍(1280×960)和3 倍(1920×1440)分辨率的图像。整体效果如图6所示。
5 实验对比与分析
5.1 实验数据集
本文使用的观测数据来源于2020年Kelvins Spot the GEO satellite挑战赛[25]中公开的SpotGEO数据集[6]。该数据集是通过在地面天文望远镜上部署低成本CMOS 传感器而采集到的夜间图像,所采用的望远镜角像素大小约为4.5 rad/s,根据相机转动角速度与曝光时长计算每个像素对应弧长约800 m。该数据集以每五个连续帧构成一个图像序列,总共6400个图像序列,包含32000张图像,每一个图像的大小为640×480 像素。按4∶1 的比例划分训练集和测试集。数据分布如表1所示,由于大气/天气影响、云层核恒星遮挡等原因,约25%的图像中不存在目标,同时存在7 个及以上目标的样本量较少。
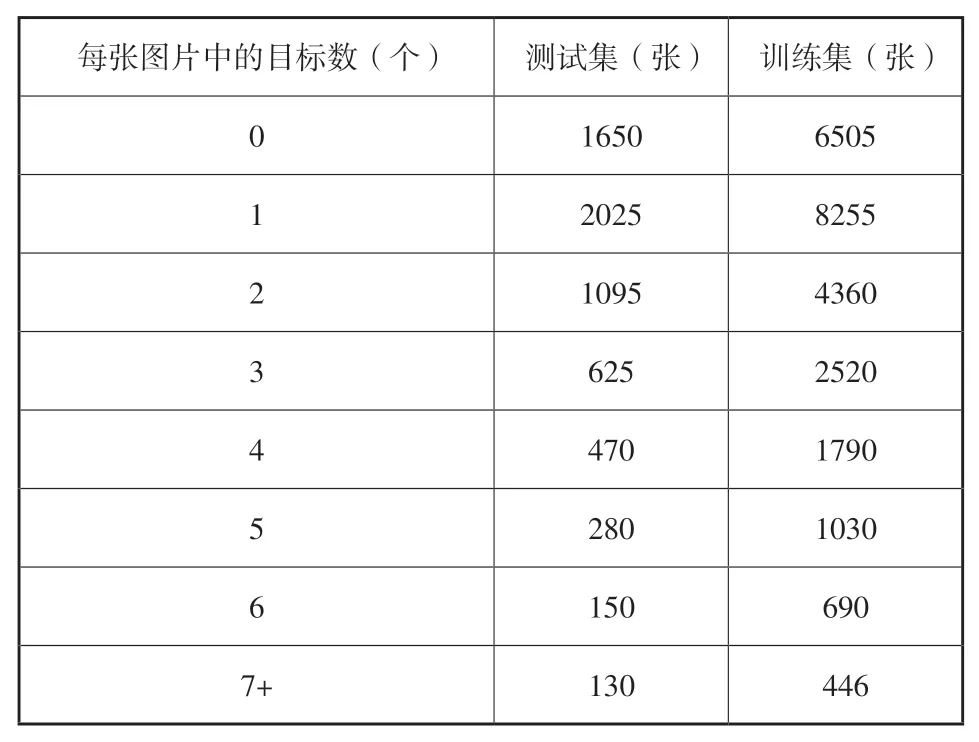
表1 数据集样本分布Table 1 Dataset sample distribution
5.2 实验环境
实验硬件环境采用Intel Xeon Gold 5218R 处理器,GTX3090 显卡,CUDA 版本为11.3,使用MMDetection 深度学习框架,共训练24 轮。训练中使用SGD优化器优化参数,Batchsize为16,学习率设置为0.02。
5.3 实验结果
本文在SpotGEO数据集上评估了SFF-RetinaNet,并与Kelvins Spot the GEO satellite排行榜上的方法进行了比较。SpotGEO数据集的评价指标由两部分组成,分别为1-F1分数和回归误差。F1是一种流行的统计数据,它同时考虑了精度和召回率,计算公式如式(5)所示。其中Precision表示预测精度,recall表示召回率。回归误差表示预测目标区域与真值的交并比误差,具体用均方差MSE计算,如式(6)所示。其中n表示样本数量,Y表示预测值,G表示真值。
由于排行榜仅公开了每个方法所产生的1-F1分数和回归误差(MSE)指标而并未公开具体算法内容,因此本文仅对比各个方法所产生的指标。如表2所示,SFF-RetinaNet的检测效果位于第11位,所产生的1-F1分数相较第一名高出了约0.11,整体来说处于排行榜的第三到第四梯队。一个很重要的前提是,本文只将SFF-RetinaNet训练了24轮,这是极少的,即便SFF-RetinaNet 未必是最优的,但也能够证明其在处理GEO任务上是有效的。

表2 模型指标对比Table 2 Model metric comparison
5.4 消融实验
在目标检测任务中,使用预测目标框与真实框的交并比(Intersection over Union,IoU)来评价模型检测效果,一般来说,IoU>0.5 代表成功预测目标位置,精确率(Precision)与召回率(Recall)可以多角度地评价模型性能。平均精确度(Average Precision,AP)表示不同召回率下精确率的均值,用于评价单类别检测效果,所有类别检测精确度取平均可得到评价目标检测算法整体性能的平均精确度均值(Mean Average Precision,mAP),指标每秒检测图片数量(Frames Per Second,fps)用于评价模型检测速度。
表3 是本文的实验结果,表格中带√标记表示实验采用该模块,组合1是RetinaNet网络的检测效果,其mAP 为48.95%,说明其在小目标检测任务上效果一般。组合2 至组合6 是本文基于RetinaNet模型各个改进点的消融实验结果,组合7是本文提出的SFF-RetinaNet模型的检测效果。
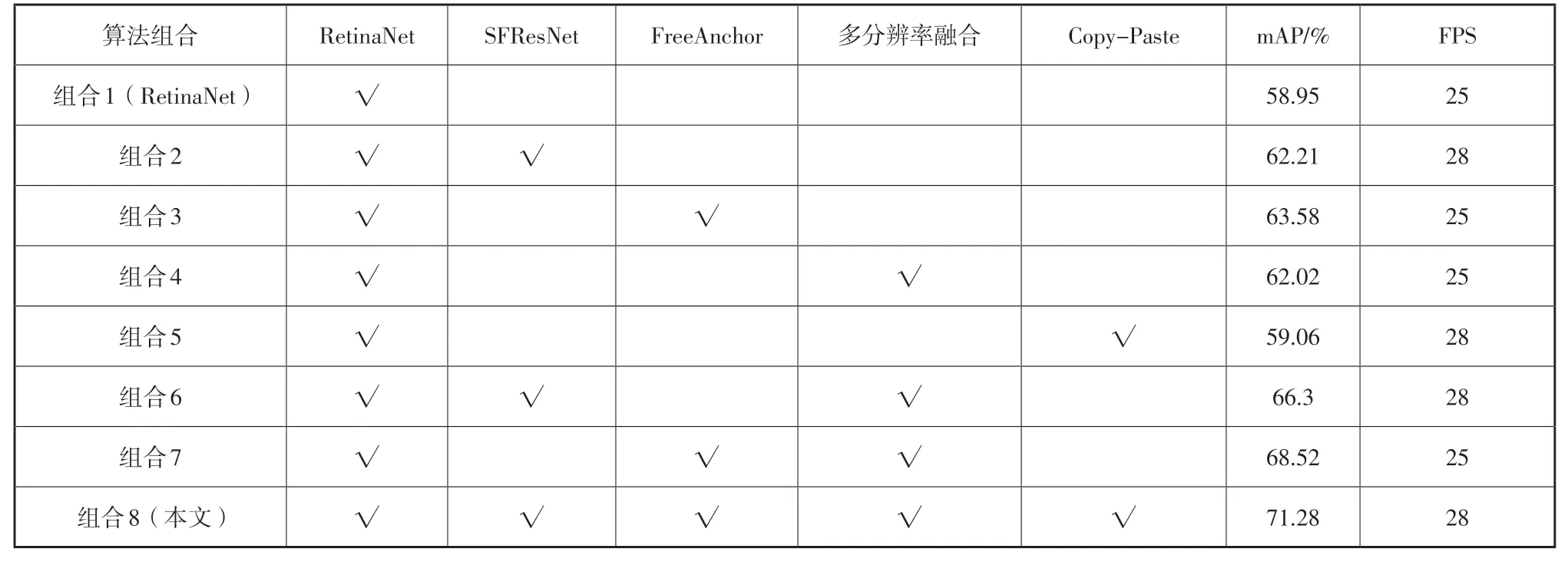
表3 模型改进实验结果Table 3 The experimental results of model improvement
组合2、3、4、5 表明,S F R e s N e t、FreeAnchor 和多分辨率融合的Copy-Paste 模块对于原来模型在精度上均有改进效果。本文提出的SFResNet 结构在精度上提升了3.26%mAP,检测速度提高了3fps,说明通过SFResNet降低了原有网络结构的参数量,在性能没有下降的情况下还提高了计算的效率。引入的FreeAnchor 模块在精度上提高了4.63%mAP,说明基于锚框的方法在检测类似轨道物体的极小目标时并不适用,通过将目标检测转化为关键点预测问题能够提升预测小目标的效果。采用的多分辨率融合的方式在精度上提高了3.07%mAP,说明通过提高图像的分辨率,丰富目标的特征,能够提高小目标的检测效果。
组合5表明,通过Copy-Paste的数据增强方式在这次实验中仅仅使得检测精度得到0.11%mAP的微弱提升。本文认为限制Copy-Paste效果的主要原因是数据集所采用的传感器成像效果差,该低成本相机的成像具有较大噪声,导致相当一部分图像会出现颜色不均匀的现象。通过复制粘贴的手段,导致原目标点周围的背景与新粘贴位置的背景差异过大,导致模型学习到了背景发生突变的特征,增强数据的同时也给模型的学习带来了噪声,如图7(b)所示。

图7 Copy-Paste增强前与增强后效果对比Fig. 7 Performance comparison before and after Copy-Paste enhancement
但本文认为Copy-Paste可以作为一种有前途的GEO目标数据增强的思路被提出。从图像的角度出发,空间目标探测属于极小目标检测问题,该问题面临着分辨率低、可提取特征少、样本数量匮乏等问题。采用Copy-Paste方法通过在图像中多次复制粘贴目标的方式来增加目标的训练样本数,从而提升小目标检测的效果。后续的研究中,可以在Copy-Paste的基础上添加上下文自适应的后处理,更加充分地利用全局上下文信息用来解决背景不匹配和尺度不匹配问题,从而达到较鲁棒的数据增强效果。
组合6、7、8 的实验结果表明SFResNet、FreeAnchor 和多分辨率融合模块进行组合对模型的提升效果大于单一模块。其中本文提出的SFFRetinaNet 模型相较于RetinaNet 的精度提高了12.33%mAP,在检测速度上提升了3fps。
6 结论
针对地球静止轨道(GEO)空间目标探测任务中目标特征薄弱、尺度小和定位精度要求高的问题,本文提出了SFF-RetinaNet算法,设计了一种聚焦浅层特征的残差网络结构,提高了网络对图像浅层特征的提取能力;引入了FreeAnchor 检测器,将锚框匹配策略转化为极大似然估计问题进行优化,提高了目标检测框的定位精度;针对观测图像中目标样本数量匮乏、分辨率低及分布不均匀的问题,引入多分辨率融合的Copy-Paste数据增强方法,提高了算法的检测效果,得到了更优的算法模型。本文通过实验得到以下结论,SFF-RetinaNet算法在Kelvins SpotGEO挑战赛的数据集上进行测试,检测精度为71.28%mAP,相较原算法提高了12.33%,算法检测速度提高了3fps,在本文的球静止轨道空间目标检测任务具备更优的检测效果。
猜你喜欢
信号处理(2022年11期)2022-12-26
计算机与生活(2022年11期)2022-11-15
计算机工程与科学(2022年8期)2022-08-20
中南民族大学学报(自然科学版)(2022年3期)2022-05-08
空间科学学报(2020年6期)2020-07-21
空间科学学报(2020年6期)2020-01-08
疯狂英语·新策略(2019年10期)2019-12-13
环球时报(2019-12-05)2019-12-05
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
