
基于改进人工神经网络的页岩气井产量预测模型研究
2023-09-02 10:03林魂孙新毅宋西翔蒙春熊雯欣黄俊和刘洪博刘成
油气藏评价与开发 2023年4期
林魂,孙新毅,宋西翔,蒙春,熊雯欣,黄俊和,刘洪博,刘成
(1.重庆科技学院安全工程学院,重庆 401331;2.重庆地质矿产研究院,重庆 401120)
页岩气储层具有低孔、低渗的特点,且储层参数、压裂参数与产量之间具有复杂的非线性关系[1−2]。目前大部分页岩气井产量的预测方法主要基于传统的数学模型,不仅要耗费大量的精力和时间去分析井的情况,而且受页岩气储层不确定性和复杂性影响,预测效率和准确率很难达到一个理想的效果[3−4]。
随着人工智能技术的发展,在油气领域引入机器学习方法已成为一种趋势[5−6]。人工神经网络作为机器学习技术方法的一种,已在非常规油气生产中显示出巨大潜力[7−8]。在人工神经网络模型训练函数选取中,随机梯度下降算法(SGD)为求解常用方法,其可以快速地收敛到一个可接受的解,但缺点在于收敛方向有一定的偏差,且稳定性差、计算效率低[9−11];另一种常见的训练函数为批量梯度下降算法(BGD),该函数根据全部样本构建出代价函数的梯度,能沿着当前最优的下降方向收敛,但缺点在于计算代价较高、耗时长[12−14]。目前利用神经网络在油气产量预测领域中,以测井参数、压力参数等作为研究对象居多,而对压裂参数与产量之间的关系研究较少[15−16]。
研究在分析页岩气储层参数和压裂参数特点的基础上,提出基于物理意义和随机组合的方法构建特征参数,并采用小批量梯度下降算法(MBGD),建立针对页岩气井产量预测的改进人工神经网络预测模型[17−19]。与传统的BP 神经网络预测模型相比,建立的改进模型在精确度和有效性方面都有较大提升,能为页岩气储层压裂优化设计以及产能评价提供重要支持。
1 方法介绍
页岩气储层参数、压裂参数与产量之间具有复杂的非线性关系,常规的模拟方法难以建立各参数与产量之间的关系,而人工神经网络对于这种复杂的非线性映射问题具有很好的处理能力[20−22]。
1.1 模型描述
网络模型为多层结构模型,由输入层、隐藏层和输出层构成,各层之间通过神经元激活函数进行信号传递。网络模型经过多组数据样本的学习训练,通过根据实际输出值与期望输出值之差,自适应确定各神经元的连接权重,最终达到对目标参数的准确预测。在进行产量预测时,通过输入单井各特征参数,根据设定的网络层数、隐藏层神经元个数、学习率以及迭代次数等参数,输入样本参数即可得到预测的产量值。
通过将页岩气储层参数和压裂参数作为网络模型的输入参数,其中工程参数包括水平井段长、完井井段长、压裂段数、总液量、砂量;地质参数包括含气量、孔隙度和渗透率等,这些参数在一定程度上可以反映页岩气储层参数、压裂参数与产量之间的相关信息,可以满足网络模型研究的需求。
首先将特征参数作为网络模型的输入层的神经元:
式中:X为输入数组;n为样本数量;x为样本参数数据;j为输入参数个数。
参数通过各层神经元向后传递,上一层输出神经元的值为下一层输入的神经元的值,k层各神经元输出值为:
式中:Y为神经元输出值;k为第k层神经元;ω为权重系数;b为偏置系数;h为对应层神经元个数。
激活函数f(x)为Sigmoig(S型函数)函数如下:
通过以页岩气储层参数和压裂参数为输入神经元,前3 个月平均日产量为输出神经元,建立合适的人工神经网络模型进行预测。
1.2 数据处理
研究以国外某页岩气区块生产井的各参数为数据集,包括水平井段长、完井井段长、压裂段数、总液量、总砂量等工程参数,含气量、孔隙度、渗透率等地质参数。
在数据清洗阶段,通过可视化方式对各个参数进行分析处理,包括数据的异常值处理、缺失值处理和标准化等操作。在异常值处理时,利用箱线图对压裂段数、总液量等参数进行分析,对数量较少且明显的异常值可直接删除;在缺失值处理时,由于数据集充足,且缺失值样本占整个样本的比例相对较小,所以将存在缺失值的样本直接丢弃。为使模型在学习训练时可以更好地收敛,采用Z−Score(标准分数)方法对数据进行标准化处理,如下:
式中:zi为标准化后数据;xi为原始数据;u为样本参数均值;N为样本总数。
通过上述数据清洗过程,为后续构建特征参数奠定基础。
1.3 模型评价
通过均方误差(MSE)(式5)和修正决定系数(T)(式7)对网络模型的预测泛化能力进行评价。
均方误差为输出值与目标值之间的平均平方误差,其值越小,说明预测模型精确度越高。
式中:f(xi)为输出值;yi为目标值。
通常使用决定系数(R2)(式6)对网络模型进行评价。
式中:R2为决定系数;Ya为真实值;Yp为预测值;Ym为真实值的平均值;为残差平方和。
由于构建了新的特征参数,增加了样本数量和特征数量,导致残差平方和减少,决定系数(R2)增大,而网络模型本身效果并非得到提升,导致模型评价具有欺骗性。为了消除模型评价的欺骗性,根据构建特征参数的方法和特点,采用修正决定系数(T)对网络模型的泛化能力进行评价。修正决定系数(T)衡量各个自变量对因变量变动的解释程度,其取值越接近1,则变量的解释程度就越高,即预测模型拟合越好、精确度越高。
式中:T为修正决定系数;p为样本特征数量。
1.4 模型改进
网络模型的训练样本和训练函数对模型的最终预测精度有重要的影响。根据页岩气储层参数和压裂参数的特点,从构建特征参数和训练函数两个方面对网络模型进行了优化改进。
1.4.1 构建特征参数
样本数据代表性的强弱决定了网络模型学习效果的好坏。通过对页岩气储层参数和压裂参数的特点进行分析,采用两种方式进行构建特征参数:一种是基于压裂参数的物理意义,将现有特征参数转换成具有新物理意义的特征参数,如通过总液量和完井井段长倍数之比得到新的特征参数每米液量,总砂量与总液量之比得到新的特征参数视砂比等;另一种是通过运用现有特征参数进行随机组合方式得到新特征参数,随机组合得到的新特征参数不具有实际物理意义。通过对新构建的特征参数进行测试,选取可以提高网络模型训练效果的特征参数作为训练样本。
数据集中,原始特征参数包含水平井段长等8个工程和地质参数,如表1所示。

表1 原始特征参数Table 1 Original feature parameters
通过基于物理意义转换和随机组合后,构建了每米液量等5个新的特征参数,如表2所示。

表2 新构建特征参数Table 2 Newly constructed feature parameters
通过修正决定系数(T)和均方误差(MSE)对构建特征参数前后模型的预测效果进行分析,结果见表3。由表3 可知,构建特征参数后的修正决定系数值为0.95,远高于构建特征参数前的0.68。构建特征参数后的均方误差值为0.025,远低于构建特征参数前的0.536。
以样本外10口井作为验证集来检验网络模型预测效果(图1)。由图1 可知,相比构建特征参数前,构建特征参数后的预测产量与实际产量交会图与45°线更贴近。

图1 构建特征参数前后预测产量与实际产量交会图Fig.1 Crossplot of actual and predicted yield before and after constructing feature parameters
通过比较构建特征参数前后的修正决定系数、均方误差、拟合效果等方面可以得出,通过构建特征参数后能明显提高网络模型的预测效果。
1.4.2 训练函数优化
研究针对样本数据集较多且代表性强的特点,采用小批量梯度下降算法(MBGD)。该算法以损失较小部分精确度和增加一定数量的迭代次数为代价,能够有效提升网络模型的总体优化效率。
梯度下降的代价函数关于ω和b的偏导数公式如下:
式(8)—式(9)中:ω为权重系数;b为偏置系数;x为输入值;y为真实值。
当n为1 时,此计算代价函数梯度使用一个样本数据;当n为样本总量时,计算代价函数梯度使用全部样本数据;当n为部分数量时,计算代价函数梯度使用一小批量样本数据。研究将小批量样本数n设置为128。
图2 给出了分别使用随机梯度下降算法(SGD)(图2a)和小批量梯度下降算法(MBGD)(图2b)的代价函数趋势。由图2a可知,在训练集和测试集上,随着迭代次数的增加,均方误差值虽然整体呈下降趋势,但代价函数曲线震荡幅度较大,梯度下降稳定性差、偏差大;由图2b可知,在训练集和测试集上,随着迭代次数的增加,代价函数曲线非常平滑地下降,即梯度下降稳定性好、偏差小,并且可以较快速达到最优值。通过结果比较可知,针对页岩气储层各参数数据集特点,采用的小批量梯度下降算法(MBGD)可以有效地提升网络模型的总体稳定性和预测精度。
1.5 模型结构
隐藏层神经元个数对网络模型的拟合效果有重要影响。研究采取公式法(式10)和试算法结合的方式进行选择。图3 为不同隐藏层神经元个数的均方误差(MSE)值折线。由图3可知,当隐藏层神经元个数为25 时均方误差(MSE)值最低,则选取隐藏层神经元个数为25。

图3 不同隐藏层神经元个数的均方误差(MSE)值折线Fig.3 Mean square error(MSE)curves of neurons in different hidden layers
式中:S为隐藏层神经元个数,m为输入层神经元个数。
通过构建特征参数后,网络模型的输入神经元由原始特征参数和新构建的特征参数组成,分别包含水平井段长等8个原始特征参数,以及每米液量等5 个新构建特征参数,共13 个参数。隐藏层神经元个数选取为均方误差(MSE)值最小时的神经元个数25,最后输出层为前3 个月平均日产量参数,则建立的人工神经网络模型的最终结构为13—25—1(图4)。
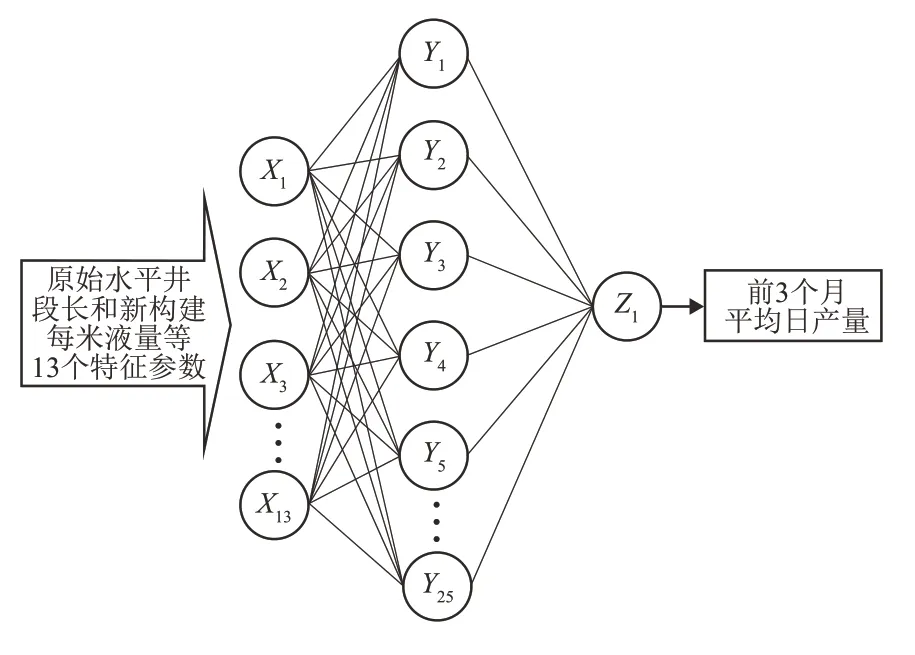
图4 网络模型结构Fig.4 Network model structure
2 实例应用
2.1 模型训练
研究以国外某页岩气区块多口井的储层参数、压裂参数和产量作为数据集,共10 000组数据,页岩气区块孔隙度平均为1.5%,渗透率平均为0.002 8×10−3µm2,含气量平均为3.1 m3/t。将整个数据集划分为训练集、测试集和验证集。训练集数据用于训练确定网络模型各层的训练权值,约占整个数据集的80%;测试集数据用于测试网络模型在训练集以外的泛化性和可靠性,约占整个数据集的20%;验证集数据将作为样本外数据对整体模型的准确性进行验证。另选取样本外10 口井作为验证集,用于检验预测值与真实值之间的匹配程度。
网络预测模型采用典型的三层神经网络模型,将原始特征参数和新构建特征参数共13个特征参数作为网络模型的输入层神经元,隐藏层神经元为25个,前3个月平均日产量作为输出层神经元。根据多次学习训练较好的结果为参考,将网络模型最大迭代次数设定为1 000,将学习率设定为0.07,每次学习最小数据集设定为128。
2.2 预测结果
通过利用验证集数据,对比分析了改进人工神经网络模型和传统BP神经网络模型的预测效果。
表4 为验证集10 口井前3 个月实际平均日产量值与改进的网络模型方法预测产量值和传统BP 神经网络方法预测产量值的对比。由表4 可知,首先,通过比较每口井的实际产量值和预测产量值,结果显示,相比传统BP 神经网络模型方法预测产量值,改进的网络模型方法预测产量值更加接近实际产量值;其次,通过比较分析表中相对误差值可知,传统BP网络模型方法的预测值最大偏差程度为35.57%,最小为15.59 %,而改进网络模型方法预测值的最大、最小偏差程度分别为9.00%、1.12%,均远低于传统BP 神经网络模型预测值的偏差程度。这表明,相比于传统的BP 神经网络模型,改进的神经网络模型预测结果最大、最小相对误差值的振幅有较大的降低,建立的改进网络模型方法在预测精度及稳定性方面明显得到提升。

表4 日实际产量与改进的网络模型方法和传统BP方法预测结果对比Table 4 Comparison of daily actual yield with prediction results of proposed method and traditional BP method
图5 为实际产量值与改进的网络模型方法预测产量值和传统BP 神经网络方法预测产量值的折线。由图5可知,改进后的网络模型预测的产量值与实际产量值折线更加贴合,其预测精确度远高于传统BP神经网络模型的预测产量值。
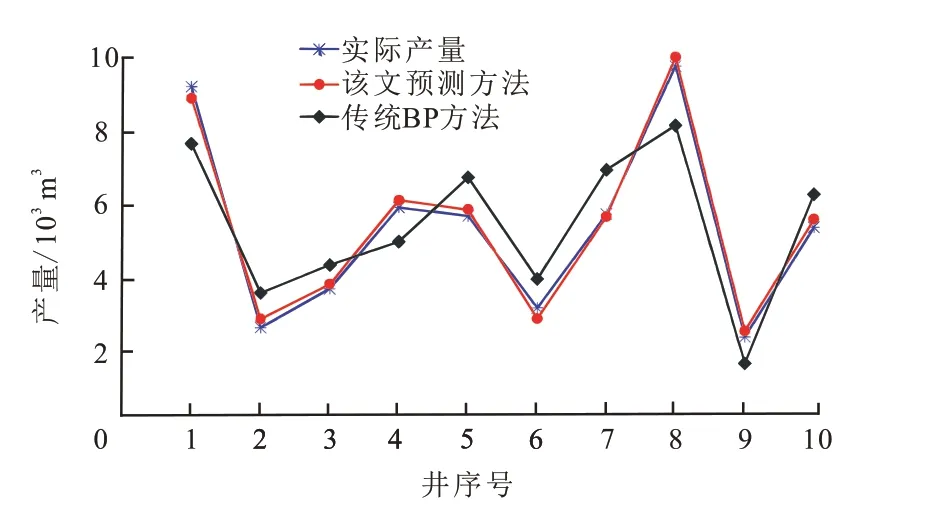
图5 实际产量值与改进的网络模型方法预测产量值和传统BP神经网络方法预测产量值的折线Fig.5 The line chart of actual yield value and the improved network model method to predict the yield value and traditional BP neural network method
表5给出了改进的网络模型和传统BP网络模型的均方误差(MSE)和修正决定系数(T)对比结果。由表5 可知,改进的网络模型方法均方误差值为0.006,远低于传统BP 神经网络模型均方误差值0.132;修正决定系数值为0.95,远远高于传统BP 神经网络模型的修正决定系数值0.73。

表5 2种模型结果评价Table 5 Evaluation of two models
综上所述,通过验证结果显示,改进的网络模型方法在分析页岩气储层参数、压裂参数与产量关系时,其预测产量值与实际产量值吻合度较高,并且在相对误差、均方误差(MSE)和修正决定系数(T)结果对比后发现,其准确率和稳定性均高于传统BP 神经网络模型。
3 结论
1)研究设计了基于物理意义和随机组合两种构建特征参数的方法,使训练样本特征参数数据代表性更强,且更加拟合网络模型,可以进一步提高网络模型的学习效果。通过对比构建特征参数前后的修正决定系数、均方误差以及拟合效果,可得构建特征参数后的预测产量值与实际产量值更贴近。
2)针对页岩气储层参数和压裂参数的数据集特点,采用了小批量梯度下降法(MBGD)作为训练函数,可以有效提升网络预测模型的稳定性和总体优化效率。
3)建立的改进人工神经网络模型能较好地拟合页岩气储层参数、压裂参数与产量之间复杂的非线性关系。且相比传统的BP 神经网络模型,改进人工神经网络模型的预测精度和稳定性都具有明显优势。
猜你喜欢
自然杂志(2021年6期)2021-12-23
中国特种设备安全(2021年5期)2021-11-06
装备制造技术(2021年4期)2021-08-05
电脑与电信(2021年10期)2021-02-10
南方农业学报(2020年4期)2020-06-04
南方农业学报(2020年10期)2020-01-21
科学与财富(2018年12期)2018-06-11
现代装饰(2018年5期)2018-05-26
制造技术与机床(2017年11期)2017-12-18
电源技术(2015年5期)2015-08-22
