
含非线性时间项的无偏灰色模型构建与应用
2023-09-04 10:42黄渝晴刘晓梅高美娜
上海第二工业大学学报 2023年2期
黄渝晴, 刘晓梅, 高美娜
(上海第二工业大学a. 计算机与信息工程学院;b. 数理与统计学院,上海 201209)
0 引言
自邓聚龙教授1982 年提出灰色系统理论以来,灰色预测模型因其建模过程简单、所需样本少等优点,已经成功地应用于工业、农业、科技、军事等众多领域[1-2]。GM(1,1) 模型是灰色预测模型的经典形式,但学者们发现即使原始数据完全符合齐次指数规律,GM(1,1)模型也不能完全拟合原始序列,进而提出了无偏GM(1,1)模型的概念[3],并通过采用参数修正、调整灰导数和背景值等方法实现了无偏GM(1,1) 模型的构建[4-7], 使模型满足协调性条件,实现从差分到微分的统一, 提高模型的拟合精度。随后学者们对模型结构较简单的NGM(1,1,k) 模型[8-9]、Verhulst 模型[10-13]、灰色Bernoulli 模型[14]进行了无偏性研究,提高了模型拟合精度,拓展了适用范围。
但随着各类系统不断涌现出新特性、新问题,多种复杂的灰色模型被提出, 譬如: 灰色Riccati 模型[15-17]、分数阶灰色模型[18-20]、时间幂次项灰色模型(GM(1,1,tα))[21-25]、时间项灰色模型等, 其中从灰作用量出发所构建的含多项式时间项灰色模型[26-28]具有一定的普适性, 极大地拓展了灰色模型的应用范围, 可以用于拟合齐次、非齐次指数或者振荡性数据。学者们在此基础上也对原始序列采用分数阶累加算子、对模型采用分数次幂时间项等方面进行改进[29-30],进一步提升了含时间项灰色模型的普适性。在含多项式时间项灰色模型中, 模型NGM(1,1,k)是最简单的,因其模型结构简单,易于构建无偏模型,但对于一般的含多项式时间项模型(也包括时间幂次项GM(1,1,tα)模型),因其白化方程离散时间响应函数的递推公式难以从时间响应函数表达式推出,所以难以通过建立与参数估计递推公式的等价关系来获得无偏参数估计,因此,含时间项无偏灰色模型的研究也比较少。
本文以二次多项式时间项为例提出了含时间项无偏灰色模型的直接建模法。首先引入新变量, 借助于矩阵微分方程的解直接建立了白化方程离散时间响应函数的递推关系,并与参数估计递推关系建立等价关系,获得了模型的无偏参数估计,构建了含二次多项式时间项的无偏灰色模型,并证明了此模型具有严格含线性时间项的非齐次指数序列重合性; 其次,在无需给出白化方程解析解的条件下,根据精细积分法直接进行模型的模拟(预测), 其计算结果可达到计算机精度,并运用最优化理论探讨了模型基值修正;最后,以严格含线性多项式时间项非齐次指数序列和能源消费量2 个实例,验证了本文模型的有效性和实用性。
1 含二次多项式时间项无偏灰色模型构建
定义1设原始序列为
其1-AGO 序列为
式中:x(1)(k) =(z(1)(2),···,z(1)(n) 为X(1)的紧邻均值生成序列;z(1)(k)=(x(1)(k)+x(1)(k −1))/2,k=2,3,···,n。
定义2称x(0)(k)+az(1)(k)=b0+b1k+b2k2为含二次多项式时间项灰色模型(GMP(1,1,t2))的基本形式。称
为GMP(1,1,t2)模型的白化微分方程。a反映了序列的发展态势(本文只研究a ̸= 0 的情况),b0为灰作用量,b1,b2为时间修正项。
特别地,当b1=0,b2=0 时,GMP(1,1,t2)模型退化为GM(1,1) 模型; 当b2= 0 时, GMP(1,1,t2)模型退化为NGM(1,1,k) 模型; 当b1= 0 时,GMP(1,1,t2) 模型退化为含时间幂次项模型GM(1,1,t2)。
1.1 无偏GMP(1,1,t2)模型参数辨识
为了获得无偏GMP(1,1,t2) 模型的参数估计,需首先构造递推关系,令
则GMP(1,1,t2)模型的白化微分方程(1)转变为
式中,A=。
根据微分方程解的理论可知式(2)的解析解在t=k时的表达式为:y(k) = eA(k−1)y(1), 且易得y(k)=eAy(k −1)。
定理1白化方程(1) 离散时间响应函数的递推关系为
其中:
证明记由矩阵的运算可知
将其代入eA的Taylor 展开式,可得
又因D2=Dn= 0,n≥3,则上式化简后可得
其中,u1、u2、u3、u4如定理1 中所给。并将其代入y(k)=eAy(k −1)可得
从式(3)可以看出,后面3 个等式是恒成立的,所以式(3)转化为
即得结论,证毕。
利用最小二乘法, 可知u= (u1,u2,u3,u4), 参数估计的法方程组为
将其记为
定理2Bu=Y中参数的最小二乘估计为
以下根据直接建模法, 利用定理1 获得无偏GMP(1,1,t2)模型a、b0、b1、b2的参数估计。
定理3无偏GMP(1,1,t2)模型的参数估计为其中
1.2 无偏GMP(1,1,t2)模型的预测
通常灰色模型参数识别后, 直接代入白化方程的解析解进行模拟和预测,但当时间项幂次比较高时,解析解的表达式是非常繁琐的,不利于求解,并且由于计算机字长的限制,可能会进一步引入舍入误差。本文引入了精细积分法, 在无需求出其解析解的前提下,只需要根据估计的模型参数即可求出其数值解,并且解的精度可以达到计算机精度。精细积分法是钟万勰院士等[31]针对齐次微分方程所提出的,其核心是精细计算其微分方程通解中的传递矩阵Mτ=exp(Aτ),τ为步长。具体为:将步长切分为2N份,N为正整数(称为精细参数),则传递矩阵Mτ可写为
当2N很大时,exp(Aτ/2N)=E+A·τ/2N,其中E为单位矩阵,记S=A·τ/2N,则传递矩阵Mτ就可写为
而(E+S)(E+S) =E+2S+S2,因为S很小,当它与单位矩阵相加时就成为其尾数,在计算机舍入操作中其精度将丧失殆尽,故采用如下程序降低舍入误差(先将小量相加,再与单位矩阵相加)。
使数值解的精度基本上可以达到计算机精度。精细积分法中虽然步长变小了,但传递矩阵Mτ只需生成一次就可终身使用,计算量并没有增大,是一种高精度的计算方法。
定理4序列X(0)、X(1)和无偏GMP(1,1,t2)模型中参数a、b0、b1、b2估计值如定理3 所述,取x(1)(1) =X(0)(1),y(1)(1) = (x(1)(1),1,1,1), 则序列ˆy的递推公式为
式中,k=2,3,···,n。
本文利用直接建模法建立参数a、b0、b1、b2的无偏估计,根据精细积分法给出(1)(k)的预测, 称此模型为基于精细积分法的无偏GMP(1,1,t2)灰色模型(简记:HUGMP(1,1,t2))。
2 无偏GMP(1,1,t2)模型的性质
引理1GMP(1,1,t2)模型的离散时间响应函数为
定理5若原始数据序列严格服从含线性时间项的非齐次指数规律
式中:k= 1,2,···,n;q ̸= 0;c1,c2,c3为任意常数,则无偏GMP(1,1,t2)模型能够完全拟合此非齐次指数规律。
证明根据原始序列x(0)(k)可得
与式(3)进行比较,可得
再根据定理3 可知
利用引理1 可得
将此代入式(6),可得
与(0)(k)相同,故此模型具有含线性时间项的非齐次指数规律。证毕。
定理6设非负序列G(0)为X(0)的数乘变换序列, 且g(0)(k) =ρx(0)(k),ρ为非负常数。对非负序列X(0)={x(0)(1),x(0)(2),···,x(0)(n)}和G(0)={ρx(0)(1),ρx(0)(2),···,ρx(0)(n)}分别建立无偏GMP(1,1,t2)模型,记,0,1,2和,0,1,2分别为序列X(0)和G(0)的模型参数估计值, 则=0,1,2。
证明记X(0)的各参数如定理2 所示,=,不妨设BTB的伴随矩阵为
故
记G(0)的各参数也如定理2 所示,则
定理7设非负序列G(0)为X(0)的数乘变换序列, 其中g(0)(k) =ρx(0)(k),ρ为非负常数。记和分别为序列X(0)和G(0)的无偏GMP(1,1,t2)模型的模拟值(预测值),则
证明根据引理1 和定义1 可知,
故还原的模拟值为
其中,k=2,3,···,n。证毕。
定理6 和定理7 称为无偏GMP(1,1,t2)模型伸缩变换一致性定理,故对原始序列进行数乘变换不影响模型模拟和预测值的相对误差。因此, 在原始序列数量级较大时可以预先进行必要的数乘变换,以有效解决模型的病态问题。
3 模型的迭代基值优化
通常考虑给迭代初值增加一个修正项以尽可能消除迭代初始值对模型拟合值的影响,反向抵消初始值带来的偏差。选择迭代基值在HUGMP(1,1,t2) 模型基础上加上基值修正项ε,即利用式(5)计算再取第1 个分量结果作为,进而构建了1 个无约束的优化模型
由此优化模型可以看出,P为关于ε的二次多项式, 且ε2项系数为正实数。故由极值的必要条件(dP/dε= 0) 得ε值, 再由极值第二充分条件(d2P/dε2>0)知函数P的最小值点为ε。
基于迭代基值优化的HUGMP(1,1,t2) 模型的具体计算步骤如下:
Step 1 识别参数,根据式(4)利用最小二乘法获得参数的估计值
Step 3 迭代基值优化, 根据精细积分法, 利用式(5)求, 进而获得并根据式(7)求出HUGMP(1,1,t2)模型的迭代基值修正项ε;
Step 4 模拟预测, 在优化初始值的基础上,求出(1)(k+1), 并根据式(6) 还原原有序列数值(0)(k)。
4 算例分析
4.1 HUGMP(1,1,t2)模型无偏性验证
为了验证HUGMP(1,1,t2)模型的无偏性,下面将从严格含线性时间项的非齐次指数序列和不同指数的含线性时间项非齐次指数序列2 个方面来验证本文模型的无偏性。
例1取序列x(0)(k) = 2k+ 3k+ 5,k=1,2,···,6, 构建HUGMP(1,1,t2) 模型。图1 给出了取不同精细参数N时基于迭代基值优化的HUGMP(1,1,t2) 模型的平均绝对百分比误差MAPE (mean absolute percentage error, MAPE =· 100%) 结果, 纵坐标为MAPE 的对数值, 即log10MAPE。从图1 中可以看出,随着精细参数N的增加, MAPE 逐渐稳定在10−13,说明所设计的算法能够严格拟合非齐次指数序列,也验证了此模型的无偏性。
根据图1 可知,精细参数N=40 时模拟精度最高,N≥45 时模拟精度趋于稳定,故表1 列举了无偏GMP(1,1,t2)在不同精细参数(N= 40,45)、不同模拟方法(直接代入解析解或采用精细积分法)、是否采用迭代基值优化的各种情况下的模拟精度。可以看出,当选取合适的精细参数N时, 基于精细积分法的无偏GMP(1,1,t2)模型的模拟精度要优于采用解析解获得的模拟精度。由于计算机舍入误差的存在,对此严格序列采用迭代基值优化的方法基本上与未采用的结果相差无几,但均优于采用解析解模拟的无偏GMP(1,1,t2)模型, 说明本文所设计算法的有效性。

表1 严格含线性时间项非齐次指数序列拟合精度Tab.1 The fitted precisions of rigorous nonhomogeneous exponential series with linear time terms
例2取x(0)(k)=3qk+5k+8,k=1,2,···,6。分别设q= 0.5,3,6,9,12, 所得原始序列如表2 所示(表中数据通过四舍五入保留小数点后四位), 采用HUGMP(1,1,t2) 建模(取精细参数N= 40), 计算得到各序列的参数和拟合情况如表3 所示。从表3 中可以看出, 除去由计算机数据处理精度造成的误差,参数c1,c2,c3的拟合精度都比较高,其中对q的拟合最好,序列拟合精度高;当序列增长比较平缓时,模拟的精度相对较差,MAPE 为2.869E−007,而q= 3 时,模拟精度最好,MAPE 为8.317E−013。通过对多个非齐次指数序列的计算,再一次证明了所提出的模型具有无偏性。
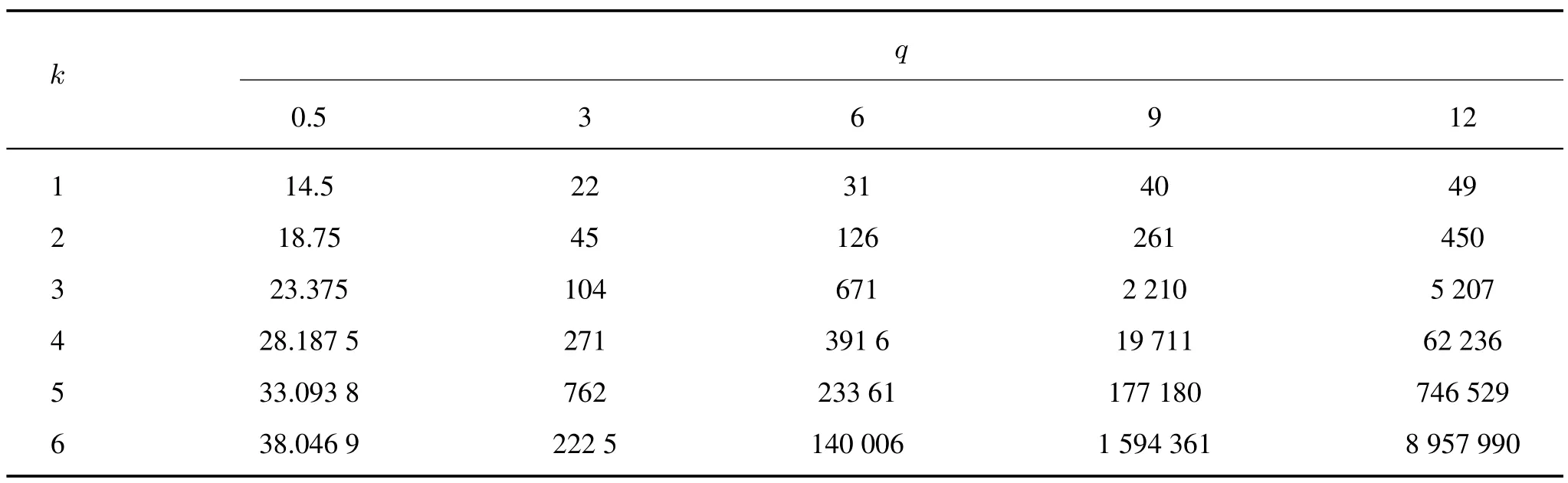
表2 多个含时间项非齐次指数序列数据Tab.2 Nonhomogeneous exponential series in different time terms
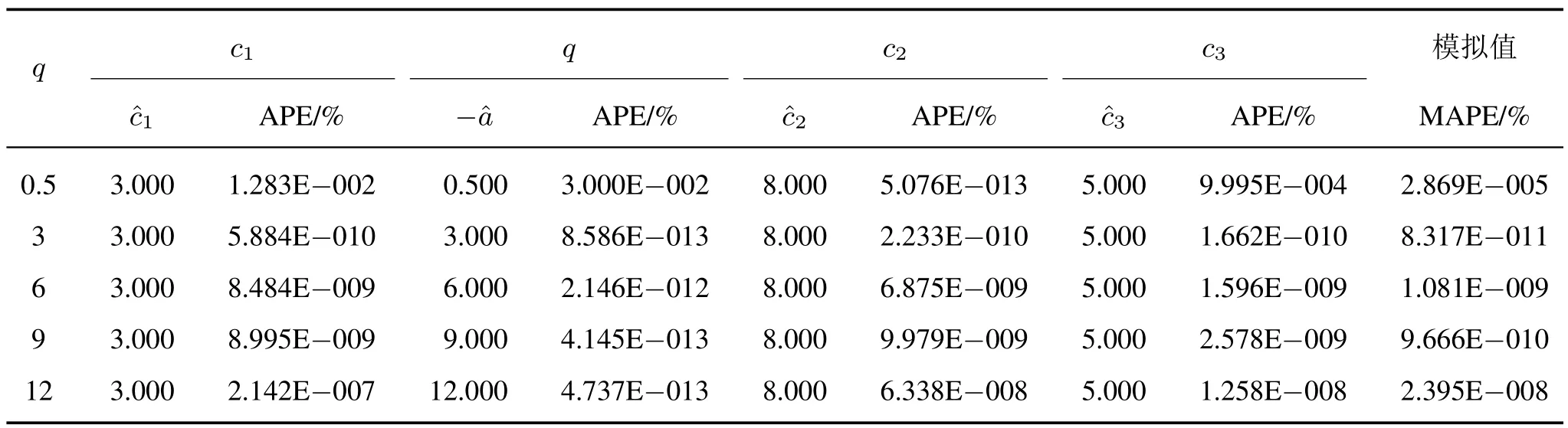
表3 多个指数序列的HUGMP(1,1,t2)模型参数及误差Tab.3 The parameters estimations and their errors of HUGMP(1,1,t2)model for different exponential series
4.2 实例分析
例3选取2005—2016 年上海市能源消费量(单位: 万t 标准煤) 为模拟数据, 2017—2019 年上海市能源消费量为预测数据, 构建GM(1,1) 模型、无偏NGM(1,1,k)模型、GMP(1,1,t2)模型以及HUGMP(1,1,t2)模型。
GM(1,1)模型:
其时间响应方程为
无偏NGM(1,1,k)模型:
其时间响应方程为
GMP(1,1,t2)模型:
其时间响应方程为
优化HUGMP(1,1,t2)模型:
各模型拟合(预测) 值和相对百分比误差(APE%) 结果见表4, 从表中可以看出, 随着时间项幂次的增大,模型的拟合和预测精度逐步提高,平均拟合误差MAPE_sim 从GM(1,1)模型(含零次多项式时间项) 2.38% 降至无偏NGM(1,1,k) 模型(含一次多项式时间项)0.89%、GMP(1,1,t2)模型(含二次多项式时间项) 0.80%, 平均预测误差MAPE_pre也从4.22% 降至1.60%。并且本文所提出的HUGMP(1,1,t2) 模型无论是拟合误差还是预测误差均低于传统的GMP(1,1,t2)模型,提高了拟合(预测)精度,同时也表明了所构建无偏模型的有效性。

表4 各种模型拟合(预测)结果对比Tab.4 Comparisons of the fitted and predicted results with different methods
例4选取《2019BP 世界能源统计年鉴》中2001—2018 年石油消费量进行建模,其中2001—2015 作拟合, 2016—2018 年作预测分析。分别采用GM(1,1)、NGM(1,1,k)、Verhulst、ARMA(1,1)、GRM(灰色Riccati 模型)[17]、HUGMP(1,1,t2) 建模。由表5 和图2 可见, NGM(1,1,k)、Verhulst 2 个模型的结果偏离实际值比较大, 拟合(预测) 效果差, ARMA(1,1) 的模拟结果有振荡性,拟合能力不好, GM(1,1) 模型的预测能力较弱。GRM、HUGMP(1,1,t2)模型的模拟(预测)值与实际值基本重合。进一步从表6 和图3 中可以看出,GM(1,1)模型、NGM(1,1,k)、Verhulst、ARMA(1,1)、GRM 的最大APE 为10.2829%、54.3376%、75.2261%、9.6100%、7.0255%, 而本文模型的最大APE 为6.5917%。本文模型的MAPE 为1.8343%,低于其他模型的3.6436%、11.9337%、34.9516%、3.8968%、2.0580%。综合来看,ARMA(1,1)、GRM、HUGMP(1,1,t2)能很好地拟合石油消费量的趋势,并且HUGMP(1,1,t2)是最好的模型。
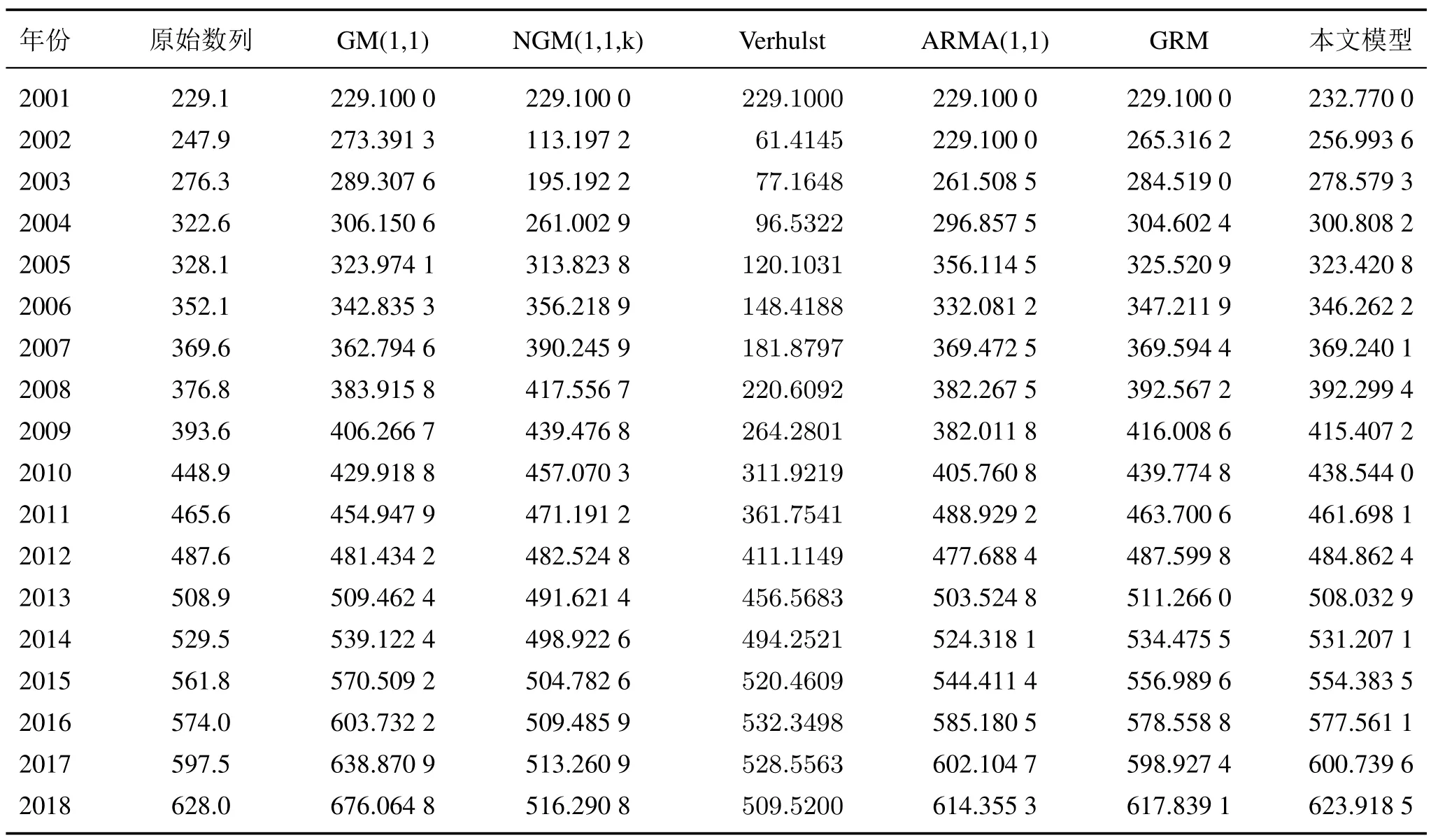
表5 原油消费各模型的拟合值和预测值Tab.5 The fitted and predicted values of different models in oil consumption

表6 原油消费各模型拟合和预测误差Tab.6 The fitted and predicted errors of different models in oil consumption

图2 各模型拟合(预测)值与实际值对比Fig.2 Comparisons of the fitted and predicted values of different models with actual values
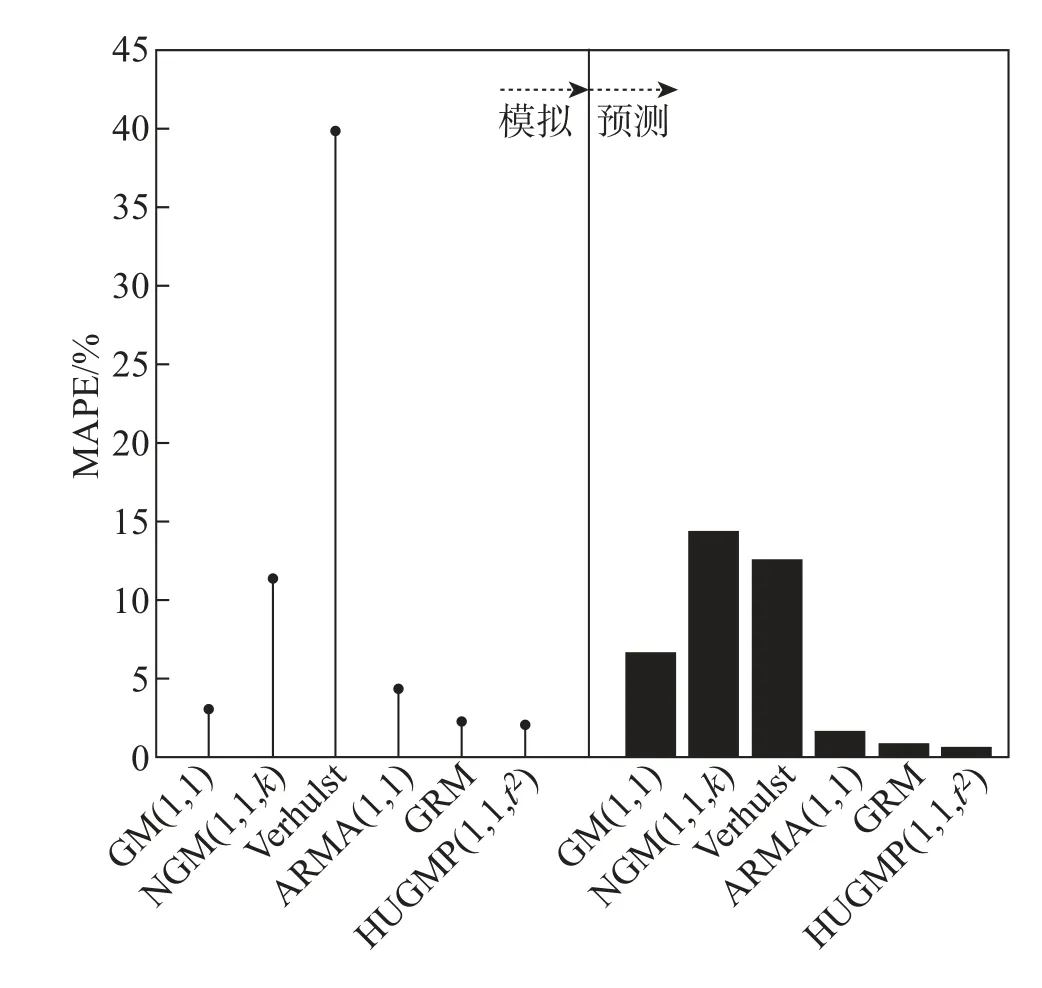
图3 各模型拟合(预测)误差Fig.3 The fitted and predicted errors of different model
5 结论
本文对含二次多项式时间项的灰色模型进行了研究, 提出了基于精细积分法的无偏灰色模型HUGMP(1,1,t2), 对该模型的建模机理和实际应用进行了研究,具体结论如下:
(1) 无需已知白化方程解析解的前提下, 给出了无偏GMP(1,1,t2)模型的参数估计,构建了无偏GMP(1,1,t2) 模型, 证明了此模型具有含线性时间项非齐次指数序列的重合性以及具有伸缩变换的一致性,具有较好的模拟和预测能力;
(2) 无需已知白化方程解析解的前提下, 采用精细积分法给出GMP(1,1,t2) 模型的模拟(预测)值,建立了基于精细积分法的无偏GMP(1,1,t2)模型, 即HUGMP(1,1,t2) 模型, 并利用最优化理论及Matlab 编程对模型HUGMP(1,1,t2) 的迭代基值进行了优化;
(3) 从严格含线性时间项非齐次指数序列和能源消费量两个实例中可以看出, 所构建的HUGMP(1,1,t2) 模型能严格模拟含线性时间项非齐次指数序列, 验证了此模型的无偏性, 且HUGMP(1,1,t2) 模型在模拟和预测精度优于传统的GM(1,1) 模型, 也优于许多灰色预测模型NGM(1,1,k)、Verhulst 模型、GRM 模型等), 其模拟和预测结果都得到了明显提高。
猜你喜欢
机械工程材料(2022年2期)2022-03-02
电焊机(2021年6期)2021-09-10
小学生学习指导(低年级)(2020年3期)2020-06-02
课程教育研究·新教师教学(2015年12期)2017-09-27
Coco薇(2017年2期)2017-04-25
Coco薇(2017年2期)2017-04-25
为了孩子(3~7岁)(2016年8期)2016-05-14
基层建设(2015年8期)2015-10-21
电气电子教学学报(2015年5期)2015-08-23
振动工程学报(2015年2期)2015-03-01
