
机器学习方法的云数据中心能耗模型研究
2023-09-06 04:29卢洪明刘先锋
小型微型计算机系统 2023年9期
卢洪明,刘先锋,周 舟,梁 赛
1(湖南师范大学 信息科学与工程学院,长沙 410081)
2(长沙学院 计算机工程与应用数学学院,长沙 410022)
1 背景介绍
近年来,大数据、人工智能、云计算等新兴技术发展迅猛,数据中心作为支撑这些技术的基础设施,数量和规模都得到了空前的发展.Synergy Research发布的数据显示[1],到2020年底,全球大型数据中心总数已增至597个,达到了2015年的两倍.数据中心数量迅速增长带来了两方面问题:1)数据中心的运营能耗日益庞大.统计结果表明[2],2020年,我国数据中心的总耗电量为2000亿千瓦时,已超过社会总用电量的2%.预计到2025年,占比将增加一倍,达到4.05%;2)社会的环保压力日益沉重;报告显示,在2019年全球数据中心的碳排放量约占碳排放总量的2%,相当于全球航空业的碳排放量[3].数据中心在能耗消耗巨大的同时资源利用率却极低,相关数据显示[4],目前数据中心的资源利用率通常在5%-25%之间[5],造成了资源的浪费.数据中心能耗组成主要包括服务器、制冷系统、照明设备以及一些其他能耗设备,其中数据中心能耗的50%以上来自服务器能耗,并且其它组件的能耗也与服务器能耗相关,数据中心由成百上千台服务器构成,因此针对单台服务器能耗的研究就可以优化整个数据中心的能耗.为了提高资源利用率和降低数据中心服务器的能耗,节能优化算法被广泛使用,能耗预测模型作为节能优化算法的基础,对优化算法的好坏至关重要,精确的能耗预测模型也有利于优化算法的建立.
本文旨在设计一个高精度的服务器能耗预测模型.为此,本文提出了一种基于支持向量机[6]与随机森林特征选择的服务器能耗模型[7].与现有方法相比,本文提出的能耗模型能够有效地预测在服务器上执行的不同类型负载任务的能耗,且精度更高.本文中贡献主要如下:
1)设计了能耗建模流程,包括数据采样、特征抽取、特征选择、模型建立和训练、模型评估与分析.
2)本文使用随机森林算法进行特征选择,分别选择了27个(CPU密集型任务)、26个(I/O密集型任务)、26个(WEB事务型任务)与能耗相关的特征建立和训练模型.
3)本文通过大量实验验证了该算法在CPU密集型任务、I/O密集型任务和Web事务型任务上的表现,即分别在所提出的模型上进行训练,并在测试数据集上对其进行全面评估.实验结果显示,本文所提出能耗模型的预测能力比其他基准模型更准确.
2 相关研究
建立一个准确的服务器能耗模型可以有效的降低数据中心能耗,精确的能耗预测模型不仅是优化算法的基础,而且还直接影响到能耗感知优化的结果[8].目前国内外学者对能耗模型的研究可分为两类:一类是基于系统资源利用率的能耗模型,另一类是基于性能计数器的能耗模型.
在基于系统资源利用率的能耗模型中[9-12],利用系统主要组件的利用率来进行能耗建模,如通过服务器的中央处理器(CPU)、内存和磁盘等建立资源利用率与系统能耗之间的函数关系来建立能耗模型,这种方法具有简单直接、计算开销小、可移植性高等特点.文献[9]结合多元线性回归、逐步回归、非线性回归等多种回归方法,总结分析不同参数对能耗模型的影响,结果表明采用多项式的非线性模型预测精度更好.在文献[10]中,作者基于回归方法和系统资源的利用率,提出了多种服务器能耗模型,并充分考虑了不同负载任务类型,即CPU密集型任务、I/O密集型任务和Web事务型任务对能耗的影响.文献[11]在线性能耗模型的基础上提出了一种改进的能耗模型(Cubic Model),该模型认为服务器的能耗与处理器不应是简单的线性关系,而是立方关系.在文献[12]中,作者讨论了在处理器、内存、磁盘和其他主要组件中提取参数的能耗模型,这种方法的优点是简单,只需收集几个关键参数即可创建能耗模型.然而,该能耗模型对不同载荷波动变化的适应性较差,精度也较低,不适应实际负载的使用情况.
随着虚拟化技术的发展和工作负载的变化,建立一个纯基于系统资源利用的能耗模型并不十分准确.近年来,很多的学者也开始关注基于PMC的能耗建模方法[13-19].这种建模方法的主要内容是根据PMC与各设备能耗的关系,针对不同设备(包括处理器、内存、磁盘、I/O等外部设备)选择最具代表性的“PMC集合”,然后,通过统计分析,建立PMC集合与设备功耗之间的函数关系,这种关系可以是线性的,也可以是非线性的,再根据确定的关系建立能耗模型,最后对建立的模型进行评估和验证.具体来说,根据回归技术的差异,文献[13]将比较分析了线性模型和非线性模型,实验比较结果显示,非线性模型的预测精度更好,但计算开销较大.文献[14]提出了一个功耗模型,该模型将服务器的功耗表示为CPU、内存、磁盘和网卡的总和.文献[15]通过分析服务器各组件的参数后选取了合适的参数建立CMP模型,实验结果表明,CMP模型的预测精度要优于传统的FAN模型和Cubic模型.文献[16]提出了一种基于细粒度性能计数器建立能耗模型的方法,该模型选取了多达200个能代表系统运行状态的特征,再用多元线性回归对该模型进行求解,该方法建立的功耗模型在3个不同平台上实验结果的最大误差均小于4%,且针对每个平台使用3组不同的采样数据组合进行模型求解,得到的有效特征集合完全一致,证明了模型的稳定性.除了这些传统的数学模型外,近年来越来越多的研究者尝试将机器学习技术[17]应用到数据中心的能耗研究中,文献[18]提出了一种基于特征选择和深度学习的能耗模型FSDL,该模型结合特征选择与深度学习的方法,得到的能耗模型预测精度优化传统模型,但是该模型易产生过拟合的情况.在文献[19]中,作者分别基于BP神经网络、LSTM神经网络和Elman神经网络建立了TW_BP_PM、MLSTM-PM、ENN-PM 3种功耗模型,并且比较了3种功耗模型在不同的任务负载下的预测精度,最后在综合考虑预测精度与训练开销的情况下,ENN-PM优于TW_BP_PM和MLSTM-PM.
3 基于SVM的RGS能耗模型
3.1 能耗建模的基本流程
图1介绍了服务器能耗建模的基本流程.它包括5个步骤:数据采样、特征提取、特征选择、模型建立和训练、模型评估和分析.数据采样步骤是从服务器采集负载特征参数和能耗相关数据.特征抽取步骤是筛选与能耗相关的特征,而特征选择步骤用于选择一个子集相关特征.模型构建和训练是开发能耗型的必要步骤.本文对服务器构建能耗模型并进行训练,训练完成后进行模型性能评估以验证模型的稳健性和有效性,最后,将此能耗模型与其他能耗模型在不同类型的负载任务上比较,验证模型的可行性.在以下小节中,本文将介绍这些步骤的详细信息.

图1 能耗建模流程图Fig.1 Flow chart of energy consumption modeling
3.2 数据采样
数据采样是建立精确能耗模型的前提.图2展示了本文的数据采样过程.主要包括电源、智能电表、被测服务器和记录设备.在图2中,智能电表分别连接电源和被测试服务器.

图2 数据采样图Fig.2 Data sampling diagram
智能电表的主要功能是获取测试服务器的能耗数据,并通过记录设备保存数据,同时记录设备也收集服务器负载特征数据.一般来说,数据采样可以使用两种方法.第一种方法基于系统资源利率,另一种方法基于PMC方法.为了及时获取服务器的工作状态并收集实验数据,对服务器的性能指标进行监控和管理具有十分重要的意义,常用的监控软件有Ganglia、Zabbix、Nagios等.Ganglia是一个可扩展分布式监控系统,主要用于收集系统级信息,包括CPU使用情况、磁盘使用情况等;Zabbix是一款可对网络、操作系统和应用程序进行监控的开源工具,它可以监控诸如CPU负载、网络使用情况、磁盘空间等统计信息,但是它会导致过多的系统开销;Nagios是一个开源监控程序.考虑到服务器中一个单独性能监控工具的局限性和缺陷,如何设计一个综合解决方案,在系统开销和监控指标的范围之间取得平衡尤为重要,为此,本文提出了一个由Ganglia和Zabbix 组成的联合监控方法.这些组件的主要优点如下:Ganglia可以实时监视集群的基本性能指标,系统开销低,对相关服务的性能没有影响;Zabbix支持二次定制开发,以监视各种所需的性能参数.这种综合监测方法有效地融合了各自的优势,不仅共同监测更多样化的能源相关指标,还确保了较低的总体系统开销.
在数据采样过程中,每隔5s采样一次,并同步采样服务器的负载相关数据,采样完成后对采样数据进行统计和处理,使样本数据满足方差齐性、正态分布和独立性的要求.同时为了更好的训练模型,对收集到的原始数据进行Min-Max标准方法将其归一化在[0,1]区间,具体公式如下所示:
(1)
式(1)中,变量x′表示标准化后的值,变量x表示原始数据,变量xmin表示样本中最小值,变量xmax表示样本中最大值.
3.3 特征抽取
特征抽取负责筛选与能耗建模相关的特征.例如,“CPU idle time”功能表示中央处理器空闲时间的百分比,“Page faults/sec”功能表示进程中执行线程导致的页面错误率,“Disk Time”功能表示磁盘用于输入/输出操作上花费的时间百分比.通过在服务器部署Ganglia和Zabbix软件获取所有特征参数.特征提取完成后,本文需要选择一个合适的特征子集.
选择合适的特征是建立精确能耗模型的必要步骤.在本文中,总共采集29个特征参数来建立能耗模型.表1描述了论文中使用的特征参数.本文使用“Ganglia”和“Zabbix”软件收集了所有这些参数.根据负载的不同,任务分为CPU密集型、I/O密集型和WEB事务型.这些任务类型的示例见表4.例如,“SPEC CPU2006”基准是评估计算机在真实应用中计算性能的有效工具,通常被认为是CPU密集型任务的代表.同样,“Iozone”是I/O密集型的代表.
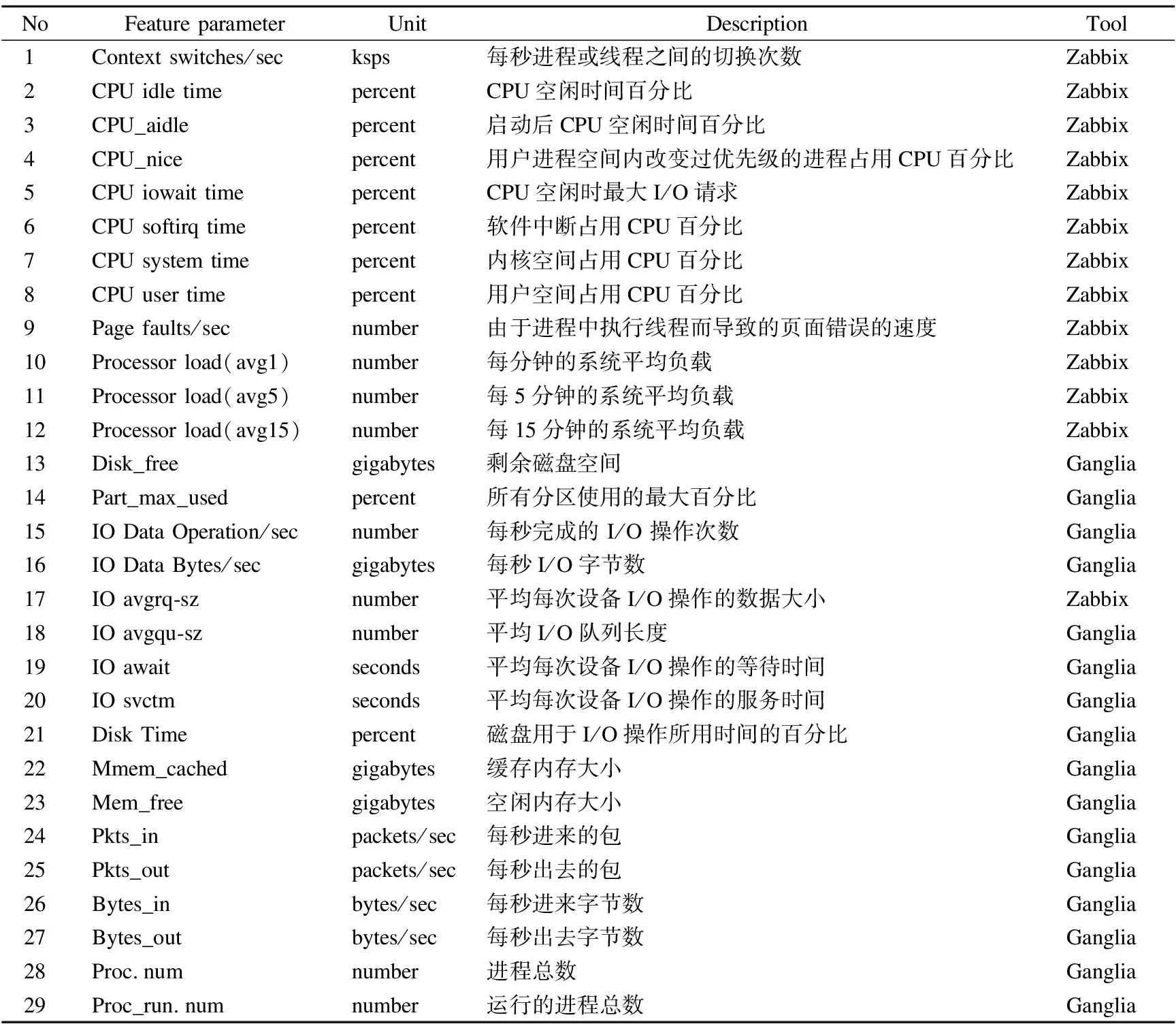
表1 特征参数Table 1 Characteristic parameters
3.4 特征选择
随机森林(Random Forest,简称RF)算法[20]是利用决策树对样本进行分类、训练并预测的一种算法,在对数据进行分类时,还能计算各特征的重要性,具有准确性高、训练速度快等优点.考虑到RF算法的优点,本文将其用于“能耗参数”的筛选.RF算法的示意图如图3所示.随机森林计算特征重要性的步骤如下:

图3 RF算法Fig.3 RF algorithm
a)对于每一颗决策树,选择对应的袋外数据统计计算结果与实际值之间的误差,记为error1.
b)对每一个特征,随机的加入噪声,再次计算相应的误差,记为error2.
c)假设森林中有N棵树,则特征X的重要性=
∑(error2-error1)/N
(2)
d)最后筛选出重要性高的特征作为新的数据集.
经过RF算法后得到了各特征的重要性量比如表2所示,当重要性量比低于1%时,可认为这个特征对服务器能耗的贡献可以忽略,所以本文以1%为选取的分界限,分别对CPU密集型数据取27个特征,I/O密集型数据取26个特征,WEB事务型数据取26个特征.

表2 特征重要性量比Table 2 Feature importance ratio
3.5 RGS能耗模型
服务器能耗因受到调度策略和资源利用率等诸多因素的影响,具有非线性和不确定性等特点,普通的线性模型很难反映其变化规律,在机器学习算法中,SVM(Support Vector Machines)算法能较好的解决非线性问题,因此,本文采用SVM算法来建立能耗模型.目前,大部分能耗模型的研究仅给出了能耗预测值,无法较好的描述服务器能耗的不确定性,本文引入了一种使用误差置信区间来描述能耗不确定性的方法.所以本文采用随机森林特征选择与网格搜索优化后的SVM模型建立能耗模型(记为RGS).
3.5.1 SVM算法
支持向量机(Support Vector Machines,简称SVM)是一类使用监督学习对数据进行二分类的机器学习方法,同时,它也常用于处理回归问题.在处理回归问题时,SVM算法会根据训练样本的数据逼近回归函数,回归函数如下:
f(x)=〈w,g(x)〉+b
(3)
式(3)中:w表示权值向量;x表示输入向量;g(x)表示映射函数;b为常数.
求解下面的二次规划问题可以确定w和b[21]:
(4)
(5)

使用隐式的核函数g(x),将非线性问题映射到高维空间,从而在高维空间进行运算,可以解决非线性问题.为解决数据中心能耗于特征参数间的非线性关联,本文选择RBF(径向基函数)为核函数,这是因为RBF处理非线性问题优于其它核函数,且所需参数较少,RBF公式如下:
(6)

C、ε及γ被称为模型超参数,不断调节这些超参数可以优化模型性能.
3.5.2 网格搜索法
网格搜索法(Grid Search,简称GS)是穷举搜索法的一种,即将模型超参数通过交叉验证进行优化来获得最优参数组合的学习算法.目前常用的调参方法有传统手工搜索法、随机搜索法、贝叶斯搜索法、网格搜索法等.其中传统手工搜索法耗时较长,随机搜索法往往难以得到最优的参数,贝叶斯搜索法需要较多的样本空间,而网格搜索法在搜索足够的广度的同时,计算开销较小.因此,本文在综合考虑其他算法优缺点后采用“网格搜索法”来调节模型超参数.GS方法的基本原理是将各个参数的取值进行排列组合,列出所有可能取值形成网格,然后将各种可能取值用于SVM模型训练.
4 实验与结果分析
为了在真实环境中实验,本文使用了一台服务器进行试验,得到经过预处理的数据后,再使用这些数据在另一台电脑上进行训练和评估模型,实验环境详细配置见表3.本文选择了3种不同类型的负载任务,包括CPU密集型工作负载、I/O密集型工作负载、WEB事务型工作负载(见表4),共采集到CPU密集型、I/O密集型、WEB事务型数据各3000条.先将数据归一化处理后再将数据集按照80%、20%划分“训练集”和“测试集”,对训练集进行参数搜索和建模,对测试集进行结果预测以检验模型性能.本文使用机器学习库中的sklearn包来建立SVM能耗模型,该算法有默认的参数值C=1、γ=0.036及ε=0.1[22].本文在默认的参数值附近建立网格,网格的参数值如下:C∈{0.01,0.05,0.1,0.5,1,5,10,50,100}、γ∈{0.001,0.005,0.01,0.05.0.1,0.5,1,5,10}及ε∈{0.001,0.005,0.01,0.05.0.1,0.5,1,5,10},这些节点组成9×9×9的网格,再使用五折交叉验证法来评估模型性能,为了提升模型的整体拟合能力,选择R2作为优化指标.

表4 不同负载基准Table 4 Different load benchmarks
4.1 模型性能评价
本文的模型性能评价指标采用平均绝对百分比误差(MAPE)、均方根误差(RMSE)和决定系数(R2).其中,MAPE描述了误误差值的相对大小.RMSE反映了真实值与预测值的误差大小.R2的值越大模型性能越好.MAPE、RMSE、R2的计算公式如下:
(7)
(8)
(9)

4.2 SVM与Grid Search性能评估(1)
分别对CPU密集型、I/O密集型、WEB事务型的任务进行能耗建模后,会得到一个能耗预测模型,再将“训练集”和“测试集”带入模型中验证,用以检验模型的拟合能力和预测能力.为了评估模型性能,本文在相同实验环境下对默认参数的SVM(标记为RS)与使用GS优化参数后的SVM模型(标记为RGS)进行比较,结果如表5所示.在3种不同负载任务下,RGS的模型拟合性能及模型预测性能都比RS模型要好,说明使用GS方法后模型的性能得到了优化.同一个模型不同负载任务之间均有差异,WEB事务型任务的模型拟合性能及模型预测性能均优于CPU密集型任务和I/O密集型任务.从表5可以看出,RGS在不同类型的负载任务预测时,模型的超参数也不相同.在模型性能方面,RS的MAPE平均值为8.72%,R2的平均值为0.937.RGS的MAPE平均值为2.17%,R2的平均值为0.963,模型未解释方差比(1-R2)降低了41.3%,说明加入GS方法可以提升模型的性能.

表5 模型性能比较Table 5 Model performance comparison
4.3 SVM与Grid Search性能评估(2)-基于模型拟合的误差区间预测
图4显示了不同任务类型下的实时预测能耗和真实能耗.表6列出了RGS的预测误差,评价标准包括MAPE和RMSE.从表6的数据可以看出,对于CPU密集型的工作负载,MAPE是3.10%,RMSE是3.05.对于I/O密集型的数据,MAPE是1.79%,RMSE是1.18.对于WEB事务型数据,MAPE是1.43%,RMSE是2.19.

表6 模型预测误差Table 6 Model prediction error

图4 不同负载下能耗预测Fig.4 Energy consumption prediction under different types of workloads
在得到能耗模型预测后,为了描述服务器能耗的不确定性,本文采用了误差置信区间方法.将RGS模型拟合的误差e看作随机变量,使用置信度为(1-α)置信区间[eα/2,e1-α/2],eα/2、e1-α/2分别表示上、下分位点.将置信区间引入后,能耗预测值就可以用预测区间来表示.预测区间展示了在外界因素影响下服务器能耗值的波动界限.将得到的能耗预测误差值按时间排序,取α=0.1,分别取误差值位于序列95%和5%的值作为置信区间上下限,可以得到一个置信度为0.9的置信区间.能耗预测值加上对应时刻的误差上、下限后,形成能耗预测区间,如图5所示,若预测值位于预测区间内,可理解为误差为0,即能准确预测能耗.若预测值在预测区间外,则需要重新计算误差.本文同时也关注在整个预测过程中预测值在预测区间内的比例Pin.对于不同负载任务类型的能耗模型,分别统计MAPE和Pin,结果如表7所示,MAPE<1.4%,Pin>88%,可看出服务器能耗预测值基本都在预测区间内.使用区间预测方法能更好的反应服务器运行能耗预测,可以看出RGS模型在不同负载任务下的测试中预测性能均较优且差异小,可为服务器运行能耗预测及优化提供参考.

表7 模型预测区间误差Table 7 Model prediction interval error

图5 不同负载下能耗预测区间Fig.5 Energy consumption prediction interval under different types of workloads
4.4 与其它能耗模型对比
为了评估模型的准确性,本文在相同的实验环境(见表3)和标准数据集Benchmarks(见表4)上展开,在训练模型PC上分别用不同方法进行建模,得到预测能耗与实际能耗的误差后,再比较不同能耗模型的预测精度,将本文提出的RGS能耗模型与Cubic能耗模型[11]、CMP能耗模型[15]、FS-DL能耗模型[18]、ENN-PM能耗模型[19]、ECMS能耗模型[23]进行比较分析,结果如图6和图7所示,其表明,RGS能耗模型在3种不同负载任务下都具有最高预测精度,且与其他5种模型相比,MAPE平均降低了2.9%,RMSE平均降低了2.7.这是因为RGS能耗模型选择了更多的特征参数,使用了RF算法筛选特征,结合了网格搜索法和支持向量机进行建模,说明了本文所提出的能耗模型有效.

图6 各能耗模型的MAPEFig.6 MAPE of each energy consumption model

图7 各能耗模型的RMSEFig.7 RMSE of each energy consumption model
5 总 结
本文提出了一种基于机器学习方法的服务器实时能耗预测方法,用于解决云数据中心服务器的能耗难以预测的问题,实验结果表明其可有效预测云数据中心服务器能耗以及能耗变化趋势.本文所提出的能耗模型精度提升的原因可归结于:1)所提出的能耗模型考虑了任务的特征,针对不同负载类型的任务分别建模;2)使用了RF算法筛选能耗相关特征;3)使用GS方法优化SVM算法的超参数;4)使用能耗预测区间替换能耗预测值.
本文所提出的能耗模型可为云数据中心服务器能耗预测提供指导,同时该能耗模型也可以对节能优化算法的评估提供参考.本文提出的能耗模型未考虑“混合负载”情况,将在后续的研究中进一步探索和实验.
猜你喜欢
机械研究与应用(2022年4期)2022-09-15
昆钢科技(2022年2期)2022-07-08
当代水产(2021年10期)2022-01-12
中国民间疗法(2021年1期)2021-04-20
建材发展导向(2021年23期)2021-03-08
山东冶金(2019年3期)2019-07-10
华人时刊(2018年15期)2018-11-10
电子测试(2018年11期)2018-06-26
酒·饮料技术装备(2018年1期)2018-04-28
广州广播电视大学学报(2015年2期)2015-12-29
