
应用ResNet和CatBoost检测重放语声∗
2023-09-15 12:36孙晓川付景昌宋晓婷宗利芳李志刚
应用声学 2023年4期
孙晓川 付景昌 宋晓婷 宗利芳 李志刚
(1 华北理工大学人工智能学院 唐山 063210)
(2 河北省工业智能感知重点实验室 唐山 063210)
0 引言
近年来,随着语声技术的发展,越来越多的用户选择使用语声交互的手段进行人机交互。作为一种确认身份的语声交互方法,自动说话人确认(Automatic speaker verification,ASV)在现实生活中有着越来越广泛的应用[1]。ASV系统通过提取语声特征后计算相似度来确认说话人身份。针对ASV系统的特点,存在一些欺骗方法,例如人为模仿语声、重放语声、语声合成和语声转化[2]。其中,重放语声攻击易于实现,已被证明对ASV系统具有较大的危害性[3]。
重放语声检测的研究吸引了很多研究人员。Ji等[4]提出了一个使用多种声学特征和分类器的集成学习模型用以检测重放语声。Ahmed 等[5]提出了一种根据真实语声和重放语声之间的频谱功率差异来检测重放语声的方法。Wang 等[6]提出一种基于双对抗域适应框架重放语声检测方法。上述方法适应于检测句子级的语声,不适应于对声频时长短、内容信息少的词级语声检测。Zhang等[7]使用智能手机的传声器来监控用户声音的反射从而检测重放语声。Sahidullah 等[8]还提出了一种使用喉部传声器的重放语声检测方法。Chen等[9]提出了一种根据扬声器发出的磁场来进行重放语声的检测方法。上述方法需要额外的特定设备或者要求用户在使用时进行额外的动作,实用性较差。
气爆杂声(Pop noise,PN)是一种由于各种呼吸噪声被传声器捕捉,导致扬声器播放不必要的噪声的现象。包含PN的语声在低频具有较高的能量。通过窃听录制语声时,攻击者会将录声设备放置在距离用户较远的位置,这将导致重放语声中没有PN。因此,PN能区分真实语声和重放语声。此外,检测PN 要求的设备简单,利用智能设备内置传声器就足够。Sayaka 等[10]提出利用PN 进行重放语声检测。随后他们提出了多通道PN 检测方法和基于音素的PN 检测方法[11-12]。Wang 等[13]进一步应用包含PN 的语声帧的伽马通频率倒谱系数(Gammatone frequency cepstral coefficient,GFCC)进行重放语声检测。Jiang 等[14]提出了一种基于PN 的反欺诈ASV系统。上述研究都是使用各自构建的非公开数据集。在Interspeech2020上,为了促进PN在重放语声检测中的应用和研究,Akimoto等[15]提出了公开数据集POCO。在POCO 数据集上,研究人员做了一些工作。Gupta 等[16]提出基于低频短时傅里叶变换(Short time Fourier transform,STFT)和卷积神经网络(Convolutional neural networks,CNN)的重放语声检测模型。Khoria 等[17]研究了常数Q倒谱系数(ConstantQcepstral coefficients,CQCC)在不同的分类器下的检测效果。虽然上述研究取得了一些成果,但检测性能仍不理想,值得进一步探索。
近年来,深度学习已成为主流技术,在重放语声检测方面取得了一些成果。残差网络(Residual network,ResNet)由于能够解决神经网络的梯度消失问题得到广泛的使用。Chen等[18]研究了ResNet在高斯混合模型和深度神经网络上进行重放语声检测的有效性。Alzantot 等[19]提出了3 种ResNet变体,利用3 种声学特征来检测重放语声。Parasu等[20]提出了一种语谱图(Spectrogram,Spec)作为输入的轻型ResNet 架构,用于重放语声检测。然而,这些网络中的全连接层包含大量参数,因此在训练过程中容易出现过拟合。分类梯度提升算法(Categorical boosting,CatBoost)是一种基于集成学习的方法,通过在树的新拆分处使用贪心方法来解决特征组合的指数增长[21-22]。基于CatBoost的分类器可以有效降低全连接层造成的过拟合风险。受此启发,本文探索了ResNet-CatBoost 模型在重放语声检测中的可行性。
本文提出了一种基于ResNet和CatBoost的重放语声检测框架。该框架由特征提取、重放语声检测模型两个模块构成。本文主要贡献如下:(1) 受到PN 的启发,提出了一种新的语声帧选择方法。(2) 将ResNet 进行改进,激活函数改为LeakyReLU,减少残差块的数量,并加入了自我注意机制(Self-attention mechanism,SAM)。(3)提出了一个基于ResNet和CatBoost 的混合检测模型来进行重放语声检测。(4) 研究了不同的声学特征、词汇和性别、语声帧选择方式以及频率范围对重放语声检测效果的影响。(5) 研究了录制设备与说话人距离、重放设备质量对重放语声检测效果的影响。
1 特征提取
1.1 语声信号预处理
语声信号预处理,包括预加重、分帧与加窗3个步骤。预加重是为了提升语声信号中的高频部分,使信号的频谱变得平坦,便于进行频谱分析。预加重一般通过一个一阶预加重数字滤波器实现,公式如下:
其中,y(m)是预加重后的信号,x(m)是预加重前的信号,0.94 ≤α≤0.97。
分帧是将语声信号分割为帧的过程。在分帧过程采用帧叠加方法避免在每一帧的交点处丢失声频的特性。根据文献[3],帧长越大频域分辨能力越强,重放语声检测效果越好。本文采用100 ms 的帧长、50 ms的帧移进行分帧处理。为了抑制在分帧过程中发生的频谱泄露问题,采用汉明加窗方法。
1.2 语声数据帧选择
为了保证模型输入的数据长度一致,同时为提升检测的效果,受到文献[15]启发,本文提出了一种选择语声数据帧的方法。语声信号在预处理后,通过快速傅里叶变换得到频谱,公式如下:
其中,xi为语声帧,i指语声帧的序号;N为第i帧语声中采样点总数;k为第i帧语声中采样点序号。
经过快速傅里叶变换之后,得到了在一定频率范围内每帧的能量向量。用Ei定义在频率范围[0,fmax]内的低频平均能量(Low frequency average energy,LFAE),其中i是每个帧序号。根据文献[10],fmax应设置为低于预期频率,排除来自谐波内容的能量。实验中fmax取40 Hz。对i=1,2,··,L(L是语声帧数量),计算Ei。找出Ei中前10 个最大的元素,其帧序号i即代表选取的语声数据帧。最后,将选择的10 个语声帧按照语声帧序号由小到大进行排序。语声帧选择的流程如图1所示。

图1 语声帧选择流程Fig.1 Audio frame selection process
1.3 声学特征提取
本文研究了3种不同的声学特征梅尔频率倒谱数(Mel frequency cepstral coefficients,MFCC)、线性倒谱系数(Linear frequency cepstral coefficients,LFCC)、GFCC 在重放语声检测方面的效果。输入语声帧为1.2节中选择的语声帧。根据文献[10],3种特征均只使用中心频率范围为0∼40 Hz的滤波器。
2 重放语声检测模型
本文提出了一种结合了ResNet和CatBoost的重放语声检测模型。在结构上,ResNet 是特征提取器,它由一些残差块(Residual block,ResBlock)组成。图2 显示了整个ResNet 及其ResBlock 的结构。ResBlock 可以分为两个部分:直接映射部分h和残差部分F,每个ResBlock可以表示如下:

图2 ResNet 模型结构Fig.2 ResNet model structure
其中,xl和xl+1分别是第l个单元的输入和输出,f是激活函数。
与传统的ResNet 不同,本文使用的ResNet 使用了LeakyReLU激活函数。通过这种方式,可以尽可能多地保留特征信息。此外,采用PreActBlock来代替原来的ResBlock,其中BN 层和LeakyReLU层被放置在卷积层的前面。本文的初步实验工作表明,新的ResBlock可以有效地缓解潜在的数据过拟合问题。最后,并非所有的语声帧都提供相同的区分信息。例如,非语声帧和短暂停顿区分性小,而一些语声内容在重放语声检测中更具区分性。ResNet中使用自我注意力池化(Self-attentive pooling,SA Pooling)层可以使较高的权重被分配给特定帧以获得更好的特征表示。
ResNet 的结构参数如表1 所示。输入是大小为10×60 的声学特征矩阵。输入首先通过卷积层Conv1。Conv1 的输出通过6 个改进的PreAct-Block。最后一个PreActBlock的输出被送入输出卷积层Conv2,随后通过SA 池化层。来自SA 池化层的输出被提供给256 维的全连接(Fully connected,FC)层FC1,最后将FC2层的2维输出使用Softmax转换成概率。

表1 ResNet 模型参数Table 1 Parameters of ResNet model
CatBoost 算法是一种基于梯度提升决策树(Gradient boosting decision tree,GBDT)的算法,在结构上是分类器。通过采用排序提升(Ordered boosting)方法,CatBoost 解决了传统GBDT 算法的过拟合问题。
算法1 显示了ResNet+CatBoost 训练的伪代码。ResNet 模型首先被训练成一个特征提取器,将输入嵌入到合适的表征中,包括数据集划分和ResNet 训练(第1∼6 行)。训练完成后,从训练的ResNet 模型中去除最后一个全连接层FC2,将所有数据转换成256 维的特征向量,即分别用于训练、验证和测试的特征向量F1、F2和F3(第7∼16行)。基于这些特征,使用自动机器学习库FLAML可以得到最优的CatBoost 模型(第17∼18 行)[23]。最后,通过CatBoost 输出语声X是真实语声的概率p(bonafide|X)与重放语声的概率p(replay |X)(第19行)。求二者的对数似然比公式如下:
3 实验与分析
3.1 实验环境与数据
实验平台硬件配置:Intel(R) Core(TM) i7-8750H CPU@ 2.2 GHz;32 GB 2667 MHz 内存;RTX2070 Max-Q 独立显卡;64位Windows 操作系统。软件方面:Anaconda3为开发平台,深度学习开源框架Pytorch 和语声特征提取框架Spafe 为程序框架,Pycharm为软件环境。
为了验证本文方法的有效性,数据集选用公开数据集POCO(Pop Noise Corpus)[15]。因为数据集中0226_5 和0207_1 两个说话人部分录声数据丢失,本文选择完整录制的声频作为实验数据。实验数据由32 名女性和31 名男性录制,录制者的英语流利程度各不相同,口音也不同,年龄从18 岁到61岁不等。每个人重复3次录制了包含44个音素的声频。图3 表示数据集POCO 录制过程。本文用到的实验数据包含两种类型,分别是RC-A和RP-A。前者是用AT4040 传声器录制的高音质声频。该数据子集代表了具有PN 的真正的说话人。说话人距离传声器10 cm。RP-A 是用位于说话人和传声器之间的TASCAM TM-AG1型号过滤器过滤说话人声音后用AT4040 传声器录制的声频。该子数据集模拟了攻击者的窃听(eavesdropping)场景。在此场景中目标说话人的声音被较为完美录制并重放,录制的重放语声中中间设备和环境的卷积和加性失真信号较少。说话人距离传声器距离同样是10 cm。声频文件数量是16632 个,每个声频文件包含一个WAV格式的单词,采样率为22.05 kHz。训练集、验证集和测试集分别占总数据的80%、10%、10%,具体的划分如表2所示。

表2 POCO 数据集划分Table 2 Dataset partition for POCO
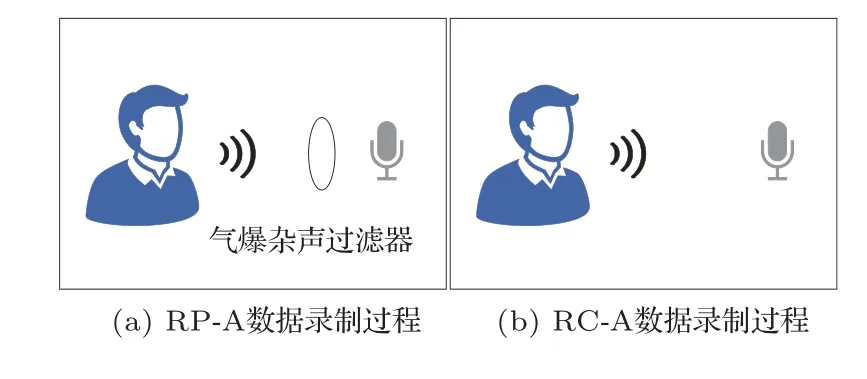
图3 POCO 数据集的记录过程Fig.3 Recording process of the POCO dataset
此外,为了研究本文提出的方法对多种条件下重放语声的检测效果,本文也使用ASVspoof2019 PA数据集进行了实验[24]。该数据集是由英国爱丁堡大学语声技术研究中心发布的专门用于评估重放语声检测算法的数据集,具体的数据集划分方式如表3所示。
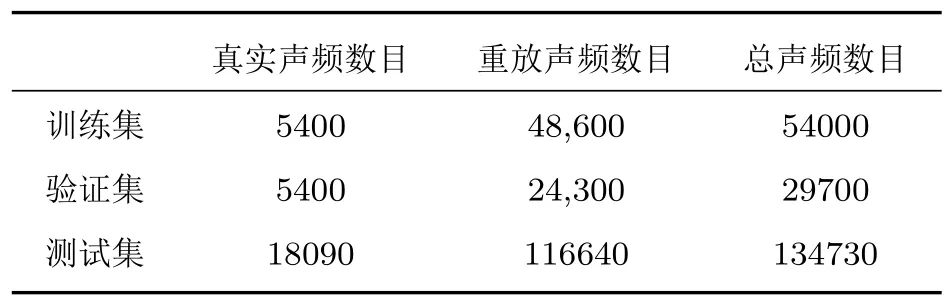
表3 ASVspoof2019 PA 数据集划分Table 3 Dataset partition for ASVspoof 2019 PA
3.2 评价指标
选择准确率(Accuracy rate,AR)与等错误率(Equal error rate,EER)作为重放语声检测方法的主要评价指标。另外,在ASVspoof2019 PA 数据集进行实验时,也使用了串联检测代价函数(tandem detection cost function,t-DCF)作为指标[25]。
AR 是预测正确的语声数占总语声数的比重,计算如下:
EER 通过调整阈值θ使得错误拒绝率Pmiss与错误接受率Pfa相同时得到,如下:
其中,θEER表示错误拒绝率Pmiss与错误接受率Pfa相等时的检测系统阈值。
3.3 特征嵌入可视化
采用t 分布随机近邻嵌入(t-distributed stochastic neighbor embedding,t-SNE)可视化方法对不同的声学特征进行可视化。实验中使用了来自POCO测试集的1663条语声,包括842条重放语声和821 条真实语声。图4 显示了不同语声特征的T-SNE 特征可视化结果。在图4(a)中代表真实语声和重放语声的点是高度分散,相互交错,这意味着基线方法中的LFAE 特征难以区分两种语声。图4(b)∼(d)所示是通过ResNet分别将MFCC、LFCC、GFCC 进一步提取后的特征。在图4(d)中,通过ResNet 和GFCC 出现了一个关于真实语声的紧凑聚类,四周只存在少量重放语声的点,这表明真实语声有很好的表征。图4(b)∼(c)中,真实语声的点与重放语声的点相混合,未出现紧凑的聚类。因此,经过ResNet 提取的GFCC 特征是后续CatBoost分类的合适特征。
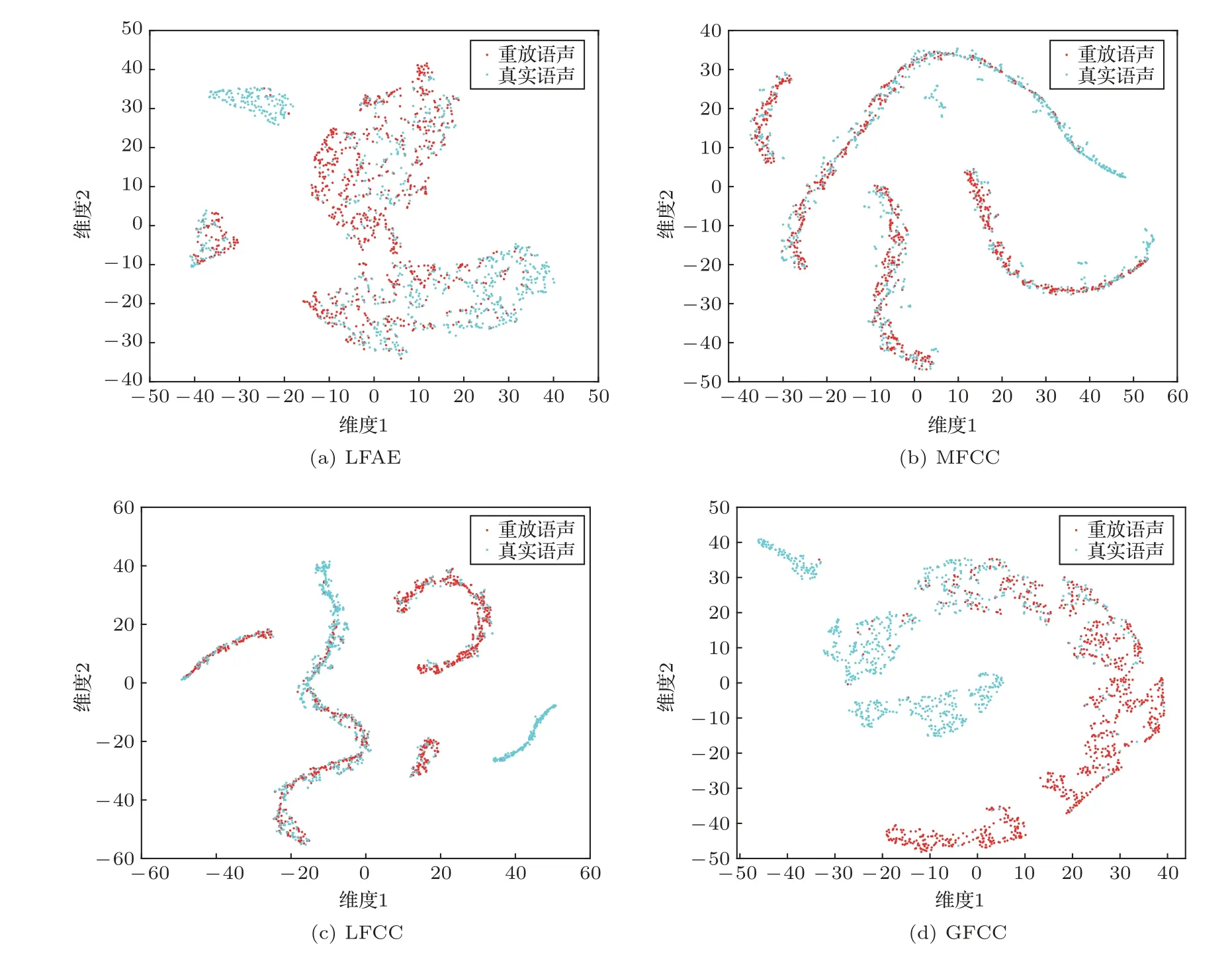
图4 对重放语声和真实语声不同特征的T-SNE 可视化Fig.4 T-SNE visualization of different features for replay voice and genuine voice
3.4 不同算法检测结果分析
为了验证该模型在重放语声检测上的有效性,与其他检测算法进行了比较,如表4 所示。从表中可知,GFCC+ResNet+CatBoost 方法检测效果最好。与基线相比,本文提出的方法的AR提高了13.95%,EER 降低了14.49%。与同样使用GFCC 特征的GFCC+SVM 方法相比,本文提出的方法也有明显提高。此外,本文的方法比使用低频STFT 特征以及CNN 分类器的方法AR 提升了5.39%。本文方法的检测效果也超过了目前效果最好的CQCC+LCNN 方法。最后,与其他3 种基于ResNet 的方法[18-20]相比,本文的方法也有明显优势。上述实验结果说明目标说话人的声音被较为完美录制并重放情况下,本文提出的方法在检测重放语声性能上优于经典重放语声检测方法。
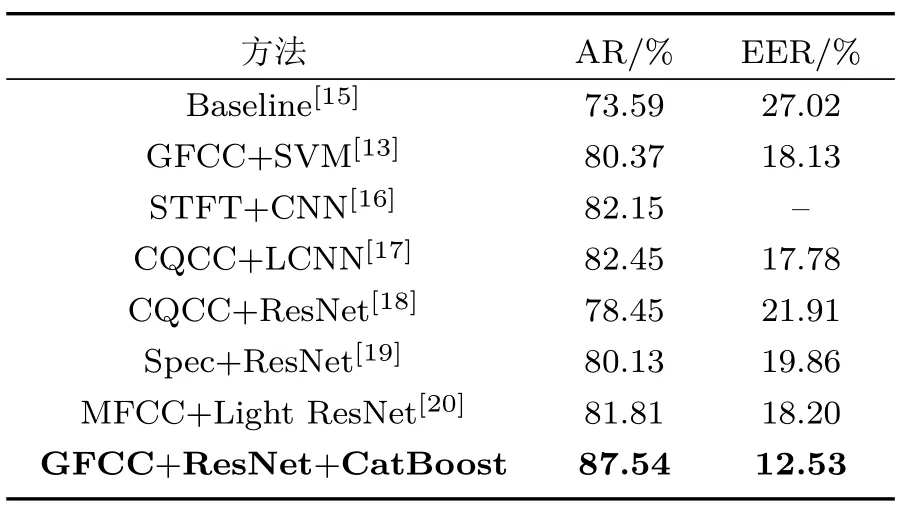
表4 不同算法在POCO 数据集上检测结果Table 4 Detection results of different methods on the POCO dataset
本节也使用不同特征和分类器进行了实验,实验结果如表5 所示。从该表中,可以看出使用相同特征时,ResNet+CatBoost 融合分类器效果最好,优于单独的ResNet分类器和单独的CatBoost分类器。此外,从整体上看,选择合适的声学特征中有助于提高分类器的检测能力。与使用其他两种声学特征相比,GFCC声学特征在检测效果上表现更好。
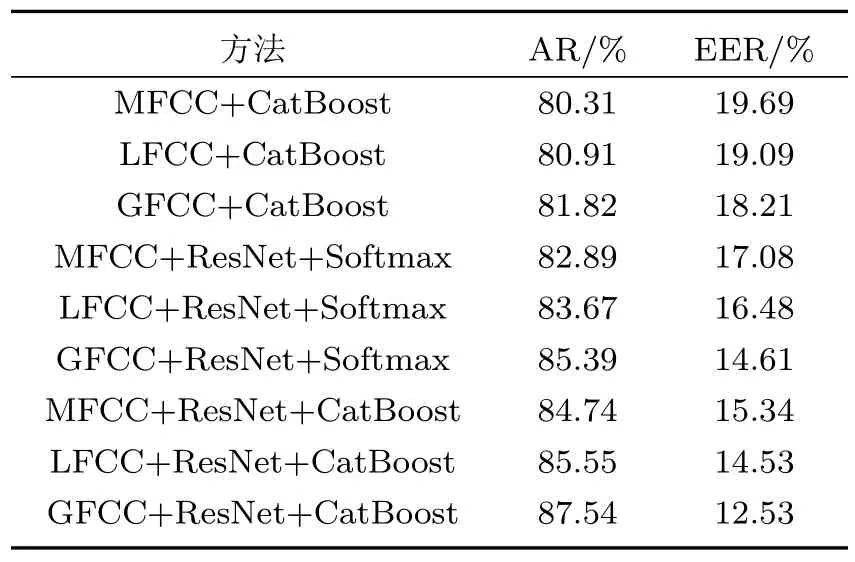
表5 不同特征和分类器检测结果Table 5 Detection results under different features and classifiers
3.5 不同词汇和性别检测结果分析
本节评估了词汇和性别对模型检测性能的影响。图5 显示了两个性别说话人的每个单词和所有单词的检测准确率。对于男性说话人,所有词汇平均准确率为89.04%,单个词汇平均准确率均超过了80%。而女性说话人的检测准确率较差,所有词汇平均准确率为86.10%,有6 个词汇的平均准确率低于80%,特别是‘end’的准确率只有61.54%。
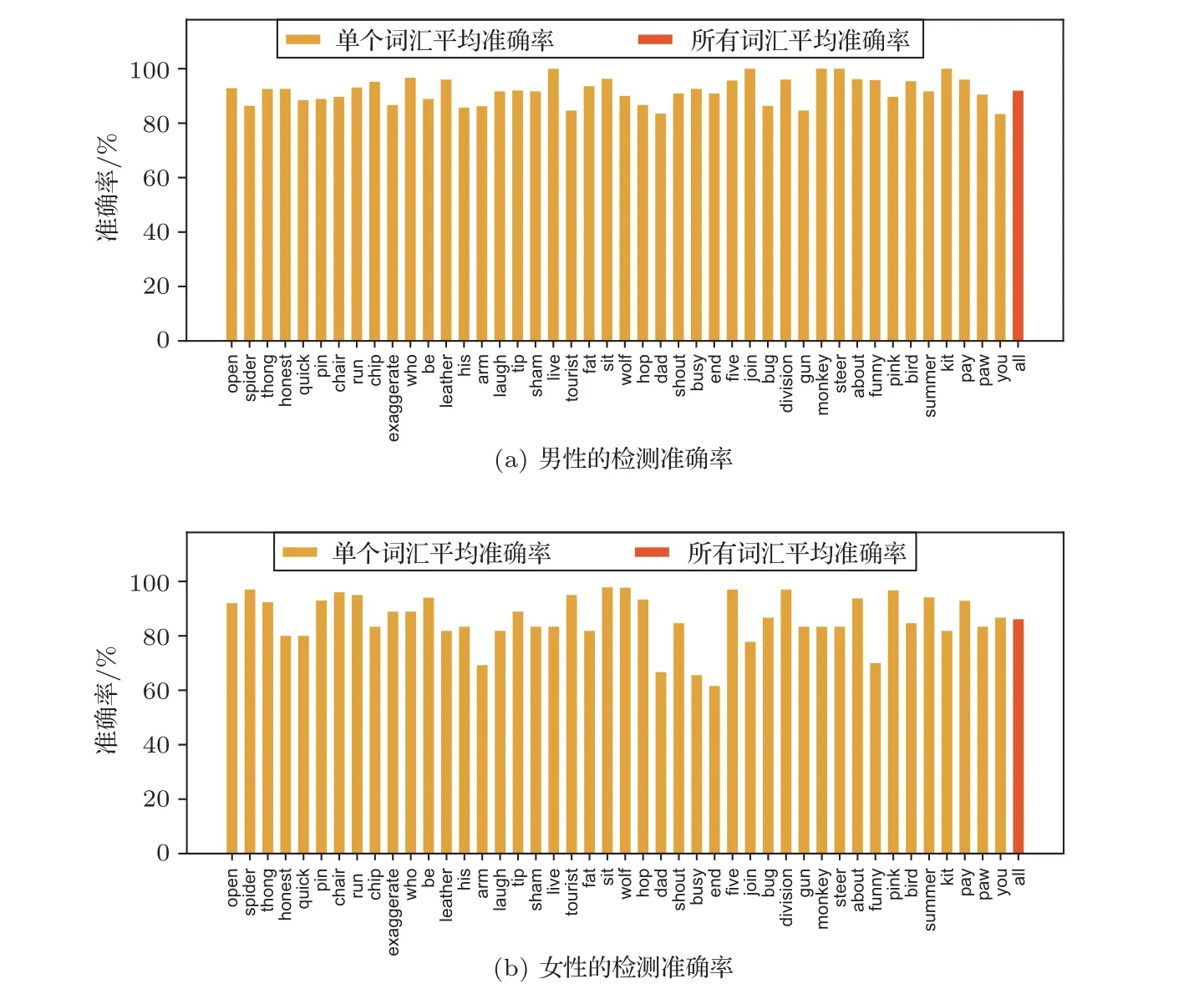
图5 在不同词汇和性别下检测准确率Fig.5 Detection accuracy under various words and genders
通过研究错误判断的数据,找出了两个可能导致错误判断的原因。首先,一些说话人说话轻柔,这使得他们的声音更容易被背景噪声所掩盖。其次,与男性相比,女性的声音频率更高。本文的方法使用了低频GFCC特征,一些女性说话人语声中的信息可能丢失。未来,将尝试提出一种更有效的基于不同性别的检测方法。
3.6 不同语声帧选择及排序方法检测结果分析
在POCO 数据集上,采用4 种语声帧选择及排序方法的实验结果如表6所示。从表中可以看出,使用本文提出的语声帧选择方法并按照3 种方式排序时检测效果与使用随机语声帧选择方法相比均有所提升。在使用本文提出的语声帧选择方法时,3种帧排序方法中按帧序号排序检测效果最好,按能量从低到高排序效果次之,按能量从高到低排序效果最差。结果说明合理选择语声数据帧并且按照原有的帧序号排序可以提高重放语声检测的效果。

表6 不同语声帧选择及排序方法的检测结果Table 6 Detection results under different voice frame selection and sorting methods
3.7 不同频率范围下的检测结果
在POCO 数据集上,分别使用文献[10]中设置的0∼40 Hz,文献[13]中设置的0∼103 Hz 以及最高频率为采样率一半的11025 Hz 三种范围的GFCC特征,检测的性能如表7 所示。从表中可以看出使用0∼40 Hz 范围的GFCC特征时,AR 和EER 效果最好,说明低频区域的声学特征区分真实语声和重放语声的效果更好。

表7 不同频率范围下的检测结果Table 7 Detection results under different frequency ranges
3.8 ASVspoof2019 PA 数据集上的检测结果分析
为研究本文提出的方法在多种重放条件下的检测效果,在ASVspoof2019 PA 数据集上进行了实验。因为ASVspoof2019 PA 数据集中声频长度相差较大,在该数据集上选择部分语声帧作为输入可能会丢失重要的信息。因此,选择最长声频提取的GFCC 特征矩阵的行数220 作为所有GFCC 特征的行数,其他提取的GFCC 特征填充0 直到成为220×60 的特征矩阵。为了输出维度的匹配,Conv2层卷积核大小改为9×3,其他设置相同。与其他检测算法进行了整体上的检测性能比较,如表8所示。与基线方法CQCC+GMM、LFCC+GMM 相比,本文方法的EER 与t-DCF 均有明显的改进。本文方法与同样使用ResNet的STFT+ResNet相比,检测性能也有比较明显的改进。最后,与其他两种基于深度学习分类器方法的Spec+CNN、STFT-CapsNet相比,本文提出的方法也有一定的提高。上述实验结果说明虽然本文提出的方法不是专门针对ASVspoof2019 PA数据集提出,也对ASVspoof2019 PA 数据集中多种条件的重放语声攻击具有一定的防御能力。

表8 不同算法在ASVspoof2019 PA 数据集上检测结果Table 8 Detection results of different methods on the ASVspoof2019 PA dataset
为评估录声距离和重放设备的质量对重放语声检测效果的影响,也进行了相应的实验。ASVspoof2019 PA数据集中重放语声攻击类型有9种,由两个字母表示。其中第一个字母表示录音设备与说话人的距离(A:10∼50 cm;B:50∼100 cm;C:>100 cm),第二个字母代表重放设备的质量(A:完美;B:高;C:低)。表9 显示了本文提出的方法和基线方法在不同重放攻击类型下的比较结果。因为表中涉及的语声全部为重放语声,采用准确率作为评价指标。由表中可以看出,攻击类型为AA、BA和CA 时,两种方法的准确率均比较低,而攻击类型为AB、BB 和CB 时,两种方法的准确率明显提高。这表明重放设备的质量越高,重放语声检测的难度越大。另外,表中也可以看出,录声设备与说话人的距离越近,重放语声检测的准确率越低。上述实验结果说明目标说话人的声音被近距离录制且用高质量重放设备重放后,引入的卷积和加性噪声相应的减少,加大了重放语声检测的难度。最后,表中也能看出本文方法对重放设备质量和距离的敏感性弱于基线系统,这表明了本文方法具有一定实用性。

表9 在不同重放攻击类型下准确率Table 9 Accuracy rate under different replay attack types
4 结论
本文通过ResNet 和CatBoost 的融合,提出了一种新的重放语声检测方法。首先,在本文提出的声频帧选择方法中,通过STFT、LFAE 计算和帧排序对的语声进行预处理。其次,计算这些帧的低频GFCC 声学特征。在此基础上,通过基于自注意机制ResNet进一步提取GFCC特征中的特定信息。最后,将提取出的特征用于CatBoost 训练和分类,从而达到更好的检测效果。通过对比实验结果说明了该方案的有效性。此外,本文还研究了性别、词汇、语声帧选择方法、频率范围、录制距离和重放设备的质量对实验结果的影响。未来的工作中将提出一种更有效的基于不同性别的重放语声检测方法。
猜你喜欢
科技信息·学术版(2021年17期)2021-11-22
哈尔滨工程大学学报(2021年8期)2021-09-07
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中国交通信息化(2018年5期)2018-08-21
东坡赤壁诗词(2018年2期)2018-05-10
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
