
面向算力网络的多路径时敏优先调度机制
2023-09-21 08:47夏华屹XIAHuayi权伟QUANWei张宏科ZHANGHongke
中兴通讯技术 2023年4期
夏华屹/XIA Huayi,权伟/QUAN Wei,张宏科/ZHANG Hongke
(北京交通大学,中国 北京 100044)
数字经济已成为中国经济发展不可或缺的驱动力,而算力作为数字经济的重要部分,在信息数据处理、智能算法优化等方面起着关键作用[1]。截至2023年3月底,中国累计建成5G基站超过264万个,算力总规模达到每秒180运算次数(EFLOPS);算力规模快速增长,梯次优化的算力供给体系初步构建,算力规模排名全球第二,年增长率近30%。以OpenAI推出的智能对话模型ChatGPT为代表的人工智能(AI)技术的爆发让全球算力大盘中的智能算力占比提升,第三方数据分析机构IDC在《2021—2022全球计算力指数评估报告》指出:算力指数平均每增加1%,国家数字经济和国内生产总值(GDP)则分别增长3.5‰和1.8‰[2]。据国家发展改革委与工业和信息化部等部门联合实施的“东数西算”工程,中国将重点发展算力全产业链的自主可控建设,形成一体化的新型算力网络体系。该工程对国家政治、经济以及各行业的发展有着重要意义[3]。
为提升数据通信质量,边缘计算中心、高性能数据中心等算力基础设施在生活中的应用逐渐增多。但同时这也逐渐暴露出算力设施在面对多样化服务流量时,计算节点的计算任务分配机制不完善、无法合理使用算力资源等问题。这使得算力设施在使用场景中有了局限性[4]。为解决上述问题,研发者们提出了算力网络的概念,即一种以算为中心、网为根基,网、云、数、智、安、边、端、链(ABCD-NETS)深度融合的一体化信息服务基础设施[5]。算力网络可以保证用户体验的一致性,使用户可以基本忽略基础设施资源的分布位置与调动状态,为多样化服务流量的分配与调度提供了解决思路[6]。对此,互联网研究工作组(IRTF)设立了网内计算研究组(COIN),研究算力网络新型传输架构;中国通信标准化协会网络与业务能力技术工作委员会(CCSA TC3)已完成《算力网络需求与架构》等研究。算力网络的发展已取得部分进展,但仍面临着诸多技术挑战。其中,算力网络下的低时延调度机制问题亟待解决。
面对算力网络的低时延传输需求,研究者从不同角度进行了方案与机制的研究。文献[7]设计了一种以服务器为中心、网络构造递归的数据中心模式以提供低延迟调度,支持延迟敏感数据的传输,但其部署模式不易拓展,较难根据算力调用需求进行网络规模的迭代。文献[8]设计了一种异构分布式数据中心场景下的工作流调度算法,提出了低负载、低成本与低延迟的多目标优化模型,但暂未考虑多样化服务的算力调用需求,较难满足不同用户的复杂需求。文献[9]提出了一种按需分配的算力资源的联合优化路由控制与资源分配调度模型,旨在降低算力网络的确定性时延,但这种以最短路径为指向的任务调度较难满足多样化服务流中的差异化调度优先级需求。文献[10]提出了一种基于动态三向决策的任务调度算法,为任务分配不同的权重,并结合工作模式和任务期限进行优先级规划,其调度算法能满足单一计算中心的高优先级任务调度需求,但没有考虑结合算力网络进行拓扑级的宏观调度调控。文献[11]根据算力网络不同层次的特性和各种应用的不同需求,提出一种多层次算力网络模型和计算卸载系统以降低确定性时延。该模型考虑了单一模型的任务调度场景,在面对多样化服务时,较难实现差异化调度服务需求。
综上所述,目前业界对算力网络多样化服务的低时延传输机制的研究尚不成熟。为此,本文设计面向算力网络的多路径时敏优先调度机制,通过基于强化学习的多路径转发调度以及优先级队列调度,降低算力网络中低时延需求数据包传输及排队时延,实现算力网络传输时延的相对确定性。
1 系统设计
1.1 机制总体设计
本文设计了面向算力网络的多路径时敏优先调度机制,其系统架构如图1所示。该机制保障算力网络中多样化服务的低时延通信需求:

▲图1 多路径时敏优先调度系统架构
1)多路径转发调度(作用于数据包转发过程)。通过基于强化学习的路径选择算法,该机制对算力网络中各路径的传输价值进行量化,动态更新各路径的价值量,并做出路径选择;对路径时延进行随机变量数学建模,在一定置信概率内利用主从备份传输机制,实现时延性能的提升。
2)优先级队列调度(作用于算力路由设备出端口数据包排队过程)。该机制设计了包等级与优先队列映射算法:当优先队列数量小于包等级范围时,数据包将近似按等级顺序出队,拟合数据包推入先出行为,从而减少算力网络中时延敏感型网络数据包在队列缓冲区的排队时延。
1.2 多路径转发调度
本文所提的多路径转发调度指通过强化学习,探索与学习路径特征并做出相应决策。它是一种通过智能体与环境的交互来获取最优决策的方法。本模块将算力网络控制器抽象为智能体,将其所处各路径的算力网络状态定义为环境,将路径选择算法每次做出的决策定义为回合迭代,并将回合迭代中所选取的传输路径定义为动作。在选择该动作的情况下,本文所设计的多路径转发调度以所探测到的网络信息作为状态,将路径时延定义为奖赏。
由于在算力网络中存在排队、拥塞等问题,我们假设第k路径的时延变量Xk服从对数正态分布, 即ln (Xk)~N(μ,δ2)。当给定xk>0 时,其概率分布函数如公式(1)所示:
其中,对数正态分布的最大似然估计如公式(2)和公式(3)所示。其中,Nk表示选择路径k的次数。
对数正态分布随机变量的均值和方差如公式(4)和公式(5)所示:
由于对数正态分布,其随机变量分布较为复杂。若将其长尾部分省略,则近似认为第k路径的时延变量Xk服从均值为μk、方差为的高斯随机变量,且各路径的时延变量Xk相互独立。Xk的概率密度函数如公式(6)所示:
对于对数正态分布其统计意义上的期望及方差无偏估计如公式(7)和公式(8)所示:
在路径选择算法中,每一轮次的路径选择会根据实时网络数据来更新每一条路径的价值量,并对价值量进行排序,选取最大的路径作为主传输路径。路径选择算法的价值量计算如公式(9)所示:
其中,S表示路径选择的总次数;代表第k条路径选择次数与选择总数之间的关系,它可以表征这条路径时延的置信区间。当一条路径探索次数较其他路径较少时,可以认为该路径有较为宽泛的置信区间,即具备较大的探索价值。当一条路径反复被选取时,可以近似认为其置信区间变小,探索价值变低。我们设计的是乐观的选路算法,即在选路时认为置信区间对于选路的决策呈现正向作用。
本文中我们通过基于强化学习的路径选择算法,选取当前最大价值量路径作为主传输路径。然而,考虑路径时延抖动与路径探索等因素的影响,价值量最大的路径可能并不是算力网络中时延敏感型传输服务的最优选择,因此我们设计了一种多路主从传输机制,利用冗余发包选取备份传输路径,牺牲了部分带宽,以换取时延性能的提升。
经以上分析,我们可近似将各路径时延分布Xk作相互独立的高斯正态分布处理,并假定基于最大价值量选取的路径为i,时延分布为Xi,则,即两独立路径的时延随机变量相减仍为高斯正态分布,路径k传输时延优于最大价值量路径i的概率可表示为:
假定P{Xk-Xi≥0}≥α,该条路径可以作为备选次优路径。若有多条路径均符合上述概率条件,则选取置信概率最大的路径进行传输,以避免占用过多带宽资源。
多路径低时延转发调度算法的具体流程如算法1所示。
1.3 优先队列调度模块设计
当路径选择模块选定具体的传输路径后,算力网络中多种网络业务并存且需求带宽大于出口带宽时,时延敏感型算力服务会产生较大的排队时延,难以满足用户需求。因此,本文中我们在可编程交换设备出端口设计了优先级队列调度模块,设计包等级与队列自适应映射算法拟合数据包推入先出行为,减少低时延需求数据包的排队时延。我们基于P4数据平面实现的自适应队列调度机制简称为P4-APQ。
包等级与队列自适应映射算法的示意如图2所示,其作用场景为数据包等级范围大于优先队列数量。该调度算法可利用有限严格优先级队列来拟合数据包的推入先出过程,即数据包近似按等级顺序出队列(本文中,我们约定等级越小,调度优先度越高)。自适应映射算法误差定义为较大等级数据包数量小于较小等级数据包出队的数据包数量,我们将这种误差的现象称为“反转”。由于利用了严格优先级队列拟合推入先出行为即按等级顺序出队,因此当数据包等级范围大于严格优先级队列数量时,有一定概率在调度过程中会出现“反转”现象。对于本文所设计的包等级-队列映射,设计目的为在保证小等级数据包优先调度的前提下,尽可能按等级顺序出队,减少“反转”现象。

▲图2 包等级与队列自适应映射算法示意图
针对算力网络时敏型业务低时延需求,包等级与队列自适应映射机制设计了高优先级预留队列,避免最小等级的数据包因优先级“反转”现象而出现较高的排队时延。具体地,首先判定数据平面传入数据包的等级;若等级最小,数据包将直接进入具有最高优先级的预留队列,从而避免等级队列的动态映射带来的“反转”损失。
当数据包等级不是最小时,为保证队列调度结果近似按等级顺序出队,我们设计了自适应映射算法,动态改变各队列的边界值,以最小化拟合损失。自适应映射算法的损失函数可以描述为公式(11):
其中,L表示为拟合损失,P表示所有入队数据包,q表示一组动态变化的队列边界向量,p表示属于P的一个入队数据包。单个数据包的损失可以表示为公式(12):
其中,r(p)表示为给定的数据包p的等级,rp(p,q)表示为给定数据包所映射的队列自适应调整后的边界值,cost表示单个数据包产生的误差,即出现“反转”的情况。包等级与队列自适应映射算法通过动态调整数据包等级与各优先队列的映射关系,在兼顾数据平面的算法复杂度基础上,降低损失函数L。
包等级与队列自适应映射算法可分为两个阶段:
1)“上推”阶段。在该阶段,通过增加进入数据包所映射队列的边界值,减少数据包分组等级与队列边界值的差值,从而减少映射中出现的误差值。具体地,传入的数据包将从较低优先级的队列开始匹配。当数据包等级r(p)大于等于队列边界qi时,数据包进入该队列,同时将队列边界qi增加到等于该数据包等级r(p)。该过程可以尽量保证数据包实现零误差映射,并防止等级小于队列边界值的数据包映射到当前队列。以上设计仅针对非最高优先级队列。当映射过程匹配到最高优先级队列(不包括预留队列),即使r(p)<q1时,当前数据包会进入最高优先级队列。这将出现“反转”现象,并带来较大的映射损失。这时,我们将根据公式(12)来计算误差损失,并更新最高优先级队列边界值为该数据包等级。
2)“下推”阶段。由于“上推”阶段可能导致最高优先级队列出现“反转”现象,“下推”阶段将减少“上推”阶段的调度损失。当最高优先级队列出现“反转”现象时,自适应算法将根据公式(12)来计算损失成本,再根据公式(13)依次减少除最高优先级队列以外的队列边界。该阶段降低了最高优先级以外的队列边界,减少较高优先级队列中允许进入的数据包等级范围,即减少等级较大的数据包进入高优先级队列的情况,进而减少出现“反转”现象,降低调度损失。
本文所设计的等级与优先队列自适应映射算法的具体流程见算法2。
2 实验验证与性能分析
为测试多路径时敏调度机制相关功能及性能,我们于Mininet 环境下搭建包含5 台终端主机及5 台BMv2 交换机的网络拓扑。其中H1、H2、H3、H4 作为算力服务请求方与算力路由设备S1 相连;S1 分别与算力路由设备S2、S3、S4相连作为传输的3 条路径;H5 作为算力节点与算力路由设备S5相连。各路径设置的实验参数如表1所示。

▼表1 路径具体参数
2.1 多路径转发调度性能测试
本文实现了多路径转发调度中置信参数α为0.05的多路径选择算法,同时实现了传统轮询方式的路径选择算法、ε值为0.1的贪心策略的路径选择算法以及基于置信区间上界(UCB)算法的路径算法以进行相关对比分析,并对每种选路算法进行了500轮次的选路决策。
为观察各路径选择算法的时延性能,我们将每10 轮计为1个记数点来计算平均时延,结果如图3所示。本文所设计的路径选择算法通过前期路径探索后,时延在50 轮后有明显的降低,150 轮后平均时延为20 ms 左右,基本收敛于最优路径。我们将4种算法作定量分析:多路径选择算法的平均时延为21.57 ms,轮询策略的平均时延为32.56 ms,ε-贪心算法的平均时延为25.12 ms,UCB 算法的平均时延为25.91 ms。本文所提的路径选择算法在进行500 轮次的决策条件后,和轮询策略相比,时延均值降低33.75%;和ε-贪心算法相比,时延均值降低14.13%;和UCB 算法相比,时延均值降低16.75%。

▲图3 各路径选择算法平均时延图
为验证不同置信参数α对多路径选择算法时延性能的影响,我们设置了3 组典型参数值,分别为:α= 0.05,α=0.15,α= 0.25,并进行了500轮次的路径决策,每10轮为1个记数点来计算平均时延,具体结果如图4 所示。α= 0.05时,本文所设计的多路径选择算法平均时延为21.57 ms;α= 0.15时,平均时延为23.30 ms;α= 0.25时,平均时延为24.02 ms。实验结果表明,较小置信参数可较多地利用主从备份传输,以提升传输性能。
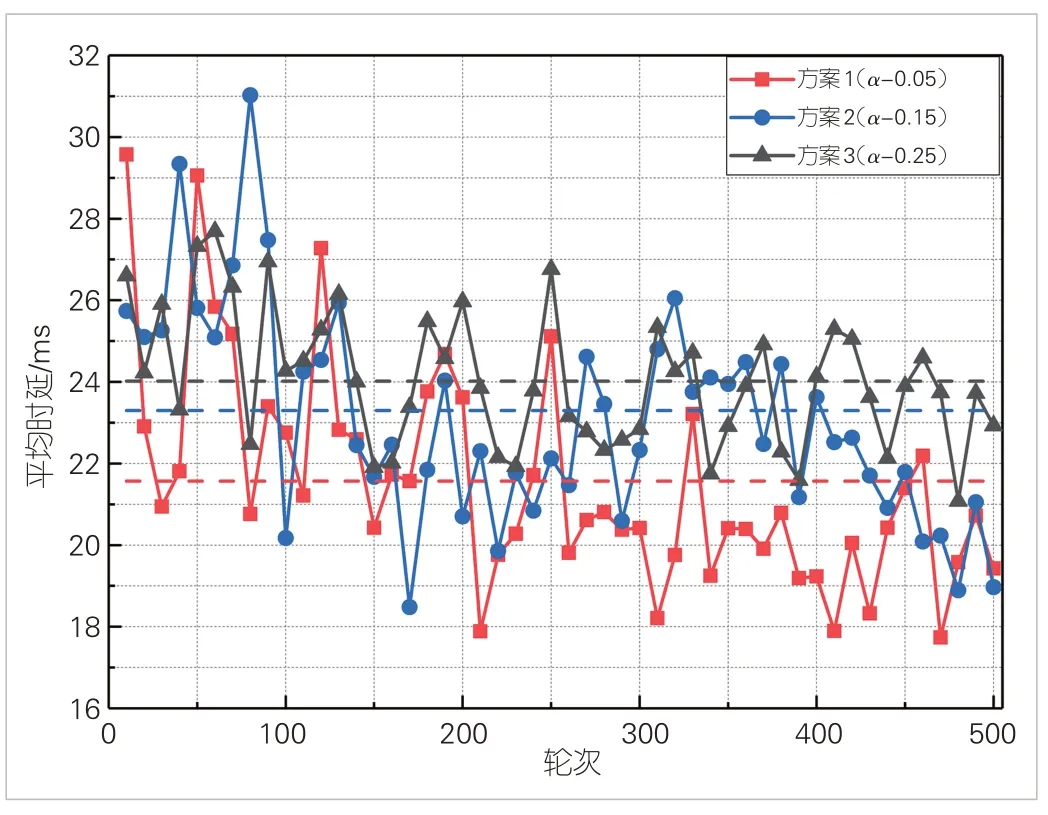
▲图4 不同置信参数下的多路径选择算法平均时延图
2.2 优先队列调度性能测试
本节中,我们将测试优先队列调度的各项性能指标,并与先进先出(FIFO)队列方案、基于严格优先级队列拟合推入先出(SP-PIFO)[12]队列调度方案进行对比。在典型场景下,我们测试队列调度算法的具体性能。假设路径选择算法已将S1 的转发出端口路径收敛于S1-S3 路径,同时设定S1与S3链路带宽为50 Mbit/s,时延为10 ms,不额外设置链路抖动。
在典型场景下,我们预设H1、H2、H3、H4 的数据流等级分别为0、1、2、3,分别代表高优先级、次高优先级、中优先级以及低优先级。H1、H2、H3、H4在同一时刻采用iperf工具来生成用户数据报协议(UDP)流量,再发往终端H5(持续50 s)。其带宽分别设置为10 Mbit/s、10 Mbit/s、15 Mbit/s及20 Mbit/s,总流量大于设置链路带宽。这将造成一定程度的节点拥塞,从而验证队列调度的相关性能。
测试中,我们利用3个FIFO队列实现了P4-APQ,同时利用3 个FIFO 队列实现SP-PIFO。P4-APQ、SP-PIFO 以及FIFO 的队列数据包容量大小均设置为64。P4-APQ、SPPIFO以及FIFO队列的高优先级流单向时延随时间的变化如图5所示。
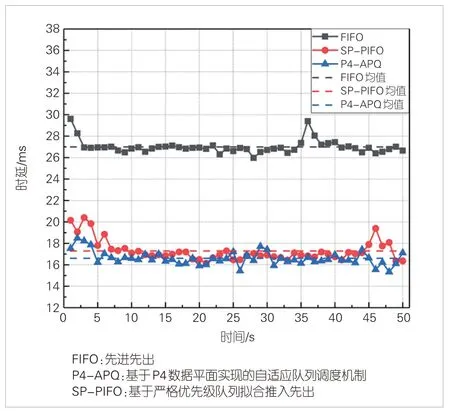
▲图5 队列调度算法高优先级流单向时延随时间变化图
对于高优先级流而言,本文所提的P4-APQ算法基于高优先级预留队列的设计,时延性能略优于SP-PIFO,显著优于FIFO。SP-PIFO 由于没有相关预留队列的设计,在最高优先级队列中会出现“反转”的现象,因此也会出现非最高优先级的数据流量,从而造成最高优先级流时延及抖动的增加。对于FIFO 队列,由于对各类流量不作区分处理,高优先级流量时延较大。高优先级流在P4-APQ 算法的调度下,平均时延为16.30 ms,方差为0.39 ms2;在SP-PIFO 队列调度下中,高优先级数据流的平均时延为17.53 ms,方差为0.65 ms2;在FIFO 队列中,高优先级数据流平均时延为26.99 ms,方差为0.41 ms2。通过定量计算可知,本文设计的P4-APQ队列调度算法针对高优先级数据流的平均时延较SP-PIFO 降低7.01%,较FIFO 降低39.6%;抖动较SP-PIFO降低40%,较FIFO降低4.9%。
P4-APQ、SP-PIFO 以及FIFO 队列的最高优先级流吞吐量随时间变化的情况如图6 所示。本文所设计的P4-APQ 队列调度算法高优先级流吞吐量均值为10.47 Mbit/s,SP-PIFO队列调度算法高优先级流吞吐量均值为10.41 Mbit/s;FIFO队列在高优先级流吞吐量均值为8.54 Mbit/s。由以上定量分析可以发现,本文所采用的P4-APQ通过给各流量的等级设定,并基于等级与队列映射算法,可以保障高优先级业务流量的稳定吞吐量;高优先级流量吞吐量高于FIFO 队列,与SP-PIFO吞吐量近似相等。

▲图6 各队列调度算法高优先级流吞吐量随时间变化图
根据上述分析,本文所设计的P4-APQ队列调度算法针对较高优先级数据流,能够有效降低排队时延及其抖动,同时提供稳定的吞吐量。
3 结束语
算力网络作为中国率先提出的新型网络架构,是推动信息产业发展、支撑“十四五”发展规划中“网络强国”发展战略的重要基础。针对算力网络的低时延传输需求,本文提出了多路径时敏优先调度机制,设计了基于强化学习的多路径低时延转发调度算法,根据网络实时状态,动态选取低时延传输路径,并在转发出端口设计了等级与队列自适应映射算法,减少低时延应用的排队时延。经过相关实验测试及分析,本文所设计的多路径时敏优先调度机制能够在算力网络场景下提供低时延服务保障。
猜你喜欢
现代经济信息(2023年30期)2023-11-26
卫星应用(2023年1期)2023-02-21
现代经济信息(2022年22期)2022-11-13
北京航空航天大学学报(2021年9期)2021-11-02
中国交通信息化(2021年7期)2021-11-02
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
中国交通信息化(2019年2期)2019-03-25
军营文化天地(2018年2期)2018-12-15
产品可靠性报告(2017年7期)2017-09-05
