
基于关系过滤和实体对标注的中文关系抽取方法
2023-09-27 01:38张啸成张永刚
吉林大学学报(理学版) 2023年5期
刘 旭, 杨 航, 张啸成, 张永刚
(吉林大学 计算机科学与技术学院, 符号计算与知识工程教育部重点实验室, 长春 130012)
0 引 言
关系三元组抽取是自然语言处理中的一项重要工作, 它的目标是从无结构的文本中联合提取出实体和关系, 为下游知识图谱的自动构建奠定基础. 以往的研究[1]通常将关系三元组抽取任务视为两个子任务: 实体识别[2-3]和关系分类[4-6], 并且两个子任务独立完成. 尽管这种三元组的抽取方法很灵活, 但忽略了实体与关系之间的交互性和关联性, 且无法避免错误传播问题. 近期提出的一系列实体和关系联合抽取方法[7-12], 能利用实体与关系之间的交互性和关联性, 有效缓解错误传播问题产生的影响. 这类方法是通过序列标注实现的, 目前已取得了许多成果. 但这类方法也存在一定的问题, 它们通常对关系集合中每种关系都进行实体标注[7-8,11], 从而产生冗余关系问题, 而冗余关系会对最终的三元组抽取结果产生不利影响. 此外, 序列标注的方法也不能有效解决各种实体重叠情况, 例如文献[7]并未考虑任何实体重叠的情况, 文献[8]虽然能解决单实体重叠和实体对重叠的情况, 但不能解决实体嵌套的情况. 表1列出了不同的实体重叠情形.
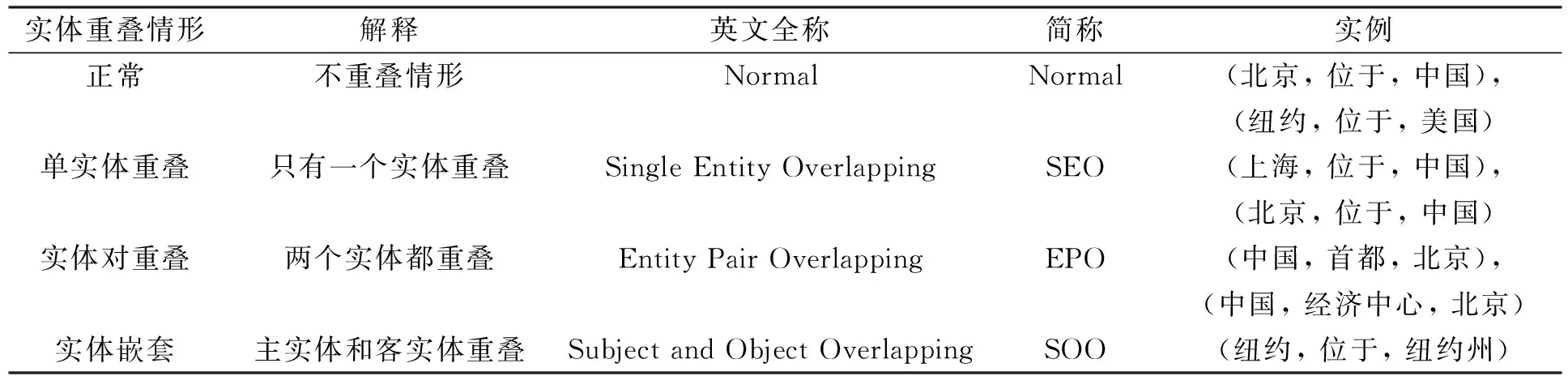
表1 不同的实体重叠情形Table 1 Different entity overlapping scenarios
为有效解决上述两个问题, 本文提出基于关系过滤器的二维实体对标注方案(RF2DTagging). 该方案由两部分组成: 1) 关系过滤器, 解决冗余关系问题; 2) 二维实体对标注器, 解决实体重叠问题. 在3个公开的中文数据集上进行验证实验, 实验结果表明, 本文模型比对比模型性能更好.
1 任务定义
对于一个句子S={w1,w2,…,wN}和一个预定义的关系集合R={r1,r2,…,rK}, 本文目的是识别出其中蕴含的所有关系三元组.关系三元组可形式化为(s,r,o), 其中s表示主实体,o表示客实体,r表示关系集合中的某个关系.需要注意的是主实体和客实体都是给定句子中的连续子序列.关系三元组提取任务可定义为根据预定义的关系集合R从给定句子S中识别出所有关系三元组的集合TS={(s,r,o)i|r∈R, 1≤i≤M}, 其中M表示从S中提取出的关系三元组总数.
2 方法设计
RF2DTagging模型的整体结构如图1所示. 由图1可见, RF2DTagging模型宏观上由三部分组成: 文本编码器、 关系过滤器和二维实体对标注器.
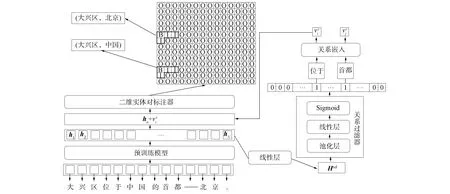
图1 RF2DTagging模型的整体结构Fig.1 Overall framework of RF2DTagging model
2.1 文本编码器
近年来, 深度学习模型在图像处理领域取得突破性进展, 因此, 相关研究者开始尝试将深度学习模型用于自然语言处理, 首先用于自然语言的编码. 在预训练语言模型提出前, 文本编码最常用的深度学习模型是长短期记忆网络(LSTM), 它是循环神经网络(RNN)的一种变形, 通过引入门控机制解决了RNN的长期依赖问题. 由于BERT模型[13]的提出, 使得先预训练再微调的两阶段训练方式成为自然语言处理的通用范式. 为捕获句子中每个字的上下文特征, 本文使用BERT作为编码器. BERT是一个基于多层双向Transformer的语言表示模型, 它能学习句子中每个字的特征信息:
H=BERT(x1,x2,…,xN)=(h1,h2,…,hN),
(1)
其中:N表示句子长度, 即该句子中的字数;xi表示第i个字的输入向量, 是第i个字wi的词嵌入与位置嵌入的拼接;hi∈dh表示第i个字的隐藏态向量.
2.2 关系过滤器
对于关系三元组抽取任务, 常存在冗余关系问题.即每个句子中所包含的关系数远小于预定义的关系总数, 如果根据关系集中的所有关系进行三元组抽取, 则会产生与输入句子不适应的关系, 即冗余关系, 这不但对计算机资源是一种浪费, 而且也会对最终的抽取结果产生消极影响.因此本文提出用关系过滤器过滤冗余关系.运算过程如下.
1) 通过线性层获得文本关于关系的向量表示:
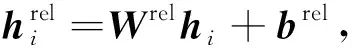
(2)
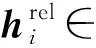
2) 通过池化操作获得文本关于关系的全局向量表示:
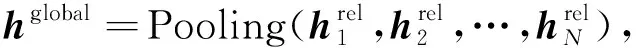
(3)
其中:hglobal∈drel是文本关于关系的全局向量表示;N表示句子长度; Pooling(·)表示池化操作, 本文使用的具体池化操作是平均池化.
3) 通过线性层和非线性激活函数获得关系的概率分布:
Prel=Sigmoid(WPhglobal+bP),
(4)
其中:Prel∈K是关系对输入文本的概率分布,K表示关系总数; Sigmoid(·)是非线性激活函数, 可将任意一个实数映射为0~1的值, 即其值域为(0, 1);WP∈K×drel表示可训练的权重;brel∈K表示偏置项.
4) 设定关系过滤阈值, 过滤冗余关系. 本文设关系过滤阈值为μ, 如果某一关系的概率小于μ, 则认为该关系为冗余关系, 并将其舍弃; 如果某一个关系的概率大于等于μ, 则认为该关系为输入文本的置信关系, 将根据置信关系进行实体对标注. 例如通过设置阈值μ, 图1中的句子“大兴区位于中国的首都——北京。”可获得置信关系“位于”和“首都”, 本文将根据这两个置信关系进行实体对标注.
2.3 二维实体对标注器
对于实体识别, 最经典的方法是seq2seq的标注方案. 该方案或者在一个序列中同时标注出主实体和客实体[7], 或者在两个序列中分别标注出主实体和客实体[8]. 无论是前者还是后者都需要主实体和客实体的匹配, 这通常会导致错误传播问题, 且这种方案也不能有效解决实体重叠问题. 本文的二维实体对标注方案是一个seq2table的标注方法, 该方法可以直接提取出实体对, 而不用主客实体的匹配, 且这种二维标注方法可有效解决各种实体重叠问题. 二维实体对标注方案示例如图2所示.
2.3.1 二维实体对标注方案
对于一个长度为N的句子, 为其每个置信关系维护一个表TN×N.为便于描述, 本文用T(i,j)表示某一置信关系下字对(i,j)的标签, 这里的(i,j)是由句子中的第i个字和第j个字组成的字对.
本文的二维实体对标注方案为每个字对预定义3个标签: B,I,O.如果句子中第i个字和第j个字分别是主实体和客实体的第一个字, 则将字对(i,j)标注为B, 即T(i,j)=B, 如图2(A)中的字对(“第”,“北”)和(“第”,“中”), 它们分别是相应主实体和客实体的第一个字, 本文的二维标注方案将其标注为B; 如果句子中的第i个字是主实体的第一个字, 第j个字是客实体中除第一个字外的其他字, 或者第j个字是客实体的第一个字, 第i个字是主实体中除第一个字外的其他字, 则将字对(i,j)标注为I, 即T(i,j)=I, 如图2(A)中的字对(“第”,“京”)和(“奥”,“北”), 其标签为I; 如果字对(i,j)不属于上述两种情况, 则将其标注为O.
本文的二维实体对标注方案可解决各种实体重叠的情况.对于单实体重叠(SEO)的情形, 如图2(A)所示, 本文二维标注方案可在同一个表中标注出两个实体对; 对于实体对重叠(EPO)的情形, 如图2(B)和(D)所示, 可分别在两个表中标注出这两个实体对; 对于实体嵌套(SOO)的情形, 如图2(C)所示, 二维标注方案也可以在一个表中明确标注出该实体对.
2.3.2 标注器的实现
本文认为文本对于主实体和客实体的特征信息会对实体对的提取有积极作用, 即对于一个置信关系, 字对的标注结果与主实体和客实体的特征信息有关. 基于此, 本文使用两个线性层分别获得每个字关于主实体和客实体的向量表示:
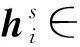
Dozat等[14]提出了Biaffine-attention机制, 其核心计算公式为
Biaffine(x,y)=xTU1y+U2(x⊕y)+b,
(7)
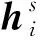
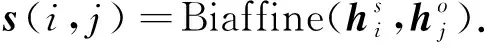
(8)
因为在标注过程中使用了3个标签, 所以s(i,j)∈3.通过Softmax函数预测字对(i,j)标签的概率分布为
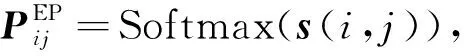
(9)
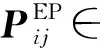
2.3.3 二维实体对标注器解码算法
本文将一个批次的二维实体对标注矩阵按下列算法进行解码, 最后获得该批次中每个样本所提取的三元组集合组成的列表.
算法1二维实体对标注器解码算法.
输入: 文本长度seq_len; 一个批次的置信关系列表rel_list∈batch_size_expand; 置信关系对应的样本序号列表sample_idxs∈batch_size_expand; 置信关系和样本对应的二维实体对标注矩阵M∈batch_size_expand×seq_len×seq_len;
输出: 该批次中每个样本所提取三元组集合的列表triple_set_list;
//初始化三元组集合列表, 用于存放一个批次中每个样本对应的三元组集合
triple_set_list←[ ];
pre_sample_idx←0;
triple_set←{ };
if sample_idx>pre_sample_idx:
//开始提取下一个样本中的关系三元组, 重新初始化其对应的triple_set
triple_set_list.append(triple_set);
triple_set←{ };
end if;
//根据关系索引获得关系名
rel_name←id2rel_name(rel);
从式(2)-式(4)、式(6)、式(7)、式(9)、式(10)知ψ、ψ9、ψ、ψ、ψ、μ、μ9由常数mb、ma、mc和变量φ决定,都无量纲。
//获取矩阵中被标注为“B”的索引
sub_heads,obj_heads←where(one_M=“B”);
//获得主实体和客实体首位置
for sub_head,obj_head in zip(sub_heads,obj_heads):
sub_index←sub_head+1;
//获得主实体尾位置
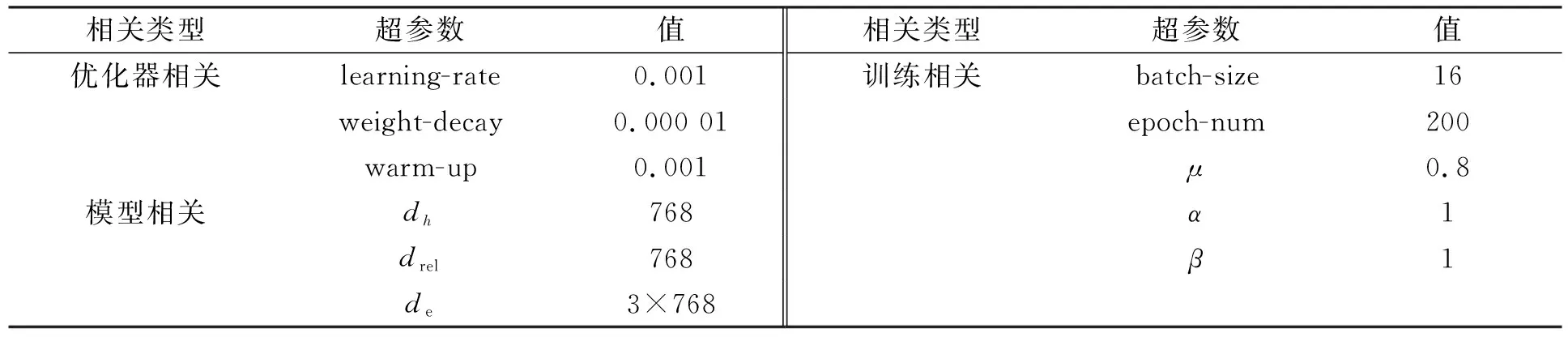
while sub_index sub_index←sub_index+1; end while; //根据主实体的首尾位置获得实体名 sub←pos2entity(sub_head,sub_index); obj_index←obj_head+1; //获得客实体尾位置 while obj_index obj_index←obj_index+1; end while; //根据客实体的首尾位置获得实体名 obj←pos2entity(obj_head,obj_index); //主实体、 关系和客实体组成三元组 triple←(sub,rel_name,obj); //将获得的三元组添加至当前样本对应的三元组集合 triple_set.add(triple); end for; end for; return triple_set_list. 为联合训练RF2DTagging模型, 本文构建联合目标函数, 其由两部分组成: 1) 关于关系的目标函数为 (10) 2) 关于实体对的目标函数为 (11) 其中N表示输入文本的长度. 本文的联合目标函数是上述两部分的加权和: Ljoint=αLrel+βLEP, (12) 其中α和β是超参数. 为测试RF2DTagging模型的性能, 本文在如下3个开放的中文关系提取数据集上进行实验: CCKS2019-Task3,CMeIE,DuIE2.0. 数据集CCKS2019-Task3是2019年全国知识图谱与语义计算大会(CCKS)发布的任务三数据集, CCKS2019的任务三旨在从中文文本中提取出人物关系, 在本文中将其数据集记为CCKS2019-Task3; CMeIE是CHIP2020会议发布的开源数据集, 其所对应的任务是中文医学文本实体关系提取; DuIE2.0是2020语言与智能技术竞赛的数据集, 该数据集专门用于关系抽取任务. 最初的3个数据集都只含有训练集和验证集而不包含测试集, 本文按照8∶2从训练集中随机选择样本组成测试集, 3个数据集的统计信息列于表2. 表2 各数据集的统计信息Table 2 Statistical information of each dataset 实验使用准确率(P)、 召回率(R)和F1值作为模型的评估标准, 三者有如下关系: F1=(2×P×R)/(P+R). 对于模型预测出的关系三元组, 当且仅当主实体、 客实体以及关系全都正确时, 才认为该关系三元组是正确的; 对于实体, 当且仅当其与测试样例的标签完全匹配时才认为是正确的. 本文在验证集上调节超参数, 训练出的最优模型所对应的重要超参数列于表3. 主要包括优化器相关、 模型相关以及训练相关. 对于模型中的可训练参数, 根据标准正态分布对其进行初始化. 本文使用AdamW算法作为优化算法训练模型, 因为它的warmup机制可加速收敛. 对于每个数据集都在其上运行5次, 并且取5次结果的平均值作为最终结果, 每次运行都会从训练集中随机生成测试集. 表3 模型超参数Table 3 Hyperparameters of model 为验证RF2DTagging模型的性能, 本文选择3个模型作为对比模型: NovelTagging[7],CasRel[8],TPlinker[11]. 其中NovelTagging模型使用BiLSTM作为文本编码器, 而CasRel和TPLinker模型使用预训练模型BERT作为文本编码器, 为公平比较, 将NovelTagging模型的文本编码器替换为BERT. 在运行对比模型时, 超参数和官方源码保持一致, 而数据的预处理参照本文模型的预处理, 即按8∶2划分训练集和测试集, 并且每次运行都从训练集中随机生成测试集. 实验的总体结果列于表4. 由表4可见, RF2DTagging模型除在数据集DuIE2.0的P评估标准上取得了次优结果外, 其余结果全部最优. 对于F1, RF2DTagging模型在数据集CCKS2019-Task3,CMeIE和DuIE2.0上比TPlinker模型分别提升了0.6,2.2,0.4, 证明了本文模型对中文关系三元组抽取任务的有效性. 相比数据集CCKS2019-Task3和DuIE2.0, 数据集CMeIE上的实验结果性能较差, 其可能原因有两个: 1) 相比数据集CCKS2019-Task3和DuIE2.0, 数据集CMeIE的训练集较小, 数据集CCKS2019-Task3和DuIE2.0的训练集分别是CMeIE的11.9倍和12.1倍; 2) 相比数据集CCKS2019-Task3和DuIE2.0, 数据集CMeIE的专业性较强, 其中包含很多专业术语和特殊符号, 在这些特殊符号中, 有些是医学专用符号, 有些是创建数据时由于格式处理产生的符号, 这给模型对文本的语义理解带来了困难. 表4 总体实验结果Table 4 Overall experimental results 为验证RF2DTagging模型在解决实体重叠问题时的效果, 本文在数据集CCKS2019-Task3和DuIE2.0上进行了进一步实验, 即根据不同重叠情形将两个数据集的测试集划分为不同的子集: Normal,EPO,SEO和SOO, 在这4个子数据集上分别进行实验, 实验结果列于表5. 由表5可见, RF2DTagging模型在EPO,SEO和SOO三种情况下都获得了最优结果, 证明了该模型能有效解决实体重叠问题. RF2DTagging模型在Normal情况下的性能有所下降, 这可能是由于错误传播导致的, 即一旦关系过滤器提取的置信关系是错误的, 则相对应的实体对标注也是错误的. 综上所述, 针对冗余关系和各种实体重叠的问题, 本文提出了一个基于关系过滤器的二维标注方案, 并将其命名为RF2DTagging. 分别设计了一个关系过滤器和一个二维实体对标注器, 二者共同构成了RF2DTagging模型. 在3个开放的中文关系抽取数据集上进行实验, 总体的实验结果证明本文模型在中文关系三元组抽取任务上比对比模型性能更好, 不同重叠模式上的实验结果也证明了本文模型确实能有效解决冗余关系问题和实体重叠问题.2.4 目标函数
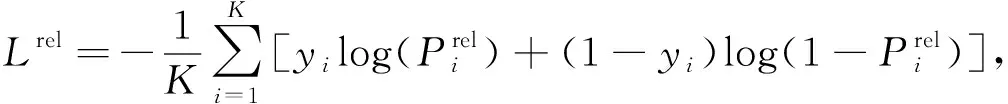

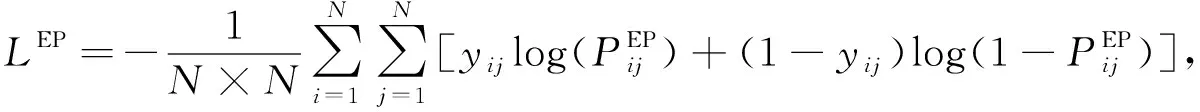
3 实 验
3.1 数据集和评估标准

3.2 实验设置
3.3 对比模型
3.4 总体实验结果

3.5 不同实体重叠情形的实验结果
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31中国毕业后医学教育(2021年3期)2021-12-02中国毕业后医学教育(2021年3期)2021-12-02陶瓷学报(2021年2期)2021-07-21山西大学学报(自然科学版)(2021年1期)2021-04-21中国外汇(2019年18期)2019-11-25五邑大学学报(自然科学版)(2019年3期)2019-09-06哲学评论(2017年1期)2017-07-31领导决策信息(2017年9期)2017-05-04领导决策信息(2017年9期)2017-05-04
