
基于Clite-YOLOv5的鸡状态检测算法
2023-09-28 03:41初晓玉祖丽楠
计算机测量与控制 2023年9期
初晓玉,祖丽楠
(青岛科技大学 自动化与电子工程学院,山东 青岛 266061)
0 引言
1950年代开始,国外畜禽养殖业逐步向集约标准化过渡,规模化畜禽养殖开始成为畜禽养殖的趋势,其对环境的要求比较严格[1]。因此,畜禽环境监控系统的开发从20世纪70年代开始成为了必然的发展趋势[2]。目前,在荷兰、美国、日本和以色列等发达国家,智能化的环境控制系统已经普遍在现代化养殖场中应用。有些先进的智能控制系统甚至整合了投喂料、疫病诊断、畜禽污染物管理等功能,形成了智能养殖管理系统[3]。国内相关技术的研发主要集中在2 000年以后,涉及畜禽环境测量与监控、单一指标的监控和干预、多指标控制策略研究、硬件开发与系统组建等各方面,其工作主要侧重于技术研发和验证[4]。
目前,机器视觉在畜牧养殖行业的技术研究有很多[5]。如:在羊群活动分析任务中,Fraess等人[6]通过计算视频相邻两种中改变的像素数量占总像素的比值得出羊群的活动水平。在商业养殖场中,畜群的活动和突变可能与设备故障、病害等异常情况有关,将图像转换为动物分布指数,通过分布指数的突然变化,可以实时发现肉鸡舍的设备故障[7]。Li等人采用Mask-RCNN算法检测家禽的梳理行为[8]。Kashiha等人采用椭圆拟合模型的方法将鸟的轮廓从背景中提取出来[9]。Aydin等人[10]将和相机安装在测试走廊的中央采集母鸡的图像,使用背景减法分割形状,然后使用椭圆形状模型定义鸡的大小和方向,从而对鸡的躺卧事件数(NOL)和躺卧时延(LTL)进行分类并实时记录。与人工计算结果相比,该自动监测系统识别NOL的准确率为83%。随后,Aydin等人通过提取特征向量对该图像处理算法进行改进,实现了更高的准确性[11]。Kristensen和Cornou等人[12]设计了一种可以自动记录肉鸡活动的模型。在他们的研究中,他们记录了三周内鸡的活动水平。采用一种方法来检测给定年龄的肉鸡活动与规定水平的偏差,以便及时通知生产商。Riddle等人[13]使用ImageJ和MATLAB软件研究了每只母鸡站立、躺卧、栖息、拍打翅膀和吸尘行为所需的面积。但是,这中算法需要手动选择完美的图像。Zhuang等人[14]通过SVM模型对患病肉鸡进行自动预测和分类,为获得姿态特征,采用k均值聚类方法对图像进行分割,采用细化方法获得骨架结构。SVM模型的准确率达到99.47%,优于其他机器学习算法。De Wet等人[15]是少数几个基于机器视觉的肉鸡称重的例子之一,他们研究了肉鸡的表面积和外围轮廓作为体重描述参数用来估计肉鸡每天的体重变化。他们在表面积的预测权重上实现了11%的平均相对误差。
中国肉鸡养殖规模飞速上涨,极大地提高了我国的肉鸡产量[16]。高密度的规模化养殖同时也会对鸡场的饲养管理方法提出更高要求,笼内鸡群的密集接触容易产生疾病问题,而传染病的出现会威胁整个鸡场的安全生产[4]。因此,应及早发现问题鸡只并做隔离处理,防止传染病的传播。
目前肉鸡养殖中能使用环境控制系统自动控制温湿度等环境参数,但对于病鸡死鸡的检查仍需人工进入鸡舍查看,这种方法监测结果往往依赖于工作人员的实际操作,首先实时性较差,不能及时清理问题鸡只,其次人工的频繁进出查看会将细菌带进鸡舍,影响鸡群的健康生长[17]。因此从很大程度上影响了我国畜禽规模养殖环境测控设备的深度发展。基于图像处理的动物监测系统可以做到自动、无创、连续地监测和识别动物的不同行为及状态。图像处理技术可以同时监测多个动物个体、工作时长没有限制且不会出现视觉疲劳,因此机器视觉在动物监测系统中的应用将成为必然趋势。
上述基于机器视觉的畜牧养殖技术提供了多种检测算法,但由于不同的检测任务有不同的目标和约束条件,难度也会有所不同。因此,上述算法并不能很好地解决鸡状态检测问题。原因如下:1)实际应用:上述讨论的相关算法大多是基于实验室的理想环境,实际应用中的限制条件更多,如拍摄角度、拍摄距离、鸡群密度等。2)目标背景复杂:笼养鸡不同于散养鸡,鸡笼内鸡群密度较大,且多处于俯卧姿态且相机安装高度受限,背景中鸡群交错重叠且混有大量鸡笼框架信息。3)鸡眼睛目标较小:由于拍摄距离和鸡眼睛本身特征影响,其在图像上的尺寸约为20*20像素,属于小目标检测,难度较高。4)鸡眼睛不同形态特征不明显:在鸡状态检测任务中,需要识别出3种形态:全睁、半睁、全闭。其中半睁状态的鸡眼睛相较于全睁状态的特征并不明显,容易导致目标分类错误。
针对以上问题,为了能够更好地实现机器视觉技术在畜牧养殖业的实际应用,提出基于机器视觉的鸡状态检测算法Clite-YOLOv5。具体贡献如下:
1)改进特征提取网络:提出lite-CBC3模块,该模块将C3模块轻量化之后融合CBAM注意力机制,在减少参数量的同时充分利用浅层浅层卷积神经网络中特征信息的提取。
2)改进目标框抑制算法:提出Fuse-NMS算法对重叠框进行调整,该算法将置信度分数作为权重参数,对重叠框按照该权重对目标框位置进行精修。提高了目标位置预测的精确度。
3)模型轻量化:提出采用深度可分离卷积对骨干网络的普通卷积进行替换,减少模型参数量和计算量,从而更易于移动端部署。
1 数据集建立及处理
以现代标准肉鸡养殖场中笼养模式下的肉鸡作为研究对象,采集了真实养殖环境中笼养鸡的原始图像。肉鸡的笼养模式下,鸡笼大小为1.2米*1米*0.6米,每个笼内约有12只鸡。
异常鸡不同于健康鸡眼睛呈圆形,病鸡眼睛多呈椭圆形或细长状与健康鸡只的眼睛形态有明显区别,而死鸡的眼睛呈紧闭状态。由于正常情况下鸡只闭眼以及半闭眼的状态较少,因此现场采集时,采用多机位架设摄像头采集视频流的方式对鸡眼睛状态进行捕捉,后期对视频流进行抽帧,将鸡只眨眼时从睁眼到闭眼的状态进行精确的捕捉。经过上述步骤,共抽取到有效鸡只照片2 146张,像素大小为1 920*1 080,保存格式为JPG。使用Labelimg[18]软件对图像进行标注,标注标签分别为:0(全睁眼)、1(半睁眼)、2(闭眼),由于鸡眼睛目标过小,因此选择将整个鸡头作为标注对象,标注示例如图1所示。各类别数量如表1所示。

表1 数据集各类别标签数量

图1 标注示例
2 YOLOv5目标检测算法原理
目前目标检测主要分为两类,分别是两阶段和一阶段检测算法[19],其中两阶段算法主要有RCNN系列[20],此系列算法适合精度需求较的目标检测任务,其缺点是检测速度非常慢,不能满足实时检测的需求[21]。一阶段算法以YOLO系列为代表,此系列算法采用回归的思想,形成了端到端的检测网络[22],因此,YOLO系列在检测速度上有明显的提升。根据任务背景对于的实时性需求,以YOLOv5算法为基础,分别针对网络的特征提取能力、假阳性检测框抑制能力以及模型的参数量3个方面进行改进。
YOLOv5网络结构:
YOLOv5网络结构共包括输入端、主干、颈部和头部网络四部分[23]。输入端主要包括Mosaic数据增强,自适应锚框计算等[24]。Mosaic数据增强极大的丰富了检测物体的背景;自适应描框计算是在训练时对真实框相对于预测框的位置偏移反复进行迭代更新,得到最合适的预测框[25]。在主干网络中,YOLOv5采用了新的CSP-Darknet53,用于提取特征并向下级颈部网络传递[26];颈部网络将原本YOLOv4颈部网络中的PAN结构替换为增加了CSP结构的New CSP-PAN,用于将提取的特征进行有效的融合[27];头部网络与YOLOv3相同,用于输出检测的目标信息[28]。
3 改进的Clite-YOLOv5算法
鸡眼睛状态的识别算法不仅要实现复杂鸡笼环境下的高精度目标识别,还要考虑到嵌入式移动硬件的部署,因此,应尽可能地压缩模型的参数量和计算量。为此,提出Clite-YOLOv5目标检测算法,如图2所示。Clite-YOLOv5采用提出的lite-CBC3模块重构了主干网络,该模块对C3模块进行了删减并添加了轻量的CBAM注意力模块[29],实现了对目标特征更好地提取;同时,改进了DIoU-NMS算法[30],增加了重叠目标框对于最终目标框的决定权,在改善目标检测框被误删的同时提高检测框的预测精度;使用深度可分离卷积[31]替代主干网络中的普通卷积,极大地减少了模型的参数量,使其更适合在移动端部署。
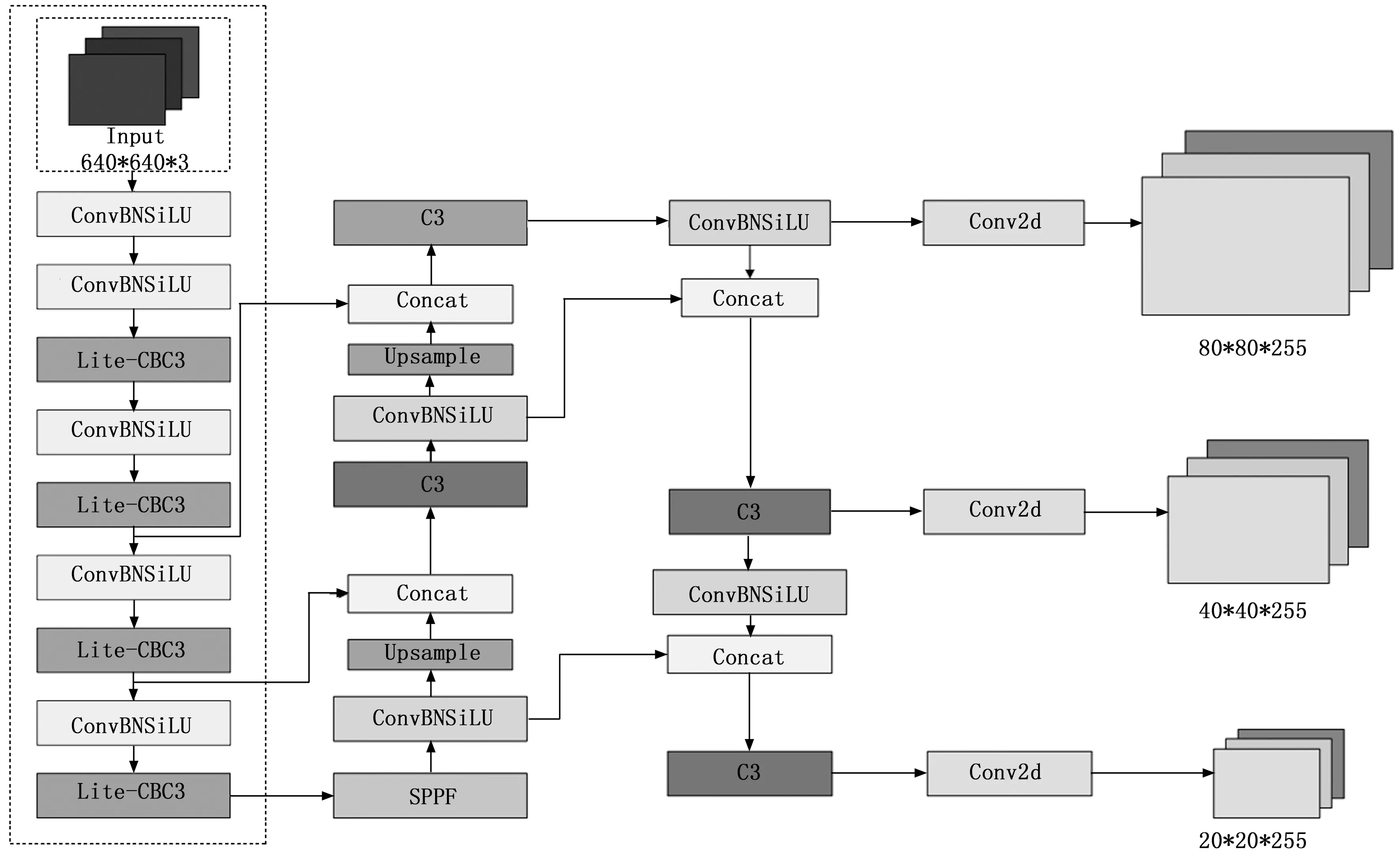
图2 Clite-YOLOv5结构示意图
3.1 主干网络重建
对YOLOv5的主干网络进行了重构,在提高精度的同时尽可能压缩模型大小。为了提取图像中的特征信息,主干网络中包含了大量的卷积层,但过多卷积层的堆叠并不能明显提升模型效果,同时这些卷积层包含了大量的参数,导致模型过于臃肿。因此改进了主干网络中的C3模块得到lite-C3模块,如图3所示,将C3模块中桥接分支上的卷积层删除,使另一分支输出的特征图直接与输入特征图进行拼接操作,能够有效减少模型的参数量。

图3 lite-C3模块结构示意图
随着网络层数的加深,高层语义信息越能被更好的提取,但高层的特征图的分辨率通常较低。由于鸡眼睛属于小目标,且其处于复杂的鸡笼环境中,过于深层的卷积操作可能会导致鸡眼睛的特征信息难以提取。因此,为了能够充分利用浅层卷积神经网络中的高分别率信息,最大限度地提取浅层网络中小目标的特征信息,提出lite-CBC3模块,该模块在浅层特征提取阶段就增加了较为轻量的注意力机制CBAM,实现从浅层到深层网络的多特征提取,lite-CBC3模块结构图如图4所示。

图4 lite-CBC3模块结构示意图
lite-CBC3模块能够更好的区分背景与目标,提高小目标的检测能力,同时弥补删除部分卷积层导致的精度略有下降的问题。
3.2 改进NMS算法
YOLOv5原网络中采用的是普通NMS非极大值抑制算法[32],该算法按照置信度分数,将检测框分为最高分数检测框与其他检测框,依次将其他检测框与最高分数框进行IoU计算,并将IoU大于阈值的其他检测框删除,上述操作可以有效去掉重复的检测框,该算法用公式(1)表示为:
(1)
其中:Si是置信度,BM为当前最大置信度预测框,Bi为其他预测框,Qth为IOU阈值。
但是当两个相同类别的不同物体距离接近时,会因为IOU的计算值比较大,经过NMS处理后只剩下一个预测框,导致漏检。为此,有人提出DIOU-NMS算法,该算法在计算IOU的基础上添加了一个惩罚项,将两个框的中心点距离也作为过滤指标,其公式(2)如下所示:
RDIoU=ρ2(b,bgt)/c2
(2)
其中:b和bgt表示两个预测框的中心点,ρ2(b,bgt)是两个中心点之间的欧式距离,c是包含两个预测框的最小方框的对角线长度。如果两个预测框之间的IOU比较大,同时两个框之间的中心距离也较大时,这两个框就都不会被过滤掉。
从DIOU-NMS算法原理上来看,该算法可以在一定程度上解决检测框误删的问题。但在鸡眼睛的检测任务中,鸡舍中的鸡只相互遮挡,不仅存在NMS算法误删检测框的问题,同时还存在多个检测框都不能准确预测的问题。因此,提出Fuse-NMS算法,该算法对DIoU-NMS进行了改进,保留了将要被删除的预测框Bi,并将其与当前最大置信度的预测框BM进行加权融合,得到新预测框BMi的位置。新预测框BMi将根据BM和Bi的相关信息计算得到左上角及右下角坐标点的位置信息,计算方法如公式(3)、(4)所示。
f(pM,pi)=pM+(pi-pM)×Ci
(3)
BMiL(x,y)=(f(xML,xiL),f(yML,yiL))
BMiR(x,y)=(f(xMR,xiR),f(yMR,yiR))
(4)
公式(3)中,f(pM,pi)为计算新预测框BMi横(纵)坐标值的函数,pM为BM的横(纵)坐标值,pi为Bi的横(纵)坐标值,Ci为Bi的置信度分数;公式(4)中BMiL(x,y)为新预测框BMi左上角坐标,BMiR(x,y)为新预测框BMi右下角角坐标。从上述公式可以看出,Bi的置信度分数越高,对新预测框的位置影响越大,从而尽可能高质量地保留了网络对于目标位置的预测信息,使输出结果更加精确。
Fuse-NMS算法流程如图5所示,算法会根据置信度分数对检测框进行排序并放入列表S,并将分数最高的检测框BM移入最终检测列表F,根据公式(2)依次计算剩余检测框Bi的Si值,对于IoU值大于阈值Qth,即Si为0的检测框,将视为重复框并进行加权融合,用融合后的Bmi位置信息更新列表F中的Bm;遍历完列表S后剩余的检测框再重新取出当前列表中置信度分数最高的检测框BM,重复上述操作直至列表S为空,输出最终检测框列表F。
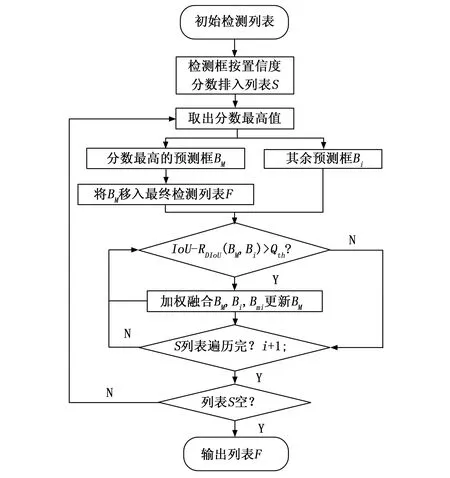
图5 Fuse-NMS算法流程图
3.3 模型轻量化
为了能够缩减模型的参数量和计算量,提高模型的运行效率,提出将主干网络中的普通卷积替换为深度可分离卷积。深度可分离卷积(Depthwise Separable Convolution)是一种卷积神经网络中常用的卷积操作,与传统的卷积操作相比,它有着更小的参数数量和更快的计算速度,同时仍然保持着较好的性能表现。
深度可分离卷积本质上由两个部分组成。第一个部分是深度卷积(Depthwise Convolution),它是一种仅在输入的每个通道上独立进行的卷积操作,可以对每个通道单独地提取特征,不同通道之间不会互相影响,这使得它的参数数量相较于传统的卷积操作要小得多。但这一操作并不能将各通道上的信息进行交互融合,而一个目标的特征信息一般由多个通道的特征信息组合而成,因此需要第二个部分逐点卷积(Pointwise Convolution)来进行通道维度的信息融合,它是一种多通道卷积操作,其采用1*1卷积核与生成的特征图进行卷积并在通道维度上进行叠加生成一张新的特征图,从而增强了卷积的非线性性。
深度可分离卷积中深度卷积和逐点卷积的具体计算步骤如下:如图6所示,假设输入图片的特征维度为W*H*D,其中W、H为输入特征图的宽高、D通道数,假设深度卷积的卷积核大小为K。

图6 深度可分离卷积
深度卷积(DW)的计算步骤为:对于输入图像的每一个通道,单独使用一个K*K卷积核与输入特征图进行卷积操作,共得到D张输出特征图,则深度卷积的卷积运算量如公式(5)所示。
FLOPs(DW)=D×W×H×K×K
(5)
逐点卷积(PW)的计算步骤为:对深度卷积输出的特征图(W*H*D)使用N个1*1*D卷积核进行卷积运算,输出得到N个新特征图,即完成深度可分离卷积操作。则逐点卷积的卷积运算如公式(6)所示。
FLOPs(PW)=N×W×H×D
(6)
经过深度可分离卷积的总运算量即为二者相加,如公式(7)所示。相较于普通卷积的运算量如公式(8)所示,深度可分离卷积的运算量大大减少。
FLOPs(DSC)=K×K×D+D×N
(7)
FLOPs(C)=(2×D×K2-1)×W×H×N
(8)
深度可分离卷积通过深度卷积和逐点卷积两个操作的组合将普通卷积计算参数量的乘法运算转变为加法运算,实现了与传统卷积相似的特征提取效果,但是相对于传统卷积,它具有更快的计算速度和更少的参数数量及运算量,节省了计算和存储成本,同时也减小了过拟合的风险,对于轻量级计算设备等资源限制性场景有着非常好的应用前景。
4 实验分析
4.1 实验环境及参数配置
训练参数设置如下:初始学习率为0.01;动量参数为0.937;权重衰减系数为0.000 5;迭代次数为300,每次迭代训练图像的数量为8;输入图像大小为640*640。实验环境如表2所示。
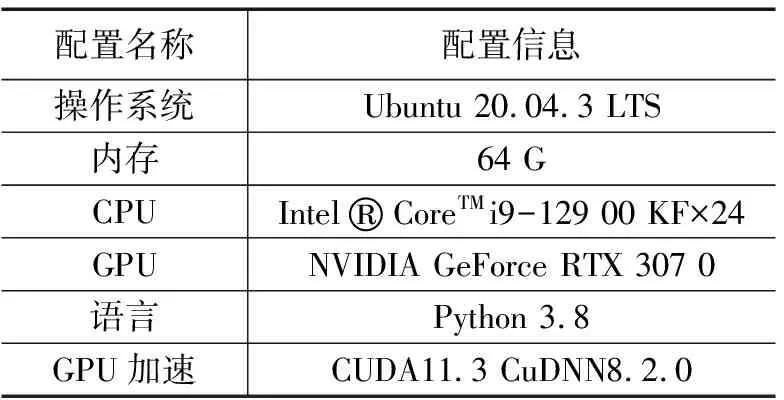
表2 环境配置
4.2 评价指标
本研究中,采用P(Precision)、R(Recall)和mAP(mean average Precision)作为客观评价指标对训练后的鸡眼睛目标检测模型进行评价。各指标计算公式分别如公式(9)、(10)、(11)所示:
(9)
(10)
(11)
其中:TP为正确识别鸡眼睛目标的数量;FP为将背景错误地识别为鸡眼睛目标的数量;FN为没有识别出鸡眼睛目标的数量;C为鸡眼睛目标类别的数量;N为测试集图片的数量;K为IoU阈值;P(k)表示精度;R(k)为召回率。
4.3 实验结果对比
4.3.1 消融实验
为验证提出的改进方法的有效性,设计了消融实验,给出了各模型的Recall、mAP、参数量以及检测速度FPS。检测结果如表3所示。

表3 消融实验结果
从表3中可以看出,原YOLOv5算法的mAP为85.76%,精度较低;从YOLOv5(lite-CBC3)实验结果可以看出,加入lite-CBC3模块后,模型精度提升了4.67%,召回率提升了4.31%,可以看出该模块对于鸡眼睛的检测有明显的提升效果;实验YOLOv5(Fuse-NMS)将原有NMS算法替换为Fuse-NMS,从实验结果来看,mAP提高了3.59%,召回率提高了6.47%,在减少检测框误删方面有明显的提升效果;YOLOv5(深度可分卷积)实验结果表示在替换为深度可分离卷积后,模型性能略有下降,但模型的参数量大大减少,更加易于移动的部署;Clite-YOLOv5为提出的最终模型,相较于原YOLOv5模型,提出的模型在精度上提高了7.12%,召回率提升了7.93%,参数量减少了19.79万,同时检测速度能够满足实时检测任务的需要。
为了能够直观看出模型改进前后的检测效果,选取了部分典型的检测效果图进行相关分析。
图中包含了所有检测类别,从图8左边的图片中可以看出,原YOLOv5对于目标与背景较难区分且有一定遮挡时检测效果不佳,出现漏检现象;图8右边图像中,当两个目标较为靠近时出现了将两个目标看作一个目标的错误;从图9可以看出,提出的Clite-YOLOv5可以能够检测出左边图像中的漏检目标,同时右边两个靠近的目标也能够实现精确检测。

图8 YOLOv5检测效果图

图9 Clite-YOLOv5检测效果
4.3.2 主流算法比较
将提出的算法与现有主流算法进行比较,实验结果如表4所示。从表中可以看出提出的Clite-YOLOv5模型检测算法在检测精度和检测速度上都优于其他算法。

表4 主流算法比较结果
5 结束语
为实现移动端部署鸡状态检测技术,提出Clite-YOLOv5鸡状态检测模型,该模型对YOLOv5的特征提取网络进行了改进,提出了融合CBAM注意力机制的轻量化模块lite-CBC3,轻量主干网络的同时提高网络对浅层特征的提取能力;提出将NMS非极大值抑制算法改为Fuse-NMS算法,该算法按照权重将重叠框信息作用于目标框,实现目标位置的微调,提高目标的定位精度;提出采用深度可分离卷积替换主干网络中的普通卷积,减少模型参数量。实验结果表明提出的算法检测精度与速度都优于现有算法,且适合在移动端部署。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
电子制作(2019年11期)2019-07-04
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
北京航空航天大学学报(2018年1期)2018-04-20
