
基于改进NeRF-Navigation的移动机器人三维路径规划方法
2023-10-02 11:41杨铖侯耀斐
电脑知识与技术 2023年24期
杨铖,侯耀斐
(1.乌江能源投资有限公司,贵州 贵阳 550081;2.贵州大学现代制造技术教育部重点实验室,贵州 贵阳 550025;3.贵州省装备制造数字化车间建模与仿真工程研究中心,贵州 贵阳 550025)
0 引言
在移动机器人路径规划研究领域,构建精确稳定的三维环境地图对于机器人路径规划的成功至关重要,已引起国内外学者的广泛关注。但在动态变化场景中,机器人传感器位姿与场景的对应关系难以稳定,这给网格地图障碍物信息的感知分析带来了困难[1]。同时,由于机器人需要在不断变化的环境中获取实时的传感器数据并进行处理,以便于准确地更新自身位姿,在场景复杂、安全性要求较高时难以保证路径规划的实时性[2]。因此,路径规划方法需要在地图网格精度与路径更新实时性之间做出权衡。
早期的人工势场路径规划研究是针对静态环境而设计的,障碍物和目标物均被视为静态元素。然而,这种做法忽略了现实环境的动态性和变化性,因此不能适应复杂多变的实际场景。Fujimura 等人[3]提出了相对动态的人工势场方法来解决移动机器人的动态路径规划问题,利用静态路径规划的思想,通过将时间视为规划模型的一维参数,实现了对动态环境下移动障碍物的处理。Ge 等人[4]在吸引势函数中关联移动机器人与目标物的相对位置与相对速度,在排斥势函数中关联移动机器人与障碍物的相对位置与相对速度,提出动态环境下的机器人路径规划算法。马小陆[5]提出了基于势场跳点的蚁群算法,该算法能够有效地减少收敛迭代的次数,缩短搜索收敛的时间,且搜索路径更优。
在实际工程应用中,运动目标的形貌、体积和姿态是路径选择的直接影响因素,面对三维复杂场景,越来越多的深度学习路径规划算法涌现出来。郑红波等人[6]在传统A*算法进行路径规划的基础上,提出了一种基于层次包围盒碰撞检测的实时路径规划优化算法,在时间效率和规划效果上都有一定的优势。Pinto 等人[7]提出了一种新的视觉引导路径规划系统(V-GPP),它确定了一个无碰撞的三维轨迹,考虑了障碍与场景的相互作用。Smith 等人[8]开发了一种新的基于启发式的多视点立体重建质量连续优化方法,并将其应用于路径规划问题,其规划速率达到毫秒级。Koch 等人[9]提出了一个三维路径规划框架,设计用于详细和完整的小规模三维重建。Kompis 等人[10]提出了一种在线路径规划算法,用于快速探索和规划先前未知兴趣区域的三维场景路径。
综上,三维场景下的路径规划需要考虑移动机器人本身位姿与环境之间的碰撞关系,以及移动轨迹与场景之间的相互作用。结合目前医疗环境所面临的配送迟缓性问题,本文将利用深度学习方法解决重建场景下的高效路径更新问题作为研究方向,在三维重建场景的基础上实现环境知情、安全和可解释的探索映射及路径规划。
1 NeRF-Navigation
神经辐射场(NeRF)是从观测图像中学习三维场景表征来进行新视图重建的神经网络模型,结构分为正余弦位置编码网络、特征提取网络和体积渲染网络,整体网络结构如图1所示。其中,特征提取网络包含两个MLP 模型,一个为8 层全连接的采样MLP 模型,另一个为3层全连接的推理MLP模型。
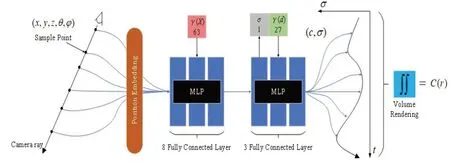
图1 NeRF网络结构图
NeRF-Navigation 是一种基于神经辐射三维重建的路径规划方法,该方法将NeRF 生成的隐式采样模型等价为空间中网格的存在概率,从而使机器人可以在只使用单目相机视觉传感器的情况下进行导航。整体网络结构如图2 所示,主要包括NeRF 场景表示模块和机器人状态信息更新模块,通过预测机器人的轨迹生成控制指令。其中,轨迹预测和控制指令生成分别通过基于梯度的优化器和深度逆强化学习(Deep Inverse Reinforcement Learning)实现。
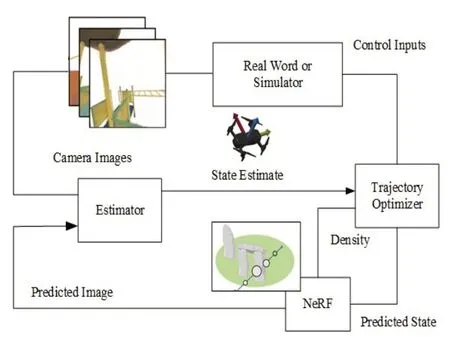
图2 NeRF-Navigation网络结构图
NeRF-Navigation采用iNeRF的思想,假设由Fθ参数化的场景NeRF已经存在,然而观测图像I的相机姿态Vd尚未确定,根据极大似然估计原理,通过反向推理一个训练过的NeRF进行六自由度姿态估计,如式(1)所示:
然而,NeRF采样模型仅表示空间中几何点截停光线的微分概率,无法作为场景查询的显式约束,故NeRF-Navigation 将光线的终止概率等价为质量粒子的终止概率,借助三维网格地图令机器人在未被占用的NeRF 表达空间中导航,以到达给定目标点。其中,机器人的外形由其边界点集B 组成的三维网格近似表示,则t时刻的碰撞概率,如式(2)所示:
为了加快规划速度,NeRF-Navigation采用了基于微分平坦性的A*路径规划方法,引入碰撞惩罚和控制惩罚约束机器人的姿态,通过梯度优化探索一组平坦连续的输出路径点W={w0,…,wn}以最小化惩罚项,如式(3)所示:
式中,ŵτ为微分平坦状态wτ的位置分量,Rτ为机器人坐标到世界坐标的旋转矩阵,Γ为控制惩罚权重的对角矩阵,uτ表示机器人行为的微分平坦状态量。
为了更新规划路径,NeRF-Navigation制定了一个状态估计滤波器,当机器人根据控制指令运行一个时间步长后,估计器从机载单目相机获取一张当前视角的新图像,通过递归贝叶斯滤波方法传播估计结果与不确定性建立动力学模型联系。同时,使用图像特征检测器(如ORB)识别特征点,使机器人转向更高梯度信息的区域周围进行采样。
2 基于改进NeRF-Navigation的三维路径规划
本文关注室内环境移动机器人的路径规划,对于给定起始位置与目标位置,在三维网格地图中使用A*搜索初始化路径,并采用一个适用于移动机器人的三自由度姿态过滤器来跟踪初始化轨迹。NeRFNavigation 根据每个时间步长中可用的有限信息控制移动机器人进一步的行为决策,本文在每一步的规划中,引入贪婪信息增益策略,对于一组采样点N,通过比较其与当前姿态连接的行为效益,选择生成路径的最佳视角;同时,使用动态权重的启发式函数提高路径搜索效率。通过两种策略的结合使用,提出一种具有隐式环境适应的动态加权A*路径规划方法,网络结构如图3所示:
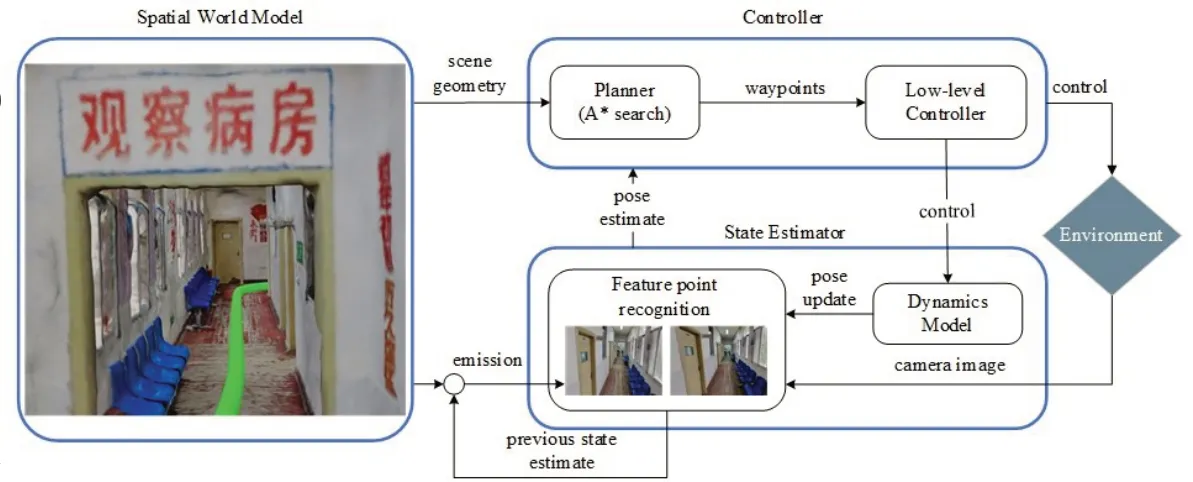
图3 改进NeRF-Navigation算法网络结构图
2.1 贪婪信息增益策略
在基于采样的规划中,移动机器人以当前姿态的地图空间视角为观测图像采样视点,通过计算每个视点的信息增益、消耗成本确定最终组合效益,约束当前节点的视角指向最佳候选点并执行动作,从而提高搜索的准确性和效率。
本文采用了一种基于采样的Next-best-view(NBV)规划策略。当机器人向当前的NBV移动时,计算观测图像平面内视点集{Ni}的综合效益。每个视点Ni={ga(Ni),ct(Ni),u(Ni)}都包含信息增益ga、消耗成本ct及综合行为效益u,信息增益ga估计了访问一个视点Ni的积极影响,消耗成本ct估计了访问一个视点Ni的负面影响,最后,综合行为效益u将信息增益和消耗成本合并成统一的优化目标。本文使用每次移动的执行时间作为其消耗成本,以作计算质量与计算效率的权衡,通过估计执行时间内动力学模型的位置和方向,得到采样点集的综合行为效益,如式(4)所示:
式中,sampling(Ni)表示观测图像平面内的采样点集,path(Nj)表示连接到当前姿态的节点集,节点被不断地重新连接计算,促使观测图像平面内的u最大化。即在每个时间步长识别出一个最佳观测视角,其中的节点序列使总累积信息增益与总累积消耗成本之比最大化。
基于上述策略,本文使用移动机器人传感器正向模拟来计算信息增益ga(Ni),如式(5)所示:
式中,visible(Vd)表示从姿态Vd中可见的所有采样图像平面的集合,Vd(Ni)是视点Ni的NBV 姿态,I(u)是采样图像平面内连接像素点的梯度信息。采用文献[9]中的方向优化方法来选择每个位置移动机器人的偏航角,如式(6)所示:
式中,xNi,yNi表示轮式移动机器人在视点Ni处的位置分量,ψ表示机器人的转角,这些参数可以在每个视点上贪婪地优化,而每个采样图像平面是独立的,因此姿态的最佳偏航会自动使等式(6)最大化。
visible(Vd)是使用迭代光线投射方法得到的,而光线投射期间是否存在精确的网格先验会导致不同的选择结果。如果光线终止在高质量的占用网格预测上,说明visible(Vd)更优地反映了真实场景,从而导致更准确的增益估计。然而,如果有错误的预测,移动机器人则放弃该传感器视图,并重新规划预测。
2.2 动态权重策略
为了加快搜索速度,基于A*算法引入了动态加权策略。该策略旨在通过自适应调整启发式函数的权重以平衡探索和行动,以应对不确定性和变化的环境带来的挑战。A*算法是一种基于Dijkstra发展而来的启发式搜索算法,其关键是确定启发式函数,形式如式(7)所示:
由于启发式函数h(n)采用欧几里得距离,其值始终小于或等于从当前节点nc到目标点的实际距离,当节点n到终点的距离较远时,h(n) ≪g(n),将增加算法搜索节点数量并降低效率。本文对A*算法中的启发式函数h(n)进行了改进。通过对h(n)的修改来控制后续节点的选择过程,限制了A*算法的节点扩展方向和深度,确保了下一个搜索节点nt的方向不会过度发散。
以起点ns与终点nd的距离R为直径做圆,以作策略几何示意,如图4 所示,其中点记为no,nc为当前节点,n'为下一搜索节点,r1为起点ns与终点nd间曼哈顿距离的一半,r2为当前节点nc与中点no的距离,形式如式(8)~(9)所示:
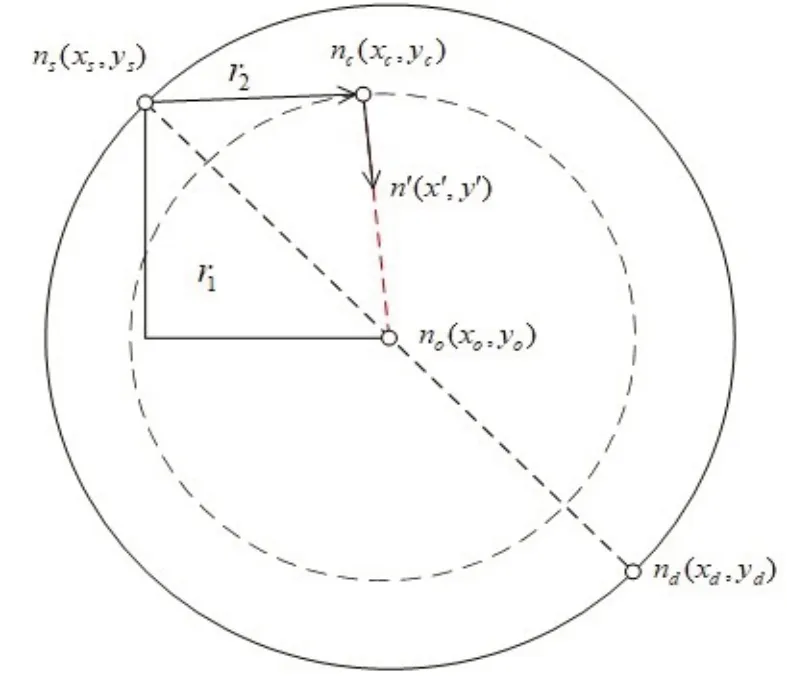
图4 路径点几何表示
通过比较r1、r2,得到跟随节点变化的动态参数ke及启发式函数的加权因子K(n),形式如式(10)~(11)所示:
故将新的启发式函数定义为f(n) =g(n) +K(n)*h(n),通过对h(n)的修改来控制后续节点的选择,确保下一搜索节点n'的方向不会过度发散。分析可知,r1在节点探索过程中保持不变,r2总体上具有先减小后增大的连续变化趋势,则ke在节点探索过程中先表现出扩张性,随后在no附近开始呈现收缩趋势。通过实施该策略,使节点探索过程中启发式函数h(n)的比重增加,减少A*算法的搜索区域,加快搜索速度,且动态权重变化较为缓和,可以得到较优路径。
本文使用上述两种策略共同作用以达到平衡路径代价和平滑程度的目的,鼓励移动机器人优先考虑高确定性预测区域,使其隐式地适应环境的类型。例如,在直线走廊中,机器人倾向于沿中心直线移动,因为这可以最大程度地观测到直线走廊的全貌;而在障碍物较多的复杂场景中,机器人倾向于沿障碍物采样点占比较大的观测视角方向移动。此时,移动机器人能在未知其所处环境的情况下选择一条较优路径。
3 实验结果与分析
为验证本文改进方法的有效性,在实验室大型室内场景、观察病房走廊纵深场景、一号病室中型室内场景和治疗室小型室内场景中,将所提方法与NeRFNavigation 算法进行了比较,不同网络的重建场景路径规划结果如图5所示,左侧图像为原始算法的路径规划结果,右侧图像为改进算法的路径规划结果,与结果相关的定量指标见表1,采用加粗字体表示较优指标。
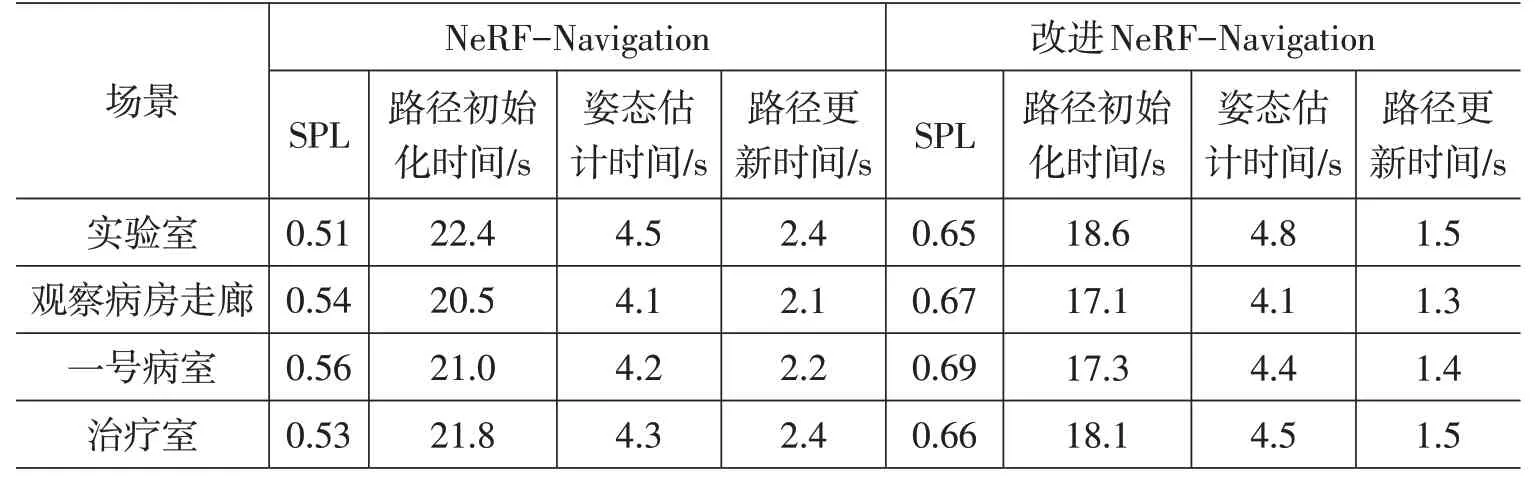
表1 不同方法综合性能对比

图5 4种不同环境下路径规划对比图
图5 展示了实验室场景、观察病房走廊场景、一号病室场景和治疗室场景下的三维路径规划定性结果,图中第一列为NeRF-Navigation 路径规划结果,第二列为本文所提方法路径规划结果。由图中4种类型的重建场景路径规划对比结果可以直观地看出,相较于原始算法,本文改进算法可以实现较为平滑的更新路径。在相对空旷处,改进算法更倾向于朝前进方向沿直线规划;在避障转角处,改进算法能规划出较为平滑的曲线路径,且4类场景都能保持较优的路径覆盖,证明了所提算法的有效性和鲁棒性。
表1 展示了原始NeRF-Navigation 与本文改进方法的综合性能对比,包括成功路径实现(SPL)、路径初始化时间、姿态估计时间和路径更新时间。由表中数据分析可知,相较于对比实验组,本文改进方法以平均0.2s 的姿态估计时间增量换取了平均-3.5s 的路径初始化时间增量和平均-0.8s 的路径更新时间增量,且成功路径实现的比例提高了13%,在所有实验场景下的性能指标均优于对比实验组,这表明本文所提网络较对比网络能有效提升重建场景下的路径规划性能。
图6 展示了实验室环境下移动机器人在同一位置的姿态估计准确性,左图代表原始算法,右图代表改进算法。因实际路径点不同,故难以选取完全一致的观测角度,这里选取二者实际路径上的接近路径点进行对比,蓝色曲线表示实际姿态,橙色曲线表示估计姿态。实验结果表明,改进算法实现了更贴合实际的姿态估计,可增强路径更新的安全性与效率。
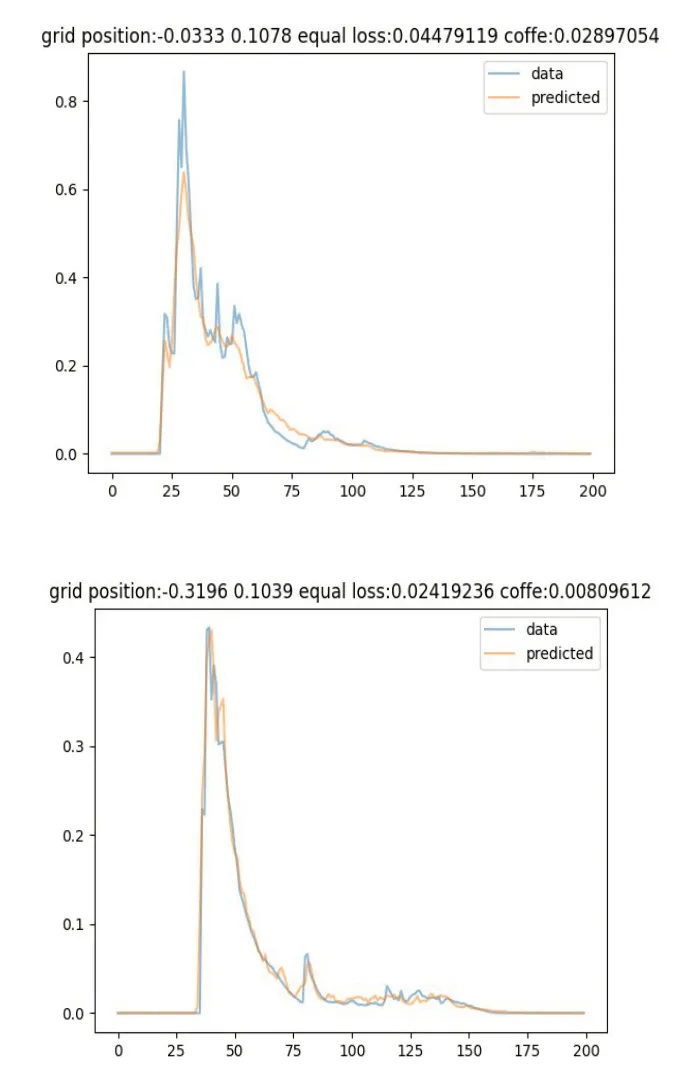
图6 实验室环境下姿态估计对比图
4 结论
针对医疗环境光线行进较为复杂的特点,本文使用Nerfstudio 框架对重建场景边界进行限定,生成了高保真的三维网格地图作为三维路径规划的基础。在NeRF-Navigation 的基础上,提出一种具有隐式环境适应的动态加权A*路径规划方法,并在实验室场景与自建医疗场景进行改进算法的实验训练与测试。实验结果表明,本文所提方法的三维路径规划各项评价指标相较于NeRF-Navigation 均有提高,能有效降低规划路径的曲率,提高规划效率,可以用来指导机器人在不同类型医疗场景下进行自适应三维路径规划,即使在复杂的环境中也能显示出可靠的路径覆盖。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
学生天地(2020年3期)2020-08-25
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
制造技术与机床(2017年3期)2017-06-23
河南电力(2016年5期)2016-02-06
中国水利(2015年5期)2015-02-28
中国海洋大学学报(自然科学版)(2014年8期)2014-02-28
中国海洋大学学报(自然科学版)(2014年7期)2014-02-28
中国校外教育(上旬)(2009年6期)2009-08-04
