
一种基于网格框架下改进的多密度SNN聚类算法
2023-10-09 01:47黄祖源黄浩淼
计算机应用与软件 2023年9期
原 野 田 园 黄祖源 李 辉 黄浩淼
1(云南电网有限责任公司信息中心 云南 昆明 650500)
2(昆明能讯科技有限责任公司 云南 昆明 650021)
0 引 言
数据智能化处理是一个长期以来研究的热点,同时在信息物理融合系统(Cyber Physical Systems)的感知层中也是研究的热点。数据集的聚类处理正在快速地发展,当前数据聚类算法分为基于网格聚类[1]、基于密度聚类[2]、基于层次聚类[3]和基于集成式聚类[4]等,基于网格聚类的算法将空间网格化后使连续空间离散化,从而大大地减少计算量。Nketsa等[5]提出一种基于统计信息的网格聚类算法STING,将数据空间网格划分为具有层次机构的矩形单元,分别计算置信度区间反映为聚类关联度,从而提高聚类效率,但底层单元的粒度粗降低了聚类的质量和准确性。Mihael等[6]提出一种基于最佳网格的高维数据集聚类算法OptiGridS,根据密度函数得到网格划分的不均匀切割平面运用数学模型使聚类效率较高,但对于高维数据集聚类质量低。Sheikholeslami等[7]提出一种基于小波变换模型的聚类算法Wave Cluster,将多维网格空间划分数据,使用小波变换转换特征空间后,得到数据密度分布信息,从而快速得到类簇中心点,但聚类准确性低。针对高维数据集处理中以上基于网格聚类算法的准确性较低问题,基于密度的聚类算法容易识别不同密度和形状的类簇中心,使聚类精确率得到提高,Peng等[8]提出一种基于密度和噪声处理的聚类算法DBSCAN,根据高密度的区域来划分类簇,在类簇的E领域寻找密度可达的对象实现聚类,但算法的时间复杂度较高。Xiao等[9]提出一种基于密度分布函数的聚类算法DENCLUE,将数据空间中数据集根据数学函数模拟为所有数据点的高斯影响函数值,由全局密度确定类簇核心点,在具有噪声的高维数据集中聚类效果较好,但算法的时间效率较高。Rodri等[10]提出一种基于密度峰值的快速聚类算法DPC,通过计算区域内样本的局部密度,利用决策图快速找到密度峰值对应的类簇中心,从而确定类簇数目,然后对剩余的样本点根据汉宁距离进行分配。为了平衡聚类的时效和准确率,研究者开始提出了基于网格和密度结合的聚类算法,San等[11]提出了一种基于高维数据子空间内聚类算法CLIQUE,对数据集网格划分后找到稀疏和密集单元,在高维的子空间实现聚类。Chen等[12]提出一种基于数据信息的子空间聚类算法SCI,首先网格划分高维数据空间,得到稠密单元、稀疏单元、离群单元,通过熵定理优化聚类效果,能够对离群点进行检测和簇的边界点的处理,但参数选择特别敏感,空间复杂度大。Goil等[13]提出一种基于子空间扩展的高维数据集聚类算法MAFIA,根据数据分布来确定网格单元,通过高密度的单元完成聚类,适用于高维数据集,但时间复杂度较高。Levent等[14]提出一种共享最近邻聚类算法SNN,根据数据对象之间k-距离建立矩阵关系图,然后通过相似度准则划分类簇中心,完成高维数据集中不同密度对象的聚类,但对于含噪声点的数据集聚类精度低。
在数据聚类处理过程中类簇的边缘网格中包含着噪声点,传统的聚类算法不能有效识别和处理噪声点,影响数据集进行正确的聚类。本文结合参考文献[15]的基本思想,首先自顶向下均匀切割数据空间得到空间单元,然后计算高维子空间内每个空间单元的密度,根据密度值划分得到数据空间内密度不同的网格,利用网格相对密度差来检测类簇边界网格中包含的噪声数据点,考虑到边界网格内噪声数据点近邻环境的影响,避免将样本错分,然后改进SNN算法利用每个样本的局部密度分布信息进行类簇分配,则高密度的数据点按照数据分布特征进行分配,而低密度的噪声点使用样本近邻信息进行分配。本文算法通过局部密度对噪声点进行分配,提高算法对非均匀密度的高维数据集聚类的准确率。
1 共享最近邻SNN聚类算法
SNN算法根据高维数据集D中数据对象之间k-距离邻居矩阵稀疏化建立起最近邻居矩阵图,若p和q两个数据对象彼此互为最近邻居,可以由k-最近距离建立起对象连接,连接的相似度权值即为数据对象p和q共享邻居个数,定义为:
similarity(p,q)=size(NN(p)∩NN(q))
(1)
式中:NN(p)和NN(q)分别代表数据对象p和q的最近邻居列表。计算对象p与第k个最近邻居的距离distance(k,p),得到:
Nk(p)={q∈D{p}|d(p,q)≤k-distance(p)}
(2)
式中:Nk(p)表示对象p的k-距离领域内所有距离小于k-distance(p)的对象数据集合;d(p,q)表示数据对象p和q之间最短距离。根据相似度准则估计出集合中数据点的SNN区域密度,SNN区域密度定义为:
N(p)={q∈D{p}|similarity(p,q)≤SIM}
(3)
式中:N(p)表示为数据对象p相似度权重小于密度阈值SIM的对象个数,设定p的领域中最小的对象个数阈值为MinPts,将大于阈值的数据对象作为类簇中心点,完成聚类。
2 基于网络框架下改进的多密度SNN聚类算法
2.1 网格簇边界噪声点检测
首先自顶向下网格划分数据空间,假设d维数据集D中,数据个数为N,第i维上的值在区间Rgi=[li,hi]中,则S=Rg1×Rg2×…×Rgd为d维数据空间,然后将数据空间的每一维度均分为∏numi个网格单元,其中numi为数据空间在第i维上单元数目,网格单元均分的边长为:
(4)
numi=[(hi-li)/length]
(5)
式中:a为网格控制因子。然后将每个维度网格单元对象X=(x1,x2,…,xd)插入网格索引表提升聚类效率,索引表每一维对应的下标为:
indi=[(xi-li)/length]
(6)
元组中插入的数据个数即网格密度,下一步计算中心密度差合并网格,将密度最大的网格作为初始网格g0,并计算边界网格gi与初始网格g0的中心密度差,定义为:
(7)
(8)
式中:den(g0)为网格密度;λ为较小密度网格占比;G为数据集D划分的网格数目。若agdd(g0,gi)<ε,则将两个网格合并形成区域D1,否则边界网格gi为包含着噪声数据的密度稀疏网格,然后根据噪声点数据分布不均匀特征得到边界网格的质心偏离度:
(9)
式中:C0和C1分别为边界网络质心点和中心点。当dcm大于阈值则边界网格中噪声数据为不均匀特征,计算边界网格中心C1与最近邻簇网格中心C的距离distC,及边界网格内数据点Ni到最近邻簇网格中心的距离disti(i=1,2,…,n),若disti≤distC则数据点Ni作为噪声点标记。边界网格噪声点检测如图1所示。
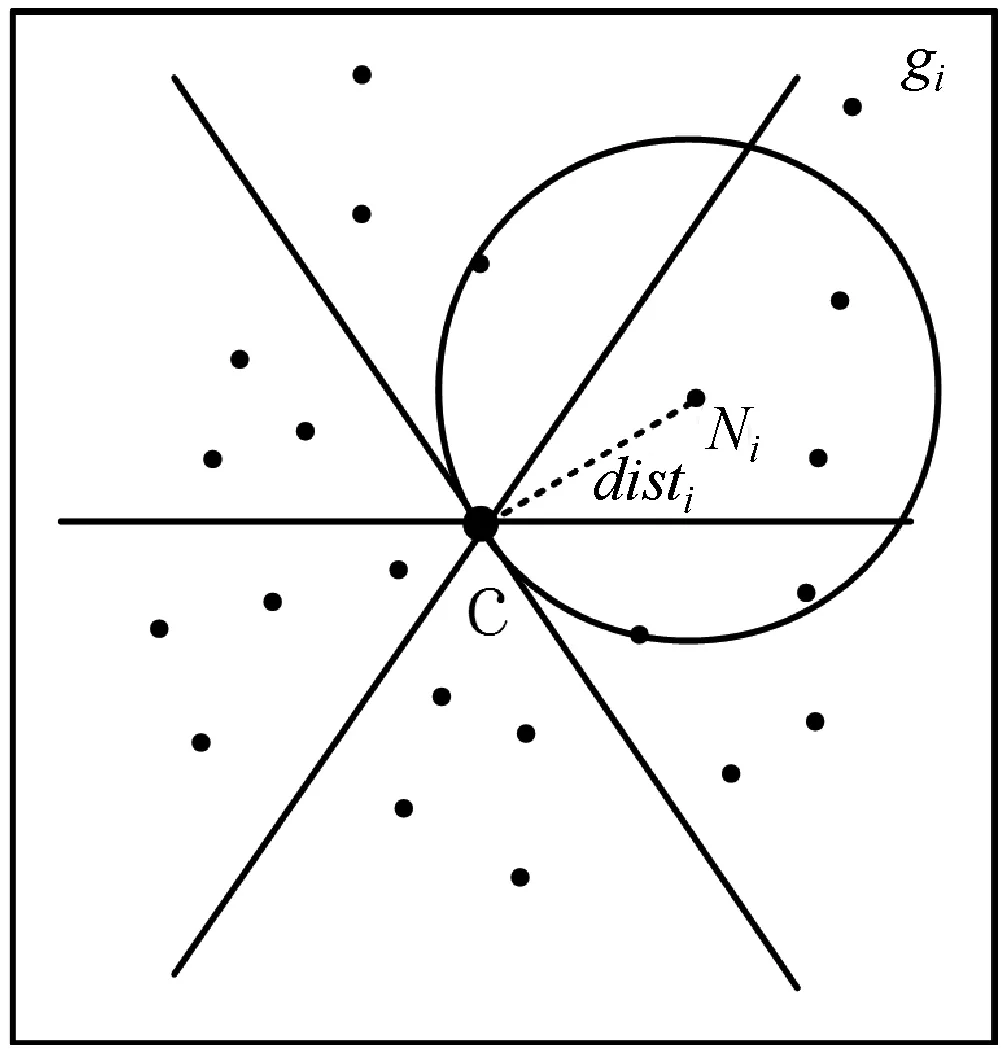
图1 边界网格噪声点检测示意图
图2 GSSN算法边界网格内噪声点分配图
2.2 改进的多密度SNN聚类算法
SNN聚类算法对不同密度的高维数据集进行聚类时,能够自动识别出簇的数目,但对于含有噪声点的数据集聚类精度都不高,且数据维度的可伸缩性较差,主要是因为SNN算法基于数据的全局密度分布将边界网格样本分配给距离最近邻类簇。本文改进的SNN算法考虑每个样本数据的局部密度峰值,找到边界网格中高密度的非噪声点分布特征进行类簇分配,对于低密度的噪声点采用KNN最近邻域信息进行类簇分配。
首先网格划分得到的边界网格后,计算样本数据i的局部密度峰值ρj定义为:
谷城县把解决贫困户眼前生计问题和建设长期收益项目结合起来,因户制宜、精准施策,资金、项目向重点贫困村倾斜,向最困难的群体倾斜,70%的资金用于37个重点贫困村,将脱贫成效作为项目安排、资金使用的重要参考因素,促使入户政策更加完善,切实改善了贫困人口的生产生活条件。
(10)
式中:KNN(i)为样本i的K个近邻样本构成的集合,样本i、j之间的欧氏距离为dij。根据密度峰值将非噪声点样本分配到相应的类簇,从而使得分配到某一簇的样本点跟类簇之间具有紧密联系。对策略1中未分配的噪声点样本,采用分配策略2利用K近邻信息的思想进行样本类簇分配,样本分配策略如下。
(1) 分配策略1:主要针对非噪声点的分配,具体实现算法如下:
Step1将网格类簇中心合集CI中选择一个未被访问的核心点ci,其作为SNN算法的类簇中心,并标记ci已被访问。
Step2计算ci点的K近邻KNN(ci)集合的样本后,初始化队列Vq,再将样本数据合并到ci所在的类簇中,若KNN(ci)中含有的非噪声点样本满足dq,r≤mean{dr,j|j∈KNN(r)},就将r归入q所属的类簇,并且将样本r加到队列Vq的尾部;依次将样本点纳入队列Vq。
Step3若队列Vq不是空队列,则转Step4。
Step4若CI中还存在未被访问的样本点,则转Step1,否则算法结束。
(2) 分配策略2:对边界网格内噪声点进行分配,具体实现算法如下:
Step1对所有未被分配的噪声点样本i,统计其K近邻KNN(i)中归属于类簇c(c=1,2,…,|CI|)的样本得分Nc(i),得到1×|CI|的向量N(i),对全部没有被分配的样本点组成一个n×|CI|识别矩阵S,其中S(i,j)=Nj(i),j=1,2,…,n。
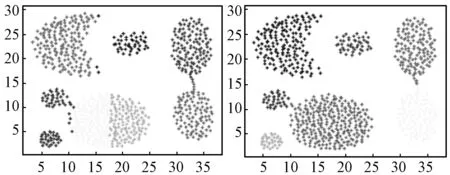
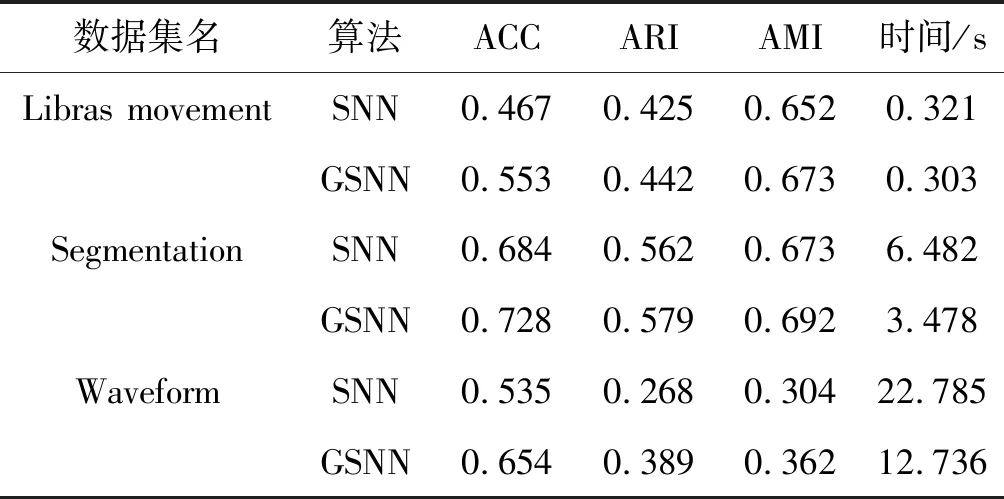
Step2根据Nk(p)=max{Nk(i),i=1,2,…,n},从识别矩阵S中选取同类样本中最大得分对应的噪声点样本p,Nk(i)为每个样本的分数组成向量。将样本p以下分配方式归入对应类簇中,若Nk(p)=k,则矩阵S中该同类样本的所有噪声点都分配到最大分数值Nk(p)所对应的簇;若0 Step3更新矩阵S,对于KNN(p)不存在分配样本q,则令Nk(q)=Nk(q)+1,并将分配样本p在矩阵S所对应向量N(p)置为0。 Step4若没有未分配的噪声点样本,则终止算法,否则,转到Step2。 输入:高维数据集D,分配样本的近邻数K。 输出:聚类的结果C。 Step1数据的预处理:归一化、有误数据剔除及缺失数据处理。 Step2网格划分数据空间,根据式(6)建立网格索引表。 Step3根据式(7)得到中心密度值判断边界网格,式(8)对边界网格中噪声点进行检测。 Step4从网格决策图中选取恰当的类簇中心合集CI,根据式(10)得到数据样本的局部密度峰值。 Step5按照分配策略1对除边界网格内高密度的非噪声点样本进行分配。 Step6按照策略2,对策略1没有分配的低密度噪声点根据样本K近邻信息进行分配。 Step7若没有未分配的样本点,聚类结束,否则返回Step3。 本文选取表1的人工数据集和UCI数据集对提出的GSNN算法进行测试,根据聚类准确率ACC、兰德指数ARI和互信息AMI指标[16]与SNN算法进行实验比较验证,实验表明本文算法对高维数据集内有效分配噪声点,使聚类结果的鲁棒性更好。本文实验环境的处理器为Intel®i5-4210 2.60 GHz,内存为4 GB。本文算法中网格控制因子取a=1.7、网格密度占比取λ=0.25。接下来通过实验结果对SNN和改进后的GSNN聚类算法进行实验分析。 从图3的Aggregation和图4的Spiral数据集聚类结果可以看出,SNN算法对边界的噪声点识别度低,导致属于同一簇的数据点没有被正确分配,而GSSN算法通过边界网格内样本点的局部密度,得到密度稀疏的噪声点后采用K近邻信息进行类簇分配,从图5的Path-based数据集聚类结果可以看出,SNN算法聚类后黑色的第3类簇结果误分严重,本文GSSN算法通过不同密度的网格得到各个类簇核心点,有效识别各种类簇的形状,聚类效果较好。 (a) SNN算法 (b) GSNN算法 从表2的UCI真实数据集算法的聚类对比结果可以看出,在Libras movement高维数据集上,本文GSSN算法在ACC值、ARI值和AMI值相比SNN算法得到明显提高,主要是因为数据特征数较多,SNN算法不能有效地寻找到类簇核心点,而GSSN算法根据网格中心密度值判断类簇核心点,从数据的分布特征改善聚类的准确率。从Segmentation数据集聚类结果可以看出,GSSN算法在各级指标上同样优于SNN算法,同时大数据集Segmentation中GSNN算法耗时明显小于SNN算法,主要因为本文算法数据集中读取数据点根据网格密度来处理分配,不需要对数据进行过多处理。在Waveform数据集上存在大量的噪声点,导致SNN算法的ARI仅为0.268,而GSSN算法有效识别边界网格内噪声点后,采取K近邻信息对其进行分配,达到更好的聚类效果。 表2 不同算法的G-means值对比结果 根据SNN算法对高维数据集进行聚类时,数据特征数较多影响类簇核心点的识别,并且不能有效处理噪声数据点,导致聚类准确率较低。本文提出一种基于网络框架下改进的多密度SNN聚类算法,即通过网格划分数据空间,根据网格中心密度值识别出类簇核心点和边界网格的噪声点,然后计算边界网格的样本局部密度,对非噪声点根据数据分布特征进行分配,对噪声点使用k近邻信息进行分配,从而减少噪声点错误分配,提高聚类算法的准确率。在人工数据集合UCI的真实数据集中聚类结果表明本文算法性能更优秀,超过了比较的SNN算法。但本文算法并没有考虑对高维数据集中离群点的检测和处理,下一步的研究方向是在多维网格结构框架下得到数据分布特征识别和处理离群点,提高聚类算法的鲁棒性。2.3 GSSN算法流程
2.4 算法时效性分析
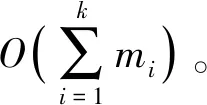
3 实验与结果分析
3.1 UCI非均衡数据集
3.2 结果分析
4 结 语
猜你喜欢
儿童时代·幸福宝宝(2021年11期)2021-12-21
铁道通信信号(2020年9期)2020-02-06
数学大王·趣味逻辑(2019年5期)2019-06-13
小学科学(学生版)(2019年5期)2019-05-21
测控技术(2018年4期)2018-11-25
经济技术协作信息(2018年30期)2018-11-22
证券法律评论(2018年0期)2018-08-31
电信科学(2017年6期)2017-07-01
数学年刊A辑(中文版)(2015年3期)2015-10-30
应用数学与计算数学学报(2014年3期)2014-09-26
